
Node.jsとPuppeteerを使用した動的Webサイトの倫理的スクレイピングガイド
公開: 2022-03-10Webスクレイピングが実際に何を意味するかについての小さなセクションから始めましょう。 私たち全員が日常生活でウェブスクレイピングを使用しています。 Webサイトから情報を抽出するプロセスを説明しているだけです。 したがって、お気に入りの麺料理のレシピをインターネットから個人のノートブックにコピーして貼り付けると、 Webスクレイピングが実行されます。
ソフトウェア業界でこの用語を使用する場合、通常、ソフトウェアを使用してこの手動タスクを自動化することを指します。 前の「麺料理」の例に固執すると、このプロセスには通常2つのステップが含まれます。
- ページを取得する
まず、ページ全体をダウンロードする必要があります。 この手順は、手動でスクレイピングするときにWebブラウザでページを開くようなものです。 - データの解析
次に、WebサイトのHTMLでレシピを抽出し、JSONやXMLなどの機械可読形式に変換する必要があります。
これまで、私は多くの企業でデータコンサルタントとして働いてきました。 ほんの数行のコードで簡単に自動化できるにもかかわらず、データの抽出、集計、および強化のタスクがまだ手動で実行されていることに驚きました。 それこそが、私にとってWebスクレイピングのすべてです。つまり、Webサイトから貴重な情報を抽出して正規化し、価値を高める別のビジネスプロセスを促進します。
この間、企業があらゆる種類のユースケースにWebスクレイピングを使用しているのを見ました。 投資会社は主に、商品レビュー、価格情報、ソーシャルメディアの投稿など、金融投資を支えるための代替データの収集に重点を置いていました。
これが1つの例です。 クライアントから、評価、レビュー担当者の場所、送信された各レビューのレビューテキストなど、いくつかのeコマースWebサイトからの製品の広範なリストの製品レビューデータを取得するように依頼されました。 結果データにより、クライアントはさまざまな市場での製品の人気に関する傾向を特定できました。 これは、一見「役に立たない」単一の情報が、大量の情報と比較してどのように価値があるかを示す優れた例です。
他の企業は、リード生成にWebスクレイピングを使用することにより、販売プロセスを加速しています。 このプロセスには通常、特定のWebサイトのリストの電話番号、電子メールアドレス、連絡先名などの連絡先情報を抽出することが含まれます。 このタスクを自動化することで、営業チームは見込み客にアプローチするための時間を増やすことができます。 したがって、販売プロセスの効率が向上します。
ルールに固執する
LinkedinとHiQの訴訟の管轄によって確認されているように、一般に、公開されているデータをWebスクレイピングすることは合法です。 しかし、私は新しいWebスクレイピングプロジェクトを開始するときに固執したい倫理的な一連のルールを設定しました。 これも:
- robots.txtファイルを確認しています。
通常、ページの所有者がロボットやスクレーパーからアクセスできるサイトの部分に関する明確な情報が含まれており、アクセスしてはならないセクションが強調表示されています。 - 利用規約を読む。
robots.txtと比較すると、この情報はそれほど頻繁には利用できませんが、通常はデータスクレイパーの処理方法を示しています。 - 適度な速度でこする。
スクレイピングは、ターゲットサイトのインフラストラクチャにサーバーの負荷をかけます。 スクレープする対象とスクレーパーが動作している同時実行のレベルによっては、トラフィックがターゲットサイトのサーバーインフラストラクチャに問題を引き起こす可能性があります。 もちろん、サーバー容量はこの方程式で大きな役割を果たします。 したがって、私のスクレーパーの速度は、常に、私がスクレイピングしようとしているデータの量とターゲットサイトの人気の間のバランスです。 このバランスを見つけるには、「計画された速度によってサイトのオーガニックトラフィックが大幅に変わるか」という1つの質問に答えることで達成できます。 サイトの自然なトラフィック量がわからない場合は、ahrefsなどのツールを使用して大まかなアイデアを取得します。
適切なテクノロジーの選択
実際、ヘッドレスブラウザーを使用したスクレイピングは、インフラストラクチャに大きな影響を与えるため、使用できるパフォーマンスが最も低いテクノロジーの1つです。 マシンのプロセッサの1つのコアで、約1つのChromeインスタンスを処理できます。
簡単な計算例を実行して、これが実際のWebスクレイピングプロジェクトにとって何を意味するかを見てみましょう。
シナリオ
- 20,000のURLをスクレイプしたいとします。
- ターゲットサイトからの平均応答時間は6秒です。
- サーバーには2つのCPUコアがあります。
プロジェクトの完了には16時間かかります。
したがって、動的Webサイトのスクレイピング実現可能性テストを実行するときは、常にブラウザーの使用を避けようとします。
これが私がいつも通っている小さなチェックリストです:
- URLのGETパラメータを使用して必要なページ状態を強制できますか? はいの場合、パラメータを追加してHTTPリクエストを実行するだけです。
- 動的情報はページソースの一部であり、DOMのどこかにあるJavaScriptオブジェクトを介して利用できますか? はいの場合、通常のHTTPリクエストを再度使用して、文字列化されたオブジェクトのデータを解析できます。
- データはXHRリクエストを介してフェッチされますか? その場合、HTTPクライアントを使用してエンドポイントに直接アクセスできますか? はいの場合、HTTPリクエストをエンドポイントに直接送信できます。 多くの場合、応答はJSONでフォーマットされているため、私たちの生活ははるかに楽になります。
すべての質問に明確な「いいえ」で回答した場合、HTTPクライアントを使用するための実行可能なオプションが正式に不足します。 もちろん、私たちが試すことができるサイト固有の微調整があるかもしれませんが、通常、ヘッドレスブラウザのパフォーマンスが遅いのに比べて、それらを理解するのに必要な時間は長すぎます。 ブラウザでスクレイピングすることの利点は、次の基本的なルールに従うものなら何でもスクレイピングできることです。
ブラウザでアクセスできれば、こすり落とすことができます。
スクレーパーの例として、https://quotes.toscrape.com/search.aspxのサイトを取り上げましょう。 それはトピックのリストのために与えられた著者のリストからの引用を特徴とします。 すべてのデータはXHRを介してフェッチされます。
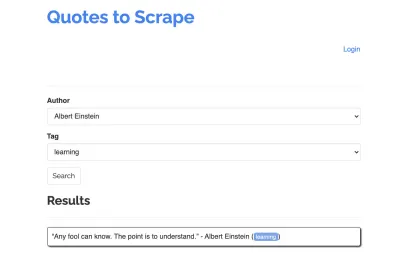
サイトの機能を詳しく調べて上記のチェックリストを確認した人は、見積もりエンドポイントで直接POSTリクエストを行うことで見積もりを取得できるため、HTTPクライアントを使用して見積もりを実際に取得できることに気付いたと思います。 ただし、このチュートリアルでは、Puppeteerを使用してWebサイトをスクレイプする方法について説明することになっているため、これは不可能であると偽ります。
前提条件のインストール
Node.jsを使用してすべてをビルドするので、最初に新しいフォルダーを作成して開き、その中に新しいNodeプロジェクトを作成して、次のコマンドを実行します。
mkdir js-webscraper cd js-webscraper npm initnpmがすでにインストールされていることを確認してください。 インストーラーは、このプロジェクトに関するメタ情報についていくつか質問します。Enterキーを押すと、スキップできます。
Puppeteerのインストール
以前、ブラウザでスクレイピングすることについて話していました。 PuppeteerはNode.jsAPIであり、プログラムでヘッドレスChromeインスタンスと通信できます。
npmを使用してインストールしましょう:
npm install puppeteerスクレーパーの構築
それでは、 scraper.jsという新しいファイルを作成して、スクレーパーの作成を始めましょう。
まず、以前にインストールしたライブラリPuppeteerをインポートします。
const puppeteer = require('puppeteer');次のステップとして、非同期の自己実行関数内で新しいブラウザインスタンスを開くようにPuppeteerに指示します。
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();注:デフォルトでは、パフォーマンスが向上するため、ヘッドレスモードはオフになっています。 ただし、新しいスクレーパーを作成するときは、ヘッドレスモードをオフにするのが好きです。 これにより、ブラウザが実行しているプロセスを追跡し、レンダリングされたすべてのコンテンツを確認できます。 これは、後でスクリプトをデバッグするのに役立ちます。
開いたブラウザインスタンス内で、新しいページを開き、ターゲットURLに直接アクセスします。
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); 非同期関数の一部として、 awaitステートメントを使用して、次のコマンドが実行されるのを待ってから、次のコード行に進みます。
ブラウザウィンドウを正常に開いてページに移動したので、Webサイトの状態を作成する必要があります。これにより、必要な情報がスクレイピング用に表示されます。
利用可能なトピックは、選択した作成者に対して動的に生成されます。 したがって、最初に「Albert Einstein」を選択し、生成されたトピックのリストを待ちます。 リストが完全に生成されたら、トピックとして「学習」を選択し、2番目のフォームパラメータとして選択します。 次に、[送信]をクリックして、結果を保持しているコンテナから取得した見積もりを抽出します。
これをJavaScriptロジックに変換するので、最初に、前の段落で説明したすべての要素セレクターのリストを作成しましょう。
| 著者選択フィールド | #author |
| タグ選択フィールド | #tag |
| 送信ボタン | input[type="submit"] |
| 見積もりコンテナ | .quote |
ページの操作を開始する前に、スクリプトに次の行を追加して、アクセスするすべての要素が表示されていることを確認します。
await page.waitForSelector('#author'); await page.waitForSelector('#tag');次に、2つの選択フィールドの値を選択します。
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');これで、ページの[検索]ボタンを押して検索を実行し、引用符が表示されるのを待つ準備ができました。
await page.click('.btn'); await page.waitForSelector('.quote'); ページのHTMLDOM構造にアクセスするため、提供されたpage.evaluate()関数を呼び出して、引用符を保持しているコンテナーを選択します(この場合は1つだけです)。 次に、オブジェクトを作成し、各objectパラメータのフォールバック値としてnullを定義します。

let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });ログに記録することで、すべての結果をコンソールに表示できます。
console.log(quotes);最後に、ブラウザを閉じて、catchステートメントを追加しましょう。
await browser.close();完全なスクレーパーは次のようになります。
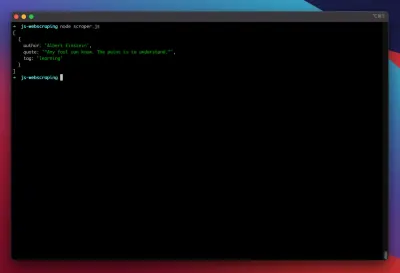
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();次のコマンドでスクレーパーを実行してみましょう。
node scraper.jsそして、そこに行きます! スクレーパーは、期待どおりに見積もりオブジェクトを返します。
高度な最適化
基本的なスクレーパーが機能しています。 いくつかのより深刻なスクレイピングタスクに備えるために、いくつかの改善を追加しましょう。
ユーザーエージェントの設定
デフォルトでは、Puppeteerは文字列HeadlessChromeを含むユーザーエージェントを使用します。 かなりの数のWebサイトがこの種の署名を探し、そのような署名で着信要求をブロックします。 それがスクレーパーが失敗する潜在的な理由になるのを避けるために、私は常に次の行をコードに追加してカスタムユーザーエージェントを設定します。
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');これは、上位5つの最も一般的なユーザーエージェントの配列からの各要求でランダムなユーザーエージェントを選択することにより、さらに改善される可能性があります。 最も一般的なユーザーエージェントのリストは、最も一般的なユーザーエージェントの記事にあります。
プロキシの実装
次のように、起動時にプロキシアドレスをPuppeteerに渡すことができるため、Puppeteerを使用するとプロキシへの接続が非常に簡単になります。
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxiesは、使用できる無料のプロキシの大規模なリストを提供します。 または、ローテーションプロキシサービスを使用することもできます。 プロキシは通常、多くの顧客(この場合は無料のユーザー)間で共有されるため、接続の信頼性は通常の状況よりもはるかに低くなります。 これは、エラー処理と再試行管理について話す絶好の機会です。
エラーと再試行-管理
多くの要因により、スクレーパーが機能しなくなる可能性があります。 したがって、エラーを処理し、障害が発生した場合にどうなるかを決定することが重要です。 スクレーパーをプロキシに接続し、接続が不安定になると予想されるため(特に、無料のプロキシを使用しているため)、あきらめる前に4回再試行します。
また、以前に失敗した場合は、同じIPアドレスでリクエストを再試行しても意味がありません。 したがって、小さなプロキシ回転システムを構築します。
まず、2つの新しい変数を作成します。
let retry = 0; let maxRetries = 5; 関数scrape()を実行するたびに、再試行変数を1つ増やします。次に、エラーを処理できるように、完全なスクレイピングロジックをtryandcatchステートメントでラップします。 再試行管理は、 catch関数内で行われます。
以前のブラウザインスタンスは閉じられ、retry変数がmaxRetries変数よりも小さい場合、scrap関数が再帰的に呼び出されます。
スクレーパーは次のようになります。
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };ここで、前述のプロキシローテーターを追加しましょう。
まず、プロキシのリストを含む配列を作成しましょう。
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];次に、配列からランダムな値を選択します。
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];これで、動的に生成されたプロキシをPuppeteerインスタンスと一緒に実行できます。
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });もちろん、このプロキシローテーターは、デッドプロキシなどにフラグを立てるためにさらに最適化できますが、これは間違いなくこのチュートリアルの範囲を超えます。
これは私たちのスクレーパーのコードです(すべての改善を含む):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();出来上がり! ターミナル内でスクレーパーを実行すると、見積もりが返されます。
パペッティアの代替としての劇作家
PuppeteerはGoogleによって開発されました。 2020年の初めに、MicrosoftはPlaywrightと呼ばれる代替案をリリースしました。 マイクロソフトは、パペッティアチームから多くのエンジニアをヘッドハントしました。 したがって、劇作家は、すでにパペッティアに取り組んでいる多くのエンジニアによって開発されました。 ブログの新しい子供であることに加えて、Playwrightの最大の差別化ポイントは、Chromium、Firefox、およびWebKit(Safari)をサポートするクロスブラウザーのサポートです。
パフォーマンステスト(Checklyによって実施されたこのようなもの)は、少なくとも執筆時点では、PuppeteerがPlaywrightと比較して約30%優れたパフォーマンスを提供することを示しています。これは、私自身の経験と一致します。
1つのブラウザインスタンスで複数のデバイスを実行できるという事実など、その他の違いは、Webスクレイピングのコンテキストではあまり価値がありません。
リソースと追加のリンク
- Puppeteerのドキュメント
- パペッティアと劇作家を学ぶ
- ZenscrapeによるJavascriptによるWebスクレイピング
- 最も一般的なユーザーエージェント
- パペッティア対劇作家