
CNNでの画像分類:知っておくべきことすべて
公開: 2021-02-25目次
序章
Facebookフィードを調べているときに、集合写真の人物がFacebookのソフトウェアによって自動的にラベル付けされる方法について疑問に思ったことはありませんか。 表示されるFacebookのすべてのインタラクティブユーザーインターフェイスの背後には、ソーシャルメディアプラットフォームにアップロードされた各画像を認識してラベルを付けるために使用される複雑で強力なアルゴリズムがあります。 私たちのすべての写真で、私たちはアルゴリズムの効率を改善するのを助けるだけです。 はい、画像分類は、人工知能の適用が見られる最も広く使用されているアルゴリズムの1つです。
最近では、畳み込みニューラルネットワーク(CNN)がディープラーニングの最も強力な支持者の1つになっています。 これらの畳み込みネットワークの一般的なアプリケーションの1つは、画像分類です。 このチュートリアルでは、畳み込みニューラルネットワークの基本を理解し、CNNモデルの構築に関連するさまざまなレイヤーを確認し、最後に画像分類タスクの例を視覚化します。
画像分類
ディープラーニングと畳み込みニューラルネットワークの詳細に入る前に、画像分類の基本を理解しましょう。 一般に、画像分類は、画像が属するクラスまたはクラスの確率を出力する特定のアルゴリズムを使用して構築されたモデルへの入力として画像を提供するタスクとして定義されます。 画像を特定のクラスにラベル付けするこのプロセスは、教師あり学習と呼ばれます。
私たちが画像を見る方法と、マシン(コンピューター)が同じ画像を見る方法には大きな違いがあります。 私たちにとって、私たちは画像を視覚化し、色とサイズに基づいてそれを特徴づけることができます。 一方、マシンにとっては、数字だけが表示されます。 見られる数字はピクセルと呼ばれます。
各ピクセルの値は0〜255です。したがって、これらの数値データを使用して、ある画像を別の画像と区別する特定のパターンまたは特徴を導出するために、マシンにはいくつかの前処理ステップが必要です。 畳み込みニューラルネットワークは、画像から特定のパターンを導き出すことができるアルゴリズムを構築するのに役立ちます。
私たちが見ているものとコンピューターが見ているもの
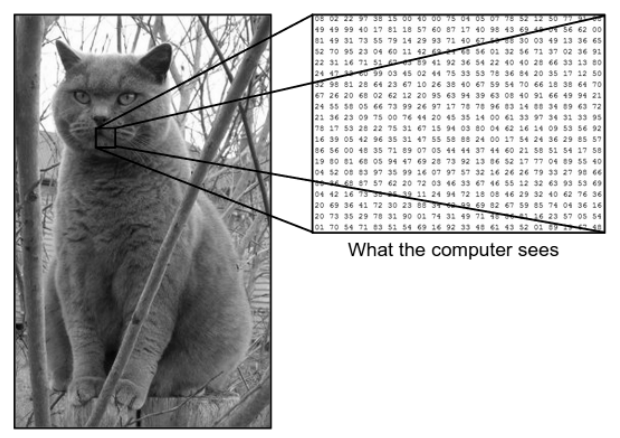 出典–コンピューターと人間の目の違い
出典–コンピューターと人間の目の違い

画像分類のための深層学習
画像分類とは何かを理解したので、人工知能を使用してそれを実装する方法を見てみましょう。 このために、人気のあるディープラーニング手法を使用します。 ディープラーニングは人工知能のサブセットであり、大きな画像データセットを利用してさまざまな画像からパターンを認識および導出し、画像データセットに存在するさまざまなクラスを区別します。
ディープラーニングが直面する主な課題は、巨大なデータベースの場合、非常に長い時間がかかり、計算コストが高くなることです。 ただし、ディープラーニングアルゴリズムの一種である畳み込みニューラルネットワークは、この問題にうまく対処します。
畳み込みニューラルネットワーク
ディープラーニングでは、畳み込みニューラルネットワークは主に視覚的イメージで使用されるディープニューラルネットワークのクラスです。 これらは、1998年にYann LeCunnによって提案された人工ニューラルネットワーク(ANN)の特別なアーキテクチャです。 畳み込みニューラルネットワークは2つの部分で構成されています。
最初の部分は、主な特徴抽出プロセスが行われる畳み込み層とプーリング層で構成されます。 2番目の部分では、完全接続層と高密度層が抽出された特徴に対していくつかの非線形変換を実行し、分類器部分として機能します。 画像分類のためのCNNを学びます。
上に示した、人間と機械が見るものの画像の例を考えてみましょう。 ご覧のとおり、コンピューターはピクセルの配列を認識しています。 たとえば、画像サイズが500×500の場合、配列のサイズは500x500x3になります。 ここで、500は各高さと幅を表し、3はRGBチャネルを表し、各カラーチャネルは個別の配列で表されます。 ピクセル強度は0から255まで変化します。
ここで画像分類のために、コンピュータは基本レベルで機能を探します。 人間としての私たちによると、猫のこれらの基本レベルの特徴は、耳、鼻、ひげです。 コンピューターの場合、これらの基本レベルの機能は曲率と境界です。 このように、畳み込み層やプーリング層などのいくつかの異なる層を使用することにより、コンピューターは画像から基本レベルの特徴を抽出します。
畳み込みニューラルネットワークモデルには、次のようないくつかのタイプのレイヤーがあります。
- 入力レイヤー
- 畳み込み層
- プーリングレイヤー
- 完全に接続されたレイヤー
- 出力層
- 活性化関数
画像分類でのアプリケーションに入る前に、各レイヤーについて簡単に説明します。
入力レイヤー
名前から、これが入力画像がCNNモデルに供給されるレイヤーであることがわかります。 要件に応じて、画像を(28,28,3)などのさまざまなサイズに再形成できます。
畳み込み層
次に、固定サイズのフィルター(カーネルとも呼ばれます)で構成される最も重要なレイヤーがあります。 畳み込みの数学演算は、入力画像とフィルターの間で実行されます。 これは、鋭いエッジや曲線などの基本的な特徴のほとんどが画像から抽出される段階であるため、このレイヤーは特徴抽出レイヤーとも呼ばれます。
プーリングレイヤー
畳み込み演算を実行した後、プーリング演算を実行します。 これは、画像の空間ボリュームが減少するダウンサンプリングとも呼ばれます。 たとえば、28×28のサイズの画像に対してストライド2のプーリング操作を実行すると、画像サイズは14×14に縮小され、元のサイズの半分に縮小されます。
完全に接続されたレイヤー
Fully Connected Layer(FC)は、CNNモデルの最終的な分類出力の直前に配置されます。 これらのレイヤーは、分類する前に結果をフラット化するために使用されます。 これには、いくつかのバイアス、重み、ニューロンが含まれます。 分類の前にFCレイヤーをアタッチすると、N次元ベクトルが生成されます。ここで、Nは、モデルがクラスを選択する必要があるクラスの数です。
出力層
最後に、出力レイヤーは、ほとんどがワンホットエンコード方式を使用してエンコードされたラベルで構成されます。
活性化関数
これらの活性化関数は、畳み込みニューラルネットワークモデルの中核です。 これらの関数は、ニューラルネットワークの出力を決定するために使用されます。 つまり、特定のニューロンをアクティブ化(「発火」)するかどうかを決定します。 これらは通常、入力信号に対して実行される非線形関数です。 この変換された出力は、入力としてニューロンの次の層に送信されます。 Sigmoid、ReLU、Leaky ReLU、TanH、Softmaxなどのいくつかの活性化関数があります。
基本的なCNNアーキテクチャ
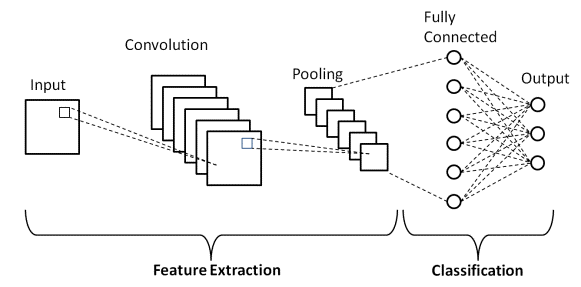
出典:基本的なCNNアーキテクチャ
前に定義したように、上に示した図は、畳み込みニューラルネットワークモデルの基本的なアーキテクチャです。 画像分類とCNNの基本の準備ができたので、リアルタイムの問題でそのアプリケーションに飛び込みましょう。 基本的なCNNアーキテクチャの詳細をご覧ください。
畳み込みニューラルネットワークの実装
画像分類と畳み込みニューラルネットワークの基本を理解したので、Pythonコーディングを使用したTensorFlow/Kerasでの実装を視覚化してみましょう。 ここでは、基本的なLeNetアーキテクチャを使用して単純な畳み込みニューラルネットワークモデルを構築し、トレーニングセットとテストセットでモデルをトレーニングし、最後にテストセットデータでモデルの精度を取得します。
問題セット
畳み込みニューラルネットワークモデルの構築とトレーニングに関するこの記事では、有名なファッションMNISTデータセットを使用します。 MNISTは、米国国立標準技術研究所の略です。 Fashion-MNISTは、Zalandoの記事画像のデータセットであり、60,000の例のトレーニングセットと10,000の例のテストセットで構成されています。 各例は、10クラスのラベルに関連付けられた28×28のグレースケール画像です。
各トレーニングとテストの例は、次のラベルのいずれかに割り当てられています。
0 –Tシャツ/トップ
1 –ズボン
2 –プルオーバー
3 –ドレス
4 –コート
5 –サンダル
6 –シャツ
7 –スニーカー
8 –バッグ
9 –アンクルブーツ

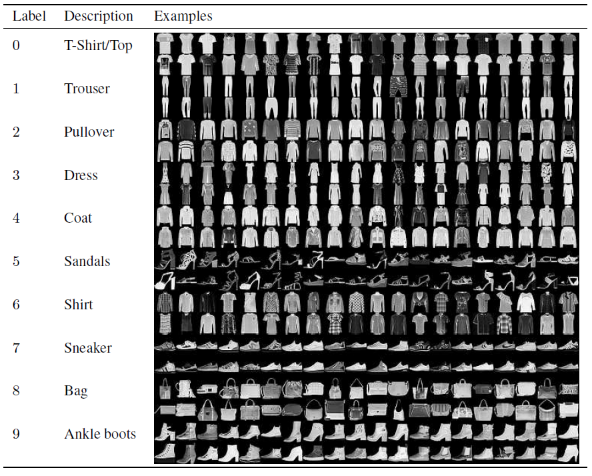
出典:FashionMNISTデータセット画像
プログラムコード
ステップ1-ライブラリのインポート
ディープラーニングモデルを構築するための最初のステップは、プログラムに必要なライブラリをインポートすることです。 この例では、TensorFlowフレームワークを使用しているため、Kerasライブラリと、計算用の数値やプロットをプロットするためのmatplotlibなどの他の重要なライブラリもインポートします。
#TensorFlow –ライブラリのインポート
numpyをnpとしてインポートします
matplotlib.pyplotをpltとしてインポートします
%matplotlibインライン
tensorflowをtfとしてインポートします
tensorflowからインポートKeras
ステップ2–データセットの取得と分割
ライブラリをインポートしたら、次のステップはデータセットをダウンロードし、FashionMNISTデータセットをそれぞれの60,000のトレーニングデータと10,000のテストデータに分割することです。 幸い、kerasには、Fashion MNISTデータセットをインポートするための事前定義された関数が用意されており、自己理解型の単純なコード行を使用して、次の行に分割できます。
#TensorFlow –データセットの取得と分割
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf、train_labels_tf)、(test_images_tf、test_labels_tf)= fashion_mnist.load_data()
ステップ3–データの視覚化
データセットは画像とそれに対応するラベルとともにダウンロードされるため、ユーザーがわかりやすくするために、畳み込みニューラルネットワークの構築で扱っているデータの種類を理解できるように、常にデータを表示することをお勧めします。それに応じてネットワークモデル。 ここでは、以下に示すこの単純なコードブロックを使用して、ランダムにシャッフルされたトレーニングデータセットの最初の3つの画像を視覚化します。
#TensorFlow –データの視覚化
def imshowTensorFlow(img):
plt.imshow(img、cmap ='gray')
print(“ Label:”、img [0])
imshowTensorFlow(train_images_tf [0])
ラベル:9ラベル:0ラベル:3
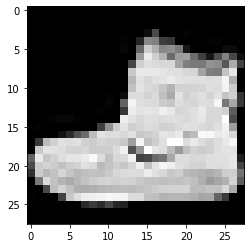


上記の画像とそのラベルは、上記のFashionMNISTデータセットの詳細に記載されているラベルで確認できます。 このことから、データ画像は高さ28ピクセル、幅28ピクセルのグレースケール画像であると推測されます。
したがって、モデルは(28,28,1)の入力サイズで構築できます。ここで、1はグレースケール画像を表します。
ステップ4–モデルの構築
前述のように、この記事では、LeNetアーキテクチャを使用して単純な畳み込みニューラルネットワークを構築します。 LeNetは、Yann LeCunetalによって提案された畳み込みニューラルネットワーク構造です。 一般に、LeNetはLeNet-5を指し、単純な畳み込みニューラルネットワークです。
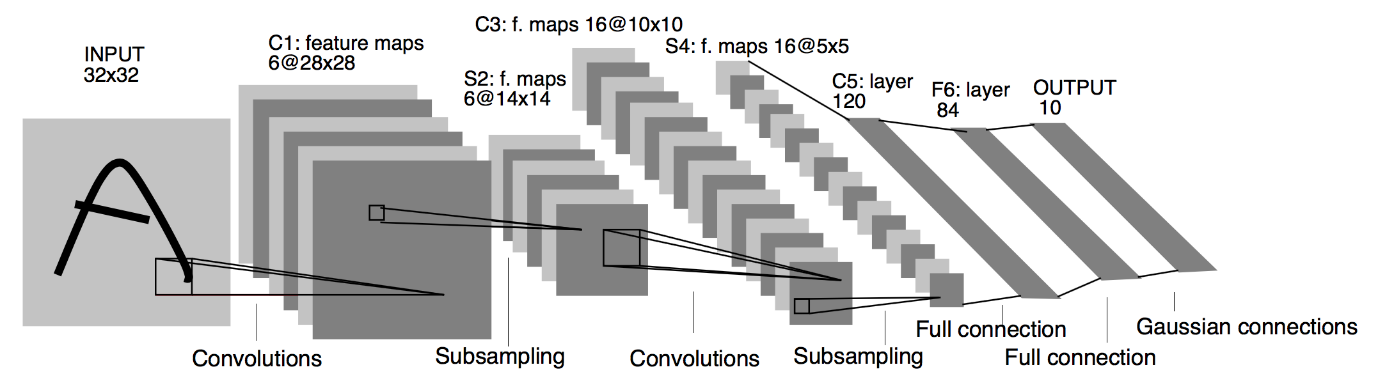
出典:LeNetアーキテクチャ
上記のLeNetCNNモデルのアーキテクチャ図から、5+2層があることがわかります。 第1層と第2層は、畳み込み層とそれに続くプーリング層です。 この場合も、3番目と4番目の層は畳み込み層とプーリング層で構成されます。 これらの操作の結果、28×28からの入力画像のサイズは7×7に減少します。
LeNetモデルの5番目のレイヤーは、前のレイヤーの出力をフラット化する完全接続レイヤーです。 2つの高密度層が続くCNNモデルの最終出力層は、10ユニットのSoftmax活性化関数で構成されています。 Softmax関数は、FashionMNISTデータセットの10個のクラスのそれぞれのクラス確率を予測します。
#TensorFlow –モデルの構築
model = keras.Sequential([
keras.layers.Conv2D(input_shape =(28,28,1)、filters = 6、kernel_size = 5、strides = 1、padding =” same”、activation = tf.nn.relu)、
keras.layers.AveragePooling2D(pool_size = 2、strides = 2)、
keras.layers.Conv2D(16、kernel_size = 5、strides = 1、padding =” same”、activation = tf.nn.relu)、
keras.layers.AveragePooling2D(pool_size = 2、strides = 2)、
keras.layers.Flatten()、
keras.layers.Dense(120、activation = tf.nn.relu)、
keras.layers.Dense(84、activation = tf.nn.relu)、
keras.layers.Dense(10、activation = tf.nn.softmax)
])
ステップ5–モデルの概要
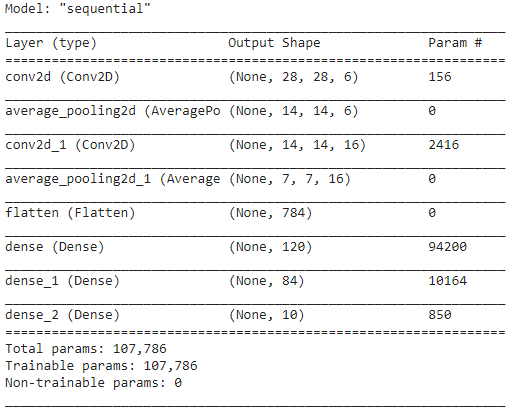
LeNetモデルのレイヤーが完成したら、モデルのコンパイルに進み、設計されたCNNモデルの要約バージョンを表示できます。
#TensorFlow –モデルの概要
model.compile(loss = keras.losses.categorical_crossentropy、
オプティマイザー='adam'、
メトリック=['acc'])
model.summary()
この場合、最終出力には2つ以上のクラス(10クラス)があるため、損失関数としてカテゴリクロスエントロピーを使用し、構築したモデルにAdamOptimizerを使用します。 モデルの概要を以下に示します。
ステップ6–モデルのトレーニング
最後に、LeNetCNNモデルのトレーニングプロセスを開始する部分に到達します。 まず、トレーニングデータセットを再形成し、255.0で除算して計算コストを削減することにより、より小さな値に正規化します。 次に、トレーニングラベルが整数クラスベクトルからバイナリクラス行列に変換されます。 たとえば、ラベル3は[0、0、0、1、0、0、0、0、0]に変換されます
#TensorFlow –モデルのトレーニング
train_images_tensorflow =(train_images_tf / 255.0).reshape(train_images_tf.shape [0]、28、28、1)
test_images_tensorflow =(test_images_tf / 255.0).reshape(test_images_tf.shape [0]、28、28、1)
train_labels_tensorflow = keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow = keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow、train_labels_tensorflow、epochs = 30、batch_size = 32)
30エポック後のトレーニングの最後に、最終的なトレーニングの精度と損失を次のように取得します。
エポック30/30
1875/1875 [==============================] –4秒2ms/ステップ–損失:0.0421 – acc:0.9850
トレーニング精度:98.294997215271%
トレーニング損失:0.04584110900759697
ステップ7–結果の予測
最後に、CNNモデルのトレーニングプロセスが完了したら、同じモデルをテストデータセットに適合させ、10,000個のテスト画像の精度を予測します。
#TensorFlow –結果の比較
予測=model.predict(test_images_tensorflow)
正しい=0
iの場合、enumerate(predictions)でpred:
np.argmax(pred)== test_labels_tf [i]の場合:
正しい+=1
print('{}テスト画像でのモデルのテスト精度:{}%with TensorFlow'.format(test_images_tf.shape [0]、100 *correct / test_images_tf.shape [0]))
得られる出力は、
10000個のテスト画像でのモデルのテスト精度:TensorFlowで90.67%
これで、畳み込みニューラルネットワークを使用した画像分類モデルの構築に関するプログラムは終了です。
また読む:機械学習プロジェクトのアイデア
結論
したがって、CNNでの画像分類の実装に関するこのチュートリアルでは、画像分類、畳み込みニューラルネットワークの背後にある基本的な概念と、TensorFlowフレームワークを使用したPythonプログラミング言語での実装について理解しました。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのPGディプロマをご覧ください。これは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIIT-を提供します。 B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。
画像分類に最適と考えられるCNNモデルはどれですか?
画像分類に最適なCNNモデルはVGG-16です。これは、大規模画像認識のための非常に深い畳み込みネットワークの略です。 ディープCNNとして設計されたVGGは、ImageNet以外のさまざまなタスクやデータセットでベースラインを上回っています。 モデルの際立った特徴は、モデルが作成されたときに、多数のハイパーパラメーターの追加に焦点を合わせるのではなく、優れた畳み込みレイヤーを組み込むことに重点が置かれたことです。 合計16層、5ブロックで、各ブロックには最大のプーリング層があり、非常に大規模なネットワークになっています。
画像分類にCNNモデルを使用することの欠点は何ですか?
画像分類に関しては、CNNモデルは非常に成功しています。 ただし、CNNを使用することにはいくつかの欠点があります。 識別される画像が傾斜または回転している場合、CNNモデルでは画像を正確に識別するのに問題があります。 CNNが画像を視覚化する場合、コンポーネントとその部分全体の接続の内部表現はありません。 さらに、使用するCNNモデルに多数の畳み込み層が含まれている場合、分類プロセスに長い時間がかかります。
入力としての画像データにANNよりもCNNモデルの使用が好まれるのはなぜですか?
フィルタまたは変換を組み合わせることにより、CNNは、入力として提供されるすべての画像の特徴表現の多くのレイヤーを学習できます。 CNNで学習するネットワークのパラメーターの数が多層ニューラルネットワークよりも大幅に少ないため、過剰適合が減少します。 ANNを使用する場合、ニューラルネットワークは画像の単一の特徴表現を学習できますが、複雑な画像の場合、入力画像に存在するピクセル依存性を学習できないため、ANNは改善された視覚化または分類を提供できません。