
機械学習におけるデータ前処理:従うべき7つの簡単なステップ
公開: 2021-07-15機械学習でのデータ前処理は、データの品質を向上させ、データからの意味のある洞察の抽出を促進するのに役立つ重要なステップです。 機械学習でのデータ前処理とは、生データを準備(クリーニング、整理)して、機械学習モデルの構築とトレーニングに適したものにする手法を指します。 簡単に言うと、機械学習でのデータ前処理は、生データを理解可能で読み取り可能な形式に変換するデータマイニング手法です。
目次
機械学習でデータを前処理する理由
機械学習モデルの作成に関しては、データの前処理がプロセスの開始を示す最初のステップです。 通常、実際のデータは不完全で、一貫性がなく、不正確であり(エラーまたは外れ値が含まれています)、特定の属性値/傾向が欠けていることがよくあります。 ここでデータの前処理がシナリオに入ります。これは、生データのクリーンアップ、フォーマット、整理に役立ち、それによって機械学習モデルですぐに使用できるようになります。 機械学習におけるデータ前処理のさまざまなステップを見ていきましょう。
世界のトップ大学(修士、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインで人工知能コースに参加して、キャリアを早急に進めましょう。
機械学習におけるデータ前処理のステップ
機械学習のデータ前処理には、次の7つの重要なステップがあります。
1.データセットを取得します
データセットの取得は、機械学習におけるデータ前処理の最初のステップです。 機械学習モデルを構築および開発するには、最初に関連するデータセットを取得する必要があります。 このデータセットは、複数の異なるソースから収集されたデータで構成され、適切な形式で組み合わされてデータセットを形成します。 データセットの形式は、ユースケースによって異なります。 たとえば、ビジネスデータセットは医療データセットとはまったく異なります。 ビジネスデータセットには関連する業界およびビジネスデータが含まれますが、医療データセットにはヘルスケア関連のデータが含まれます。
https://www.kaggle.com/uciml/datasetsやhttps://archive.ics.uci.edu/ml/index.phpなどのデータセットをダウンロードできるオンラインソースがいくつかあります。 さまざまなPythonAPIを介してデータを収集することにより、データセットを作成することもできます。 データセットの準備ができたら、CSV、HTML、またはXLSXファイル形式でデータセットを配置する必要があります。

2.すべての重要なライブラリをインポートします
Pythonは、世界中のデータサイエンティストによって最も広く使用されており、最も好まれているライブラリでもあるため、機械学習でデータを前処理するためにPythonライブラリをインポートする方法を紹介します。 データサイエンス用のPythonライブラリについて詳しくは、こちらをご覧ください。 事前定義されたPythonライブラリは、特定のデータ前処理ジョブを実行できます。 重要なライブラリをすべてインポートすることは、機械学習におけるデータ前処理の2番目のステップです。 機械学習でこのデータ前処理に使用される3つのコアPythonライブラリは次のとおりです。
- NumPy – NumPyは、Pythonでの科学計算の基本的なパッケージです。 したがって、コードに任意のタイプの数学演算を挿入するために使用されます。 NumPyを使用すると、コードに大きな多次元配列と行列を追加することもできます。
- Pandas – Pandasは、データの操作と分析のための優れたオープンソースのPythonライブラリです。 データセットのインポートと管理に広く使用されています。 Python用の高性能で使いやすいデータ構造とデータ分析ツールが含まれています。
- Matplotlib – Matplotlibは、Pythonで任意のタイプのグラフをプロットするために使用されるPython2Dプロットライブラリです。 プラットフォーム(IPythonシェル、Jupyterノートブック、Webアプリケーションサーバーなど)全体で、多数のハードコピー形式およびインタラクティブ環境で出版品質の数値を提供できます。
読む:初心者のための機械学習プロジェクトのアイデア
3.データセットをインポートします
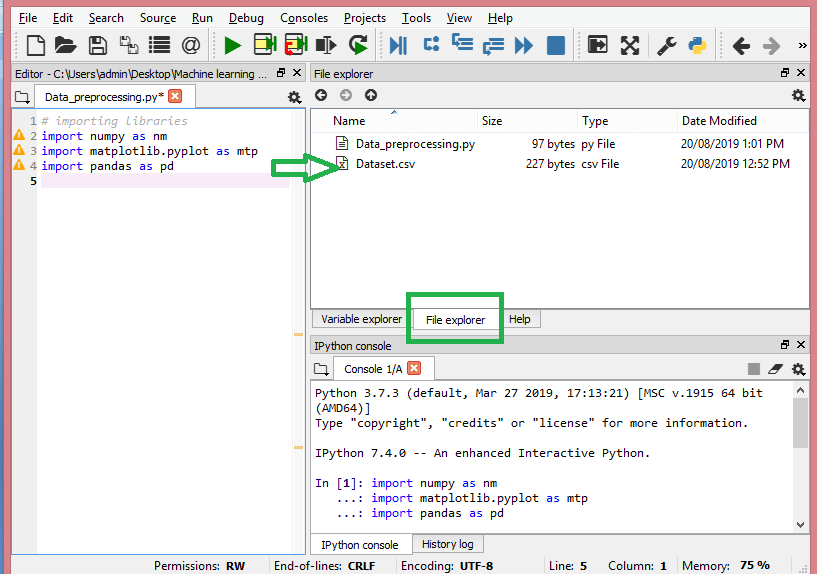
このステップでは、手元のMLプロジェクト用に収集したデータセットをインポートする必要があります。 データセットのインポートは、機械学習のデータ前処理における重要なステップの1つです。 ただし、データセットをインポートする前に、現在のディレクトリを作業ディレクトリとして設定する必要があります。 Spyder IDEで作業ディレクトリを設定するには、次の3つの簡単な手順を実行します。
- データセットを含むディレクトリにPythonファイルを保存します。
- Spyder IDEの[ファイルエクスプローラー]オプションに移動し、必要なディレクトリを選択します。
- 次に、F5ボタンまたは[実行]オプションをクリックして、ファイルを実行します。
ソース
これは、作業ディレクトリがどのように見えるかです。
関連するデータセットを含む作業ディレクトリを設定したら、Pandasライブラリの「read_csv()」関数を使用してデータセットをインポートできます。 この関数は、CSVファイルを(ローカルまたはURLを介して)読み取り、さまざまな操作を実行することもできます。 read_csv()は次のように記述されます。
data_set = pd.read_csv('Dataset.csv')
このコード行で、「data_set」はデータセットを保存した変数の名前を示します。 この関数には、データセットの名前も含まれています。 このコードを実行すると、データセットが正常にインポートされます。
データセットのインポートプロセス中に、実行する必要のあるもう1つの重要なことがあります。それは、従属変数と独立変数を抽出することです。 すべての機械学習モデルについて、データセット内の独立変数(特徴の行列)と従属変数を分離する必要があります。
このデータセットについて考えてみましょう。
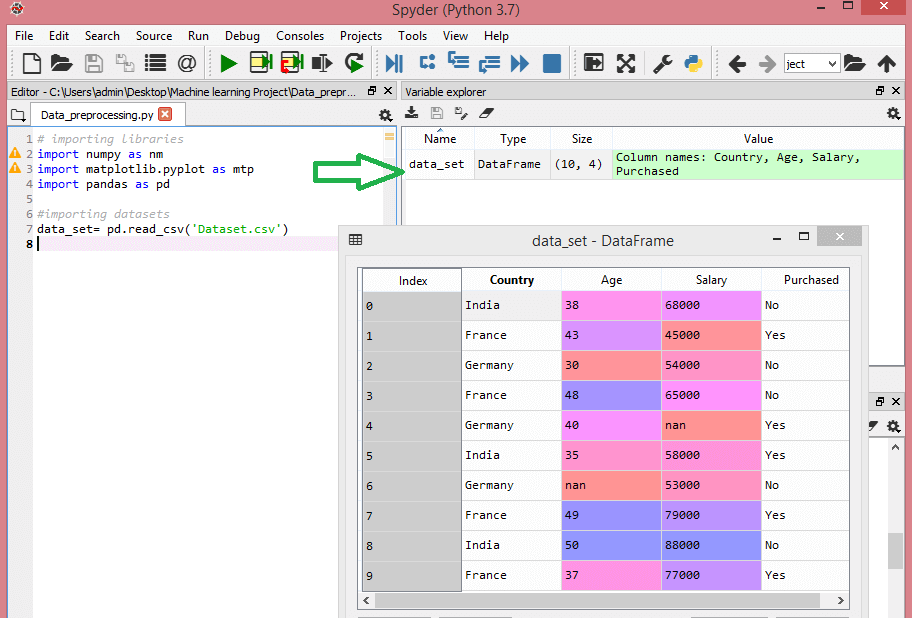
ソース
このデータセットには、国、年齢、給与の3つの独立変数と、購入した1つの従属変数が含まれています。
独立変数を抽出する方法は?
独立変数を抽出するには、Pandasライブラリの「iloc[]」関数を使用できます。 この関数は、データセットから選択した行と列を抽出できます。
x = data_set.iloc [:、:-1] .values
上記のコード行では、最初のコロン(:)がすべての行を考慮し、2番目のコロン(:)がすべての列を考慮します。 従属変数を含む最後の列を除外する必要があるため、コードには「:-1」が含まれています。 このコードを実行すると、次のような機能のマトリックスが得られます–
[['インド'38.068000.0]
[「フランス」43.045000.0]
[「ドイツ」30.054000.0]
[「フランス」48.065000.0]
['ドイツ'40.0nan]
[「インド」35.058000.0]
['ドイツ'nan53000.0]
[「フランス」49.079000.0]
['インド'50.088000.0]
['フランス'37.077000.0]]
従属変数を抽出する方法は?
「iloc[]」関数を使用して、従属変数を抽出することもできます。 書き方は次のとおりです。
y = data_set.iloc [:、3] .values
このコード行は、最後の列のみを含むすべての行を考慮します。 上記のコードを実行すると、次のような従属変数の配列が得られます–
array(['No'、'Yes'、'No'、'No'、'Yes'、'Yes'、'No'、'Yes'、'No'、'Yes']、
dtype = object)
4.欠落している値の特定と処理
データの前処理では、欠落している値を特定して正しく処理することが極めて重要です。これを行わないと、データから不正確で誤った結論や推論が導き出される可能性があります。 言うまでもなく、これはMLプロジェクトの妨げになります。
基本的に、欠落データを処理する方法は2つあります。
- 特定の行の削除–この方法では、機能のnull値を持つ特定の行、または値の75%以上が欠落している特定の列を削除します。 ただし、この方法は100%効率的ではないため、データセットに適切なサンプルがある場合にのみ使用することをお勧めします。 データを削除した後、バイアスが追加されないようにする必要があります。
- 平均の計算–この方法は、年齢、給与、年などの数値データを持つフィーチャに役立ちます。ここでは、欠落している値を含む特定のフィーチャまたは列または行の平均、中央値、または最頻値を計算して、欠落している値の結果。 この方法では、データセットに分散を追加でき、データの損失を効率的に無効にすることができます。 したがって、最初の方法(行/列の省略)と比較して、より良い結果が得られます。 近似のもう1つの方法は、隣接する値の偏差を使用することです。 ただし、これは線形データに最適です。
読む:クラウドを使用した機械学習アプリケーションのアプリケーション
5.カテゴリデータのエンコード
カテゴリデータとは、データセット内に特定のカテゴリを持つ情報を指します。 上記のデータセットには、国と購入という2つのカテゴリ変数があります。
機械学習モデルは、主に数学方程式に基づいています。 したがって、方程式に必要なのは数値のみであるため、方程式にカテゴリデータを保持すると特定の問題が発生することを直感的に理解できます。
国変数をエンコードする方法は?
データセットの例に見られるように、国の列は問題を引き起こすため、数値に変換する必要があります。 これを行うには、sci-kitlearnライブラリのLabelEncoder()クラスを使用できます。 コードは次のようになります–
#カテゴリデータ
#国変数の場合
sklearn.preprocessingからインポートLabelEncoder
label_encoder_x = LabelEncoder()
x [:、0] = label_encoder_x.fit_transform(x [:、0])
そして、出力は次のようになります–
アウト[15]:
array([[2、38.0、68000.0]、
[0、43.0、45000.0]、
[1、30.0、54000.0]、
[0、48.0、65000.0]、
[1、40.0、65222.22222222222]、
[2、35.0、58000.0]、
[1、41.111111111111114、53000.0]、
[0、49.0、79000.0]、
[2、50.0、88000.0]、
[0、37.0、77000.0]]、dtype = object)
ここで、LabelEncoderクラスが変数を数字に正常にエンコードしたことがわかります。 ただし、上記の出力には0、1、および2としてエンコードされた国の変数があります。 したがって、MLモデルは、3つの変数の間に何らかの相関関係があり、それによって誤った出力が生成されると想定する場合があります。 この問題を解消するために、ダミーエンコーディングを使用します。
ダミー変数は、結果をシフトする可能性のある特定のカテゴリ効果の有無を示すために値0または1をとる変数です。 この場合、値1は特定の列にその変数が存在することを示し、他の変数は値0になります。ダミーエンコーディングでは、列の数はカテゴリの数と同じです。
データセットには3つのカテゴリがあるため、値が0と1の3つの列が生成されます。ダミーエンコーディングには、scikit-learnライブラリのOneHotEncoderクラスを使用します。 入力コードは次のようになります–
#国変数の場合
sklearn.preprocessingからimportLabelEncoder、OneHotEncoder
label_encoder_x = LabelEncoder()
x [:、0] = label_encoder_x.fit_transform(x [:、0])
#ダミー変数のエンコーディング
onehot_encoder = OneHotEncoder(categorical_features = [0])
x = onehot_encoder.fit_transform(x).toarray()
このコードを実行すると、次の出力が得られます–
array([[0.00000000e + 00、0.00000000e + 00、1.00000000e + 00、3.80000000e + 01、
6.80000000e + 04]、
[1.00000000e + 00、0.00000000e + 00、0.00000000e + 00、4.30000000e + 01、
4.50000000e + 04]、
[0.00000000e + 00、1.00000000e + 00、0.00000000e + 00、3.00000000e + 01、
5.40000000e + 04]、
[1.00000000e + 00、0.00000000e + 00、0.00000000e + 00、4.80000000e + 01、
6.50000000e + 04]、
[0.00000000e + 00、1.00000000e + 00、0.00000000e + 00、4.00000000e + 01、
6.52222222e + 04]、
[0.00000000e + 00、0.00000000e + 00、1.00000000e + 00、3.50000000e + 01、
5.80000000e + 04]、
[0.00000000e + 00、1.00000000e + 00、0.00000000e + 00、4.11111111e + 01、

5.30000000e + 04]、
[1.00000000e + 00、0.00000000e + 00、0.00000000e + 00、4.90000000e + 01、
7.90000000e + 04]、
[0.00000000e + 00、0.00000000e + 00、1.00000000e + 00、5.00000000e + 01、
8.80000000e + 04]、
[1.00000000e + 00、0.00000000e + 00、0.00000000e + 00、3.70000000e + 01、
7.70000000e + 04]])
上記の出力では、すべての変数が3つの列に分割され、値0と1にエンコードされています。
購入した変数をエンコードする方法は?
2番目のカテゴリ変数、つまり購入した場合は、LableEncoderクラスの「labelencoder」オブジェクトを使用できます。 購入した変数にはyesまたはnoの2つのカテゴリしかなく、どちらも0と1にエンコードされているため、OneHotEncoderクラスは使用していません。
この変数の入力コードは次のようになります–
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
出力は次のようになります–
Out [17]:array([0、1、0、0、1、1、0、1、0、1])
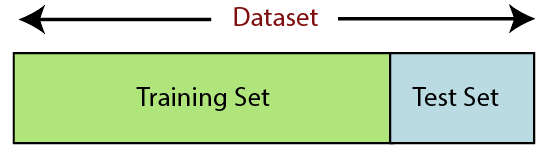
6.データセットを分割する
データセットの分割は、機械学習におけるデータ前処理の次のステップです。 機械学習モデルのすべてのデータセットは、トレーニングセットとテストセットの2つの別々のセットに分割する必要があります。
ソース
トレーニングセットは、機械学習モデルのトレーニングに使用されるデータセットのサブセットを示します。 ここで、あなたはすでに出力を知っています。 一方、テストセットは、機械学習モデルのテストに使用されるデータセットのサブセットです。 MLモデルは、テストセットを使用して結果を予測します。
通常、データセットは70:30の比率または80:20の比率に分割されます。 これは、モデルをトレーニングするためにデータの70%または80%を取得し、残りの30%または20%を除外することを意味します。 分割プロセスは、問題のデータセットの形状とサイズによって異なります。
データセットを分割するには、次のコード行を記述する必要があります–
sklearn.model_selectionからimporttrain_test_split
x_train、x_test、y_train、y_test = train_test_split(x、y、test_size = 0.2、random_state = 0)
ここで、最初の行は、データセットの配列をランダムなトレインとテストのサブセットに分割します。 コードの2行目には、次の4つの変数が含まれています。
- x_train –トレーニングデータの機能
- x_test –テストデータの機能
- y_train –トレーニングデータの従属変数
- y_test –データをテストするための独立変数
したがって、train_test_split()関数には4つのパラメーターが含まれ、そのうちの最初の2つはデータの配列用です。 test_size関数は、テストセットのサイズを指定します。 test_sizeは、.5、.3、または.2の場合があります。これは、トレーニングセットとテストセットの間の分割比率を指定します。 最後のパラメーター「random_state」は、出力が常に同じになるようにランダムジェネレーターのシードを設定します。
7.機能のスケーリング
機能のスケーリングは、機械学習でのデータ前処理の終わりを示します。 これは、特定の範囲内でデータセットの独立変数を標準化する方法です。 言い換えると、機能のスケーリングにより変数の範囲が制限されるため、共通の理由で変数を比較できます。
たとえば、このデータセットについて考えてみましょう–
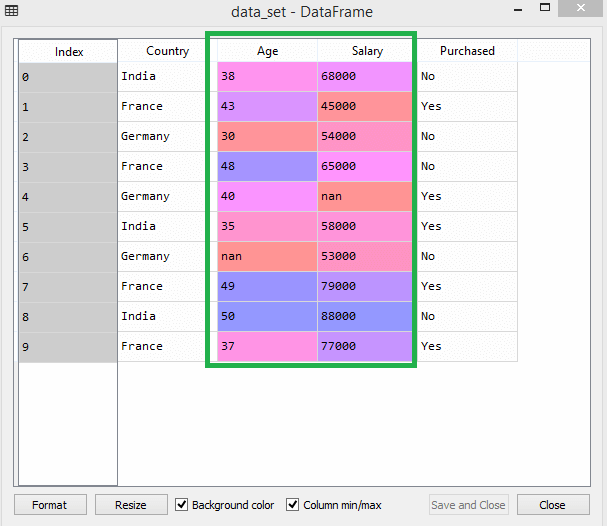
ソース
データセットでは、年齢と給与の列のスケールが同じではないことがわかります。 このようなシナリオでは、年齢と給与の列から2つの値を計算すると、給与の値が年齢の値を支配し、誤った結果をもたらします。 したがって、機械学習の機能スケーリングを実行して、この問題を取り除く必要があります。
ほとんどのMLモデルは、次のように表されるユークリッド距離に基づいています。
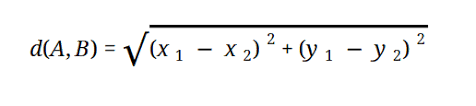
ソース
機械学習で機能のスケーリングを実行するには、次の2つの方法があります。
標準化
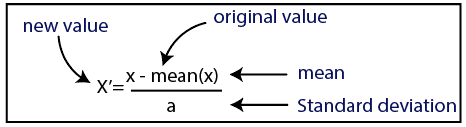
ソース
正規化
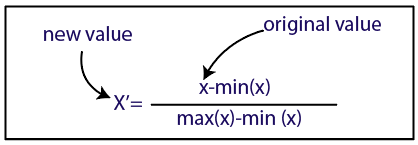
ソース
データセットには、標準化手法を使用します。 そのために、次のコード行を使用して、sci-kit-learnライブラリのStandardScalerクラスをインポートします。
sklearn.preprocessingからインポートStandardScaler
次のステップは、独立変数のStandardScalerクラスのオブジェクトを作成することです。 この後、次のコードを使用してトレーニングデータセットを適合および変換できます。
st_x = StandardScaler()
x_train = st_x.fit_transform(x_train)
テストデータセットの場合、transform()関数を直接適用できます(トレーニングセットで既に実行されているため、fit_transform()関数を使用する必要はありません)。 コードは次のようになります–
x_test = st_x.transform(x_test)
テストデータセットの出力には、x_trainとx_testのスケーリングされた値が次のように表示されます。
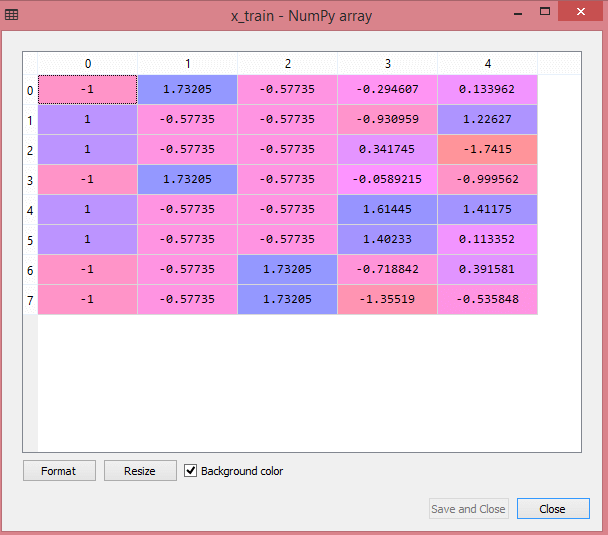
ソース
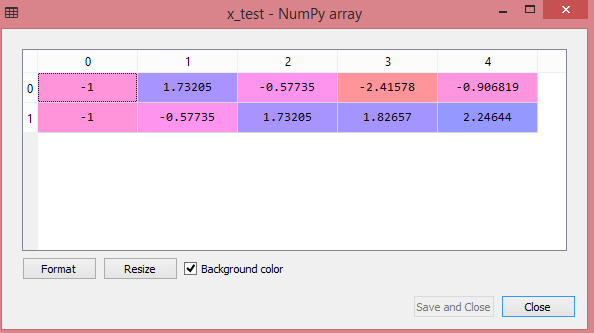
ソース
出力のすべての変数は、値-1と1の間でスケーリングされます。
これまでに実行したすべての手順を組み合わせると、次のようになります。
#ライブラリのインポート
numpyをnmとしてインポート
matplotlib.pyplotをmtpとしてインポートします
パンダをpdとしてインポートします
#データセットのインポート
data_set = pd.read_csv('Dataset.csv')
#独立変数の抽出
x = data_set.iloc [:、:-1] .values
#従属変数の抽出
y = data_set.iloc [:、3] .values
#欠落データの処理(欠落データを平均値に置き換える)
sklearn.preprocessingからインポートImputer
imputer = Imputer(missing_values ='NaN'、strategy ='mean'、axis = 0)
#インピュターオブジェクトを独立変数xに適合させます。
imputerimputer = imputer.fit(x [:、1:3])
#欠落データを計算された平均値で置き換える
x [:、1:3] = imputer.transform(x [:、1:3])
#国変数の場合
sklearn.preprocessingからimportLabelEncoder、OneHotEncoder
label_encoder_x = LabelEncoder()
x [:、0] = label_encoder_x.fit_transform(x [:、0])
#ダミー変数のエンコーディング
onehot_encoder = OneHotEncoder(categorical_features = [0])
x = onehot_encoder.fit_transform(x).toarray()
購入した変数の#エンコーディング
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
#データセットをトレーニングセットとテストセットに分割します。
sklearn.model_selectionからimporttrain_test_split
x_train、x_test、y_train、y_test = train_test_split(x、y、test_size = 0.2、random_state = 0)
#Featureデータセットのスケーリング
sklearn.preprocessingからインポートStandardScaler
st_x = StandardScaler()
x_train = st_x.fit_transform(x_train)
x_test = st_x.transform(x_test)
つまり、これが機械学習でのデータ処理です。
upGradに関連して、機械学習とAIに関するIITデリーのエグゼクティブPGプログラムを確認できます。 IITデリーは、インドで最も権威のある機関の1つです。 主題で最高の500人以上の社内教員がいます。
データ前処理の重要性は何ですか?
エラー、冗長性、欠落値、および不整合はすべてデータセットの整合性を危険にさらすため、より正確な結果を得るには、それらすべてに対処する必要があります。 欠陥のあるデータセットを使用して、クライアントの購入に対処するための機械学習システムをトレーニングしていると仮定します。 システムはバイアスや偏差を生成する可能性があり、その結果、ユーザーエクスペリエンスが低下します。 その結果、意図した目的でそのデータを使用する前に、可能な限り整理され、「クリーン」である必要があります。 対処している問題の種類に応じて、多数のオプションがあります。
データクリーニングとは何ですか?
データセットには、ほぼ確実に欠落したノイズの多いデータが含まれます。 データ収集手順は理想的ではないため、役に立たない情報や欠落している情報がたくさんあります。 データクリーニングは、この問題に対処するために採用する必要がある方法です。 これは2つのカテゴリに分けることができます。 1つ目は、欠落データを処理する方法について説明します。 データ収集のこのセクション(タプルと呼ばれる)で欠落している値を無視することを選択できます。 2番目のデータクリーニング方法は、ノイズの多いデータ用です。 プロセス全体をスムーズに実行したい場合は、システムで読み取ることができない不要なデータを取り除くことが重要です。
データの変換と削減とはどういう意味ですか?
データの前処理は、懸念事項に対処した後、変換段階に進みます。 これを使用して、分析のためにデータを関連するコンフォメーションに変換します。 正規化、属性選択、離散化、および概念階層の生成は、これを実現するために使用できるアプローチの一部です。 自動化された方法の場合でも、大規模なデータセットの選別には長い時間がかかる可能性があります。 そのため、データ削減段階は非常に重要です。データセットを最も重要な情報に限定することでデータセットのサイズを削減し、ストレージの効率を高めながら、データセットを操作するための費用と時間のコストを削減します。