
不安定なテスト:テストで生きている悪夢を取り除く
公開: 2022-03-10最近よく考えている寓話があります。 子供の頃、寓話は私に言われました。 それは、Aesopによって「オオカミを泣いた少年」と呼ばれています。 それは彼の村の羊を世話する少年についてです。 彼は退屈し、オオカミが群れを攻撃しているふりをして、村人たちに助けを求めます。彼らはそれが誤った警報であることに失望して気づき、少年を放っておくだけです。 そして、実際にオオカミが現れ、少年が助けを求めたとき、村人たちはそれが別の誤った警報であると信じて救助に来ず、羊はオオカミに食べられてしまいます。
物語の教訓は、著者自身によって最もよく要約されています:
「嘘つきは、たとえ彼が真実を語ったとしても、信じられないでしょう。」
オオカミが羊を襲い、少年は助けを求めて泣きますが、何度も嘘をついた後、誰も彼を信じなくなりました。 この道徳はテストに適用できます。Aesopの話は、私が偶然見つけた一致パターンの素晴らしい寓話です。価値を提供できない不安定なテストです。
フロントエンドテスト:なぜ面倒なのか?
私の日々のほとんどはフロントエンドのテストに費やされています。 したがって、この記事のコード例のほとんどが、私の仕事で出会ったフロントエンドテストからのものであることは驚くべきことではありません。 ただし、ほとんどの場合、他の言語に簡単に翻訳して、他のフレームワークに適用できます。 ですから、この記事があなたにとって役立つことを願っています—あなたが持っているかもしれないどんな専門知識でも。
フロントエンドテストの意味を思い出す価値があります。 本質的に、フロントエンドテストは、その機能を含め、WebアプリケーションのUIをテストするための一連のプラクティスです。
品質保証エンジニアとして始めた私は、リリース直前のチェックリストから、無限の手動テストの苦痛を知っています。 そのため、継続的な更新中にアプリケーションにエラーがないことを保証するという目標に加えて、実際には人間を必要としない日常的なタスクによって引き起こされるテストの作業負荷を軽減するように努めました。 現在、開発者として、特にユーザーと同僚を直接支援しようとしているので、このトピックは依然として関連性があると感じています。 そして、特にテストには悪夢をもたらす問題が1つあります。
フレークテストの科学
不安定なテストとは、同じ分析を実行するたびに同じ結果を生成できないテストです。 ビルドが失敗するのはたまにしかありません。ビルドに変更を加えずに、1回は通過し、別の時間は失敗し、次の時間は再び通過します。
テストの悪夢を思い出すと、特に1つのケースが頭に浮かびます。 UIテストでした。 カスタムスタイルのコンボボックス(つまり、入力フィールドを含む選択可能なリスト)を作成しました。
このコンボボックスを使用すると、製品を検索して1つ以上の結果を選択できます。 多くの日、このテストはうまくいきましたが、ある時点で状況が変わりました。 継続的インテグレーション(CI)システムの約10のビルドの1つで、このコンボボックスで製品を検索および選択するためのテストが失敗しました。
失敗のスクリーンショットは、検索が成功したにもかかわらず、結果リストがフィルタリングされていないことを示しています。
このような不安定なテストは、継続的デプロイパイプラインをブロックし、機能の配信を必要以上に遅くする可能性があります。 さらに、不安定なテストはもはや決定論的ではないため問題があり、役に立たなくなります。 結局のところ、嘘つきを信頼するよりも、1つを信頼することはありません。
さらに、不安定なテストは修復に費用がかかり、デバッグに数時間または数日かかることがよくあります。 エンドツーエンドのテストは不安定になりがちですが、単体テスト、機能テスト、エンドツーエンドのテストなど、あらゆる種類のテストで経験しました。
不安定なテストに関するもう1つの重要な問題は、テストが開発者に与える態度です。 私がテスト自動化で働き始めたとき、私はしばしば開発者が失敗したテストに応じてこれを言うのを聞きました:
「ああ、そのビルド。 気にしないで、もう一度始めてください。 いつかは通過するでしょう。」
これは私にとって大きな赤い旗です。 ビルドのエラーが深刻に受け止められないことを示しています。 不安定なテストは実際のバグではなく、世話をしたりデバッグしたりする必要がなく、「ただ」不安定であるという仮定があります。 とにかく、テストは後でまた合格しますよね? いいえ! このようなコミットがマージされると、最悪の場合、製品に新しい不安定なテストが発生します。
原因
したがって、不安定なテストには問題があります。 私たちはそれらについて何をすべきですか? さて、問題を知っていれば、対抗戦略を設計することができます。
私は日常生活の中でしばしば原因に遭遇します。 それらはテスト自体の中にあります。 テストは、最適に記述されていないか、間違った仮定を保持しているか、悪い習慣が含まれている可能性があります。 しかし、それだけではありません。 不安定なテストは、はるかに悪いことを示している可能性があります。
次のセクションでは、私が遭遇した最も一般的なものについて説明します。
1.テスト側の原因
理想的な世界では、アプリケーションの初期状態は元の状態であり、100%予測可能である必要があります。 実際には、テストで使用したIDが常に同じであるかどうかはわかりません。
私の側で単一の失敗の2つの例を調べてみましょう。 間違いの1つは、テストフィクスチャでIDを使用していたことです。
{ "id": "f1d2554b0ce847cd82f3ac9bd1c0dfca", "name": "Variant product", }間違い2は、UIテストで使用する一意のセレクターを探して、「わかりました。このIDは一意のようです。 使用します。」
<!-- This is a text field I took from a project I worked on --> <input type="text" />ただし、別のインストールでテストを実行した場合、または後でCIのいくつかのビルドでテストを実行した場合、それらのテストは失敗する可能性があります。 このアプリケーションはIDを新たに生成し、ビルド間でIDを変更します。 したがって、最初に考えられる原因は、ハードコードされたIDにあります。
2番目の原因は、ランダムに(またはその他の方法で)生成されたデモデータから発生する可能性があります。 確かに、この「欠陥」は正当化されると考えているかもしれません—結局のところ、データ生成はランダムです—しかし、このデータのデバッグについて考えてみてください。 バグがテスト自体にあるのか、デモデータにあるのかを確認するのは非常に難しい場合があります。
次は、私が何度も苦労してきたテスト側の原因です。相互依存関係のあるテストです。 一部のテストは、独立して、またはランダムな順序で実行できない場合があり、これには問題があります。 さらに、以前のテストは後続のテストに干渉する可能性があります。 これらのシナリオは、副作用を導入することにより、不安定なテストを引き起こす可能性があります。
ただし、テストは難しい仮定に関するものであることを忘れないでください。 そもそもあなたの仮定に欠陥があるとどうなりますか? 私はこれらを頻繁に経験しましたが、私のお気に入りは時間についての欠陥のある仮定です。
1つの例は、特にUIテストでの不正確な待機時間の使用です。たとえば、固定待機時間を使用します。 次の行は、Nightwatch.jsテストから取得したものです。
// Please never do that unless you have a very good reason! // Waits for 1 second browser.pause(1000);もう1つの間違った仮定は、時間自体に関連しています。 私はかつて、不安定なPHPUnitテストがナイトリービルドでのみ失敗していることを発見しました。 デバッグを行った結果、昨日と今日の間のタイムシフトが原因であることがわかりました。 もう1つの良い例は、タイムゾーンによる障害です。
誤った仮定はそれだけではありません。 また、データの順序について誤った仮定をする可能性があります。 通貨のリストなどの情報を含む複数のエントリを含むグリッドまたはリストを想像してみてください。
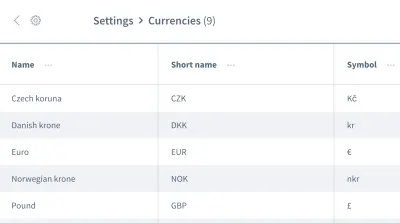
最初のエントリである「チェココルナ」通貨の情報を処理したいと思います。 テストが実行されるたびに、アプリケーションが常にこのデータを最初のエントリとして配置することを確認できますか? 場合によっては、「ユーロ」または別の通貨が最初のエントリになる可能性がありますか?
データが必要な順序で提供されると思い込まないでください。 ハードコードされたIDと同様に、アプリケーションの設計に応じて、ビルド間で順序が変わる可能性があります。
2.環境側の原因
原因の次のカテゴリは、テスト以外のすべてに関連しています。 具体的には、テストが実行される環境、テスト外のCIおよびDocker関連の依存関係について話します。これらはすべて、少なくともテスターとしての役割ではほとんど影響を与えません。
一般的な環境側の原因はリソースリークです。多くの場合、これは負荷がかかっているアプリケーションであり、さまざまな読み込み時間や予期しない動作を引き起こします。 大規模なテストは簡単にリークを引き起こし、大量のメモリを消費する可能性があります。 もう1つの一般的な問題は、クリーンアップの欠如です。
依存関係間の非互換性は、特に私に悪夢を与えます。 私がUIテストのためにNightwatch.jsを使用していたときに、ある悪夢が発生しました。 Nightwatch.jsはWebDriverを使用しますが、これはもちろんChromeに依存します。 Chromeがアップデートを先に進めたとき、互換性に問題がありました。Chrome、WebDriver、Nightwatch.js自体が連携しなくなり、ビルドが失敗することがありました。
依存関係について言えば、権限の欠落やnpmのダウンなど、npmの問題については名誉ある言及があります。 私はCIを観察する際にこれらすべてを経験しました。
環境問題によるUIテストのエラーに関しては、それらを実行するためにアプリケーションスタック全体が必要であることに注意してください。 関係するものが多いほど、エラーが発生する可能性が高くなります。 したがって、JavaScriptテストは、大量のコードをカバーするため、Web開発で安定させるのが最も難しいテストです。
3.製品側の原因
最後になりましたが、この3番目の領域(実際のバグがある領域)には本当に注意する必要があります。 私はフレークネスの製品側の原因について話している。 最もよく知られている例の1つは、アプリケーションの競合状態です。 これが発生した場合、バグはテストではなく製品で修正する必要があります。 この場合、テストまたは環境を修正しようとしても意味がありません。
フレキネスと戦う方法
フレークネスの3つの原因を特定しました。 これに対抗戦略を立てることができます! もちろん、不安定なテストに遭遇したときに3つの原因を念頭に置くことで、すでに多くのことを学んでいるはずです。 あなたはすでに何を探すべきか、そしてどのようにテストを改善するかを知っているでしょう。 ただし、これに加えて、テストの設計、作成、およびデバッグに役立ついくつかの戦略があり、次のセクションでそれらを一緒に見ていきます。
チームに集中する
あなたのチームは間違いなく最も重要な要素です。 最初のステップとして、不安定なテストに問題があることを認めます。 チーム全体のコミットメントを得ることが重要です! 次に、チームとして、不安定なテストに対処する方法を決定する必要があります。
私がテクノロジーで働いていた数年間、私はチームがフレークネスに対抗するために使用する4つの戦略に出くわしました。
- 何もせず、不安定なテスト結果を受け入れます。
もちろん、この戦略はまったく解決策ではありません。 たとえあなたが薄片を受け入れたとしても、あなたはもはやそれを信頼することができないので、テストは価値を生み出しません。 したがって、これをかなりすばやくスキップできます。 - 合格するまでテストを再試行します。
この戦略は私のキャリアの開始時に一般的であり、その結果、前述の反応が得られました。 テストに合格するまでテストを再試行することで、ある程度の受け入れがありました。 この戦略はデバッグを必要としませんが、怠惰です。 問題の症状を隠すことに加えて、テストスイートの速度がさらに低下し、ソリューションが実行不可能になります。 ただし、このルールにはいくつかの例外がある場合があります。これについては後で説明します。 - テストを削除して忘れてください。
これは自明です。不安定なテストを削除するだけで、テストスイートの邪魔になりません。 もちろん、テストをデバッグして修正する必要がなくなるため、コストを節約できます。 ただし、テストカバレッジが少し失われ、潜在的なバグ修正が失われるという犠牲が伴います。 テストは理由があります! テストを削除してメッセンジャーを撃ってはいけません。 - 隔離して修正します。
私はこの戦略で最も成功しました。 この場合、テストを一時的にスキップし、テストスイートにテストがスキップされたことを常に通知させます。 修正が見落とされないようにするために、次のスプリントのチケットをスケジュールします。 ボットのリマインダーもうまく機能します。 フレークネスの原因となる問題が修正されたら、テストを再度統合(つまりスキップ解除)します。 残念ながら、一時的にカバレッジが失われますが、修正が加えられて戻ってくるので、それほど時間はかかりません。
これらの戦略は、ワークフローレベルでテストの問題に対処するのに役立ちます。これらの戦略に遭遇したのは、私だけではありません。 彼の記事では、サム・サフランも同様の結論に達しています。 しかし、私たちの日常業務では、限られた範囲で私たちを助けてくれます。 それで、そのようなタスクが私たちの道に来たとき、私たちはどのように進むのですか?

テストを分離しておく
テストケースと構造を計画するときは、テストを常に他のテストから分離して、独立した順序またはランダムな順序で実行できるようにしてください。 最も重要な手順は、テスト間でクリーンインストールを復元することです。 さらに、テストするワークフローのみをテストし、テスト自体のモックデータのみを作成します。 このショートカットのもう1つの利点は、テストのパフォーマンスが向上することです。 これらの点に従えば、他のテストや残りのデータによる副作用が邪魔になることはありません。
以下の例は、eコマースプラットフォームのUIテストから抜粋したもので、ショップの店頭での顧客のログインを処理します。 (テストは、サイプレスフレームワークを使用してJavaScriptで記述されています。)
// File: customer-login.spec.js let customer = {}; beforeEach(() => { // Set application to clean state cy.setInitialState() .then(() => { // Create test data for the test specifically return cy.setFixture('customer'); }) }): 最初のステップは、アプリケーションをクリーンインストールにリセットすることです。 これは、 beforeEachライフサイクルフックの最初のステップとして実行され、リセットが毎回実行されることを確認します。 その後、テストデータはテスト専用に作成されます。このテストケースでは、カスタムコマンドを使用して顧客を作成します。 続いて、テストしたい1つのワークフローである顧客のログインから始めることができます。
テスト構造をさらに最適化する
テスト構造をより安定させるために、他の小さな調整を行うことができます。 1つ目は非常に単純です。小さなテストから始めます。 前に述べたように、テストで行うほど、うまくいかない可能性があります。 テストは可能な限りシンプルに保ち、各テストで多くのロジックを回避します。
データの順序を想定しない場合(たとえば、UIテストでリスト内のエントリの順序を処理する場合)、任意の順序に関係なく機能するテストを設計できます。 情報を含むグリッドの例を戻すために、順序に強く依存する疑似セレクターやその他のCSSは使用しません。 nth-child(3)セレクターの代わりに、順序が重要ではないテキストやその他のものを使用できます。 たとえば、「このテーブルでこの1つのテキスト文字列を持つ要素を見つけてください」のようなアサーションを使用できます。
待って! テストの再試行は時々大丈夫ですか?
テストの再試行は物議を醸すトピックであり、当然のことながらそうです。 テストが成功するまで盲目的に再試行された場合、私はまだそれをアンチパターンと考えています。 ただし、重要な例外があります。エラーを制御できない場合、再試行が最後の手段になる可能性があります(たとえば、外部の依存関係からエラーを除外するため)。 この場合、エラーの原因に影響を与えることはできません。 ただし、これを行うときは特に注意してください。テストを再試行するときにフレークネスを知らないようにし、テストがスキップされたときに通知を使用して通知します。
次の例は、GitLabを使用したCIで使用した例です。 他の環境では、再試行を実行するための構文が異なる場合がありますが、これで味がわかります。
test: script: rspec retry: max: 2 when: runner_system_failureこの例では、ジョブが失敗した場合に実行する再試行回数を構成しています。 興味深いのは、ランナーシステムにエラーがある場合(たとえば、ジョブのセットアップが失敗した場合)に再試行できることです。 Dockerセットアップの何かが失敗した場合にのみ、ジョブを再試行することを選択しています。
これにより、トリガーされたときにジョブ全体が再試行されることに注意してください。 障害のあるテストのみを再試行する場合は、これをサポートする機能をテストフレームワークで探す必要があります。 以下は、バージョン5以降の単一テストの再試行をサポートしているサイプレスの例です。
{ "retries": { // Configure retry attempts for 'cypress run` "runMode": 2, // Configure retry attempts for 'cypress open` "openMode": 2, } } サイプレスの構成ファイルcypress.jsonでテストの再試行をアクティブ化できます。 そこで、テストランナーおよびヘッドレスモードでの再試行の試行を定義できます。
動的待機時間の使用
この点は、あらゆる種類のテスト、特にUIテストにとって重要です。 これを十分に強調することはできません。固定の待機時間を使用しないでください。少なくとも、非常に正当な理由がない場合はそうです。 それを行う場合は、考えられる結果を考慮してください。 最良の場合、待ち時間が長すぎるため、テストスイートが必要以上に遅くなります。 最悪の場合、十分な時間待機しないため、アプリケーションの準備ができていないためにテストが続行されず、テストが不安定な方法で失敗します。 私の経験では、これが不安定なテストの最も一般的な原因です。
代わりに、動的な待機時間を使用してください。 これを行うには多くの方法がありますが、サイプレスはそれらを特にうまく処理します。
すべてのサイプレスコマンドは、暗黙の待機メソッドを所有しています。コマンドが適用されている要素が指定された時間DOMに存在するかどうかをすでにチェックしており、サイプレスの再試行可能性を示しています。 ただし、存在をチェックするだけで、それ以上はチェックしません。 したがって、さらに一歩進んで、UI自体やアニメーションの変更など、実際のユーザーにも表示されるWebサイトまたはアプリケーションのUIの変更を待つことをお勧めします。
この例では、セレクター.offcanvasを使用して要素で明示的な待機時間を使用しています。 テストは、次のように構成できる指定されたタイムアウトまで要素が表示されている場合にのみ続行されます。
// Wait for changes in UI (until element is visible) cy.get(#element).should('be.visible'); サイプレスの動的待機のもう1つの優れた可能性は、ネットワーク機能です。 はい、リクエストが発生し、その応答の結果が出るのを待つことができます。 私はこの種の待機を特に頻繁に使用します。 以下の例では、待機する要求を定義し、 waitコマンドを使用して応答を待機し、そのステータスコードをアサートします。
// File: checkout-info.spec.js // Define request to wait for cy.intercept({ url: '/widgets/customer/info', method: 'GET' }).as('checkoutAvailable'); // Imagine other test steps here... // Assert the response's status code of the request cy.wait('@checkoutAvailable').its('response.statusCode') .should('equal', 200);このようにして、アプリケーションが必要とする限り正確に待機できるため、テストがより安定し、リソースリークやその他の環境問題によるフレークが発生しにくくなります。
不安定なテストのデバッグ
これで、設計によって不安定なテストを防ぐ方法がわかりました。 しかし、すでに不安定なテストを扱っている場合はどうなりますか? どうすればそれを取り除くことができますか?
私がデバッグしているとき、欠陥のあるテストをループに入れることは、フレークネスを明らかにするのに大いに役立ちました。 たとえば、テストを50回実行し、毎回合格した場合、テストが安定していることを確認できます。修正が機能した可能性があります。 そうでない場合は、少なくともフレーク状のテストについてより多くの洞察を得ることができます。
// Use in build Lodash to repeat the test 100 times Cypress._.times(100, (k) => { it(`typing hello ${k + 1} / 100`, () => { // Write your test steps in here }) }) この不安定なテストについてより多くの洞察を得るのは、CIでは特に困難です。 ヘルプが必要な場合は、テストフレームワークがビルドに関する詳細情報を取得できるかどうかを確認してください。 フロントエンドテストに関しては、通常、テストでconsole.logを利用できます。
it('should be a Vue.JS component', () => { // Mock component by a method defined before const wrapper = createWrapper(); // Print out the component's html console.log(wrapper.html()); expect(wrapper.isVueInstance()).toBe(true); }) この例は、 console.logを使用してテスト対象のコンポーネントのHTMLの出力を取得するJest単体テストから抜粋したものです。 サイプレスのテストランナーでこのロギングの可能性を使用する場合は、選択した開発ツールで出力を検査することもできます。 さらに、CIのサイプレスに関しては、プラグインを使用してCIのログでこの出力を調べることができます。
ロギングのサポートを受けるには、常にテストフレームワークの機能を確認してください。 UIテストでは、ほとんどのフレームワークがスクリーンショット機能を提供します。少なくとも失敗すると、スクリーンショットが自動的に取得されます。 一部のフレームワークはビデオ録画も提供します。これは、テストで何が起こっているかを洞察するのに非常に役立ちます。
フレキネスの悪夢と戦おう!
不安定なテストを最初から防止するか、発生したらすぐにデバッグして修正することによって、不安定なテストを継続的に探すことが重要です。 アプリケーションの問題を示唆する可能性があるため、これらを真剣に受け止める必要があります。
赤旗を見つける
もちろん、最初から不安定なテストを防ぐのが最善です。 簡単に要約すると、ここにいくつかの危険信号があります:
- テストは大規模で、多くのロジックが含まれています。
- テストは多くのコードをカバーします(たとえば、UIテストで)。
- テストでは、固定の待機時間を利用します。
- テストは以前のテストに依存します。
- このテストでは、ID、時間、デモデータの使用など、100%予測できないデータ、特にランダムに生成されたデータをアサートします。
この記事の指針と戦略を念頭に置いておけば、不安定なテストが発生する前に防ぐことができます。 そして、それらが来た場合、あなたはそれらをデバッグして修正する方法を知っているでしょう。
これらの手順は、テストスイートへの信頼を取り戻すのに本当に役立ちました。 現在、テストスイートは安定しているようです。 将来的に問題が発生する可能性があります。100%完璧なものはありません。 この知識とこれらの戦略は、私がそれらに対処するのに役立ちます。 したがって、私はそれらの不安定なテストの悪夢と戦う私の能力に自信を持って成長します。
私はあなたの痛みと薄片の心配の少なくともいくつかを和らげることができたと思います!
参考文献
このトピックについてもっと知りたい場合は、ここにいくつかのきちんとしたリソースと記事があり、それは私を大いに助けました:
- 「フレーク」に関する記事、Cypress.io
- 「テストを再試行することは、実際には良いことです(アプローチが正しい場合)」、Filip Hric、Cypress.io
- 「テストの不安定さ:不安定なテストを識別して処理する方法」、Spotify R&DEngineeringのJasonPalmer
- 「Googleでの不安定なテストとその軽減方法」、Google Testing Blog、John Micco