
機械学習におけるフェイクニュースの検出[コーディング例で説明]
公開: 2021-02-08フェイクニュースは、インターネットとソーシャルメディアの現在の時代における最大の問題の1つです。 ニュースが世界の隅々から数時間のうちに流れるのは幸いですが、多くの人々やグループが偽のニュースを広めるのを見るのも辛いことです。
自然言語処理と深層学習を使用した機械学習技術を使用して、この問題にある程度取り組むことができます。 このチュートリアルでは、機械学習を使用してフェイクニュース検出モデルを構築します。
この記事の終わりまでに、あなたは次のことを知っているでしょう:
- テキストデータの処理
- NLP処理技術
- カウントのベクトル化とTF-IDF
- 予測を行い、ニューステキストを分類する
世界のトップ大学(修士、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインでAI&MLコースに参加して、キャリアを早急に進めましょう。
目次
データと問題
KaggleFakeNewsチャレンジデータを使用して分類子を作成します。 データセットは、4つの機能と1つのバイナリターゲットで構成されています。 4つの機能は次のとおりです。
- id :ニュース記事の一意のID
- タイトル:ニュース記事のタイトル
- 著者:ニュース記事の著者
- テキスト:記事のテキスト。 不完全である可能性があります
そして、ターゲットは、バイナリ値0と1を含む「ラベル」です。 ここで、0は、信頼できるニュースソース、つまり偽物ではないことを意味します。 1は、それが潜在的に偽のニュースであり、信頼できないことを意味します。 20800個のインスタンスで構成されたデータセット。 すぐに飛び込みましょう。

データの前処理とクリーニング
| パンダをpdとしてインポートします df = pd.read_csv( 'fake-news / train.csv' ) df.head() |
| X = df.drop( 'label' 、axis = 1 )#機能 y = df [ 'label' ]#ターゲット |
ここで、データが欠落しているインスタンスを削除する必要があります。
| df = df.dropna() |
![]()
ご覧のとおり、データが欠落しているすべてのインスタンスが削除されました。
| messages = df.copy() messages.reset_index(inplace = True ) messages.head( 10 ) |
データを一度見てみましょう。
| メッセージ['テキスト'][6] |

ご覧のとおり、次の手順を実行する必要があります。
- ストップワードの削除:データに関係なく、テキストに価値を付加しない単語がたくさんあります。 たとえば、「I」、「a」、「am」などです。これらの単語には情報価値がないため、削除してコーパスのサイズを縮小し、実際に価値のある単語/トークンのみに焦点を当てることができます。 。
- 単語のステミング:ステミングとレマタイゼーションは、単語を語幹または語根に還元する手法です。 このステップの主な利点は、語彙のサイズを減らすことです。 たとえば、Play、Playing、Playedなどの単語は「Play」に短縮されます。 ステミングは、単語を最短の単語に切り捨てるだけで、テキストの文法的な側面は考慮されません。 一方、Lemmatizationは文法的な考慮も考慮しているため、はるかに優れた結果が得られます。 ただし、辞書を参照し、文法的な側面を考慮する必要があるため、通常、レマタイゼーションはステミングよりも遅くなります。
- アルファベットの値以外のすべてを削除する:アルファベット以外の値はここではあまり役に立たないため、削除できます。 ただし、数値データまたは他のタイプのデータの存在がターゲットに影響を与えるかどうかをさらに詳しく調べることができます。
- 単語を小文字にする:語彙を減らすために単語を小文字にします。
- 文をトークン化する:文からトークンを生成します。
| sklearn.feature_extraction.textからインポートCountVectorizer、TfidfVectorizer、HashingVectorizer nltk.corpusからインポートストップワード nltk.stem.porterからインポートPorterStemmer 再インポート ps = PorterStemmer() corpus = [] for i in range(0、len(messages)): review = re.sub('[^ a-zA-Z]'、''、messages ['text'] [i]) review = review.lower() review = review.split() review = [ps.stem(word)for word in review if not word in stopwords.words('english')] review ='' .join(review) corpus.append(レビュー) |
それでは、コーパスを見てみましょう。
| コーパス[ 3 ] |
![]()
ご覧のとおり、単語はルート単語にステム処理されています。
TF-IDFベクトライザー
次に、単語を数値データにベクトル化する必要があります。これは、ベクトル化とも呼ばれます。 ベクトル化する最も簡単な方法は、BagofWordsを使用することです。 しかし、Bag of Wordsはスパース行列を作成するため、多くの処理メモリが必要になります。 さらに、BoWは単語の頻度を考慮していないため、アルゴリズムが不適切になります。
TF-IDF(Term Frequency – Inverse Document Frequency)は、単語の頻度を考慮して単語をベクトル化するもう1つの方法です。 たとえば、「we」、「our」、「the」などの一般的な単語はすべてのドキュメント/インスタンスに含まれているため、BoW値が高すぎて、誤解を招く可能性があります。 これは悪いモデルにつながります。 TF-IDFは、用語頻度と逆ドキュメント頻度の乗算です。
用語頻度は、ドキュメント内の単語の頻度を考慮し、逆ドキュメント頻度は、コーパス全体に存在する単語を考慮します。 IDF値がはるかに低いため、コーパス全体に存在する単語の重要性は低くなっています。 1つのドキュメントに具体的に存在する単語は、IDF値が高いため、TF-IDF値の合計が高くなります。
| ## TFi df Vectorizer sklearn.feature_extraction.textからインポートTfidfVectorizer tfidf_v = TfidfVectorizer(max_features = 5000 、ngram_range = ( 1、3 ) ) X = tfidf_v.fit_transform(corpus).toarray() y = messages [ 'label' ] |
上記のコードでは、Sklearnの特徴抽出モジュールからTF-IDFVectorizerをインポートします。 max_featuresを5000として、ngram_rangeを(1,3)として渡すことにより、そのオブジェクトを作成します。 パラメータmax_featuresは、作成する特徴ベクトルの最大数を定義し、ngram_rangeパラメータは、含めるngramの組み合わせを定義します。 この場合、1ワード、2ワード、および3ワードの3つの組み合わせを取得します。 作成された機能のいくつかを見てみましょう。
| tfidf_v.get_feature_names()[: 20 ] |


ご覧のとおり、形成される組み合わせには複数の種類があります。 1トークン、2トークン、および3トークンの機能名があります。
データフレームの作成
| ##データセットをトレーニングとテストに分割します sklearn.model_selectionからimporttrain_test_split _ X_train、X_test、y_train、y_test = train_test_split(X、y、test_size = 0.33 、random_state = 0 ) count_df = pd.DataFrame(X_train、columns = tfidf_v.get_feature_names()) count_df.head() |
データセットをtrainとtestに分割して、見えないデータでモデルのパフォーマンスをテストできるようにします。 次に、新しい特徴ベクトルを含む新しいデータフレームを作成します。
モデリングとチューニング
MultinomialNBアルゴリズム
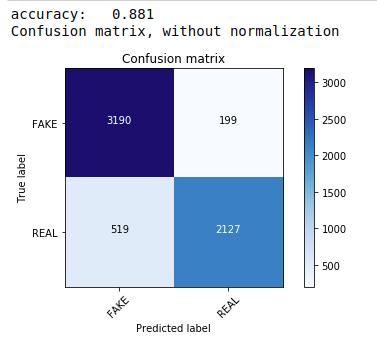
まず、テキストデータの分類に適した最も一般的で最も簡単なアルゴリズムである多項ナイーブベイズ定理を使用します。 トレーニングデータに適合し、テストデータを予測します。 後で、混同行列を計算してプロットし、88.1%の精度を取得します。
| sklearn.naive_bayesからインポートMultinomialNB sklearnインポートメトリックから numpyをnpとしてインポートします itertoolsをインポートする sklearn.metricsからインポートplot_confusion_matrix classifier = MultinomialNB() classifier.fit(X_train、y_train) pred = classifier.predict(X_test) スコア=metrics.accuracy_score(y_test、pred) print( “精度:%0.3f” %スコア) cm =metrics.confusion_matrix(y_test、pred) plot_confusion_matrix(cm、classes = [ 'FAKE' 、 'REAL' ]) |
ハイパーパラメータ調整を使用した多項分類器
MultinomialNBには、さらに調整できるパラメーターalphaがあります。 したがって、ループを実行して、アルファ値が異なる複数のMultinomialNB分類子を試し、それらの精度スコアを確認します。 そして、現在のスコアが以前のスコアよりも大きいかどうかを確認します。 そうである場合は、分類子を現在の分類子として設定します。
| previous_score = 0 np.arange ( 0、1、0.1 )のアルファの場合: _ sub_classifier = MultinomialNB(alpha = alpha) sub_classifier.fit(X_train、y_train) y_pred = sub_classifier.predict(X_test) スコア=metrics.accuracy_score(y_test、y_pred) スコア>previous_scoreの場合: classifier = sub_classifier print( “ Alpha:{}、Score:{}” .format(alpha、score)) |
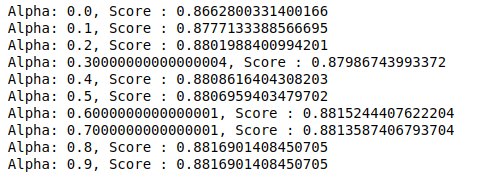
したがって、0.9または0.8のアルファ値が最高の精度スコアを与えたことがわかります。
結果の解釈
次に、これらの分類子係数値の意味を見てみましょう。 まず、すべての機能名を別の変数に保存します。
| ## GetFeaturesの名前 feature_names = cv.get_feature_names() |
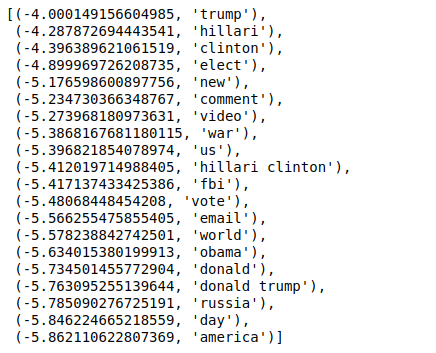
ここで、値を逆の順序で並べ替えると、最小値が-4の値が得られます。 これらは、最も本物であるか、最も偽物ではない単語を示します。
| ###最もリアル sorted(zip(classifier.coef_ [ 0 ]、feature_names)、reverse = True )[: 20 ] |
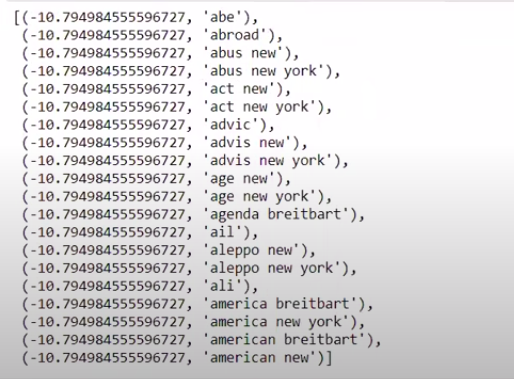
値を逆順ではない順序で並べ替えると、最小値が-10の値が得られます。 これらは、最も現実的でない、または最も偽物である単語を示します。
| ###最もリアル ソート済み(zip(classifier.coef_ [ 0 ]、feature_names))[: 20 ] |
結論
このチュートリアルでは、MLアルゴリズムのみを使用しましたが、他のニューラルネットワーク手法も使用します。 さらに、テキストデータをベクトル化するために、TF-IDFベクトライザーを使用しました。 Count Vectorizer、Hashing Vectorizerなどのベクトル化機能もありますが、これらは作業をより効果的に行うことができます。 他のアルゴリズムや手法を試してみて、より良い結果が得られるかどうかを確認してください。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのエグゼクティブPGプログラムをご覧ください。このプログラムは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIITを提供しています。 -B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との雇用支援。
なぜ偽のニュースを検出する必要があるのですか?
現在の状況では、ソーシャルメディアプラットフォームは、ユーザーがアイデアについて話し合ったり交換したり、民主主義、教育、健康などの主題について議論したりできるため、非常に強力で価値があります。 ただし、特定のエンティティは、特定の状況で金銭的利益を得るため、および偏見のある視点を生み出し、考え方を変え、他の状況で風刺やばかげたことを広めるために、そのようなプラットフォームをうまく利用しません。 フェイクニュースはこの現象の用語です。 現実に従わないアイテムをオンラインで投稿することが急増しているため、政治、スポーツ、健康、科学、その他の分野で多くの問題が発生しています。
フェイクニュースの検出を主に利用している企業はどれですか?
フェイクニュースの検出は、ソーシャルメディアやニュースWebサイトなどのプラットフォームで使用されます。 Facebook、Instagram、Twitterなどのソーシャルメディアの巨人は、ユーザーの大多数が最新の情報を入手するために毎日のニュースソースとしてそれらに依存しているため、フェイクニュースに対して脆弱です。 偽の検出技術は、メディア企業が持っている情報の信憑性を判断するためにも使用されます。 電子メールは、個人がニュースを受信するためのもう1つの媒体であり、そのため、個人の信憑性を特定して検証することは困難です。 デマ、スパム、ジャンクメールは、電子メールで送信されることでよく知られています。 その結果、電子メールプラットフォームの大部分は、スパムや迷惑メールを識別するために誤ったニュース検出を採用しています。