
Pythonでのデータの視覚化:基本的なプロットの説明[図解付き]
公開: 2021-02-08目次
基本的な設計原則
意欲的なまたは成功したデータサイエンティストにとって、あなたの研究と分析を説明できることは、所有するのに非常に重要で有用なスキルです。 ここで、データの視覚化が重要になります。 このツールを正直に使用することは非常に重要です。なぜなら、聴衆はデザインの選択が不十分なために、非常に簡単に誤解されたり、だまされたりする可能性があるからです。
データサイエンティストとして、私たち全員には、真実を維持するという点で一定の義務があります。
1つ目は、データをクリーンアップして要約するときは、自分自身に完全に正直である必要があるということです。 データの前処理は、機械学習アルゴリズムが機能するための非常に重要なステップであるため、データに不正があれば、結果が大幅に異なります。
もう1つの義務は、ターゲットオーディエンスに対するものです。 データの視覚化には、データの特定のセクションを強調表示し、他のデータを目立たなくするために使用されるさまざまな手法があります。 したがって、十分に注意しないと、読者は分析を適切に調査および判断することができず、疑問や信頼の欠如につながる可能性があります。
常に自分自身に疑問を投げかけることは、データサイエンティストにとって良い特徴です。 そして、文脈が重要であることを忘れずに、理解しやすく、見た目にも美しい方法で、本当に重要なことをどのように示すかを常に考える必要があります。
これはまさにアルベルトカイロが彼の教えで描写しようとしていることです。 彼は、優れた視覚化の5つの品質、つまり、心に留めておく価値のある、美しく、啓発的で、機能的で、洞察に満ちた、真実であると述べています。
いくつかの基本的なプロット
設計原理の基本を理解したので、Pythonでmatplotlibライブラリを使用していくつかの基本的な視覚化手法について詳しく見ていきましょう。
以下のすべてのコードは、Jupyterノートブックで実行できます。
%matplotlibノートブック
#これはインタラクティブな環境を提供し、バックエンドを設定します。 ( %matplotlibインラインも使用できますが、インタラクティブではありません。これは、プロット関数をさらに呼び出しても、元の視覚化が自動的に更新されないことを意味します。)
import matplotlib.pyplot as plt #必要なライブラリモジュールをインポートする
ポイントプロット
ポイントをプロットする最も簡単なmatplotlib関数はplot()です。 引数はX座標とY座標を表し、次にデータ出力の表示方法を説明する文字列値を表します。
plt.figure()
plt.plot(5、6、'+') #+記号はマーカーとして機能します
散布図
散布図は2次元プロットです。 scatter()関数も、最初の引数としてX値を取り、2番目の引数としてY値を取ります。 以下のプロットは対角線であり、 matplotlibは両方の軸のサイズを自動的に調整します。 ここでは、散布図はアイテムをシリーズとして扱いません。 そのため、各ポイントに対応する希望の色のリストを提供することもできます。
numpyをnpとしてインポートします
x = np.array([1、2、3、4、5、6、7、8])
y = x
plt.figure()
plt.scatter(x、y)
ラインプロット
折れ線グラフは、 plot()関数を使用して作成され、散布図のようにさまざまな一連のデータポイントをプロットしますが、各ポイントシリーズを線で接続します。
numpyをnpとしてインポートします
linear_data = np.array([1、2、3、4、5、6、7、8])
squared_data = linear_data ** 2
plt.figure()
plt.plot(linear_data、'-o'、squared_data、'-o')
グラフを読みやすくするために、各線が何を表しているかを示す凡例を追加することもできます。 グラフと両方の軸に適したタイトルが重要です。 また、 fill_between()関数を使用してグラフの任意のセクションをシェーディングして、関連する領域を強調表示することもできます。
plt.xlabel('X値')

plt.ylabel('Y値')
plt.title('ラインプロット')
plt.legend(['linear'、'squared'])
plt.gca()。fill_between(range(len(linear_data))、linear_data、squared_data、facecolor ='blue'、alpha = 0.25)
これは、変更されたグラフがどのように見えるかです-
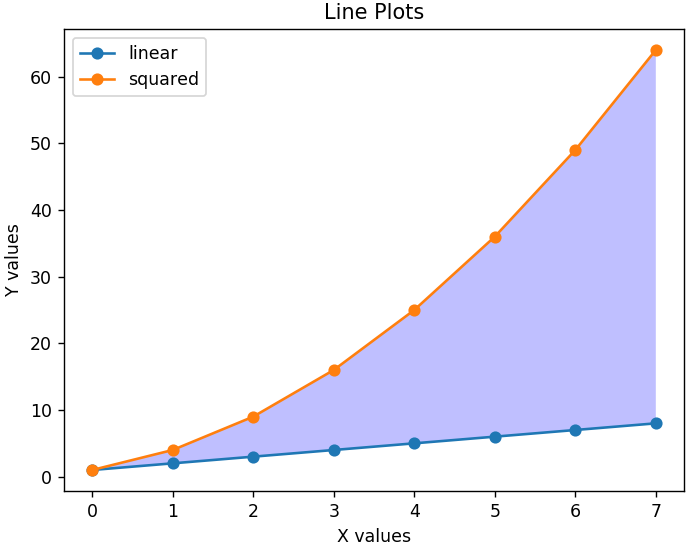
棒グラフ
X値と各棒の高さの引数をbar()関数に送信することで、棒グラフをプロットできます。 以下は、上記で使用したものと同じ線形データ配列の棒グラフです。
plt.figure()
x = range(len(linear_data))
plt.bar(x、linear_data)
#2乗データを同じグラフ上の別のバーのセットとしてプロットするには、最初のバーのセットを補うために新しいx値を調整する必要があります
new_x = []
xのデータの場合:
new_x.append(data + 0.3)
plt.bar(new_x、squared_data、width = 0.3、color ='green')
#水平方向のグラフの場合、 barh()関数を使用します
plt.figure()
x = range(len(linear_data))
plt.barh(x、linear_data、height = 0.3、color ='b')
plt.barh(x、squared_data、height = 0.3、left = linear_data、color ='g')
#これはバープロットを垂直に積み重ねる例です
plt.figure()
x = range(len(linear_data))
plt.bar(x、linear_data、width = 0.3、color ='b')
plt.bar(x、squared_data、width = 0.3、bottom = linear_data、color ='g')
世界のトップ大学からデータサイエンスコースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
結論
視覚化の種類はここで終わるだけではありません。 Pythonには、 seabornと呼ばれる優れたライブラリもあり、これは間違いなく探索する価値があります。 適切な情報の視覚化は、データの価値を高めるのに大いに役立ちます。 データの視覚化は、何百万ものレコードを持つ退屈なテーブルを調べるよりも、洞察を得てさまざまな傾向やパターンを特定するためのより良いオプションです。
データサイエンスについて知りたい場合は、IIIT-BとupGradのデータサイエンスのPGディプロマをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップ、1- on-1業界のメンター、400時間以上の学習、トップ企業との仕事の支援。
データの視覚化に役立つPythonパッケージは何ですか?
Pythonには、データを視覚化するための驚くべき便利なパッケージがいくつかあります。 これらのパッケージのいくつかを以下に示します。
1. Matplotlib -Matplotlibは、スキャッタープロット、棒グラフ、円グラフ、折れ線グラフなどのさまざまな形式でデータを視覚化するために使用される人気のあるPythonライブラリです。 数学演算にはNumpyを使用しています。
2. Seaborn -Seabornライブラリは、Pythonでの統計表現に使用されます。 Matplotlibの上に開発され、Pandasデータ構造と統合されています。
3. Altair -Altairは、データを視覚化するためのもう1つの人気のあるPythonライブラリです。 これは、最小限のコーディングでビジュアルを作成できる宣言型統計ライブラリです。
4. Plotly -Plotlyは、Pythonのインタラクティブなオープンソースデータ視覚化ライブラリです。 このブラウザベースのライブラリによって作成されたビジュアルは、JupyterNotebookやスタンドアロンのHTMLファイルなどの多くのプラットフォームでサポートされています。
ポイントプロットと散布図について何を知っていますか?
ポイントプロットは、データを視覚化するための最も基本的で最も単純なプロットです。 ポイントプロットは、デカルト平面上のポイントの形式でデータを表示します。 「+」は値の増加を示し、「-」は時間の経過に伴う値の減少を示します。
一方、散布図は、データが2次元平面上に視覚化される最適化されたプロットです。 これは、x軸の値を最初のパラメーターとして、y軸の値を2番目のパラメーターとして受け取るscatter()関数を使用して定義されます。
データ視覚化の利点は何ですか?
次の利点は、データの視覚化が組織の成長の真のヒーローになる方法を示しています。
1.データの視覚化により、生データの解釈と理解が容易になり、さらに分析できるようになります。
2.データを調査および分析した後、意味のある視覚化を使用して結果を表示できます。 これにより、聴衆とつながり、結果を説明しやすくなります。
3.この手法の最も重要なアプリケーションの1つは、パターンと傾向を分析して、予測と潜在的な成長領域を推測することです。
4.また、顧客の好みに応じてデータを分離することもできます。 さらに注意が必要な領域を特定することもできます。