
インド2022年のデータエンジニアの給与[平均から最高]
公開: 2021-01-10データエンジニアの職務内容は、業界で最も需要の高い役割の1つです。 彼らはすべてのセクターの企業から高く評価されており、スキルと才能を提供するために高い給与を獲得しています。
ますます多くの企業がビッグデータの時流に参加し、貴重な洞察を生み出すためにデータをマイニングするにつれて、データ関連の仕事に対する需要は日ごとに高まっています。 データエンジニアも例外ではありません。 企業は、大量の複雑なデータを処理し、それを処理してビジネスにとって意味のある洞察を引き出すことができる熟練したデータエンジニアを常に探しています。 また、この仕事にはビッグデータに関する高度なスキルと専門知識が必要であるため、データエンジニアの給与は拡大しているだけです。 ビッグデータエンジニアになる方法を読んでください。
Burning GlassのNovaプラットフォームによって作成された最近のデータによると、データエンジニアの仕事は、技術分野でトップの仕事としてランク付けされており、12か月間に88.3%の求人広告の増加を記録しています。

ソース
目次
データエンジニアになるには何が必要ですか?
データエンジニアの主な仕事は、データサイエンティストが使用できるような形式にデータを変換するための、信頼性の高いインフラストラクチャを設計および設計することです。 半構造化データと非構造化データを使用可能な形式に変換するためのスケーラブルなパイプラインを構築する以外に、データエンジニアは大規模なデータセットの意味のある傾向を特定する必要もあります。 基本的に、データエンジニアは、生データを準備し、分析または運用での使用により役立つようにするために作業します。 データエンジニアについては多くの神話があり、それらのほとんどは現実からかけ離れています。 データエンジニアの神話と現実についてもっと読む。
組織では、データエンジニアの立場は、データサイエンティストの立場と同じくらい重要です。 データエンジニアが脚光を浴びないままでいる唯一の理由は、分析の最終製品への直接のリンクがないことです。 データエンジニアになるには、データサイエンスコースをご覧ください。
データエンジニアの特定のタスクは会社ごとに異なる可能性がありますが、次のようないくつかの共通の責任を共有しています。
- 複数のソースから収集されたデータを統合、統合、およびクレンジングします。
- データサイエンティストによる操作および予測/処方モデリングのために生データを準備します。
- SQL、AWS、およびその他のビッグデータテクノロジーを使用して、異種ソースからのデータの最適な抽出、変換、およびロードに必要なインフラストラクチャを開発します。
- 高度な分析プログラム、機械学習アルゴリズム、統計手法を導入して、データパイプラインを構築します。
- 機能的および非機能的なビジネス要件に対応するために、膨大で複雑なデータセットを組み立てます。
- データの信頼性、効率、品質を向上させる革新的な方法を特定して開発します。
- データアーキテクチャを開発、構築、テスト、および保守します。
- 既存のフレームワークを再考および再設計して、それらの機能を最適化します。
- データアーキテクチャをビジネス要件に完全に適合するように調整します。
- 業界調査を実施して、最新の市場動向を常に把握してください。
- 同僚やクライアントと協力して、プロジェクトの要件を決定します。
また読む:インドのデータサイエンティスト給与
データエンジニアになるために必要なスキル
- アクティブなプロジェクト管理と組織力。
- 大規模な非構造化データセットを処理および操作するための優れた分析スキル。
- Python、Java、C ++、Scala、Rubyなどのトレンド言語での強力なプログラミングの才能。
- SQLの高度な実務知識と、リレーショナルデータベースの運用経験。
- 多種多様なデータベースの操作に習熟していること。
- ビッグデータパイプラインとアーキテクチャの構築と最適化の経験。
- 内部/外部のデータとプロセスで根本原因分析を実行して、特定のビジネス問題の解決策を見つけ、改善の機会を特定した経験。
- Hadoop、Spark、Kafka、Flume、Pig、Hiveなどのビッグデータプラットフォームでの作業経験。
- Azkaban、Luigi、Airflowなどのデータパイプラインおよびワークフロー管理ツールの取り扱い経験。
- StormやSpark-Streamingなどのストリーム処理システムの取り扱い経験。
データエンジニアの給与
Glassdoorによると、インドのデータエンジニアの平均給与はRs.8,56,643LPAです。 しかしもちろん、データエンジニアの給与は、会社の規模と評判、地理的な場所、教育資格、職位、仕事の経験など、いくつかの要因によって異なります。 いくつか例を挙げると、Amazon、Airbnb、Spotify、Netflix、IBM、Accenture、Deloitte、Capgeminiなどのビッグデータ業界で評判の高い企業や大手企業は、通常、データエンジニアに高い報酬を支払っています。 また、ビッグデータでの過去の仕事の経験が多ければ多いほど、市場価値は高くなります。

世界的な需要と供給のパラドックス(データエンジニアの需要は供給をはるかに上回っています)にもかかわらず、データエンジニアのキャリアの見通しはインドで有望に見えます。 Analytics India Magazineのレポートによると、
「IT企業はネガティブな傾向を示していますが、データエンジニアリングの専門家に対する需要は企業全体で増加しており、その結果、給与体系が大幅に向上しています。 一方、分析スキル全体の給与については、高度な分析の役割と予測モデリングの専門家が他の役割と比較して脚光を浴びました。」
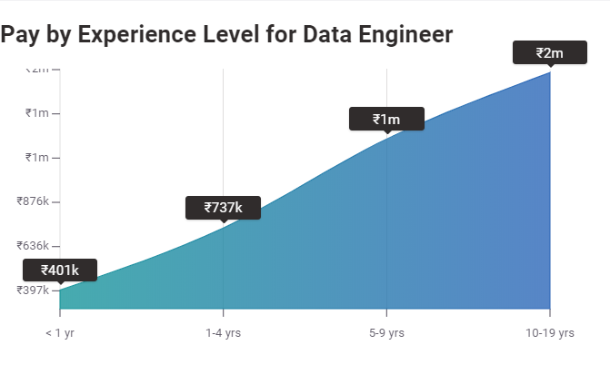
この分野で十分な人材が不足しているため、企業は新入生や中堅のデータエンジニアにも巨額の報酬を支払う準備ができています。 PayScaleの統計によると、経験が1年未満のエントリーレベルのデータエンジニアは、平均年収Rs.4,00,676LPAを獲得できます。
彼らの初期のキャリア(1-4年の経験)のデータエンジニアに関しては、彼らはRs.7,37,257LPAの周りのどこでも作ります。 中級レベル(5〜9年の経験)に進むと、データエンジニアの給与はRs.1,218,983LPAになります。 15年以上の実務経験を持つデータエンジニアは、1,579,282ルピー以上のLPAを作成できます。
ソース
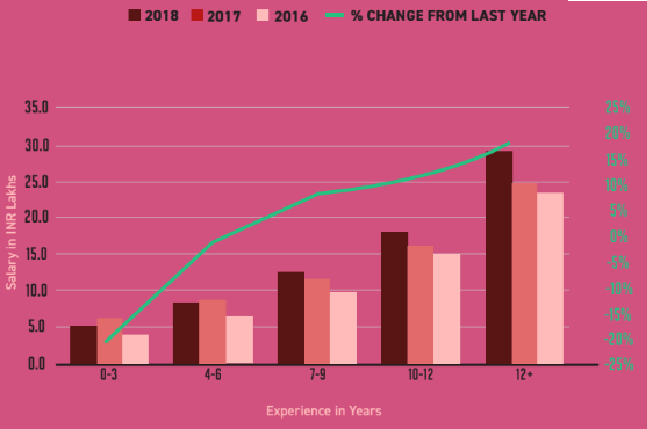
報酬に関するもう1つの大きな進歩は、給与パッケージがRs未満の分析専門家の割合です。 6LPAが大幅に減少しました。 現在、インドの分析専門家の37.6%がRs.6 LPA未満を作成しています。これは、2017年(39%)および2016年(42%)よりも低くなっています。
ソース
結論
インドおよび海外でデータ分析とビッグデータの仕事が着実に増加していることを考えると、データエンジニアになることを検討する絶好の機会です。 データサイエンスの分野には多くの職務範囲があり、将来さらに拡大することが見込まれています。
データドメインに参加したい場合は、3000人以上の学生に力を与えてきたデータサイエンスのIIIT-BとupGradのエグゼクティブPGプログラムをチェックしてください。 10以上のケーススタディ、実践的なハンズオンワークショップなど、データサイエンスのエキスパートになりましょう。
データエンジニアの役割と責任は何ですか?
すべてのプロセスと企業の成長はデータを中心に展開するため、ここではデータエンジニアの役割が重要になります。 データエンジニアに期待される主な責任の一部を次に示します。データエンジニアの最終的なタスクは、生データをさらに使用、分析、および評価できるようにすることです。 分析チームの重要なプレーヤーであるデータエンジニアは、過去の傾向の分析などのプロセスを実行し、会社の要件を理解し、データを変換してビジネス目標に合わせることができるアルゴリズムを開発することが期待されています。 技術的なタスクとは別に、データエンジニアは、組織の要件と目標を理解するために、十分なコミュニケーションを取り、ビジネス指向の洞察を持っている必要があります。
データエンジニアは平均していくら稼ぎますか?
インドのデータエンジニアは見事に稼いでいます。 1〜4年の経験を持つデータエンジニアは、年間約£7,37,257ラックを稼いでいます。 さらに、あなたの経験が増えるにつれて、給料の上昇は劇的に増加します。 データエンジニアの給与は、彼/彼女の経験に正比例します。 5〜9年の経験を持つ中堅データエンジニアには、年間約1,218,983ラックが支払われます。 15年以上の経験を持つエンジニアは、年間1,579,282ラックの豪華なパッケージを手に入れます。
データエンジニアになるにはどのようなスキルが必要ですか?
データエンジニアになるには、意志力以上のものが必要です。 データエンジニアリングで優れているために習得しなければならない特定のスキルがあります。 これらのスキルは次のとおりです。強力なプログラミングの基礎と、Python、R、Java、Scalaなどの一般的なプログラミング言語の構文に精通していること。 非構造化データの大きなチャンクを処理および操作するための優れた分析スキル。 SQLに関する豊富な知識とリレーショナルデータベースの実践的な経験。 MongoDBなどの一般的なDBMSの操作に習熟していること。 ビッグデータパイプラインとアーキテクチャの構築と最適化の経験。 Hadoop、Spark、Kafka、Flume、Pig、Hiveなどのビッグデータソフトウェアを使用した実務経験。Azkaban、Luigi、Airflowなどのデータパイプラインおよびワークフロー管理ツールの処理経験。