
ReactとTesseract.js(OCR)を使用した画像からテキストへの変換
公開: 2022-03-10アプリケーションの主な目的は人間の問題を解決することであるため、データはすべてのソフトウェアアプリケーションのバックボーンです。 人間の問題を解決するためには、それらについての情報が必要です。
このような情報は、特に計算を通じてデータとして表されます。 Webでは、データは主にテキスト、画像、ビデオなどの形式で収集されます。 画像には、特定の目的を達成するために処理されることを意図した重要なテキストが含まれている場合があります。 これらの画像は、プログラムで処理する方法がなかったため、ほとんどが手動で処理されました。
画像からテキストを抽出できないことは、前の会社で直接経験したデータ処理の制限でした。 スキャンしたギフトカードを処理する必要があり、画像からテキストを抽出できなかったため、手動で処理する必要がありました。
ギフトカードの手動確認とユーザーのアカウントへの入金を担当する「オペレーション」と呼ばれる部門が社内にありました。 ユーザーがつながるウェブサイトがありましたが、ギフトカードの処理は舞台裏で手動で行われました。
当時、私たちのウェブサイトは主にバックエンド用のPHP(Laravel)とフロントエンド用のJavaScript(jQueryとVue)で構築されていました。 問題が経営陣によって重要であると見なされた場合、私たちの技術スタックはTesseract.jsで動作するのに十分でした。
私は問題を解決するつもりでしたが、ビジネスまたは経営者の観点から判断して問題を解決する必要はありませんでした。 会社を辞めた後、私はいくつかの調査を行い、可能な解決策を見つけることを試みることにしました。 最終的に、私はOCRを発見しました。
OCRとは何ですか?
OCRは、「光学式文字認識」または「光学式文字リーダー」の略です。 画像からテキストを抽出するために使用されます。
OCRの進化はいくつかの発明にまでさかのぼることができますが、オプトフォン、「Gismo」、CCDフラットベッドスキャナー、Newton MesssagePad、Tesseractは、文字認識を別のレベルの有用性に導く主要な発明です。
では、なぜOCRを使用するのでしょうか。 さて、光学式文字認識は多くの問題を解決します。そのうちの1つが、この記事を書くきっかけになりました。 画像からテキストを抽出する機能により、次のような多くの可能性が保証されることに気付きました。
- 規制
すべての組織は、何らかの理由でユーザーの活動を規制する必要があります。 この規制は、ユーザーの権利を保護し、脅威や詐欺からユーザーを保護するために使用される可能性があります。
画像からテキストを抽出することで、組織は、特に画像が一部のユーザーによって提供されている場合に、規制のために画像のテキスト情報を処理できます。
たとえば、Facebookのように、広告に使用される画像のテキスト数を規制することは、OCRを使用して実現できます。 また、Twitterで機密コンテンツを非表示にすることもOCRによって可能になります。 - 検索性
検索は、特にインターネット上で最も一般的なアクティビティの1つです。 検索アルゴリズムは、主にテキストの操作に基づいています。 光学式文字認識を使用すると、画像上の文字を認識し、それらを使用して関連する画像結果をユーザーに提供することができます。 つまり、画像とビデオはOCRを使用して検索できるようになりました。 - アクセシビリティ
画像にテキストを表示することは、アクセシビリティにとって常に課題であり、画像にテキストを表示することは経験則です。 OCRを使用すると、スクリーンリーダーは画像のテキストにアクセスして、ユーザーに必要なエクスペリエンスを提供できます。 - データ処理の自動化データの処理は、大部分がスケールのために自動化されています。 テキストは手動以外では処理できないため、画像にテキストを含めることはデータ処理の制限です。 光学式文字認識(OCR)を使用すると、プログラムで画像上のテキストを抽出できるため、特に画像上のテキストの処理に関係する場合に、データ処理の自動化が保証されます。
- 印刷物のデジタル化
すべてがデジタル化されており、デジタル化されるドキュメントはまだたくさんあります。 小切手、証明書、およびその他の物理的なドキュメントは、光学式文字認識を使用してデジタル化できるようになりました。
上記のすべての用途を見つけることは私の興味を深めたので、私は質問をすることによってさらに進むことにしました:
「特にReactアプリケーションで、Web上でOCRを使用するにはどうすればよいですか?」
その質問は私をTesseract.jsに導きました。
Tesseract.jsとは何ですか?
Tesseract.jsは、元のTesseractをCからJavaScript WebAssemblyにコンパイルし、ブラウザーでOCRにアクセスできるようにするJavaScriptライブラリです。 Tesseract.jsエンジンは元々ASM.jsで作成され、後でWebAssemblyに移植されましたが、WebAssemblyがサポートされていない場合でも、ASM.jsはバックアップとして機能します。
Tesseract.jsのWebサイトに記載されているように、100以上の言語、自動テキスト方向付けとスクリプト検出、段落、単語、文字境界ボックスを読み取るためのシンプルなインターフェイスをサポートしています。
Tesseractは、さまざまなオペレーティングシステム用の光学式文字認識エンジンです。 これは、ApacheLicenceの下でリリースされたフリーソフトウェアです。 ヒューレットパッカードは、1980年代にプロプライエタリソフトウェアとしてTesseractを開発しました。 2005年にオープンソースとしてリリースされ、その開発は2006年からGoogleによって後援されています。
Tesseractの最新バージョンであるバージョン4は2018年10月にリリースされ、Long Short-Term Memory(LSTM)に基づくニューラルネットワークシステムを使用する新しいOCRエンジンが含まれており、より正確な結果を生成することを目的としています。
TesseractAPIを理解する
Tesseractがどのように機能するかを実際に理解するには、そのAPIとそのコンポーネントのいくつかを分解する必要があります。 Tesseract.jsのドキュメントによると、これを使用する方法は2つあります。 以下は、その内訳の最初のアプローチです。
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } recognizeメソッドは、最初の引数として画像、2番目の引数として言語(複数の場合もあります)、最後の引数として{ logger: m => console.log(me) }を取ります。 Tesseractでサポートされている画像形式はjpg、png、bmp、pbmで、要素(img、video、canvas)、ファイルオブジェクト( <input> )、blobオブジェクト、画像へのパスまたはURL、base64でエンコードされた画像としてのみ提供できます。 。 (Tesseractが処理できるすべての画像形式の詳細については、こちらをお読みください。)
言語は、 engなどの文字列として提供されます。 +記号は、 eng+chi_traのように複数の言語を連結するために使用できます。 言語引数は、画像の処理に使用されるトレーニング済みの言語データを決定するために使用されます。
注:利用可能なすべての言語とそのコードはここにあります。
{ logger: m => console.log(m) }は、処理中の画像の進行状況に関する情報を取得するのに非常に役立ちます。 ロガープロパティは、Tesseractが画像を処理するときに複数回呼び出される関数を取ります。 ロガー関数のパラメーターは、 workerId 、 jobId 、 status 、 progressをプロパティとして持つオブジェクトである必要があります。
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progressは0から1までの数値であり、画像認識プロセスの進行状況を示すパーセンテージです。
Tesseractは、ロガー関数のパラメーターとしてオブジェクトを自動的に生成しますが、手動で指定することもできます。 認識プロセスが行われている間、関数が呼び出されるたびにloggerオブジェクトのプロパティが更新されます。 そのため、コンバージョンの進行状況バーを表示したり、アプリケーションの一部を変更したり、目的の結果を達成したりするために使用できます。
上記のコードのresultは、画像認識プロセスの結果です。 resultの各プロパティには、バウンディングボックスのx/y座標としてプロパティbboxがあります。
resultオブジェクトのプロパティ、その意味または使用法は次のとおりです。
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text:文字列として認識されたすべてのテキスト。 -
lines:テキストの行ごとに認識されたすべての行の配列。 -
words:認識されたすべての単語の配列。 -
symbols:認識された各文字の配列。 -
paragraphs:認識されたすべての段落の配列。 この記事の後半で「自信」について説明します。
Tesseractは、次のようにさらに必須に使用することもできます。
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();このアプローチは最初のアプローチに関連していますが、実装が異なります。
createWorker(options)は、Tesseractワーカーを作成するWebワーカーまたはノードの子プロセスを作成します。 ワーカーは、TesseractOCRエンジンのセットアップを支援します。 load()メソッドはTesseractコアスクリプトをロードし、 loadLanguage()は文字列として提供された言語をロードし、 initialize()はTesseractが完全に使用できる状態になっていることを確認してから、recognizeメソッドを使用して提供された画像を処理します。 terminal()メソッドはワーカーを停止し、すべてをクリーンアップします。
注:詳細については、TesseractAPIのドキュメントを確認してください。
ここで、Tesseract.jsがどれほど効果的であるかを実際に確認するために何かを構築する必要があります。
何を構築するのですか?
ギフトカードからPINを抽出することが、そもそもこのライティングアドベンチャーにつながった問題だったため、ギフトカードPIN抽出機能を構築します。
スキャンしたギフトカードからPINを抽出する簡単なアプリケーションを作成します。 簡単なギフトカードピンエクストラクタの作成に着手したときに、私が直面したいくつかの課題、提供したソリューション、および私の経験に基づく結論について説明します。
- ソースコードに移動→
以下は、実世界で可能な現実的な特性を備えているため、テストに使用する画像です。

カードからAQUX-QWMB6L-R6JAUを抽出します。 それでは、始めましょう。
ReactとTesseractのインストール
ReactとTesseract.jsをインストールする前に注意すべき質問があります。質問は、なぜReactをTesseractで使用するのかということです。 実際には、TesseractをVanilla JavaScript、任意のJavaScriptライブラリ、またはReact、Vue、Angularなどのフレームワークで使用できます。
この場合にReactを使用することは、個人的な好みです。 当初はVueを使いたかったのですが、VueよりもReactに精通しているので、Reactを使うことにしました。
それでは、インストールを続けましょう。
create-react-appを使用してReactをインストールするには、以下のコードを実行する必要があります。
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jsまた
npm install tesseract.jsnpmでTesseractをインストールできなかったため、yarnを使用してTesseract.jsをインストールすることにしましたが、yarnはストレスなく作業を完了しました。 npmを使用することもできますが、私の経験から判断すると、Tesseractを糸でインストールすることをお勧めします。
それでは、以下のコードを実行して開発サーバーを起動しましょう。
yarn startまた
npm startヤーンスタートまたはnpmスタートを実行すると、デフォルトのブラウザで次のようなWebページが開きます。

ページが自動的に起動されない場合は、ブラウザでlocalhost:3000に移動することもできます。
ReactとTesseract.jsをインストールした後、次は何ですか?
アップロードフォームの設定
この場合、必要なフォームが含まれるように、ブラウザーで表示したばかりのホームページ(App.js)を調整します。
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App この時点で注意が必要な上記のコードの部分は、関数handleChangeです。
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } この関数では、 URL.createObjectURLはevent.target.files[0]を介して選択されたファイルを取得し、img、audio、videoなどのHTMLタグで使用できる参照URLを作成します。 setImagePathを使用して、状態にURLを追加しました。 これで、 imagePathを使用してURLにアクセスできるようになりました。
<img src={imagePath} className="App-logo" alt="image"/> 画像のsrc属性を{imagePath}に設定して、処理する前にブラウザでプレビューします。
選択した画像をテキストに変換する
選択した画像へのパスを取得したので、画像のパスをTesseract.jsに渡して、そこからテキストを抽出できます。
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default App関数「handleClick」を「App.js」に追加します。この関数には、選択した画像へのパスを取得するTesseract.jsAPIが含まれています。 Tesseract.jsは、「imagePath」、「language」、「設定オブジェクト」を取ります。
以下のボタンがフォームに追加され、「handClick」を呼び出します。これにより、ボタンがクリックされるたびに画像からテキストへの変換がトリガーされます。
<button onClick={handleClick} style={{height:50}}> convert to text</button>処理が成功すると、結果から「信頼」と「テキスト」の両方にアクセスします。 次に、「setText(text)」を使用して状態に「text」を追加します。
<p> {text} </p>に追加することにより、抽出されたテキストを表示します。
画像から「テキスト」が抽出されていることは明らかですが、自信とは何ですか?
信頼度は、変換がどれほど正確であるかを示します。 信頼水準は1から100の間です。精度の観点から、1は最低を表し、100は最高を表します。 また、抽出されたテキストが正確であると認められるべきかどうかを判断するためにも使用できます。
次に、問題は、変換全体の信頼スコアまたは精度に影響を与える可能性のある要因は何かということです。 これは主に、使用されるドキュメントの品質と性質、ドキュメントから作成されるスキャンの品質、およびTesseractエンジンの処理能力という3つの主要な要因の影響を受けます。
それでは、以下のコードを「App.css」に追加して、アプリケーションのスタイルを少し整えましょう。
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }これが私の最初のテストの結果です:

Firefoxでの結果
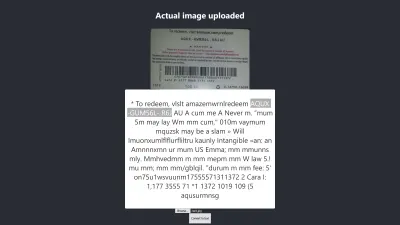
上記の結果の信頼水準は64です。ギフトカードの画像の色が濃く、得られる結果に間違いなく影響することは注目に値します。
上の画像をよく見ると、カードのピンが抽出されたテキストでほぼ正確であることがわかります。 ギフトカードがはっきりしないため、正確ではありません。
あ、待って! Chromeではどのように表示されますか?
Chromeでの結果
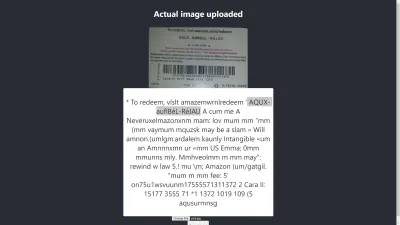
ああ! Chromeでは結果はさらに悪化します。 しかし、Chromeの結果がMozillaFirefoxと異なるのはなぜですか? ブラウザが異なれば、画像とそのカラープロファイルの処理も異なります。 つまり、ブラウザによって画像のレンダリングが異なる可能性があります。 事前にレンダリングされたimage.dataをTesseractに提供することにより、使用しているブラウザーに応じて異なるimage.dataがTesseractに提供されるため、異なるブラウザーで異なる結果が生成される可能性があります。 この記事の後半で説明するように、画像を前処理すると、一貫した結果を得るのに役立ちます。
正しい情報を取得または提供していることを確認できるように、より正確である必要があります。 ですから、もう少し先に進む必要があります。
最終的に目標を達成できるかどうか、もっと試してみましょう。
精度のテスト
Tesseract.jsを使用した画像からテキストへの変換に影響を与える要因はたくさんあります。 これらの要因のほとんどは、処理する画像の性質を中心に展開し、残りはTesseractエンジンが変換を処理する方法に依存します。
内部的には、Tesseractは実際のOCR変換の前に画像を前処理しますが、常に正確な結果が得られるとは限りません。
解決策として、画像を前処理して正確な変換を実現できます。 画像を2値化、反転、拡張、デスキュー、または再スケーリングして、Tesseract.js用に前処理することができます。
画像の前処理は、それ自体が多くの作業または広範な分野です。 幸い、P5.jsは、使用したいすべての画像前処理技術を提供しています。 ホイールのごく一部を使用したいという理由だけでホイールを再発明したり、ライブラリ全体を使用したりする代わりに、必要なものをコピーしました。 すべての画像前処理技術はpreprocess.jsに含まれています。
二値化とは何ですか?
二値化とは、画像のピクセルを黒または白に変換することです。 以前のギフトカードを2値化して、精度が向上するかどうかを確認します。
以前は、ギフトカードからいくつかのテキストを抽出しましたが、ターゲットPINは希望するほど正確ではありませんでした。 したがって、正確な結果を得る別の方法を見つける必要があります。
次に、ギフトカードを2値化します。つまり、ピクセルを白黒に変換して、より高いレベルの精度が達成できるかどうかを確認します。
以下の関数は2値化に使用され、preprocess.jsという別のファイルに含まれています。
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImage上記のコードは何をしますか?
変換のためにTesseractに渡す前に、画像データを保持していくつかのフィルターを適用し、画像を前処理するためのキャンバスを紹介します。
最初のpreprocessImage関数はpreprocess.jsにあり、ピクセルを取得して使用できるようにキャンバスを準備します。 関数thresholdFilterは、ピクセルを黒または白に変換することにより、画像を2値化します。
preprocessImageを呼び出して、前のギフトカードから抽出されたテキストがより正確になるかどうかを確認しましょう。
App.jsを更新する頃には、次のようなコードになっているはずです。
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default Appまず、次のコードを使用して「preprocess.js」から「preprocessImage」をインポートする必要があります。
import preprocessImage from './preprocess'; 次に、フォームにキャンバスタグを追加します。 canvasタグとimgタグの両方のref属性をそれぞれ{ { canvasRef }と{ imageRef }に設定します。 参照は、アプリコンポーネントからキャンバスと画像にアクセスするために使用されます。 次のように、「useRef」を使用してキャンバスと画像の両方を取得します。
const canvasRef = useRef(null); const imageRef = useRef(null);コードのこの部分では、JavaScriptでキャンバスを前処理することしかできないため、画像をキャンバスにマージします。 次に、画像形式として「jpeg」を使用してデータURLに変換します。
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");「dataUrl」は、処理される画像としてTesseractに渡されます。
それでは、抽出されたテキストがより正確になるかどうかを確認しましょう。
テスト#2

上の画像はFirefoxでの結果を示しています。 画像の暗い部分が白に変更されていることは明らかですが、画像を前処理しても、より正確な結果は得られません。 それはさらに悪いです。
最初の変換には2つの誤った文字しかありませんが、これには4つの誤った文字があります。 しきい値レベルを変更しようとしましたが、役に立ちませんでした。 二値化が悪いからではなく、画像を二値化してもTesseractエンジンに適した方法で画像の性質が修正されないため、より良い結果は得られません。
Chromeでもどのように表示されるかを確認しましょう。

同じ結果が得られます。
画像を2値化することでより悪い結果が得られた後、他の画像前処理技術をチェックして、問題を解決できるかどうかを確認する必要があります。 それでは、次に拡張、反転、ぼかしを試してみます。
この記事で使用されているように、P5.jsから各テクニックのコードを取得してみましょう。 preprocess.jsに画像処理技術を追加し、1つずつ使用します。 使用する前に、使用したい画像前処理技術のそれぞれを理解する必要があるので、最初にそれらについて説明します。
膨張とは何ですか?
拡張とは、画像内のオブジェクトの境界にピクセルを追加して、画像をより広く、より大きく、またはより開いた状態にすることです。 「拡張」技術は、画像を前処理して、画像上のオブジェクトの明るさを上げるために使用されます。 JavaScriptを使用して画像を拡張する関数が必要なため、画像を拡張するコードスニペットがpreprocess.jsに追加されます。
ブラーとは何ですか?
ぼかしとは、画像の鮮明さを下げることで画像の色を滑らかにすることです。 時々、画像は小さな点/パッチを持っています。 これらのパッチを削除するために、画像をぼかすことができます。 画像をぼかすためのコードスニペットはpreprocess.jsに含まれています。
反転とは何ですか?
反転とは、画像の明るい領域を暗い色に、暗い領域を明るい色に変更することです。 たとえば、画像の背景が黒で前景が白の場合、背景が白になり、前景が黒になるように画像を反転できます。 また、画像をpreprocess.jsに反転するコードスニペットを追加しました。
dilate 、 invertColors 、 blurARGBを「preprocess.js」に追加した後、これらを使用して画像を前処理できるようになりました。 それらを使用するには、preprocess.jsの最初の「preprocessImage」関数を更新する必要があります。
preprocessImage(...)は次のようになります。
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } 上記のpreprocessImageでは、4つの前処理手法を画像に適用します。画像のドットを削除するblurARGB() 、画像の明るさを上げるdilate( dilate() 、画像の前景色と背景色を切り替えるinvertColors() 、 thresholdFilter()画像を白黒に変換します。これはTesseract変換により適しています。
thresholdFilter()は、 image.dataとlevelをパラメーターとして受け取ります。 levelは、画像の白または黒を設定するために使用されます。 Tesseractが優れた結果を生成するために画像がどの程度白、暗、または滑らかであるかわからないため、試行錯誤によってthresholdFilterレベルとblurRGB半径を決定しました。
テスト#3
4つの手法を適用した後の新しい結果は次のとおりです。

上の画像は、ChromeとFirefoxの両方で得られた結果を表しています。
おっと! 結果はひどいです。
4つのテクニックすべてを使用する代わりに、一度に2つだけを使用してみませんか?
うん! invertColorsとthresholdFilterの手法を使用して、画像を白黒に変換し、画像の前景と背景を切り替えることができます。 しかし、どのようなテクニックを組み合わせるのかをどうやって知るのでしょうか? 前処理したい画像の性質に基づいて、何を組み合わせるかがわかります。
たとえば、デジタル画像を白黒に変換し、パッチのある画像をぼかしてドット/パッチを削除する必要があります。 本当に重要なのは、それぞれのテクニックが何のために使われているのかを理解することです。
invertColorsとthresholdFilterを使用するには、 preprocessImageでblurARGBとdilateの両方をコメントアウトする必要があります。
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }テスト#4
さて、ここに新しい結果があります:

結果は、前処理なしの結果よりもさらに悪いです。 この特定の画像と他のいくつかの画像の各手法を調整した後、異なる性質の画像には異なる前処理手法が必要であるという結論に達しました。
つまり、画像の前処理なしでTesseract.jsを使用すると、上記のギフトカードで最良の結果が得られました。 画像の前処理を使用した他のすべての実験では、精度の低い結果が得られました。
問題
当初、AmazonギフトカードからPINを抽出したかったのですが、一貫性のある結果を得るために一貫性のないPINを照合する意味がないため、それを実現できませんでした。 正確なPINを取得するために画像を処理することは可能ですが、そのような前処理は、性質の異なる別の画像が使用されるまでに一貫性がなくなります。
生み出された最高の成果
下の画像は、実験によって得られた最良の結果を示しています。
テスト#5

画像のテキストと抽出されたテキストは完全に同じです。 変換の精度は100%です。 結果を再現しようとしましたが、似たような性質の画像を使用した場合にのみ再現できました。
観察と教訓
- 前処理されていない一部の画像は、ブラウザによって結果が異なる場合があります。 この主張は最初のテストで明らかです。 Firefoxでの結果はChromeでの結果とは異なります。 ただし、画像の前処理は、他のテストで一貫した結果を達成するのに役立ちます。
- 白い背景の黒い色は、扱いやすい結果をもたらす傾向があります。 以下の画像は、前処理なしの正確な結果の例です。 画像を前処理することで同じレベルの精度を得ることができましたが、多くの調整が必要であり、不要でした。
変換は100%正確です。
- フォントサイズが大きいテキストの方が正確になる傾向があります。
- エッジが湾曲しているフォントは、Tesseractを混乱させる傾向があります。 私が得た最高の結果は、Arial(フォント)を使用したときに達成されました。
- OCRは現在、特に80%を超えるレベルの精度が必要な場合、画像からテキストへの変換を自動化するには十分ではありません。 ただし、手動で修正するためにテキストを抽出することにより、画像上のテキストの手動処理のストレスを軽減するために使用できます。
- OCRは現在、アクセシビリティのためにスクリーンリーダーに有用な情報を渡すのに十分ではありません。 スクリーンリーダーに不正確な情報を提供すると、ユーザーを誤解させたり、気を散らしたりする可能性があります。
- OCRは、ニューラルネットワークによって学習と改善が可能になるため、非常に有望です。 ディープラーニングは、近い将来、OCRをゲームチェンジャーにするでしょう。
- 自信を持って意思決定する。 信頼スコアは、アプリケーションに大きな影響を与える可能性のある決定を行うために使用できます。 信頼スコアは、結果を受け入れるか拒否するかを決定するために使用できます。 私の経験と実験から、90未満の信頼スコアは実際には役に立たないことに気づきました。 テキストからいくつかのピンを抽出するだけでよい場合、75から100の間の信頼スコアが期待され、75未満のものはすべて拒否されます。
テキストの一部を抽出する必要なしにテキストを扱っている場合、私は間違いなく90から100の間の信頼スコアを受け入れますが、それ以下のスコアは拒否します。 たとえば、小切手や歴史的なドラフトなどのドキュメントをデジタル化したい場合、または正確なコピーが必要な場合は、90以上の精度が期待されます。 ただし、ギフトカードからPINを取得するなど、正確なコピーが重要でない場合は、75〜90のスコアを使用できます。 つまり、信頼スコアは、アプリケーションに影響を与える決定を下すのに役立ちます。
結論
画像上のテキストによって引き起こされるデータ処理の制限とそれに関連する欠点を考えると、光学式文字認識(OCR)は採用するのに便利なテクノロジーです。 OCRには限界がありますが、ニューラルネットワークを使用しているため非常に有望です。
時間の経過とともに、OCRはディープラーニングの助けを借りてその制限のほとんどを克服しますが、それ以前は、この記事で強調したアプローチを利用して、少なくとも画像からのテキスト抽出を処理し、手動に関連する困難と損失を減らすことができます処理—特にビジネスの観点から。
今度は、OCRを試して画像からテキストを抽出する番です。 幸運を!
参考文献
- P5.js
- OCRでの前処理
- 出力の品質を改善する
- JavaScriptを使用してOCR用の画像を前処理する
- Tesseract.jsを使用したブラウザのOCR
- 光学式文字認識の簡単な歴史
- OCRの未来はディープラーニングです
- 光学式文字認識のタイムライン