
すべてのデータサイエンティストが持つべき究極のデータサイエンスチートシート
公開: 2021-01-29活況を呈しているデータサイエンスの世界に飛び込むことを考えているすべての新進の専門家と初心者のために、この分野を強調する基本と方法論をブラッシュアップするための簡単なチートシートをまとめました。
目次
データサイエンス-基本
私たちの世界で生成されるデータは、生の形式、つまり、数字、コード、単語、文などです。データサイエンスは、この非常に生のデータを科学的手法を使用して処理し、意味のある形式に変換して知識と洞察を獲得します。 。
データ
データサイエンスの信条に飛び込む前に、データ、そのタイプ、およびデータ処理について少し話しましょう。
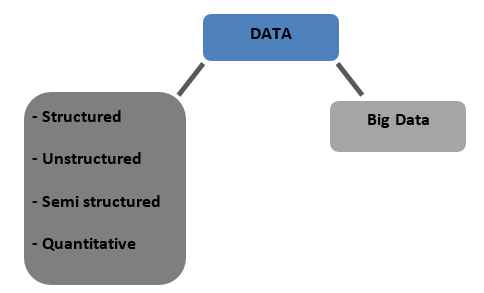
データの種類
構造化–データベースに表形式で保存されているデータ。 数値またはテキストのいずれかです
非構造化–明確な構造で表にできないデータは、非構造化データと呼ばれます
半構造化–構造化データと非構造化データの両方の特性を持つ混合データ
定量的–定量化できる明確な数値を持つデータ
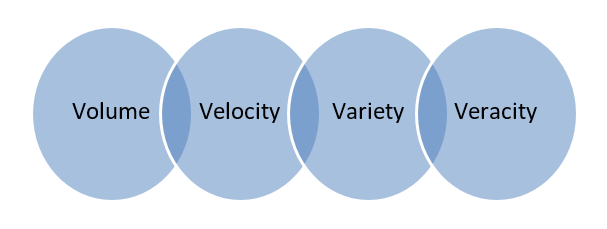
ビッグデータ–複数のコンピューターまたはサーバーファームにまたがる巨大なデータベースに保存されているデータは、ビッグデータと呼ばれます。 生体認証データ、ソーシャルメディアデータなどはビッグデータと見なされます。 ビッグデータは4つのVによって特徴付けられます
データ前処理
データ分類–データを数値、テキストまたは画像、テキスト、ビデオなどのクラスに分類またはラベル付けするプロセスです。
データクレンジング–欠落している/一貫性のない/互換性のないデータを取り除くか、次のいずれかの方法を使用してデータを置き換えることで構成されます。
- 補間
- ヒューリスティック
- ランダム割当
- 最寄りの隣人
データマスキング–機密データを非表示またはマスクして、機密情報のプライバシーを維持しながら処理できるようにします。
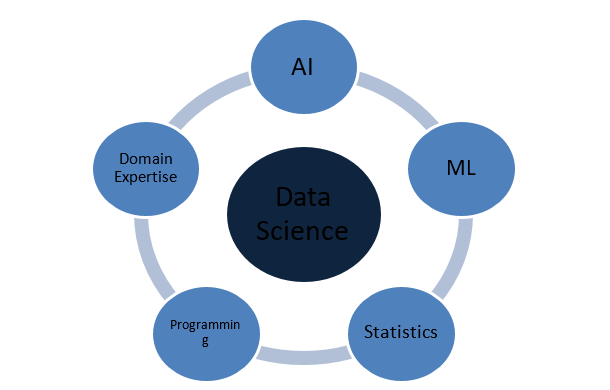
データサイエンスは何でできていますか?
統計の概念
回帰
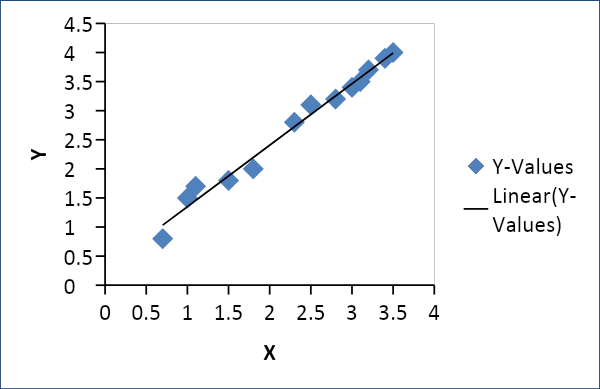
線形回帰
線形回帰は、需要と供給、価格と消費などの2つの変数間の関係を確立するために使用されます。これは、ある変数xを別の変数yの線形関数として次のように関連付けます。
Y = f(x)またはY = mx + c、ここでm=係数
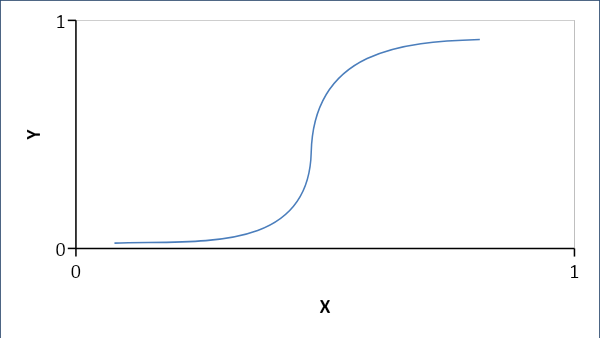
ロジスティック回帰
ロジスティック回帰は、変数間の線形関係ではなく、確率的関係を確立します。 結果の答えは0または1のいずれかであり、確率を探します。曲線はS字型です。
p <0.5の場合、その0、それ以外の場合は1
方式:
Y = e ^(b0 + b1x)/(1 + e ^(b0 + b1x))
ここで、b0 =バイアス、b1=係数
確率
確率は、イベントの発生の可能性を予測するのに役立ちます。 いくつかの用語:
サンプル:一連の可能性のある結果
イベント:サンプルスペースのサブセットです
確率変数:確率変数は、可能性のある結果をサンプル空間の数値または線にマッピングまたは定量化するのに役立ちます
確率分布
離散分布:確率を離散値のセット(整数)として示します
P [X = x] = p(x)
 画像ソース
画像ソース
連続分布:離散値ではなく、いくつかの連続点または間隔にわたる確率を示します。 方式:
P[a≤x≤b]=a∫bf(x)dx、ここでa、bはポイントです
画像ソース
相関と共分散
標準偏差:特定のデータセットの平均値からの変動または偏差
σ=√{(Σi= 1N(xi – x))/(N -1)}
共分散
これは、確率変数XおよびYの偏差の範囲をデータセットの平均で定義します。
Cov(X、Y)=σ2XY= E [(X-μX)(Y-μY)] = E[XY]-μXμY
相関
相関は、変数間の線形関係の範囲とその方向、+veまたは-veを定義します
ρXY=σ2XY/σX**σY
人工知能
機械が知識を獲得し、入力に基づいて意思決定を行う能力は、人工知能または単にAIと呼ばれます。
タイプ
- リアクティブマシン:リアクティブマシンAIは、最速かつ最良のオプションに絞り込むことで、事前定義されたシナリオに対応することを学習することで機能します。 それらはメモリが不足しており、定義されたパラメータのセットを持つタスクに最適です。 信頼性が高く、一貫性があります。
- 限られたメモリ:このAIには、実際の観測データとレガシーデータが供給されます。 与えられたデータに基づいて学習し、決定を下すことができますが、新しい経験を積むことはできません。
- 心の理論:周囲のエンティティの動作に基づいて決定を下すことができるインタラクティブなAIです。
- 自己認識:このAIは、周囲から離れてその存在と機能を認識しています。 それは認知能力を発達させ、周囲に対する自身の行動の影響を理解し評価することができます。
AI用語
ニューラルネットワーク
ニューラルネットワークは、システム内のデータと情報を中継する相互接続されたノードの束またはネットワークです。 NNは、脳内のニューロンを模倣するようにモデル化されており、学習して予測することで意思決定を行うことができます。
経験則
ヒューリスティックは、利用可能な情報が不完全な状況での以前の経験を使用して、近似と推定に基づいて迅速に予測する機能です。 迅速ですが、正確でも正確でもありません。

事例ベースの推論
以前の問題解決の事例から学び、現在の状況でそれらを適用して、許容できる解決策に到達する能力
自然言語処理
それは単に、人間のスピーチやテキストを直接理解して相互作用する機械の能力です。 たとえば、車内の音声コマンド
機械学習
機械学習は、さまざまなモデルとアルゴリズムを使用して問題を予測および解決するAIのアプリケーションです。
タイプ
監視あり
この方法は、出力データに関連付けられている入力データに依存しています。 マシンには一連のターゲット変数Yが提供されており、最適化アルゴリズムの監視下で、一連の入力変数Xを介してターゲット変数に到達する必要があります。 教師あり学習の例としては、ニューラルネットワーク、ランダムフォレスト、ディープラーニング、サポートベクターマシンなどがあります。
監督されない
この方法では、入力変数にはラベル付けや関連付けがなく、アルゴリズムが機能してパターンとクラスターを見つけ、新しい知識と洞察をもたらします。
強化
強化学習は、学習行動を研ぎ澄ますまたは磨くための即興テクニックに焦点を当てています。 これは報酬ベースの方法であり、マシンは徐々に技術を向上させて目標の報酬を獲得します。
モデリング方法
回帰
回帰モデルは、連続データの内挿または外挿によって常に数値を出力として提供します。
分類
分類モデルは、クラスまたはラベルとして出力を考え出し、「どのような種類」のような離散的な結果を予測するのに優れています。
回帰と分類はどちらも教師ありモデルです。
クラスタリング
クラスタリングは、特性、属性、機能などに基づいてクラスターを識別する教師なしモデルです。
MLアルゴリズム
デシジョンツリー
決定木は、バイナリアプローチを使用して、各段階での連続した質問に基づいて解決策に到達し、結果が「はい」または「いいえ」のような2つの可能なもののいずれかになるようにします。 デシジョンツリーは、実装と解釈が簡単です。
ランダムフォレストまたはバギング
ランダムフォレストは、決定木の高度なアルゴリズムです。 多数の決定木を使用しているため、森のように密集して複雑な構造になっています。 複数の結果が生成されるため、より正確な結果とパフォーマンスが得られます。
K-最近傍法(KNN)
kNNは、新しいデータポイントに対するプロット上の最も近いデータポイントの近接性を利用して、どのカテゴリに分類されるかを予測します。新しいデータポイントは、隣接するカテゴリの数が多いカテゴリに割り当てられます。
k=最近傍の数
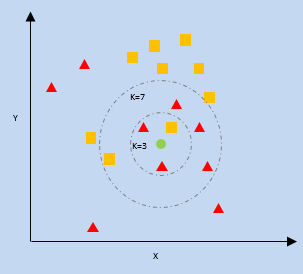
ナイーブベイズ
ナイーブベイズは2つの柱に取り組んでいます。1つはデータポイントのすべての特徴が独立していて、互いに無関係、つまり一意であり、もう1つは条件または仮説に基づいて結果を予測するベイズの定理です。
ベイズの定理:
P(X | Y)= {P(Y | X)* P(X)} / P(Y)
ここで、P(X | Y)=Yの発生が与えられた場合のXの条件付き確率
P(Y | X)=Xの発生が与えられた場合のYの条件付き確率
P(X)、P(Y)=XとYの個別の確率
ベクターマシンのサポート
このアルゴリズムは、線または平面のいずれかである境界に基づいて、空間内のデータを分離しようとします。 この境界は「超平面」と呼ばれ、各クラスの最も近いデータポイントによって定義されます。これらのデータポイントは「サポートベクター」と呼ばれます。 両側のサポートベクター間の最大距離はマージンと呼ばれます。
ニューラルネットワーク
パーセプトロン
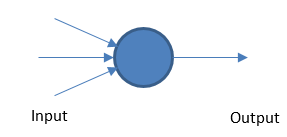
基本的なニューラルネットワークは、しきい値に基づいて重み付けされた入力と出力を取得することによって機能します。
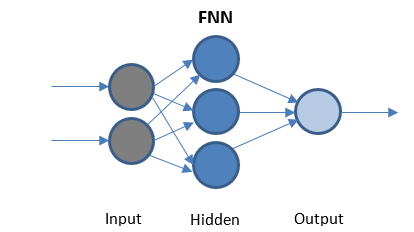
フィードフォワードニューラルネットワーク
FFNは、データを一方向にのみ送信する最も単純なネットワークです。 隠しレイヤーがある場合とない場合があります。
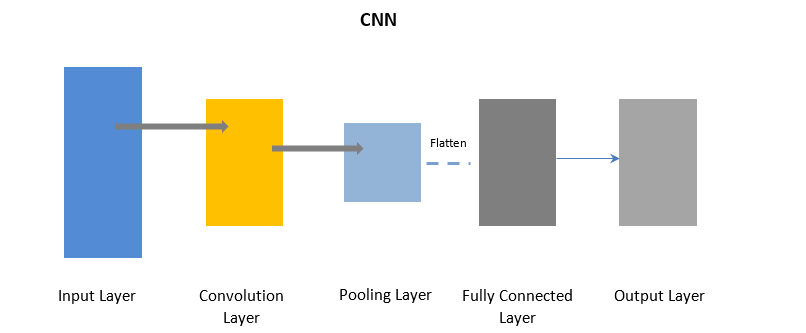
畳み込みニューラルネットワーク
CNNは、畳み込み層を使用して入力データの特定の部分をバッチで処理し、続いてプーリング層を使用して出力を完了します。
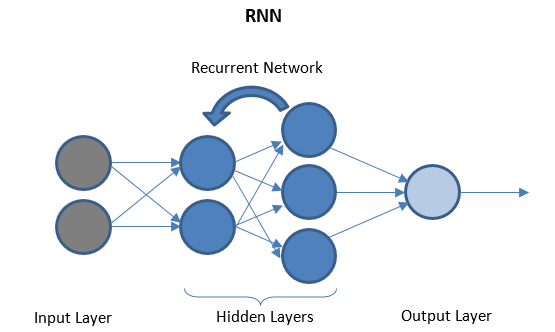
リカレントニューラルネットワーク
RNNは、「履歴」データを格納できるI/Oレイヤー間のいくつかのリカレントレイヤーで構成されます。 データフローは双方向であり、予測を改善するために反復層に供給されます。
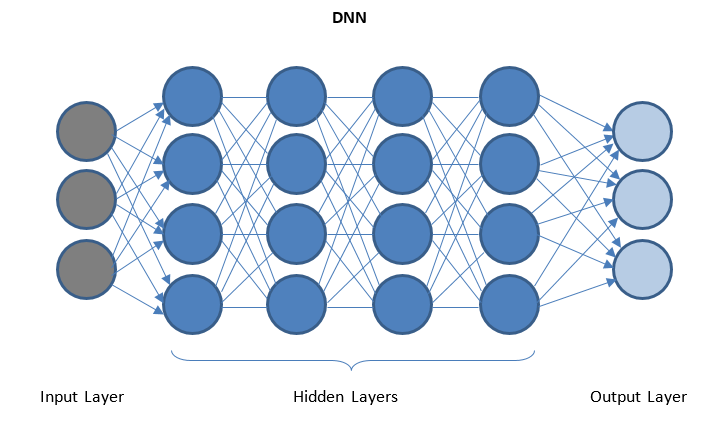
ディープニューラルネットワークとディープラーニング
DNNは、I/Oレイヤー間に複数の隠れレイヤーがあるネットワークです。 非表示のレイヤーは、データを出力レイヤーに送信する前に、データに連続した変換を適用します。
「ディープラーニング」はDNNによって促進され、複数の隠れ層があるため、大量の複雑なデータを処理し、高精度を実現できます。
世界のトップ大学からデータサイエンス認定を取得します。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを学び、キャリアを早急に進めましょう。
結論
データサイエンスは、さまざまな流れを貫く広大な分野ですが、私たちにとって革命と啓示として出くわします。 データサイエンスは活況を呈しており、将来的にはシステムの動作と感じ方を変えるでしょう。
データサイエンスについて知りたい場合は、IIIT-BとupGradのデータサイエンスのPGディプロマをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップ、1- on-1業界のメンター、400時間以上の学習、トップ企業との仕事の支援。
データサイエンスに最適なプログラミング言語とその理由を教えてください。
データサイエンス用のプログラミング言語は数十ありますが、データサイエンスコミュニティの大多数は、データサイエンスに秀でたいのであれば、Pythonが正しい選択であると考えています。 以下は、この信念を支持する理由のいくつかです。
1. Pythonには、データサイエンスの概念を簡単に処理できるようにする、TensorFlowやPyTorchなどの幅広いモジュールとライブラリがあります。
2.広大なPython開発者コミュニティは、初心者がデータサイエンスの旅の次の段階に進むのを常に支援しています。
3.この言語は、読みやすさを向上させるクリーンな構文を備えた、最も便利で書きやすい言語の1つです。
データサイエンスを完成させるための概念は何ですか?
データサイエンスは、他のさまざまな重要なドメインの傘として機能する広大なドメインです。 以下は、データサイエンスを構成する最も顕著な概念です。
統計学
統計は、データサイエンスを前進させるために、優れている必要がある重要な概念です。 さらに、いくつかのサブトピックがあります。
1.線形回帰
2.確率
3.確率分布
人工知能
機械に頭脳を提供し、入力に基づいて機械が独自の決定を下せるようにする科学は、人工知能として知られています。 リアクティブマシン、限られたメモリ、心の理論、および自己認識は、人工知能のタイプの一部です。
機械学習
機械学習は、提供されたデータに基づいて将来の結果を予測するための教育機械を扱うデータサイエンスのもう1つの重要なコンポーネントです。 機械学習には、クラスタリング、回帰、分類の3つの主要なモデリング手法があります。
機械学習の種類を説明してください。
機械学習または単純なMLには、作業方法に基づいて3つの主要なタイプがあります。 これらのタイプは次のとおりです。
1.教師あり学習
これは、入力データにラベルが付けられる最もプリミティブなタイプのMLです。 マシンには、マシンに問題への洞察を与え、それについてトレーニングされる、より小さなデータセットが提供されます。
2.教師なし学習
このタイプの最大の利点は、データがここでラベル付けされておらず、人的労力がほとんど無視できることです。 これにより、はるかに大きなデータセットをモデルに導入するための門が開かれます。
3.強化学習これは、人間の生活に触発された最も高度なタイプのMLです。 不要な出力は推奨されませんが、必要な出力は強化されます。