
機械学習で分類を実装する方法は?
公開: 2021-03-12さまざまな分野での機械学習の適用は、過去数年間で飛躍的に増加しており、それは継続しています。 機械学習モデルで最も一般的なタスクの1つは、オブジェクトを認識し、それらを指定されたクラスに分離することです。
これは、機械学習の最も一般的なアプリケーションの1つである分類方法です。 分類は、大量のデータを、0/1、Yes / Noなどのバイナリ、または動物、車、鳥などのマルチクラスの離散値のセットに分離するために使用されます。
次の記事では、機械学習における分類の概念、関連するデータの種類を理解し、機械学習でいくつかのデータを分類するために使用される最も一般的な分類アルゴリズムのいくつかを見ていきます。
目次
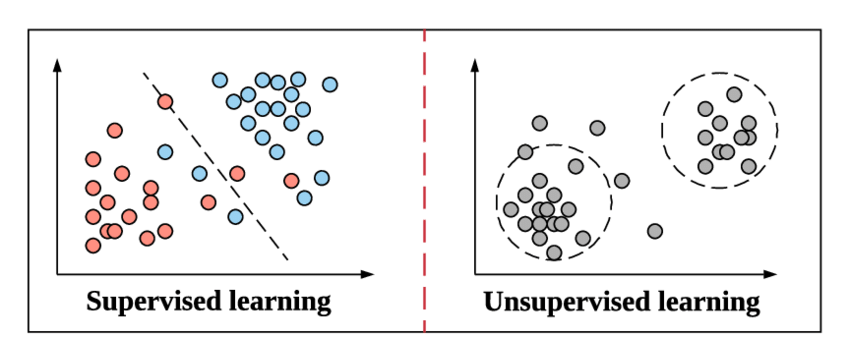
教師あり学習とは何ですか?
分類とそのタイプの概念に飛び込む準備ができているので、教師あり学習の意味と、それが機械学習における他の教師なし学習の方法とどのように異なるかについて、すぐにリフレッシュしましょう。
高校の物理学の授業で簡単な例を挙げて、これを理解しましょう。 新しいメソッドに関連する単純な問題があるとします。 同じ方法で解かなければならない質問が出てきたら、同じ方法で問題の例を参考にして解いてみませんか。 その方法に自信が持てたら、もう一度参照して解決を続ける必要はありません。
ソース

これは、教師あり学習が機械学習で機能するのと同じ方法です。 例によって学習します。 さらに簡単にするために、教師あり学習では、データ全体に対応するラベルが提供されるため、トレーニングプロセス中に、機械学習モデルは特定のデータの出力を同じデータの実際の出力と比較し、次のことを試みます。予測されたラベル値と実際のラベル値の両方の間の誤差を最小限に抑えます。
この記事で説明する分類アルゴリズムは、この教師あり学習の方法(たとえば、スパム検出やオブジェクト認識)に従います。
教師なし学習は、データにラベルが付けられていない上記のステップです。 データからパターンを導き出し、出力を提供するのは、機械学習モデルの責任と効率次第です。 クラスタリングアルゴリズムは、この教師なし学習方法に従います。
分類とは何ですか?
分類は、オブジェクトまたはデータを認識、理解、および事前設定されたクラスにグループ化することとして定義されます。 機械学習モデルのトレーニングプロセスの前にデータを分類することで、さまざまな分類アルゴリズムを使用してデータをいくつかのクラスに分類できます。 回帰とは異なり、分類の問題は、出力変数が「はい」、「いいえ」、「病気」、「病気なし」などのカテゴリである場合に発生します。
ほとんどの機械学習の問題では、データセットがプログラムに読み込まれると、トレーニングの前に、データセットをトレーニングセットと固定比率のテストセット(通常は70%のトレーニングセットと30%のテストセット)に分割します。 この分割プロセスにより、モデルはバックプロパゲーションを実行できます。バックプロパゲーションでは、いくつかの数学的近似によって、予測値の誤差を真の値に対して修正しようとします。
同様に、分類を開始する前に、トレーニングデータセットが作成されます。 分類アルゴリズムは、エポックと呼ばれる反復ごとにテストデータセットでテストしながら、トレーニングを受けます。
ソース
最も一般的な分類アルゴリズムアプリケーションの1つは、電子メールが「スパム」であるか「非スパム」であるかをフィルタリングすることです。 つまり、機械学習の分類は、トレーニングデータに適用されるこれらのアルゴリズムを使用して、データからいくつかのパターン(類似した単語や番号のシーケンス、感情など)を抽出する「パターン認識」の形式として定義できます。 。)。
分類は、特定のデータセットをクラスに分類するプロセスです。 構造化データと非構造化データの両方で実行できます。 それは、与えられたデータポイントのクラスを予測することから始まります。 これらのクラスは、出力変数、ターゲットラベルなどとも呼ばれます。いくつかのアルゴリズムには、入力データポイント変数から出力ターゲットクラスへのマッピング関数を近似する数学関数が組み込まれています。 分類の主な目標は、新しいデータがどのクラス/カテゴリに分類されるかを特定することです。
機械学習における分類アルゴリズムの種類
分類アルゴリズムが適用されるデータのタイプに応じて、アルゴリズムには線形モデルと非線形モデルの2つの大きなカテゴリがあります。
線形モデル
- ロジスティック回帰
- サポートベクターマシン(SVM)
非線形モデル
- K最近傍(KNN)分類
- カーネルSVM
- 単純ベイズ分類
- デシジョンツリー分類
- ランダムフォレスト分類
この記事では、上記の各アルゴリズムの背後にある概念について簡単に説明します。
機械学習における分類モデルの評価
上記のこれらのアルゴリズムの概念に飛び込む前に、これらのアルゴリズムの上に構築された機械学習モデルを評価する方法を理解する必要があります。 トレーニングセットとテストセットの両方でモデルの精度を評価することが不可欠です。
クロスエントロピー損失または対数損失
これは、出力が0〜1の分類器のパフォーマンスを評価する際に使用する最初のタイプの損失関数です。これは主に二項分類モデルに使用されます。 対数損失の式は、次の式で与えられます。
対数損失=-((1 – y)* log(1 – yhat)+ y * log(yhat))
ここで、それは予測値であり、yは実際の値です。
混同行列
混同行列はNXN行列です。ここで、Nは予測されるクラスの数です。 混同行列は、出力として行列/テーブルを提供し、モデルのパフォーマンスを記述します。 これは、分類モデルを評価するためのいくつかのパフォーマンスメトリックを導出できるマトリックスの形式の予測結果で構成されます。 それは形です、
| 実際のポジティブ | 実際のネガティブ | |
| 予測されるポジティブ | トゥルーポジティブ | 誤検知 |
| 予測されるネガティブ | 偽陰性 | 真のネガティブ |
上記の表から導き出せるパフォーマンスメトリックのいくつかを以下に示します。
1.精度–正しい予測の総数の割合。
2.正の予測値または精度–正しく識別された正のケースの割合。
3.ネガティブ予測値–正しく識別されたネガティブケースの割合。
4.感度または想起–正しく識別された実際の陽性症例の割合。
5.特異性–正しく識別された実際のネガティブケースの割合。
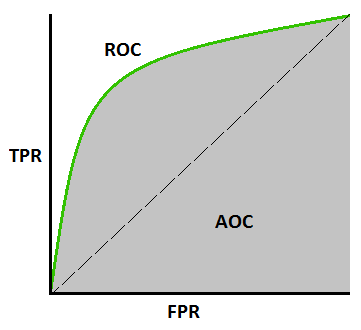
AUC-ROC曲線–
これは、機械学習モデルを評価するもう1つの重要な曲線指標です。 ROC曲線は受信者動作特性曲線を表し、AUCは曲線下面積を表します。 ROC曲線は、TPRとFPRでプロットされます。ここで、TPR(真陽性率)はY軸に、FPR(偽陽性率)はX軸に示されています。 これは、さまざまなしきい値での分類モデルのパフォーマンスを示しています。
ソース
1.ロジスティック回帰
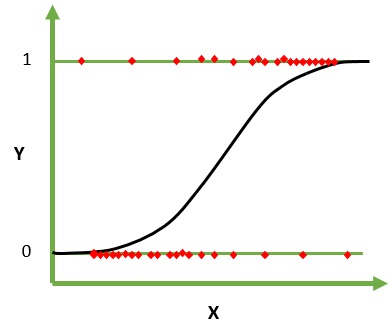
ロジスティック回帰は、分類のための機械学習アルゴリズムです。 このアルゴリズムでは、単一の試行の可能な結果を表す確率がロジスティック関数を使用してモデル化されます。 入力変数が数値であり、ガウス(ベル曲線)分布であると想定しています。
シグモイド関数とも呼ばれるロジスティック関数は、当初、生態学における人口増加を説明するために統計家によって使用されていました。 シグモイド関数は、予測値を確率にマッピングするために使用される数学関数です。 ロジスティック回帰にはS字型の曲線があり、0〜1の値を取ることができますが、これらの制限に正確に達することはありません。
ソース

ロジスティック回帰は、主に、はい/いいえや合格/不合格などのバイナリ結果を予測するために使用されます。 独立変数はカテゴリ変数または数値変数にすることができますが、従属変数は常にカテゴリ変数です。 ロジスティック回帰の式は、次の式で与えられます。
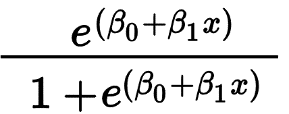
ここで、eは0から1の間の値を持つS字型の曲線を表します。
2.サポートベクターマシン
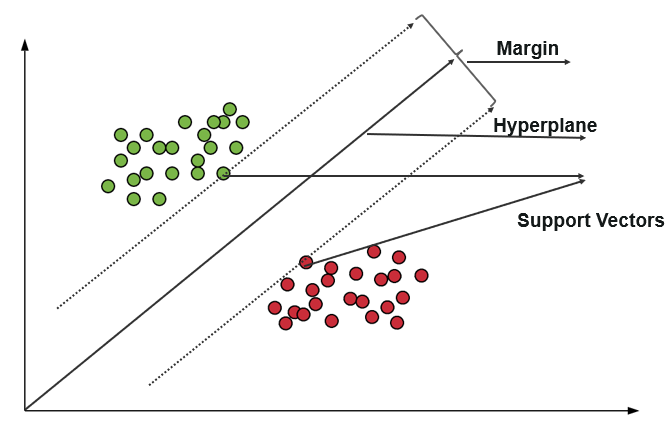
サポートベクターマシン(SVM)は、アルゴリズムを使用して、極性の程度内でデータをトレーニングおよび分類し、X/Y予測を超える程度までデータを取得します。 SVMでは、クラスを分離するために使用される線は超平面と呼ばれます。 超平面に最も近い超平面の両側のデータポイントは、境界線をプロットするために使用されるサポートベクターと呼ばれます。
この分類のサポートベクターマシンは、トレーニングデータを、多くのカテゴリが超平面カテゴリに分割されている空間内のデータポイントとして表します。 新しいポイントが入ると、それらがどのカテゴリに分類され、特定のスペースに属するかを予測することによって分類されます。
ソース
サポートベクターマシンの主な目的は、2つのサポートベクター間のマージンを最大化することです。
世界のトップ大学(修士、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインでMLコースに参加して、キャリアを早急に進めましょう。
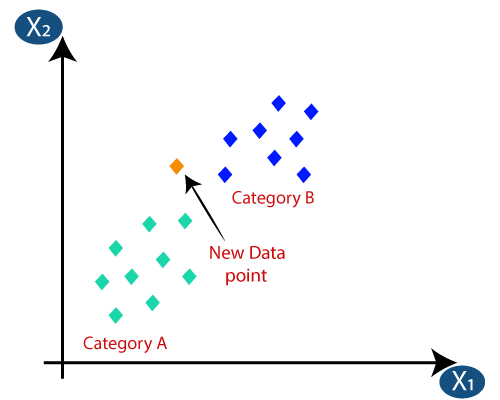
3. K最近傍(KNN)分類
KNN分類は、分類の最も単純なアルゴリズムの1つですが、効率が高く、使いやすいため、非常に使用されています。 この方法では、データセット全体が最初にマシンに保存されます。 次に、ネイバーの数を表す値–kが選択されます。 このようにして、新しいデータポイントがデータセットに追加されると、その新しいデータポイントに最も近いk個のクラスラベルの多数決が行われます。 この投票により、投票数が最も多い特定のクラスに新しいデータポイントが追加されます。
ソース
4.カーネルSVM
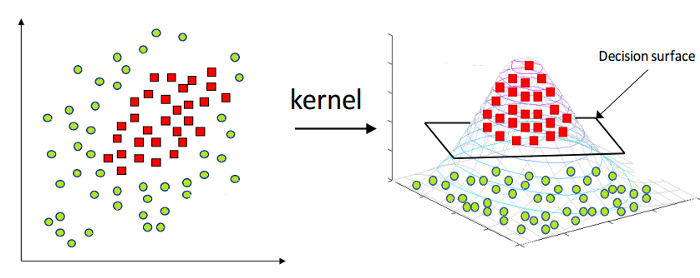
上記のように、線形サポートベクターマシンは、本質的に線形データにのみ適用できます。 ただし、世界中のすべてのデータを線形分離可能というわけではありません。 したがって、非線形分離可能でもあるデータを考慮して、サポートベクターマシンを開発する必要があります。 ここに、カーネルサポートベクターマシンまたはカーネルSVMとしても知られるカーネルトリックがあります。
カーネルSVMでは、RBFやガウスカーネルなどのカーネルを選択します。 すべてのデータポイントはより高い次元にマッピングされ、線形分離可能になります。 このようにして、データセットの異なるクラス間に決定境界を作成できます。
ソース
したがって、このように、サポートベクターマシンの基本概念を使用して、非線形のカーネルSVMを設計できます。
5.単純ベイズ分類
ナイーブベイズ分類は、データセットのすべての独立変数(特徴)が独立していると仮定して、ベイズの定理に属するルーツを持っています。 それらは、結果を予測する上で同等の重要性を持っています。 ベイズの定理のこの仮定は、「ナイーブ」という名前を与えます。 スパムフィルタリングやその他のテキスト分類領域など、さまざまなタスクに使用されます。 Naive Bayesは、データポイントが特定のカテゴリに属するかどうかの可能性を計算します。
単純ベイズ分類の公式は、次の式で与えられます。
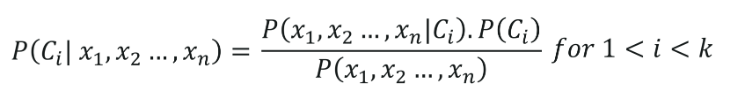
6.ディシジョンツリーの分類
決定木は、クラスを正確なレベルで順序付けることができるため、分類問題に最適な教師あり学習アルゴリズムです。 フローチャートの形式で動作し、各レベルでデータポイントを分離します。 最終的な構造は、ノードと葉を持つツリーのように見えます。

ソース
決定ノードには2つ以上のブランチがあり、リーフは分類または決定を表します。 上記のディシジョンツリーの例では、いくつかの質問をすることでフローチャートが作成され、市場に行くかどうかを予測するという単純な問題を解決するのに役立ちます。
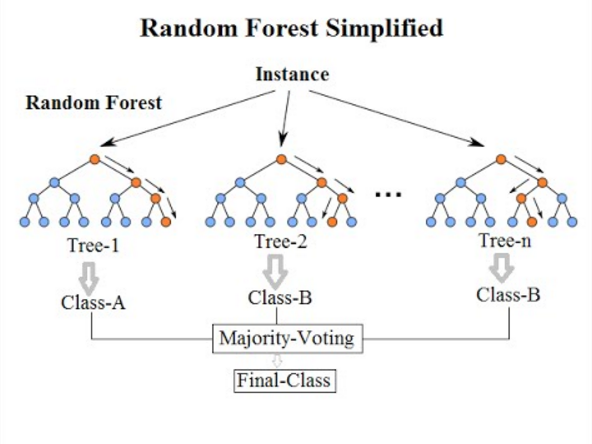
7.ランダムフォレスト分類
このリストの最後の分類アルゴリズムになると、ランダムフォレストはディシジョンツリーアルゴリズムの拡張にすぎません。 ランダムフォレストは、複数の決定木を使用したアンサンブル学習方法です。 デシジョンツリーと同じように機能します。
ソース
ランダムフォレストアルゴリズムは、「過剰適合」という大きな問題に悩まされている既存のディシジョンツリーアルゴリズムの進歩です。 また、ディシジョンツリーアルゴリズムと比較して、より高速で正確であると見なされます。
また読む:機械学習プロジェクトのアイデアとトピック
結論
したがって、分類のための機械学習方法に関するこの記事では、分類の基本と教師あり学習、分類モデルのタイプと評価の指標、そして最後に、最も一般的に使用されるすべての分類モデルの機械学習の概要を理解しました。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのエグゼクティブPGプログラムをご覧ください。このプログラムは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIITを提供しています。 -B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との雇用支援。
Q1。 機械学習で最も使用されているアルゴリズムは何ですか?
機械学習は多くの異なるアルゴリズムを採用しており、教師あり学習アルゴリズム、教師なし学習アルゴリズム、強化学習アルゴリズムの3つの主要な種類に大きく分類できます。 ここで、最も一般的に使用されるアルゴリズムのいくつかを絞り込んで名前を付けるために、言及する必要があるのは、線形回帰、ロジスティック回帰、SVM、決定ツリー、ランダムフォレストアルゴリズム、kNN、ナイーブベイズ理論、K-Means、次元削減、勾配ブースティングアルゴリズム。 XGBoost、GBM、LightGBM、およびCatBoostアルゴリズムは、勾配ブースティングアルゴリズムで特に言及する価値があります。 これらのアルゴリズムは、ほぼすべての種類のデータ問題を解決するために適用できます。
Q2。 機械学習における分類と回帰とは何ですか?
分類アルゴリズムと回帰アルゴリズムの両方が、機械学習で広く使用されています。 ただし、それらの間には多くの違いがあり、最終的にはそれらの使用または目的を決定します。 主な違いは、分類アルゴリズムを使用して男性-女性や真偽などの離散値を分類または予測するのに対し、回帰アルゴリズムは、給与、年齢、価格などの非離散の連続値を予測するために使用されることです。ランダムフォレスト、カーネルSVM、およびロジスティック回帰は最も一般的な分類アルゴリズムの一部ですが、単純および多重線形回帰、サポートベクトル回帰、多項式回帰、および決定ツリー回帰は、機械学習で使用される最も一般的な回帰アルゴリズムの一部です。
Q3。 機械学習を学習するための前提条件は何ですか?
機械学習を始めるには、熟練した数学者やエキスパートプログラマーである必要はありません。 ただし、この分野の広大さを考えると、機械学習の旅を始めようとしているときは、恐ろしいと感じることがあります。 このような場合、前提条件を知っていると、スムーズに開始できます。 前提条件は、基本的に、機械学習の概念を理解するために習得する必要のあるコアスキルです。 したがって、何よりもまず、Pythonを使用してコーディングする方法を学ぶようにしてください。 次に、統計と数学、特に線形代数と多変数微積分の基本的な理解が追加の利点になります。