
Pythonの探索的データ分析とは何ですか? ゼロから学ぶ
公開: 2021-03-04探索的データ分析(EDA)は、要するに、データサイエンスプロジェクトのほぼ70%を占めています。 EDAは、さまざまな分析ツールを使用してデータから推論統計を取得することにより、データを探索するプロセスです。 これらの調査は、単純な数値を確認するか、さまざまなタイプのグラフやチャートをプロットすることによって行われます。
各グラフまたはチャートは、同じデータに対する異なるストーリーと角度を示しています。 ほとんどのデータ分析とクリーニングの部分では、Pandasが最も使用されているツールです。 視覚化とグラフ/チャートのプロットには、Matplotlib、Seaborn、Plotlyなどのプロットライブラリが使用されます。
EDAは、データを告白するため、実行する必要があります。 非常に優れたEDAを実行するデータサイエンティストはデータについて多くのことを知っているため、構築するモデルは、優れたEDAを実行しないデータサイエンティストよりも自動的に優れています。
このチュートリアルを終えると、次のことがわかります。
- データの基本的な概要を確認する
- データの記述統計を確認する
- 列名とデータ型の操作
- 欠落値と重複行の処理
- 二変量解析
目次
データの基本的な概要
このチュートリアルでは、KaggleからダウンロードできるCarsデータセットを使用します。 ほとんどすべてのデータセットの最初のステップは、データセットをインポートして、その基本的な概要(形状、列、列タイプ、上位5行など)を確認することです。このステップでは、操作するデータの概要を簡単に確認できます。 Pythonでこれを行う方法を見てみましょう。
| #必要なライブラリをインポートする パンダをpdとしてインポートします numpyをnpとしてインポートします Seabornをsns # visualisationとしてインポートします matplotlib.pyplotをplt #visualisationとしてインポートします %matplotlibインライン sns.set(color_codes = True ) |
データヘッドとテール
| data = pd.read_csv( “ path / dataset.csv” ) #データフレームの上位5行を確認します data.head() |
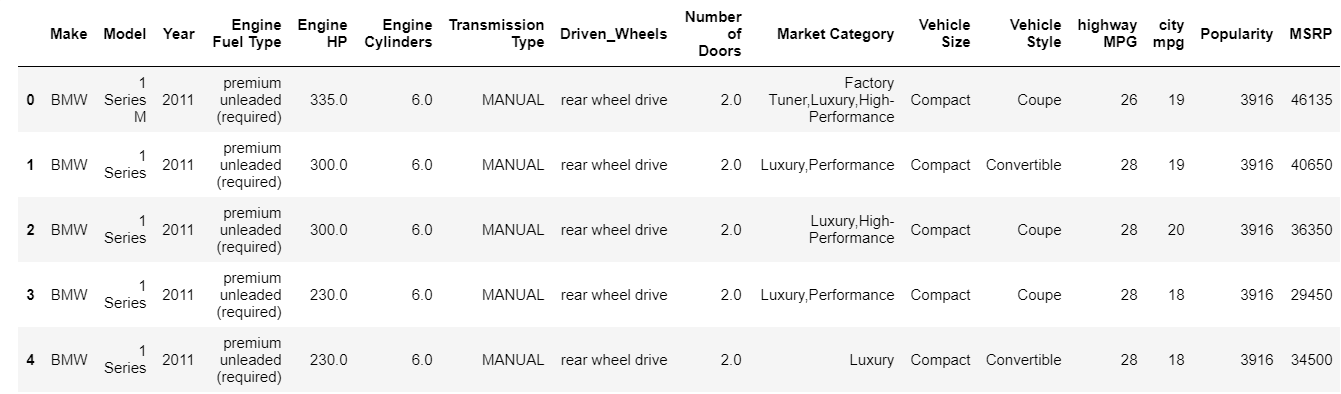
head関数は、デフォルトでデータフレームの上位5つのインデックスを出力します。 また、その値をヘッドにバイパスして表示する必要がある上位インデックスの数を指定することもできます。 ヘッドを印刷すると、データの種類、存在する機能の種類、およびそれらに含まれる値をすばやく確認できます。 もちろん、これはデータの全体像を示すものではありませんが、データを簡単に確認することができます。 同様に、tail関数を使用して、データフレームの下部を印刷できます。
| #データフレームの最後の10行を印刷します data.tail( 10 ) |
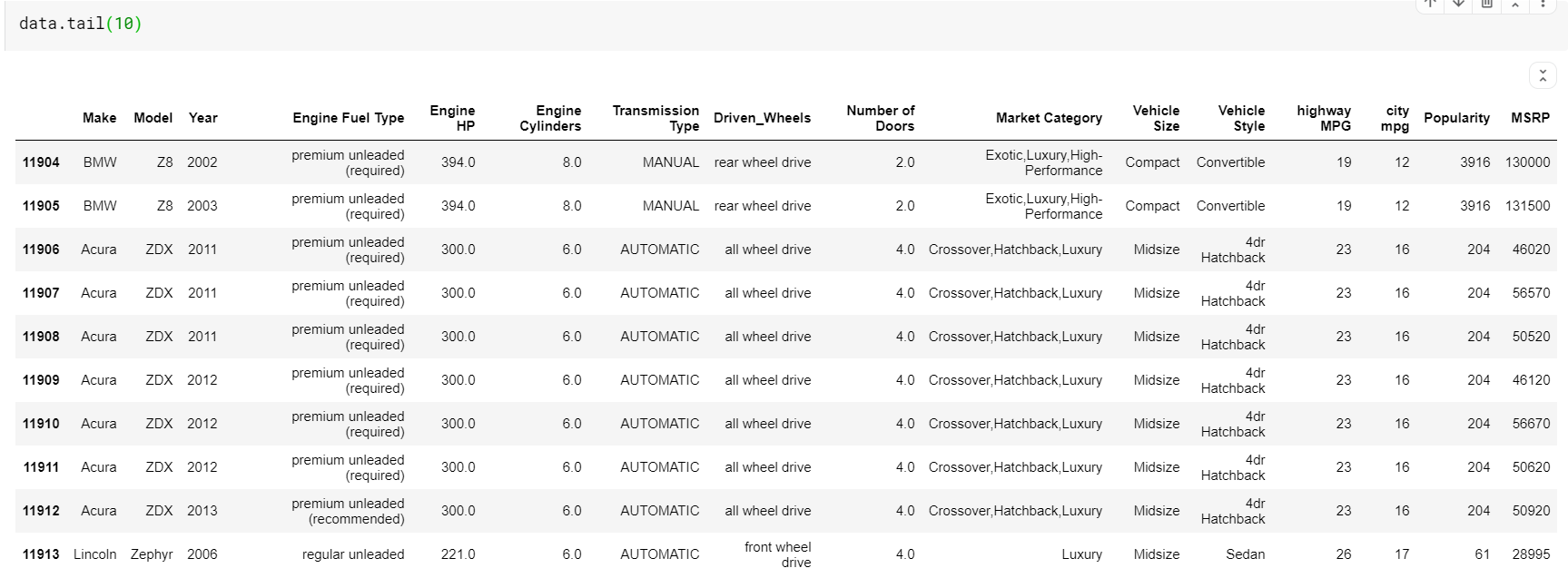
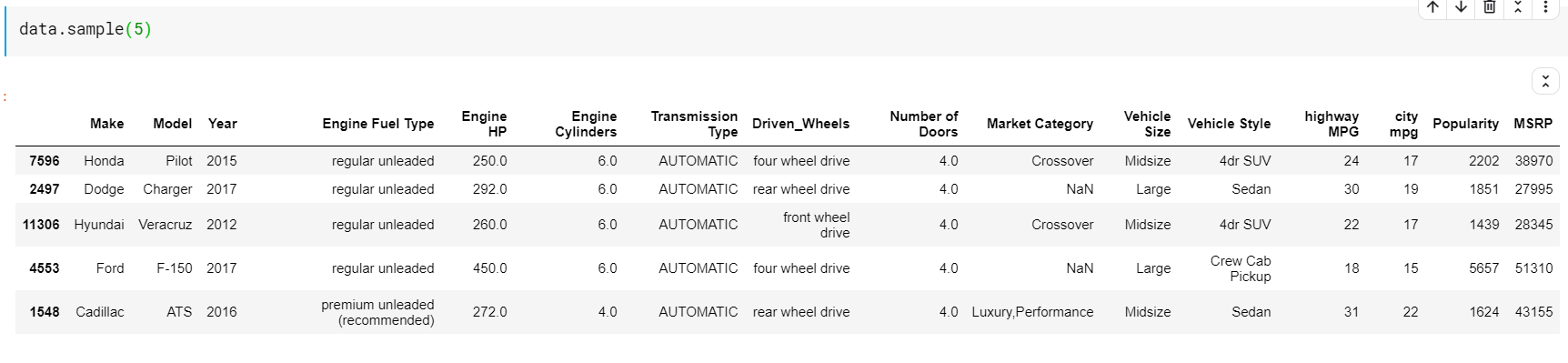
ここで注意すべきことの1つは、関数headとtailの両方がtopまたはbottomインデックスを提供することです。 ただし、一番上の行または一番下の行は、必ずしもデータの良いプレビューであるとは限りません。 したがって、sample()関数を使用して、データセットからランダムにサンプリングされた任意の数の行を出力することもできます。
| #ランダムな5行を印刷 data.sample( 5 ) |
記述統計
次に、データセットの記述統計を確認しましょう。 記述統計は、データセットを「説明する」すべてのもので構成されます。 データフレームの形状、すべての列が存在するか、すべての数値およびカテゴリの特徴が存在するかを確認します。 また、これらすべてを単純な関数で行う方法についても説明します。
形
| #データフレームの形状を確認する(mxn) #m=行数 #n=列数 data.shape |

ご覧のとおり、このデータフレームには11914行と16列が含まれています。
列
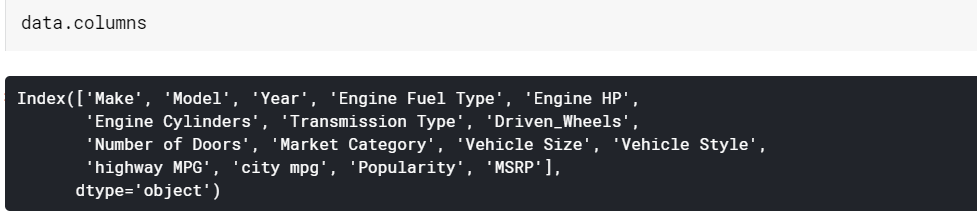
| #列名を出力します data.columns |
データフレーム情報
| #列のデータ型と欠落していない値の数を出力します data.info() |
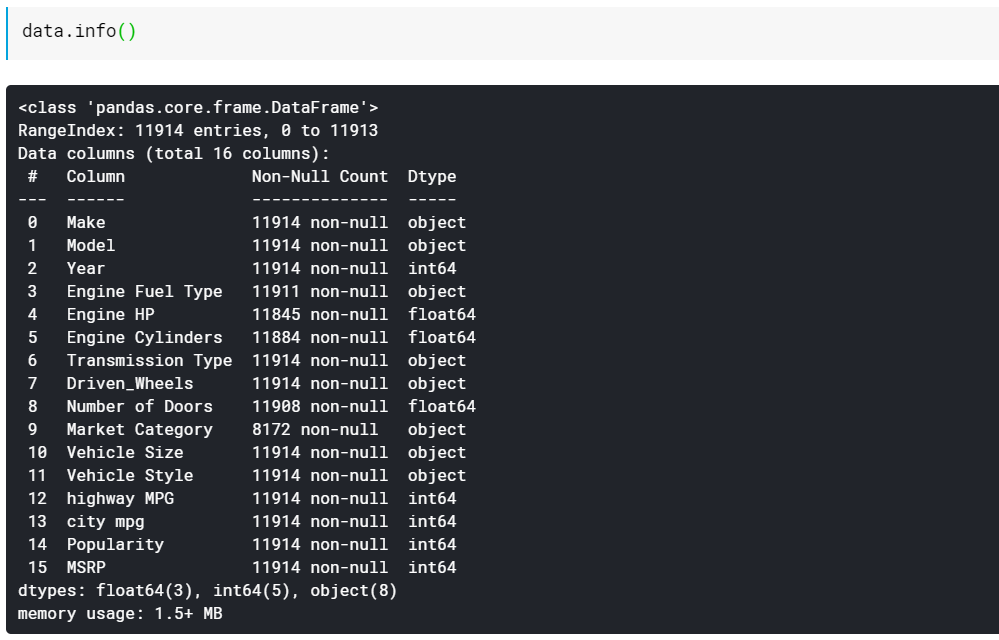
ご覧のとおり、info()関数はすべての列、それらの列に存在するnull以外の値または欠落していない値の数、最後にそれらの列のデータ型を提供します。 これは、すべての機能が数値であり、すべてがカテゴリ/テキストベースであるかをすばやく確認するための優れた方法です。 また、すべての列に欠落している値に関する情報があります。 欠落している値を処理する方法については、後で説明します。
列名とデータ型の操作
EDAでは、各列を注意深くチェックして操作することが非常に重要です。 列/機能に含まれるすべてのタイプのコンテンツと、パンダがそのデータ型を読み取ったものを確認する必要があります。 数値データ型は主にint64またはfloat64です。 テキストベースまたはカテゴリ機能には、「オブジェクト」データ型が割り当てられます。
日時ベースの機能が割り当てられますパンダが機能のデータ型を理解しない場合があります。 そのような場合、それはただ怠惰にそれに'オブジェクト'データ型を割り当てます。 read_csvを使用してデータを読み取るときに、列のデータ型を明示的に指定できます。
カテゴリ列と数値列の選択
| #すべてのカテゴリ列と数値列を個別のリストに追加します categorical = data.select_dtypes( 'object' ).columns 数値=data.select_dtypes( 'number' ).columns |


ここで、「number」として渡した型は、int64またはfloat64などの任意の種類の数値を持つデータ型を持つすべての列を選択します。
列の名前を変更する
| #列名の名前を変更する data = data.rename(columns = { “ Engine HP” : “ HP” 、 「エンジンシリンダー」 : 「シリンダー」 、 「送信タイプ」 : 「送信」 、 「drived_Wheels」 : 「ドライブモード」 、 「高速道路MPG」 : 「MPG-H」 、 「希望小売価格」 : 「価格」 }) data.head( 5 ) |

名前変更関数は、名前を変更する列名とその新しい名前を含む辞書を取り込むだけです。
欠落値と重複行の処理
欠落値は、実際のデータセットで最も一般的な問題/不一致の1つです。 欠落している値を処理する方法は複数あるため、それ自体が大きなトピックです。 いくつかの方法はより一般的な方法であり、いくつかは処理している可能性のあるデータセットに固有のものです。
欠落している値の確認
| #不足している値を確認する data.isnull()。sum() |
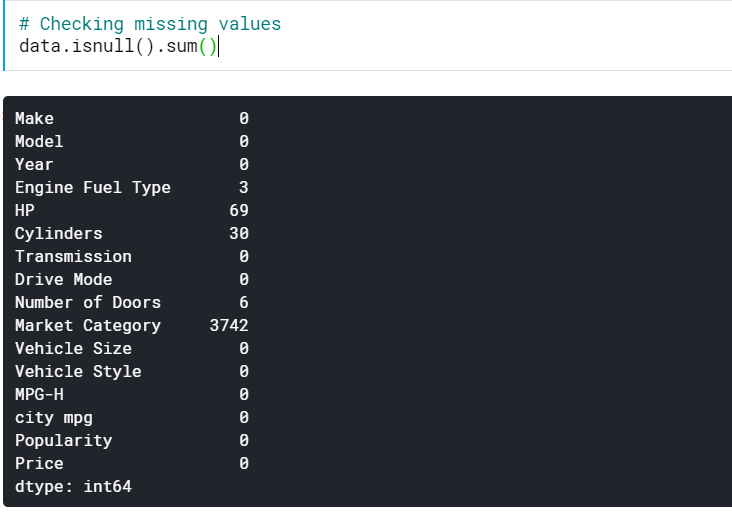
これにより、すべての列で欠落している値の数がわかります。 欠落している値のパーセンテージも確認できます。
| #欠落値の割合 data.isnull()。mean()* 100 |
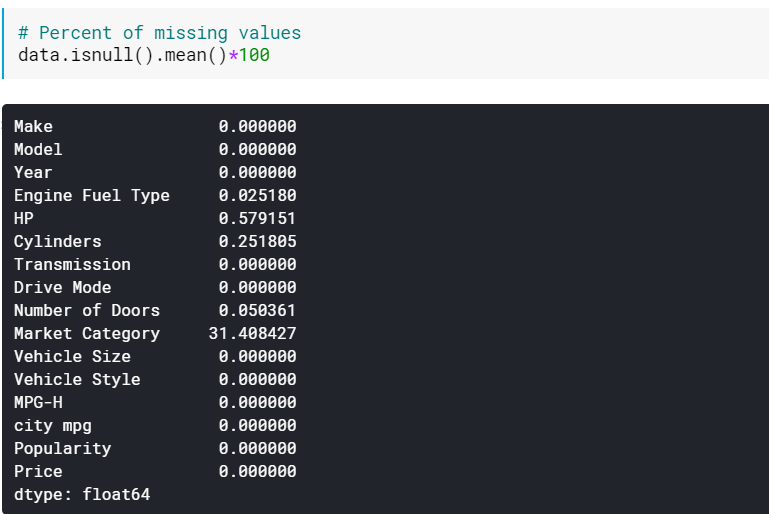
値が欠落している列が多数ある場合は、パーセンテージを確認すると役立つ場合があります。 このような場合、欠落している値が多い(たとえば、60%を超える欠落している)列を削除することができます。
欠落値の代入
| #平均で数値列の欠落値を代入する data [numerical] = data [numerical] .fillna(data [numerical] .mean()。iloc [ 0 ]) #モードごとにカテゴリ列の欠落値を代入する data [categorical] = data [categorical] .fillna(data [categorical] .mode()。iloc [ 0 ]) |
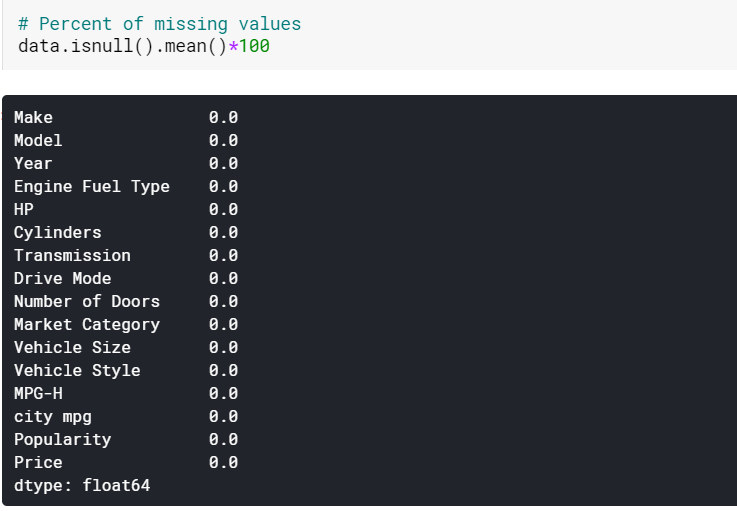
ここでは、数値列の欠落値をそれぞれの平均で代入し、カテゴリ列の欠落値をモードで代入します。 ご覧のとおり、現在、欠測値はありません。
これは値を代入する最も原始的な方法であり、補間、KNNなどのより高度な方法が開発されている実際のケースでは機能しないことに注意してください。
重複する行の処理
| #重複する行を削除する data.drop_duplicates(inplace = True ) |
これにより、重複する行が削除されます。
チェックアウト: Pythonプロジェクトのアイデアとトピック
二変量解析
次に、二変量解析を実行してより多くの洞察を得る方法を見てみましょう。 二変量とは、2つの変数または特徴で構成される分析を意味します。 さまざまなタイプの機能に使用できるさまざまなタイプのプロットがあります。
数値の場合–数値
- 散布図
- 折れ線グラフ
- 相関関係のヒートマップ
カテゴリカル-数値の場合
- 棒グラフ
- バイオリン図
- スウォームプロット
カテゴリカルの場合-カテゴリカル
- 棒グラフ
- ポイントプロット
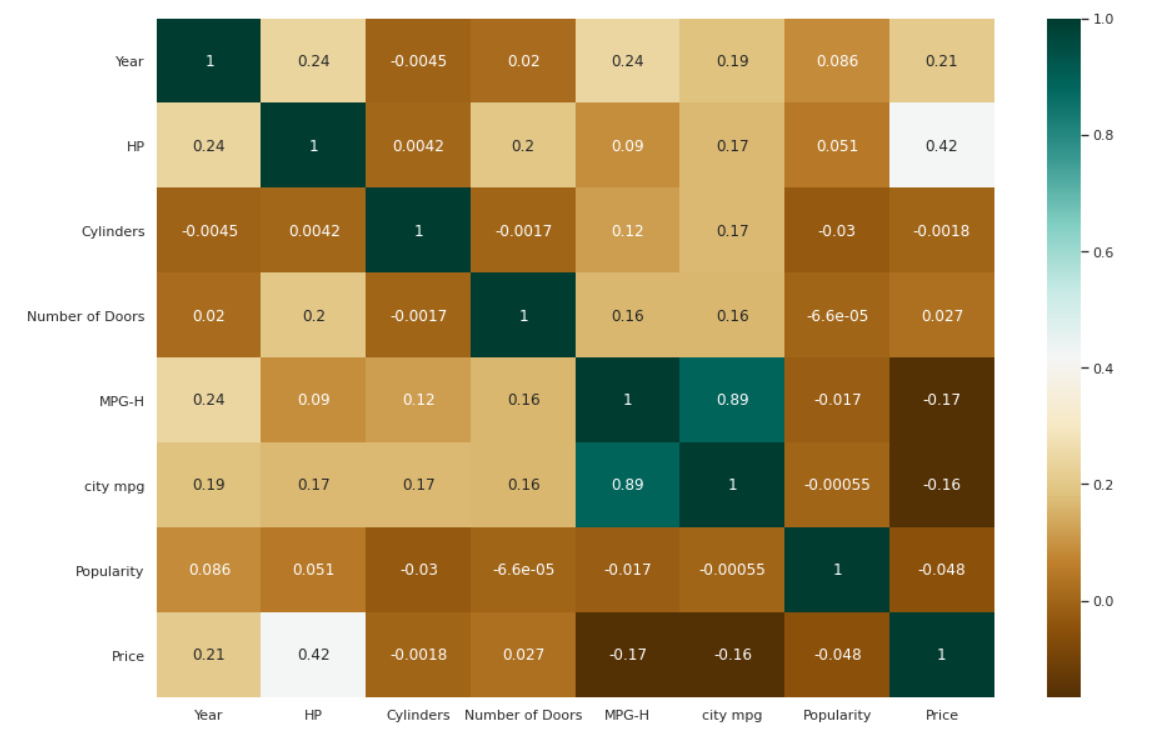
相関関係のヒートマップ
| #変数間の相関をチェックします。 plt.figure(figsize = ( 15、10 ) ) c = data.corr() sns.heatmap(c、cmap = “ BrBG” 、annot = True ) |
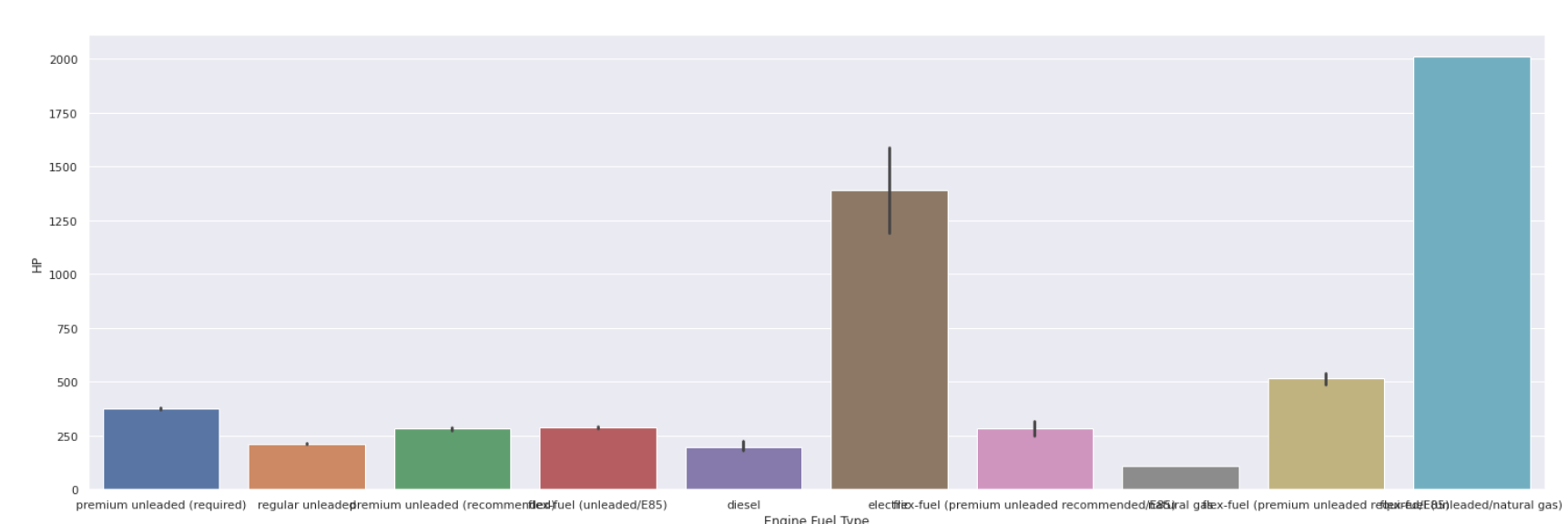
棒グラフ
| sns.barplot(data [ 'エンジン燃料タイプ' ]、data [ 'HP' ]) |
世界のトップ大学からデータサイエンス認定を取得します。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを学び、キャリアを早急に進めましょう。
結論
これまで見てきたように、データセットを探索する際にカバーする必要のある多くのステップがあります。 このチュートリアルではほんの一握りの側面しか取り上げませんでしたが、これにより、優れたEDAの基本的な知識以上のものが得られます。
Python、データサイエンスのすべてについて知りたい場合は、IIIT-BとupGradのデータサイエンスのPGディプロマをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界とのメンターシップを提供します。専門家、業界のメンターと1対1で、400時間以上の学習とトップ企業との仕事の支援。
探索的データ分析の手順は何ですか?
探索的データ分析を行うために実行する必要がある主な手順は次のとおりです。
変数とデータ型を特定する必要があります。
基本的な指標の分析
単変量非グラフィカル分析
単変量グラフィカル分析
二変量データの分析
可変の変換
不足している値の処理
外れ値の処理
相関の分析
次元削減
探索的データ分析の目的は何ですか?
EDAの主な目標は、仮定を行う前にデータの分析を支援することです。 これは、明らかなエラーの検出、データパターンの理解の向上、外れ値や異常なイベントの検出、変数間の興味深い関係の発見に役立ちます。
データサイエンティストは探索的分析を使用して、作成した結果が正確で、対象となるビジネスの成果と目標に適切であることを保証できます。 EDAはまた、利害関係者が適切な質問に確実に対応できるようにすることで、利害関係者を支援します。 標準偏差、カテゴリデータ、および信頼区間はすべてEDAで回答できます。 EDAの完了と洞察の抽出に続いて、その機能を機械学習を含むより高度なデータ分析またはモデリングに適用できます。
さまざまな種類の探索的データ分析とは何ですか?
EDA手法には、グラフィカルと定量的(非グラフィカル)の2種類があります。 一方、定量的アプローチでは要約統計量を編集する必要がありますが、グラフィカルな方法では、図式的または視覚的な方法でデータを収集する必要があります。 単変量および多変量アプローチは、これら2つのタイプの方法論のサブセットです。
関係を調査するために、単変量アプローチは一度に1つの変数(データ列)を調べますが、多変量メソッドは一度に2つ以上の変数を調べます。 単変量および多変量のグラフィカルおよび非グラフィカルは、EDAの4つの形式です。 定量的手順はより客観的ですが、絵画的方法はより主観的です。