
Pythonでの探索的データ分析:知っておくべきこと
公開: 2021-03-12探索的データ分析(EDA)は、すべてのデータサイエンティストが従う、非常に一般的で重要な手法です。 それを完全に理解するために、さまざまな角度からテーブルとデータのテーブルを見るプロセスです。 データをよく理解することで、データを整理して要約することができます。これにより、他の方法では不明確だった洞察と傾向が明らかになります。
EDAには、たとえば「データ分析」のように従う必要のあるハードコアなルールのセットはありません。 この分野に不慣れな人は、常に2つの用語を混同する傾向があります。これらの用語はほとんど同じですが、目的が異なります。 EDAとは異なり、データ分析は、さまざまなバリアント間の事実と関係を明らかにするための確率と統計的手法の実装に傾倒しています。
戻ってきて、EDAを実行する正しい方法も間違った方法もありません。 それは人によって異なりますが、一般的に従ういくつかの主要なガイドラインが以下にリストされています。
- 欠落値の処理:収集中にすべてのデータが使用可能または記録されていない可能性がある場合、ヌル値が表示される可能性があります。
- 重複データの削除:繰り返しデータレコードを使用して機械学習アルゴリズムのトレーニング中に発生する過剰適合やバイアスを防ぐことが重要です
- 外れ値の処理:外れ値は、他のデータとは大幅に異なり、傾向に従わないレコードです。 これは、データ収集中の特定の例外または不正確さが原因で発生する可能性があります
- スケーリングと正規化:これは、数値データ変数に対してのみ実行されます。 ほとんどの場合、変数の範囲とスケールは大きく異なるため、変数を比較して相関関係を見つけることは困難です。
- 単変量および二変量解析:単変量解析は通常、1つの変数がターゲット変数にどのように影響しているかを確認することによって行われます。 二変量解析は、任意の2つの変数間で実行され、数値またはカテゴリ、あるいはその両方になります。
ここでKaggleで入手できる非常に有名な「ホームクレジットデフォルトリスク」データセットを使用して、これらのいくつかがどのように実装されているかを見ていきます。 データには、ローン申請時のローン申請者に関する情報が含まれています。 これには、次の2種類のシナリオが含まれています。
- 支払いが困難なクライアント:X日以上支払いが遅れた
サンプルのローンの最初のY回の分割払いの少なくとも1つで、
- 他のすべての場合:支払いが時間通りに支払われる他のすべての場合。
この記事では、アプリケーションデータファイルのみを扱います。
関連:初心者向けのPythonプロジェクトのアイデアとトピック
目次
データを見る
app_data = pd.read_csv('application_data.csv')
app_data.info()
アプリケーションデータを読み取った後、info()関数を使用して、処理するデータの概要を取得します。 以下の出力は、122個の変数を持つ約300000件のローンレコードがあることを示しています。 これらのうち、16のカテゴリ変数と残りの数値があります。
<クラス'pandas.core.frame.DataFrame'>
RangeIndex:307511エントリ、0〜307510
列:122エントリ、SK_ID_CURRからAMT_REQ_CREDIT_BUREAU_YEAR
dtypes:float64(65)、int64(41)、object(16)
メモリ使用量:286.2+ MB
数値データとカテゴリデータを別々に処理および分析することは、常に良い習慣です。
categorical = app_data.select_dtypes(include = object).columns
app_data [categorical] .apply(pd.Series.nunique、axis = 0)
以下のカテゴリ機能のみを見ると、それらのほとんどには、単純なプロットを使用して分析しやすいように、いくつかのカテゴリしかないことがわかります。
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype:int64
ここで、数値機能について、describe()メソッドはデータの統計を提供します。
numer = app_data.describe()
数値=numer.columns
numer
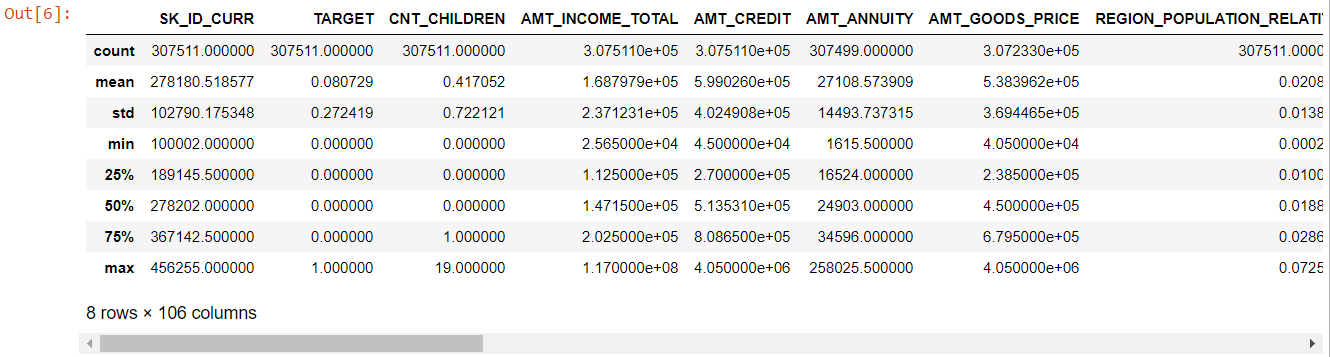
表全体を見ると、次のことが明らかです。
- days_birthは負です:申請日に対する申請者の年齢(日数)
- days_employedには外れ値があります(最大値は約100年です)(635243)
- amt_annuity-最大値よりはるかに小さいことを意味します
これで、どの機能をさらに分析する必要があるかがわかりました。
欠測データ
Y軸に沿って欠測データの割合をプロットすることにより、欠測値を持つすべての特徴のポイントプロットを作成できます。

行方不明=pd.DataFrame((app_data.isnull()。sum())* 100 / app_data.shape [0])。reset_index()
plt.figure(figsize =(16,5))
ax = sns.pointplot('index'、0、data = missing)
plt.xticks(rotation = 90、fontsize = 7)
plt.title( "欠落値のパーセンテージ")
plt.ylabel( "PERCENTAGE")
plt.show()
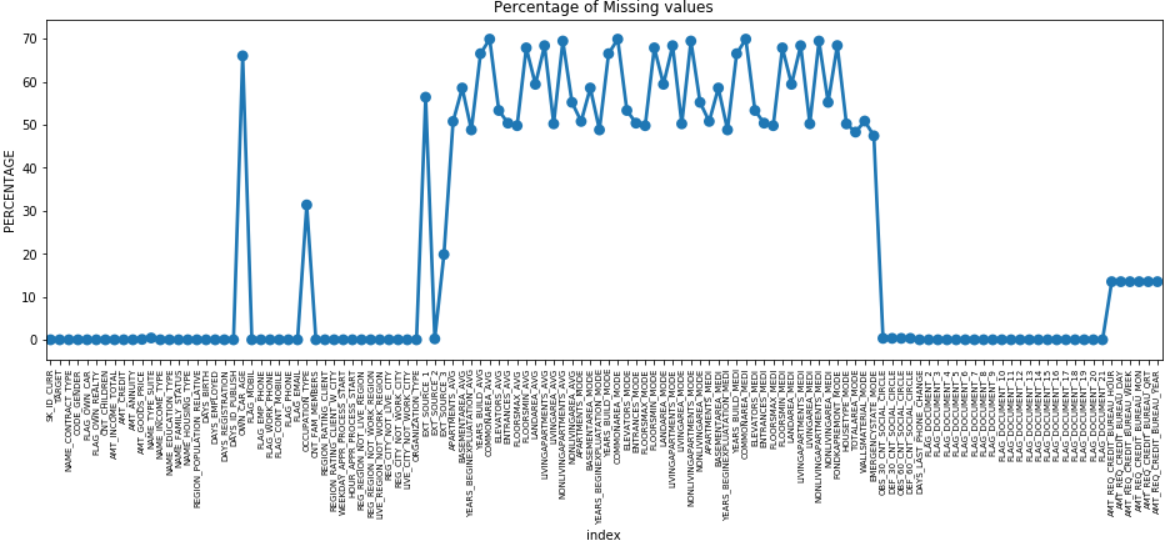
多くの列には多くの欠測データ(30〜70%)があり、一部の列には欠測データがほとんどなく(13〜19%)、多くの列にも欠測データがまったくありません。 EDAを実行するだけの場合は、データセットを変更する必要はありません。 ただし、データの前処理を進めるには、欠落している値を処理する方法を知っておく必要があります。
欠落値が少ない機能の場合、機能に応じて、回帰を使用して欠落値を予測するか、存在する値の平均を埋めることができます。 また、欠落している値の数が非常に多い機能の場合、分析に関する洞察が非常に少ないため、これらの列を削除することをお勧めします。
データの不均衡
このデータセットでは、ローンの不履行者はバイナリ変数「TARGET」を使用して識別されます。
100 * app_data ['TARGET']。value_counts()/ len(app_data ['TARGET'])
091.927118
1 8.072882
名前:TARGET、dtype:float64
データは92:8の比率で非常に不均衡であることがわかります。 ほとんどのローンは期限内に返済されました(目標= 0)。 したがって、このような大きな不均衡がある場合は常に、機能を取得してターゲット変数と比較し(ターゲット分析)、それらの機能のどのカテゴリが他のカテゴリよりもローンのデフォルトになる傾向があるかを判断することをお勧めします。
以下は、Pythonのseabornライブラリと単純なユーザー定義関数を使用して作成できるグラフのほんの数例です。
性別
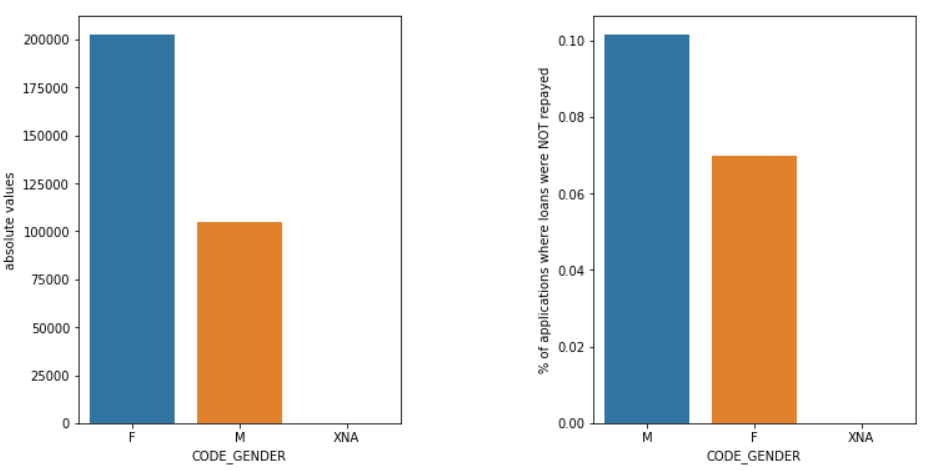
女性の応募者数はほぼ2倍ですが、男性(M)は女性(F)に比べて債務不履行の可能性が高くなっています。 したがって、女性は男性よりもローンの返済の信頼性が高くなります。
教育タイプ
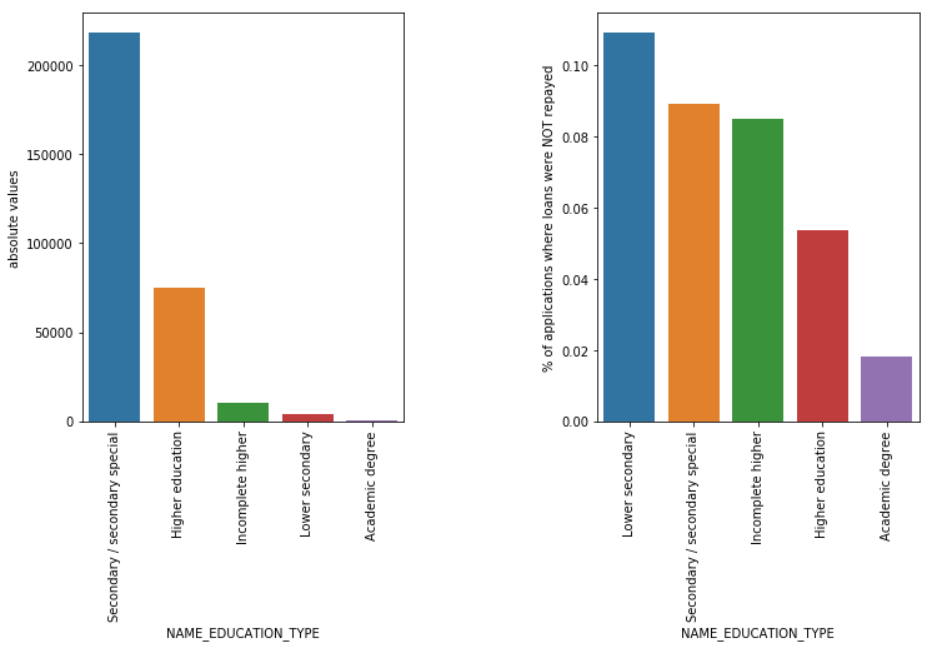
ほとんどの学生ローンは中等教育または高等教育向けですが、会社にとって最もリスクが高いのは中等教育ローンであり、次に中等教育ローンが続きます。
また読む:データサイエンスのキャリア
結論
上記のような分析は、銀行や金融サービスのリスク分析で広く行われています。 このようにして、データアーカイブを使用して、顧客への貸し出し中にお金を失うリスクを最小限に抑えることができます。 他のすべてのセクターにおけるEDAの範囲は無限であり、広く使用する必要があります。
データサイエンスについて知りたい場合は、IIIT-BとupGradのデータサイエンスのエグゼクティブPGをご覧ください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップ、1- on-1業界のメンター、400時間以上の学習、トップ企業との仕事の支援。
探索的データ分析は、データのモデリングを開始するときの初期レベルと見なされます。 これは、データをモデル化するためのベストプラクティスを分析するための非常に洞察に満ちた手法です。 データから視覚的なプロット、グラフ、およびレポートを抽出して、データを完全に理解することができます。 外れ値は、データの異常またはわずかな分散を指します。 これは、データ収集中に発生する可能性があります。 データセット内の外れ値を検出する方法は4つあります。 これらの方法は次のとおりです。 データ分析とは異なり、EDAについて従うべき厳格な規則や規制はありません。 これが正しい方法であるとか、EDAを実行するための間違った方法であるとは言えません。 初心者はしばしば誤解され、EDAとデータ分析の間で混乱します。探索的データ分析(EDA)が必要なのはなぜですか?
EDAには、統計結果の導出、欠落データ値の検出、誤ったデータエントリの処理、最終的にさまざまなプロットやグラフの推定など、データを完全に分析するための特定の手順が含まれます。
この分析の主な目的は、使用しているデータセットがモデリングアルゴリズムの適用を開始するのに適していることを確認することです。 これが、モデリング段階に移行する前にデータに対して実行する必要がある最初のステップである理由です。 外れ値とは何ですか?それらを処理する方法は?
1.箱ひげ図-箱ひげ図は、四分位数でデータを分離する外れ値を検出する方法です。
2.散布図-散布図は、デカルト平面上にマークされた点のコレクションの形式で2つの変数のデータを表示します。 一方の変数の値は水平軸(x-ais)を表し、もう一方の変数の値は垂直軸(y軸)を表します。
3. Zスコア-Zスコアを計算する際に、中心から遠く離れたポイントを探し、それらを外れ値と見なします。
4.四分位範囲(IQR)-四分位範囲またはIQRは、上位四分位範囲と下位四分位範囲、または75番目と25番目の四分位数の差であり、統計的分散と呼ばれることがよくあります。 EDAを実行するためのガイドラインは何ですか?
ただし、一般的に実践されているガイドラインがいくつかあります。
1.欠落値の処理
2.重複データの削除
3.外れ値の処理
4.スケーリングと正規化
5.単変量および二変量解析