
埋め込み画像プレビューによる画像読み込みの高速化
公開: 2022-03-10低品質画像プレビュー(LQIP)とSVGベースのバリアントSQIPは、レイジー画像読み込みの2つの主要な手法です。 両方に共通しているのは、最初に低品質のプレビュー画像を生成することです。 これはぼやけて表示され、後で元の画像に置き換えられます。 追加のデータをロードせずに、Webサイトの訪問者にプレビュー画像を表示できるとしたらどうでしょうか。
遅延読み込みが主に使用されるJPEGファイルは、仕様に従って、最初に粗い画像の内容、次に詳細な画像の内容が表示されるように、ファイルに含まれるデータを保存する可能性があります。 ロード中に画像を上から下に構築する代わりに(ベースラインモード)、ぼやけた画像を非常にすばやく表示でき、徐々に鮮明になります(プログレッシブモード)。


より速く表示される外観によって提供される優れたユーザーエクスペリエンスに加えて、プログレッシブJPEGは通常、ベースラインでエンコードされた対応物よりも小さくなります。 Yahoo開発チームのStoyanStefanovによると、10 kBを超えるファイルの場合、プログレッシブモードを使用すると、94%の確率で画像が小さくなります。
Webサイトが多数のJPEGで構成されている場合は、プログレッシブJPEGでさえ次々に読み込まれることに気付くでしょう。 これは、最近のブラウザではドメインへの同時接続が6つしか許可されていないためです。 したがって、プログレッシブJPEGだけでは、ユーザーにページの可能な限り最速の印象を与えるソリューションではありません。 最悪の場合、ブラウザは次の画像の読み込みを開始する前に画像を完全に読み込みます。
ここで紹介するアイデアは、サーバーからプログレッシブJPEGの非常に多くのバイトのみをロードして、画像コンテンツの印象をすばやく取得できるようにすることです。 後で、私たちが定義した時間(たとえば、現在のビューポートのすべてのプレビュー画像が読み込まれたとき)に、プレビューを再度要求した部分を再度要求せずに、画像の残りの部分を読み込む必要があります。

残念ながら、属性内のimgタグに、いつどのくらいの画像をロードする必要があるかを伝えることはできません。 ただし、Ajaxでは、画像を配信するサーバーがHTTP範囲リクエストをサポートしていれば、これは可能です。
クライアントは、HTTP範囲要求を使用して、要求されたファイルのどのバイトがHTTP応答に含まれるかをHTTP要求ヘッダーでサーバーに通知できます。 この機能は、より大きなサーバー(Apache、IIS、nginx)のそれぞれでサポートされており、主にビデオの再生に使用されます。 ユーザーがビデオの最後にジャンプした場合、ユーザーが最終的に目的の部分を見ることができる前に、完全なビデオをロードすることはあまり効率的ではありません。 したがって、ユーザーが要求した時間のビデオデータのみがサーバーによって要求され、ユーザーはビデオをできるだけ速く見ることができます。
現在、次の3つの課題に直面しています。
- プログレッシブJPEGの作成
- 最初のHTTP範囲リクエストがプレビュー画像をロードする必要があるバイトオフセットを決定します
- フロントエンドJavaScriptコードの作成
1.プログレッシブJPEGの作成
プログレッシブJPEGは、いくつかのいわゆるスキャンセグメントで構成され、各セグメントには最終画像の一部が含まれています。 最初のスキャンでは画像が非常に大まかに表示されますが、ファイルの後半に続くスキャンでは、すでにロードされているデータにさらに詳細な情報が追加され、最終的に最終的な外観が形成されます。
個々のスキャンがどの程度正確に見えるかは、JPEGを生成するプログラムによって決まります。 mozjpegプロジェクトのcjpegなどのコマンドラインプログラムでは、これらのスキャンに含まれるデータを定義することもできます。 ただし、これにはより深い知識が必要であり、この記事の範囲を超えます。 これについては、JPEG圧縮の基本を教えている私の記事「最終的にJPGを理解する」を参照したいと思います。 スキャンスクリプトでプログラムに渡す必要のある正確なパラメータは、mozjpegプロジェクトのwizard.txtで説明されています。 私の意見では、mozjpegがデフォルトで使用するスキャンスクリプト(7回のスキャン)のパラメーターは、高速プログレッシブ構造とファイルサイズの間の適切な妥協点であるため、採用できます。
最初のJPEGをプログレッシブJPEGに変換するには、mozjpegプロジェクトのjpegtranを使用します。 これは、既存のJPEGにロスレスの変更を加えるためのツールです。 WindowsおよびLinux用にコンパイル済みのビルドは、https://mozjpeg.codelove.de/binaries.htmlから入手できます。 セキュリティ上の理由から安全にプレイしたい場合は、自分で作成することをお勧めします。
コマンドラインから、プログレッシブJPEGを作成します。
$ jpegtran input.jpg > progressive.jpgプログレッシブJPEGを作成するという事実は、jpegtranによって想定されており、明示的に指定する必要はありません。 画像データは一切変更されません。 ファイル内の画像データの配置のみが変更されます。
画像の外観に関係のないメタデータ(Exif、IPTC、XMPデータなど)は、対応するセグメントが画像コンテンツの前にある場合にのみメタデータデコーダーで読み取ることができるため、理想的にはJPEGから削除する必要があります。 このため、ファイル内の画像データの後ろに移動することはできないため、プレビュー画像とともに既に配信されており、それに応じて最初のリクエストが拡大されます。 コマンドラインプログラムexiftoolを使用すると、次のメタデータを簡単に削除できます。
$ exiftool -all= progressive.jpgコマンドラインツールを使用したくない場合は、オンライン圧縮サービスcompress-or-die.comを使用して、メタデータなしでプログレッシブJPEGを生成することもできます。
2.最初のHTTP範囲リクエストがプレビュー画像をロードする必要があるバイトオフセットを決定します
JPEGファイルはさまざまなセグメントに分割され、それぞれにさまざまなコンポーネント(画像データ、IPTC、Exif、XMPなどのメタデータ、埋め込みカラープロファイル、量子化テーブルなど)が含まれています。 これらの各セグメントは、16進数のFFバイトによって導入されたマーカーで始まります。 この後に、セグメントのタイプを示すバイトが続きます。 たとえば、 D8は、各JPEGファイルが始まるSOIマーカーFF D8 (画像の開始)のマーカーを完成させます。
スキャンの各開始は、SOSマーカー(スキャンの開始、16進数のFF DA )によってマークされます。 SOSマーカーの背後にあるデータはエントロピー符号化されているため(JPEGはハフマン符号化を使用)、SOSセグメントの前にデコードするために必要なハフマンテーブル(DHT、16進FF C4 )を持つ別のセグメントがあります。 したがって、プログレッシブJPEGファイル内の関心領域は、交互のハフマンテーブル/スキャンデータセグメントで構成されます。 したがって、画像の最初の非常に大まかなスキャンを表示する場合は、サーバーからDHTセグメント(16進数のFF C4 )が2番目に出現するまでのすべてのバイトを要求する必要があります。
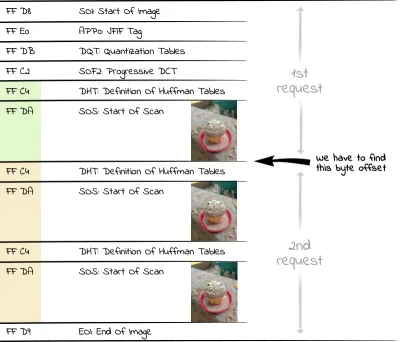
PHPでは、次のコードを使用して、すべてのスキャンに必要なバイト数を配列に読み込むことができます。
<?php $img = "progressive.jpg"; $jpgdata = file_get_contents($img); $positions = []; $offset = 0; while ($pos = strpos($jpgdata, "\xFF\xC4", $offset)) { $positions[] = $pos+2; $offset = $pos+2; }ブラウザはプレビュー画像の最後の行を新しいマーカー(上記の2バイトで構成されている)に遭遇したときにのみレンダリングするため、見つかった位置に2の値を追加する必要があります。
この例の最初のプレビュー画像に関心があるので、HTTP RangeRequestを介してファイルをリクエストする必要がある$positions[1]で正しい位置を見つけます。 より良い解像度の画像をリクエストするには、配列内のより後の位置、たとえば$positions[3]を使用できます。
3.フロントエンドJavaScriptコードの作成
まず、 imgタグを定義します。このタグに、評価されたばかりのバイト位置を指定します。
<img data-src="progressive.jpg" data-bytes="<?= $positions[1] ?>"> 遅延読み込みライブラリの場合によくあることですが、 src属性を直接定義しないため、HTMLコードを解析するときに、ブラウザがサーバーからの画像の要求をすぐに開始しません。

次のJavaScriptコードを使用して、プレビュー画像を読み込みます。
var $img = document.querySelector("img[data-src]"); var URL = window.URL || window.webkitURL; var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ $img.src_part = this.response; $img.src = URL.createObjectURL(this.response); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes=0-" + $img.getAttribute('data-bytes')); xhr.responseType = 'blob'; xhr.send(); このコードは、HTTP範囲ヘッダーでサーバーにファイルを最初からdata-bytesで指定された位置に返すように指示するAjaxリクエストを作成します。 サーバーがHTTP範囲リクエストを理解すると、バイナリイメージデータをHTTP-206応答(HTTP 206 =部分コンテンツ)でblobの形式で返します。このデータから、 createObjectURLを使用してブラウザー内部のURLを生成できます。 このURLをimgタグのsrcとして使用します。 このようにして、プレビュー画像をロードしました。
このデータがすぐに必要になるため、プロパティsrc_partのDOMオブジェクトにblobを追加で格納します。
開発者コンソールの[ネットワーク]タブで、完全なイメージがロードされていないことを確認できますが、ロードされているのはごく一部です。 さらに、blob URLのロードは、0バイトのサイズで表示される必要があります。
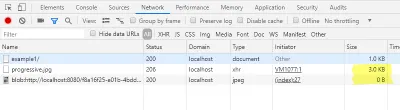
元のファイルのJPEGヘッダーはすでに読み込まれているため、プレビュー画像のサイズは正しいです。 したがって、アプリケーションによっては、 imgタグの高さと幅を省略できます。
別の方法:プレビュー画像をインラインで読み込む
パフォーマンス上の理由から、プレビュー画像のデータをデータURIとしてHTMLソースコードで直接転送することもできます。 これにより、HTTPヘッダーを転送するオーバーヘッドが節約されますが、base64エンコーディングでは画像データが3分の1大きくなります。 これは、 gzipやbrotliなどのコンテンツエンコーディングを使用してHTMLコードを配信する場合に相対化されますが、小さなプレビュー画像にはデータURIを使用する必要があります。
さらに重要なのは、プレビュー画像がすぐに利用可能であり、ページを作成するときにユーザーに目立った遅延がないという事実です。
まず、データURIを作成する必要があります。これを、 imgタグでsrcとして使用します。 このために、PHPを介してデータURIを作成します。これにより、このコードは、SOSマーカーのバイトオフセットを決定する、作成されたばかりのコードに基づいています。
<?php … $fp = fopen($img, 'r'); $data_uri = 'data:image/jpeg;base64,'. base64_encode(fread($fp, $positions[1])); fclose($fp); 作成されたデータURIは、 srcとして `img`タグに直接挿入されます。
<img src="<?= $data_uri ?>" data-src="progressive.jpg" alt="">もちろん、JavaScriptコードも適合させる必要があります。
<script> var $img = document.querySelector("img[data-src]"); var binary = atob($img.src.slice(23)); var n = binary.length; var view = new Uint8Array(n); while(n--) { view[n] = binary.charCodeAt(n); } $img.src_part = new Blob([view], { type: 'image/jpeg' }); $img.setAttribute('data-bytes', $img.src_part.size - 1); </script> すぐにblobを受け取るAjaxリクエストを介してデータをリクエストする代わりに、この場合、データURIから自分でblobを作成する必要があります。 これを行うには、画像データを含まない部分からdata-URIを解放します: data:image/jpeg;base64 。 残りのbase64コード化データをatobコマンドでデコードします。 現在のバイナリ文字列データからblobを作成するには、データをUint8配列に転送する必要があります。これにより、データがUTF-8でエンコードされたテキストとして扱われないようになります。 この配列から、プレビュー画像の画像データを使用してバイナリブロブを作成できます。
このインラインバージョンに次のコードを適合させる必要がないように、 imgタグに属性data-bytesを追加します。これには、前の例では、画像の2番目の部分をロードする必要があるバイトオフセットが含まれています。 。
開発者コンソールの[ネットワーク]タブで、プレビュー画像を読み込んでも追加のリクエストが生成されないことを確認できますが、HTMLページのファイルサイズは大きくなっています。
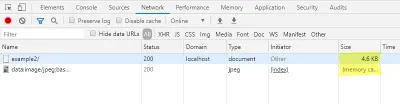
最終画像の読み込み
2番目のステップでは、例として2秒後に残りの画像ファイルをロードします。
setTimeout(function(){ var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ var blob = new Blob([$img.src_part, this.response], { type: 'image/jpeg'} ); $img.src = URL.createObjectURL(blob); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes="+ (parseInt($img.getAttribute('data-bytes'), 10)+1) +'-'); xhr.responseType = 'blob'; xhr.send(); }, 2000); 今回のRangeヘッダーでは、プレビュー画像の終了位置からファイルの終了までの画像をリクエストすることを指定します。 最初のリクエストに対する回答は、DOMオブジェクトのプロパティsrc_partに格納されています。 両方のリクエストからの応答を使用して、画像全体のデータを含むnew Blob()ごとに新しいblobを作成します。 これから生成されたblobURLは、DOMオブジェクトのsrcとして再び使用されます。 これで、画像が完全に読み込まれました。
また、開発者コンソールの[ネットワーク]タブでロードされたサイズを再度確認できるようになりました。
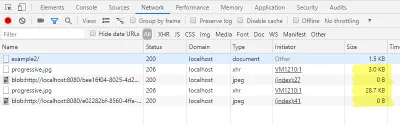
プロトタイプ
次のURLで、さまざまなパラメータを試すことができるプロトタイプを提供しました:https://embedded-image-preview.cerdmann.com/prototype/
プロトタイプのGitHubリポジトリは、https://github.com/McSodbrenner/embedded-image-previewにあります。
最後の考慮事項
ここで紹介するEmbeddedImage Preview(EIP)テクノロジーを使用すると、AjaxおよびHTTP Range Requestsを使用して、プログレッシブJPEGから質的に異なるプレビュー画像を読み込むことができます。 これらのプレビュー画像のデータは破棄されず、代わりに画像全体を表示するために再利用されます。
さらに、プレビュー画像を作成する必要はありません。 サーバー側では、プレビュー画像が終了するバイトオフセットのみを決定して保存する必要があります。 CMSシステムでは、この番号を画像の属性として保存し、 imgタグに出力するときに考慮に入れることができるはずです。 画像ファイルとは別にオフセットを保存する必要がないように、画像のファイル名をオフセットで補足するワークフロー(たとえば、 progressive-8343.jpg )も考えられます。 このオフセットは、JavaScriptコードによって抽出できます。
プレビュー画像データは再利用されるため、この手法は、プレビュー画像をロードしてからWebPをロードする(およびWebPをサポートしていないブラウザーにJPEGフォールバックを提供する)通常のアプローチよりも優れた代替手段になる可能性があります。 プレビュー画像は、プログレッシブモードをサポートしていないWebPのストレージの利点を損なうことがよくあります。
現在、通常のLQIPのプレビュー画像は、プレビューデータのロードに追加の帯域幅が必要であると想定されているため、品質が劣っています。 ロビンオズボンは2018年のブログ投稿ですでに明らかにしているように、最終的な画像のアイデアを与えないプレースホルダーを表示することはあまり意味がありません。 ここで提案する手法を使用することで、プログレッシブJPEGのスキャンをユーザーに提示することで、最終的な画像の一部をプレビュー画像として迷わず表示できます。
ユーザーのネットワーク接続が弱い場合は、アプリケーションによっては、JPEG全体をロードせずに、たとえば最後の2つのスキャンを省略することが理にかなっている場合があります。 これにより、品質がわずかに低下するだけで、はるかに小さいJPEGが生成されます。 ユーザーはそれを感謝し、サーバーに追加のファイルを保存する必要はありません。
さて、プロトタイプを試して楽しんでいただき、コメントをお待ちしております。