
機械学習の特徴選択方法の選択方法
公開: 2021-06-22目次
特徴選択の紹介
多くの機能が機械学習モデルで使用されていますが、重要なのはそのうちのいくつかだけです。 データモデルのトレーニングに不要な機能が使用されている場合、モデルの精度が低下します。 さらに、モデルの複雑さが増し、一般化機能が低下して、モデルに偏りが生じます。 「時々少ない方が良い」ということわざは、機械学習の概念によく合います。 この問題は、データから関連する機能のセットを識別し、関連性のない機能のセットをすべて無視することが難しいと感じる多くのユーザーが直面しています。 重要度の低い機能は、ターゲット変数に寄与しないため、これらの機能と呼ばれます。
したがって、重要なプロセスの1つは、機械学習での特徴選択です。 目標は、機械学習モデルの開発に最適な機能セットを選択することです。 特徴選択によってモデルのパフォーマンスに大きな影響があります。 データクリーニングとともに、特徴選択はモデル設計の最初のステップである必要があります。
機械学習での特徴選択は、次のように要約できます。
- 予測変数または出力に最も貢献している機能の自動または手動選択。
- 関連性のない機能が存在すると、モデルが関連性のない機能から学習するため、モデルの精度が低下する可能性があります。
特徴選択の利点
- データの過剰適合を減らします。データの数が少ないほど、冗長性が低くなります。 したがって、ノイズについて決定を下す可能性は少なくなります。
- モデルの精度が向上します。データを誤解させる可能性が低くなるため、モデルの精度が向上します。
- トレーニング時間が短縮されます。関係のない機能を削除すると、存在するデータポイントが少なくなるため、アルゴリズムの複雑さが軽減されます。 したがって、アルゴリズムはより高速にトレーニングされます。
- データの解釈が改善されると、モデルの複雑さが軽減されます。
特徴選択の監視ありおよび監視なしの方法
特徴選択アルゴリズムの主な目的は、モデルの開発に最適な特徴のセットを選択することです。 機械学習の特徴選択方法は、教師あり方法と教師なし方法に分類できます。
- 教師あり法:教師あり法は、ラベル付けされたデータから特徴を選択するために使用され、関連する特徴の分類にも使用されます。 したがって、構築されたモデルの効率が向上します。
- 教師なし方法:この特徴選択の方法は、ラベルのないデータに使用されます。
監視対象メソッドのメソッドのリスト
機械学習における特徴選択の教師あり方法は、次のように分類できます。

1.ラッパーメソッド
このタイプの特徴選択アルゴリズムは、アルゴリズムの結果に基づいて特徴のパフォーマンスのプロセスを評価します。 欲張りアルゴリズムとも呼ばれ、特徴のサブセットを繰り返し使用してアルゴリズムをトレーニングします。 停止基準は通常、アルゴリズムをトレーニングする人によって定義されます。 モデルの機能の追加と削除は、モデルの事前のトレーニングに基づいて行われます。 この検索戦略では、あらゆるタイプの学習アルゴリズムを適用できます。 モデルは、フィルター方式と比較してより正確です。
ラッパーメソッドで使用される手法は次のとおりです。
- フォワードセレクション:フォワードセレクションプロセスは、モデルを改善する新しい機能が各反復後に追加される反復プロセスです。 それは機能の空のセットから始まります。 モデルのパフォーマンスをさらに向上させない機能が追加されるまで、反復は継続して停止します。
- 後方選択/排除:このプロセスは、すべての機能から始まる反復プロセスです。 各反復の後、重要度が最も低い機能が初期機能のセットから削除されます。 反復の停止基準は、機能を削除してもモデルのパフォーマンスがそれ以上向上しない場合です。 これらのアルゴリズムは、mlxtendパッケージに実装されています。
- 双方向除去:順方向選択と逆方向除去の両方の手法が双方向除去法に同時に適用され、 1つの固有のソリューションに到達します。
- 徹底的な特徴選択:特徴サブセットを評価するためのブルートフォースアプローチとしても知られています。 可能なサブセットのセットが作成され、サブセットごとに学習アルゴリズムが構築されます。 そのサブセットが選択され、そのモデルが最高のパフォーマンスを発揮します。
- 再帰的機能除去(RFE):この方法は、機能のセットがどんどん小さくなっていくことを再帰的に考慮して機能を選択するため、貪欲と呼ばれます。 特徴の初期セットは推定器のトレーニングに使用され、それらの重要性はfeature_importance_attributeを使用して取得されます。 次に、重要度の最も低い機能を削除して、必要な数の機能のみを残します。 アルゴリズムはscikit-learnパッケージに実装されています。
図4:再帰的な特徴除去手法を示すコードの例
2.埋め込みメソッド
機械学習に組み込まれた特徴選択方法には、特徴の相互作用を含め、妥当な計算コストを維持することにより、フィルターやラッパーの方法に比べて一定の利点があります。 埋め込みメソッドで使用される手法は次のとおりです。
- 正則化:モデルのパラメーターにペナルティを追加することにより、モデルによるデータの過剰適合が回避されます。 係数はペナルティとともに追加され、一部の係数はゼロになります。 したがって、係数がゼロの機能は、機能のセットから削除されます。 特徴選択のアプローチでは、Lasso(L1正則化)とElasticネット(L1およびL2正則化)を使用します。
- SMLR(スパース多項ロジット回帰):アルゴリズムは、古典的な多項ロジット回帰のARD事前(自動関連性決定)によるスパース正則化を実装します。 この正則化は、各特徴の重要性を推定し、予測に役立たない次元を削除します。 アルゴリズムの実装はSMLRで行われます。
- ARD(自動関連性決定回帰):アルゴリズムは係数の重みをゼロに向かってシフトし、ベイズリッジ回帰に基づいています。 アルゴリズムはscikit-learnで実装できます。
- ランダムフォレストの重要性:この特徴選択アルゴリズムは、指定された数のツリーの集約です。 このアルゴリズムのツリーベースの戦略は、ノードの不純物を増やすか、不純物(Gini不純物)を減らすことに基づいてランク付けされます。 ツリーの終わりは、不純物の減少が最も少ないノードで構成され、ツリーの開始は、不純物の減少が最も大きいノードで構成されます。 したがって、特定のノードの下にあるツリーを剪定することで、重要な機能を選択できます。
3.フィルターメソッド
メソッドは、前処理ステップ中に適用されます。 この方法は非常に高速で安価であり、重複した、相関した、冗長な機能を削除するのに最適です。 教師あり学習方法を適用する代わりに、機能の重要性が固有の特性に基づいて評価されます。 アルゴリズムの計算コストは、特徴選択のラッパーメソッドと比較して低くなります。 ただし、特徴間の統計的相関を導き出すのに十分なデータが存在しない場合、結果はラッパーメソッドよりも悪い可能性があります。 したがって、アルゴリズムは高次元データに対して使用され、ラッパーメソッドを適用する場合は計算コストが高くなります。

Filterメソッドで使用される手法は次のとおりです。
- 情報ゲイン:情報ゲインとは、ターゲット値を特定するために機能から取得される情報の量を指します。 次に、エントロピー値の減少を測定します。 各属性の情報ゲインは、特徴選択の目標値を考慮して計算されます。
- カイ二乗検定:カイ二乗法(X 2 )は、通常、2つのカテゴリ変数間の関係を検定するために使用されます。 このテストは、データセットのさまざまな属性からの観測値と期待値の間に有意差があるかどうかを識別するために使用されます。 帰無仮説は、2つの変数間に関連性がないことを示しています。
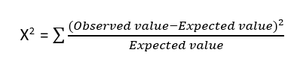
ソース
カイ二乗検定の式
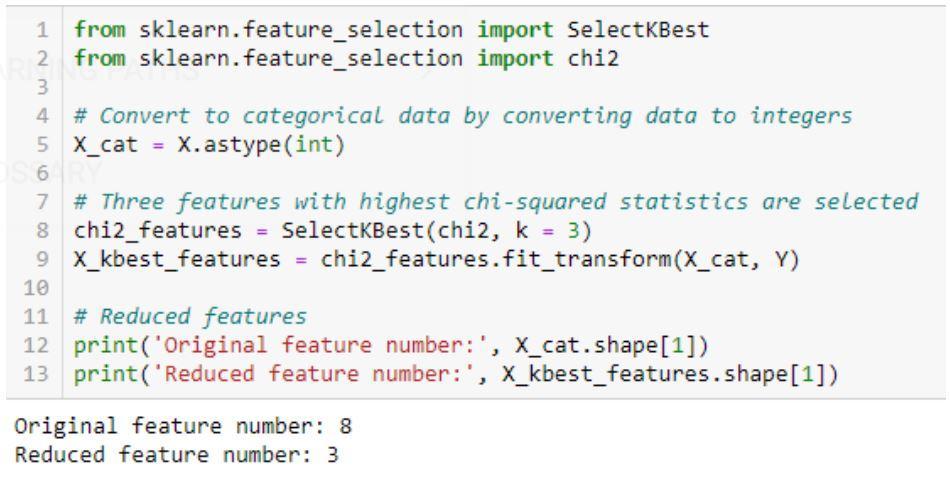
カイ二乗アルゴリズムの実装:sklearn、scipy
カイ二乗検定のコード例
ソース
- CFS(相関ベースの特徴選択):この方法は、「CFS(相関ベースの特徴選択)の実装:scikit-feature
世界のトップ大学(修士、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインでAI&MLコースに参加して、キャリアを早急に進めましょう。
- FCBF(高速相関ベースのフィルター):上記の救済およびCFSの方法と比較して、FCBFの方法はより高速で効率的です。 最初に、対称不確実性の計算がすべての機能に対して実行されます。 これらの基準を使用して、機能が分類され、冗長な機能が削除されます。
対称的な不確実性=xの情報ゲイン| yをそれらのエントロピーの合計で割ったもの。 FCBFの実装:skfeature
- フィッシャースコア:フィッシャー比率(FIR)は、特徴ごとの各クラスのサンプル平均間の距離を分散で割ったものとして定義されます。 各機能は、フィッシャー基準の下でのスコアに従って個別に選択されます。 これは、次善の機能セットにつながります。 フィッシャーのスコアが大きいほど、選択された機能が適切であることを示します。
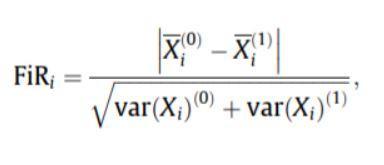
ソース
フィッシャースコアの公式
フィッシャースコアの実装:scikit-feature
フィッシャースコア手法を示すコードの出力
ソース
ピアソンの相関係数:これは、2つの連続変数間の関連を定量化する尺度です。 相関係数の値の範囲は-1から1で、変数間の関係の方向を定義します。
- 分散しきい値:分散が特定のしきい値を満たさない機能は削除されます。 分散がゼロのフィーチャは、この方法で削除されます。 考慮される仮定は、より高い分散の特徴がより多くの情報を含む可能性が高いということです。
図15:分散しきい値の実装を示すコードの例
- 平均絶対差(MAD):このメソッドは平均絶対差を計算します
平均値との差。
平均絶対差(MAD)の実装を示すコードとその出力の例
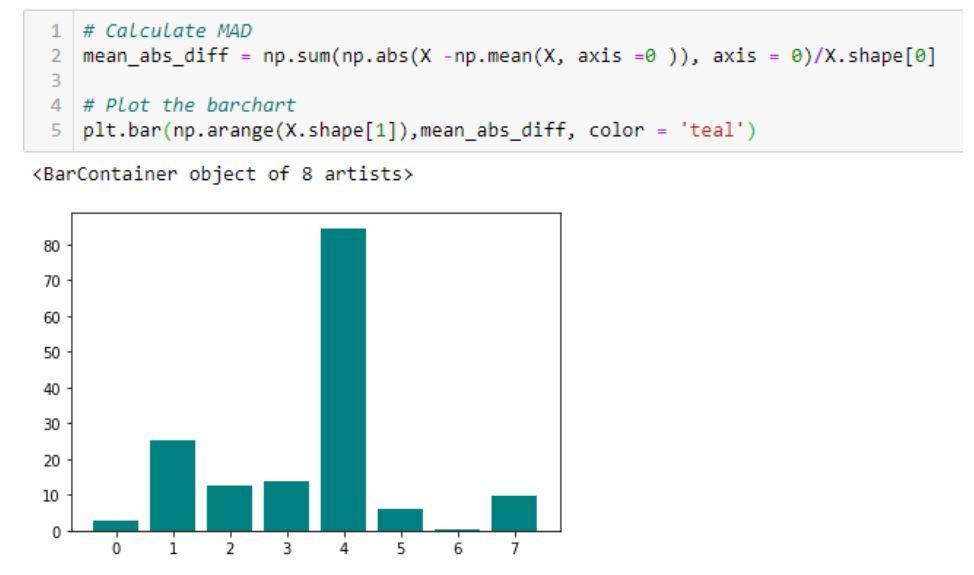
ソース
- 分散比:分散比は、特定の機能の算術平均(AM)と幾何平均(GM)の比として定義されます。 その値は、特定の機能のAM≥GMとして+1から∞の範囲です。
より高い分散比は、Riの値がより高いことを意味し、したがって、より関連性の高い機能を意味します。 逆に、Riが1に近い場合は、関連性の低い機能を示します。
- 相互依存性:このメソッドは、2つの変数間の相互依存性を測定するために使用されます。 一方の変数から取得した情報を使用して、もう一方の変数の情報を取得できます。
- Laplacianスコア:同じクラスのデータは互いに近いことがよくあります。 機能の重要性は、その局所性保存の力によって評価できます。 各機能のラプラシアンスコアが計算されます。 最小値が重要な寸法を決定します。 ラプラシアンスコアの実装:scikit-feature。
結論
機械学習プロセスでの特徴選択は、機械学習モデルの開発に向けた重要なステップの1つとして要約できます。 特徴選択アルゴリズムのプロセスにより、検討中のモデルに関連しない、または重要ではない特徴が削除され、データの次元が減少します。 関連する機能により、モデルのトレーニング時間が短縮され、パフォーマンスが向上する可能性があります。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのエグゼクティブPGプログラムをご覧ください。このプログラムは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIITを提供しています。 -B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との雇用支援。
フィルタメソッドはラッパーメソッドとどのように異なりますか?
ラッパーメソッドは、分類器のパフォーマンスに基づいて機能がどの程度役立つかを測定するのに役立ちます。 一方、フィルター法は、交差検定のパフォーマンスではなく単変量統計を使用して特徴の固有の品質を評価します。これは、特徴の関連性を判断することを意味します。 結果として、ラッパーメソッドは分類器のパフォーマンスを最適化するため、より効果的です。 ただし、学習プロセスと相互検証が繰り返されるため、ラッパー手法はフィルター手法よりも計算コストが高くなります。
機械学習におけるシーケンシャルフォワードセレクションとは何ですか?
これは一種の順次特徴選択ですが、フィルター選択よりもはるかにコストがかかります。 これは、理想的な特徴サブセットを見つけるために、分類器のパフォーマンスに基づいて特徴を繰り返し選択する貪欲な検索手法です。 空の機能サブセットで始まり、ラウンドごとに1つの機能を追加し続けます。 この1つの機能は、機能サブセットに含まれていないすべての機能のプールから選択され、他の機能と組み合わせたときに最高の分類器パフォーマンスを実現します。
特徴選択にフィルター法を使用することの制限は何ですか?
フィルタアプローチは、ラッパーや埋め込み特徴選択法よりも計算コストが低くなりますが、いくつかの欠点があります。 単変量アプローチの場合、この戦略では、機能を選択する際に機能の相互依存性を無視し、各機能を個別に評価することがよくあります。 特徴選択の他の2つの方法と比較すると、コンピューティングパフォーマンスが低下する場合があります。