
エージェンシーでの新しいサーバーレスデータベーステクノロジーの選択(ケーススタディ)
公開: 2022-03-10この記事は、すべてのソフトウェア開発チームにとって、運用データの操作を生産的でスケーラブルかつ安全なものにする、Faunaの親愛なる友人たちによって親切にサポートされています。 ありがとう!

新しいテクノロジーを採用することは、リーダーシップの役割を担う技術者にとって最も難しい決断の1つです。 これは、別の組織用にソフトウェアを構築している場合でも、自分の組織内でソフトウェアを構築している場合でも、多くの場合、大きくて不快なリスク領域です。
ソフトウェアエンジニアとしての過去12年間、私は新しいテクノロジーをますます頻繁に評価しなければならない立場にいることに気づきました。 これは、次のフロントエンドフレームワーク、新しい言語、またはサーバーレスのようなまったく新しいアーキテクチャである可能性があります。
実験段階はしばしば楽しくてエキサイティングです。 ここは、ソフトウェアエンジニアが最も家にいる場所であり、新しい概念を模索しながら、「あは」の瞬間の斬新さと陶酔感を受け入れています。 エンジニアとして、私たちは考えていじくり回すのが好きですが、十分な経験を積むと、すべてのエンジニアは、最も素晴らしいテクノロジーでさえ欠点があることを学びます。 あなたはまだそれらを見つけていません。
現在、クリエイティブエージェンシーの共同創設者として、私のチームと私はしばしば新しいテクノロジーを使用するというユニークな立場にあります。 多くのグリーンフィールドプロジェクトがあり、新しいものを紹介する絶好の機会になります。 これらのプロジェクトはまた、大規模な組織からある程度の技術的孤立が見られ、多くの場合、事前の決定による負担が少なくなります。
そうは言っても、優れたエージェンシーリーダーは、他の誰かの大きなアイデアを世話し、それを世界に届けることを任されています。 私たち自身のプロジェクトよりもさらに注意深く扱う必要があります。 新しいテクノロジーについて最後の呼びかけをするときはいつでも、共同創設者のStack OverflowJoelSpolskiからのこの知恵についてよく考えます。
「それが十分に良いことを本当に知ったり、どんなに頑張ってもできないことに気付く前に、1、2年は汗をかいて出血しなければなりません...」
これは恐れです。これは、技術リーダーが自分自身を見つけたくない場所です。実際のプロジェクトに新しい技術を選択することは十分に困難ですが、代理店として、他の誰かのプロジェクト、誰かとこれらの決定を下さなければなりません。他人の夢、他人のお金。 代理店で、あなたが望む最後のことは、プロジェクトの締め切り近くにそれらの傷の1つを見つけることです。 スケジュールと予算が厳しいため、特定のしきい値を超えた後、コースを逆にすることはほぼ不可能です。そのため、テクノロジーが重要なことを実行できない、またはプロジェクトに遅すぎる信頼性がないことを発見すると、壊滅的となる可能性があります。
ソフトウェアエンジニアとしてのキャリアを通じて、私はSaaS企業やクリエイティブエージェンシーで働いてきました。 プロジェクトに新しいテクノロジーを採用する場合、これら2つの環境の基準は大きく異なります。 基準には重複がありますが、概して、政府機関の環境は厳格な予算と厳格な時間的制約に対応する必要があります。 私たちが構築する製品は時間の経過とともに十分に古くなることを望んでいますが、証明されていないものに投資したり、より急な学習曲線と粗いエッジを持つテクノロジーを採用したりすることは、多くの場合より困難です。
そうは言っても、エージェンシーには、単一の組織にはないかもしれないいくつかの固有の制約もあります。 効率と安定性にバイアスをかける必要があります。 多くの場合、請求可能な時間は、プロジェクトが完了したときの最終的な測定単位です。 私はSaaS企業にいて、セットアップやビルドパイプラインに1日か2日を費やしても大したことはありません。
あるエージェンシーでは、財務チームが目に見える結果がほとんどないために利益率が狭くなっていることを認識しているため、このタイプの時間コストは関係に負担をかけます。 また、プロジェクトの長期的なメンテナンス、および逆に、プロジェクトをクライアントに引き渡す必要がある場合はどうなるかを考慮する必要があります。 したがって、選択するテクノロジーの効率、学習曲線、および安定性にバイアスをかける必要があります。
新しいテクノロジーを評価するとき、私は3つの包括的な領域に注目します。
- テクノロジー
- 開発者エクスペリエンス
- ビジネス
これらの各領域には、コードを実際に調べて実験を始める前に満たした一連の基準があります。 この記事では、これらの基準を確認し、プロジェクトの新しいデータベースを検討する例を使用して、各レンズの下で高レベルでレビューします。 このような具体的な決定を行うことは、このフレームワークを現実の世界にどのように適用できるかを示すのに役立ちます。
テクノロジー
新しいテクノロジーを評価するときに最初に確認することは、そのソリューションが解決すると主張する問題を解決できるかどうかです。 テクノロジーがプロセスとビジネスオペレーションにどのように役立つかを理解する前に、まずテクノロジーが機能要件を満たしていることを確認することが重要です。 ここでは、私たちが使用している既存のソリューションと、この新しいソリューションがそれらとどのように重なるかを見てみたいと思います。
私は自分自身に次のような質問をします:
- それは少なくとも私の既存の解決策がする問題を解決しますか?
- このソリューションはどのように優れていますか?
- どのようにそれは悪いですか?
- さらに悪い分野では、これらの欠点を克服するために何が必要ですか?
- 複数のツールの代わりになりますか?
- 技術はどれくらい安定していますか?
私たちの理由は?
この時点で、なぜ別の解決策を模索しているのかについても確認したいと思います。 簡単な答えは、既存のソリューションでは解決できない問題が発生しているということです。 ただし、これはめったにありません。 私たちは、今日のすべてのテクノロジーを使用して、長年にわたって多くのソフトウェアの問題を解決してきました。 通常起こることは、私たちが現在行っていることをより簡単に、より安定して、より速く、またはより安くする新しいテクノロジーに転向することです。
例としてReactを取り上げましょう。 jQueryまたはVanillaJavaScriptがその仕事をしているときに、なぜReactを採用することにしたのですか? この場合、フレームワークを使用すると、これがステートフルフロントエンドを処理するためのはるかに優れた方法であることが明らかになりました。 DOMを直接操作する代わりに、データ構造を操作することで、フィルタリングや並べ替え機能などを構築するのが速くなりました。 これにより、時間の節約とソリューションの安定性の向上が実現しました。
Typescriptは、コードの安定性と保守性の向上が見られたため、採用することを決定したもう1つの例です。 新しいテクノロジーを採用することで、解決しようとしている明確な問題がないことがよくあります。むしろ、最新の状態を維持し、現在使用しているよりも効率的で安定したソリューションを見つけることを目指しています。
データベースの場合、特にサーバーレスオプションへの移行を検討していました。 サーバーレスアプリケーションとデプロイメントで多くの成功を収め、組織としてのオーバーヘッドを削減しました。 これが不足していると感じた領域の1つは、データレイヤーでした。 サーバーレスの原則をデータベースに適用しているAmazonAurora、Fauna、Cosmos、Firebaseなどのサービスを見て、自分たちで飛躍する時が来たかどうかを確認したいと考えていました。 この場合、運用オーバーヘッドを削減し、開発の速度と効率を向上させることを目指していました。
このレベルでは、新しい製品に飛び込む前に、その理由を理解することが重要です。 これは、新しい問題を解決していることが原因である可能性がありますが、多くの場合、すでに解決しているタイプの問題を解決する能力を向上させようとしています。 その場合、ワークフローに意味のある改善をもたらすものを見つけるために、どこに行ったかのインベントリを作成する必要があります。 サーバーレスデータベースを検討する例に基づいて、現在どのように問題を解決しているか、およびそれらの解決策がどこで不十分であるかを確認する必要があります。
私たちがいた場所…
代理店として、これまで、MySQL、PostgreSQL、MongoDB、DynamoDB、BigQuery、FirebaseCloudStorageを含むがこれらに限定されない幅広いデータベースを使用してきました。 ただし、私たちの作業の大部分は、PostgreSQL、MongoDB、FirebaseRealtimeDatabaseの3つのコアデータベースを中心にしています。 実際、これらのそれぞれにセミサーバーレスオファリングがありますが、新しいオファリングのいくつかの重要な機能により、以前の仮定を再評価する必要がありました。 これらのそれぞれについての私たちの歴史的経験と、そもそもなぜ私たちが代替案を検討しているのかを見てみましょう。
私たちは通常、大規模で長期的なプロジェクトにPostgreSQLを選択しました。これは、ほとんどすべての分野でテスト済みのゴールドスタンダードであるためです。 従来のトランザクション、正規化されたデータをサポートし、ACIDに準拠しています。 ほぼすべての言語で利用できるツールとORMが豊富にあり、JSON列をサポートするアドホックNoSQLデータベースとしても使用できます。 多くの既存のフレームワーク、ライブラリ、プログラミング言語とうまく統合できるため、どこにでも持ち運べる真の主力製品になります。 また、オープンソースであるため、1つのベンダーに縛られることはありません。 彼らが言うように、Postgresを選んだことで誰も解雇されたことはありません。
そうは言っても、ノード指向のショップになるにつれて、PostgreSQLの使用は徐々に少なくなっています。 NodeのORMは光沢がなく、より多くのカスタムクエリが必要であることがわかり(これは今では問題が少なくなっていますが)、JavaScriptまたはTypeScriptランタイムで作業する場合はNoSQLの方が自然に適していると感じました。 そうは言っても、eコマースワークフローのような従来のリレーショナルモデリングを使用して非常に迅速に実行できるプロジェクトがよくありました。 ただし、データベースのローカルセットアップの処理、チーム間のテストフローの統合、およびローカル移行の処理は、私たちが気に入らなかったものであり、NoSQLとして、クラウドベースのデータベースの人気が高まりました。
優先バックエンドとしてNode.jsを採用したため、 MongoDBはますます頼りになるデータベースになりました。 MongoDB Atlasを使用することで、私たちのチームが使用できるデータベースの迅速な開発とテストを簡単に行うことができました。 しばらくの間、MongoDBはACIDに準拠しておらず、トランザクションをサポートしておらず、内部結合のような操作が多すぎることを思いとどまらせていました。そのため、eコマースアプリケーションでは、依然としてPostgresを最も頻繁に使用していました。 そうは言っても、それに対応するライブラリは豊富にあり、Mongoのクエリ言語とファーストクラスのJSONサポートにより、リレーショナルデータベースでは経験したことのない速度と効率が得られました。 MongoDBは最近ACIDトランザクションのサポートを追加しましたが、長い間、これが代わりにPostgresを選択する主な理由でした。
MongoDBはまた、新しいレベルの柔軟性をもたらしました。 エージェンシープロジェクトの途中で、要件は必ず変更されます。 それに対してどれほど厳しく防御しても、常に土壇場でのデータ要件があります。 一般に、NoSQLデータベースでは、データ構造の柔軟性により、これらのタイプの変更はそれほど厳しくありませんでした。 プロジェクトが日光を浴びる前に、追加、削除、追加された列を管理するための移行ファイルでいっぱいのフォルダーになってしまうことはありませんでした。
サービスとして、Mongo Atlasは、データベースクラウドサービスで私たちが望んでいたものにもかなり近いものでした。 Atlasの管理にはまだ運用上のオーバーヘッドがあるため、Atlasをセミサーバーレスオファリングと考えるのが好きです。 特定のサイズのデータベースをプロビジョニングし、事前にメモリの量を選択する必要があります。 これらは自動的にスケーリングされないため、より多くのスペースまたはメモリを提供する時期が来たときに監視する必要があります。 真のサーバーレスデータベースでは、これはすべて自動的にオンデマンドで行われます。
また、いくつかのプロジェクトでFirebaseRealtimeDatabaseを利用しました。 これは確かに、データベースがオンデマンドでスケールアップおよびスケールダウンするサーバーレス製品であり、従量課金制で、スケールが事前にわかっておらず、予算が限られているアプリケーションにとっては理にかなっています。 単純なデータ要件を持つ短期間のプロジェクトでは、MongoDBの代わりにこれを使用しました。
Firebaseについて私たちが楽しんでいなかったことの1つは、私たちが慣れ親しんだ正規化されたデータを中心に構築された典型的なリレーショナルモデルから遠く離れていると感じたことです。 データ構造をフラットに保つことは、多くの場合、重複が多くなることを意味し、プロジェクトが成長するにつれて少し醜くなる可能性があります。 最終的に、同じデータを複数の場所で更新したり、異なる参照を結合しようとしたりすると、コード内で推論するのが難しくなる可能性のある複数のクエリが発生します。 Firebaseは気に入っていましたが、クエリ言語に夢中になることはなく、ドキュメントがつまらない場合もありました。
一般に、MongoDBとFirebaseはどちらも非正規化データに同様の焦点を当てており、効率的なトランザクションにアクセスできないため、リレーショナルデータベースでモデル化するのが簡単なワークフローの多くが見つかりました。そのため、アプリケーション層でより複雑なコードが作成されました。 NoSQLの対応物。 従来のSQLデータベースの堅牢性とリレーショナルモデリングを使用して、これらのNoSQL製品の柔軟性と使いやすさを実現できれば、本当に素晴らしい一致が見つかります。 MongoDBの方がAPIと機能が優れていると感じましたが、Firebaseの運用上は真にサーバーレスモデルでした。
私たちの理想
この時点で、検討する新しいオプションを検討し始めることができます。 以前のソリューションを明確に定義し、新しいソリューションで最低限必要なものを特定しました。 ベースラインまたは最小の要件セットがあるだけでなく、新しいソリューションで軽減してほしい一連の問題もあります。 技術的な要件は次のとおりです。
- オンデマンドスケールで運用上サーバーレス
- 柔軟なモデリング(スキーマレス)
- 移行やORMに依存しない
- ACID準拠のトランザクション
- 関係と正規化されたデータをサポートします
- サーバーレスバックエンドと従来のバックエンドの両方で動作します
必須アイテムのリストができたので、実際にいくつかのオプションを評価できます。 新しいソリューションがここですべてのターゲットを釘付けにすることは重要ではないかもしれません。 既存のソリューションが重複していない機能の適切な組み合わせに当てはまる可能性があります。 たとえば、スキーマレスの柔軟性が必要な場合は、ACIDトランザクションを放棄する必要がありました。 (これは、データベースでは長い間当てはまりました。)
別のドメインの例として、テンプレートレンダリングでタイプスクリプトの検証を行う場合は、TSXとReactを使用する必要があります。 SvelteやVueなどのオプションを使用する場合は、テンプレートレンダリングを使用して、これを部分的に(完全ではありませんが)行うことができます。 したがって、ReactとTypeScriptのテンプレートレベルのタイプチェックを使用してSvelteの小さなフットプリントと速度を提供するソリューションは、別の機能が欠落している場合でも採用するには十分である可能性があります。 プロジェクトごとに、ウォンツとニーズのバランスが変化します。 値がどこにあるかを把握し、分析で最も重要なポイントをチェックする方法を決定するのはあなた次第です。
これで、ソリューションを見て、目的のソリューションに対してどのように評価されるかを確認できます。 Faunaは、グローバルな分散を備えたオンデマンドスケールを誇るサーバーレスデータベースソリューションです。 これはスキーマレスデータベースであり、ACID準拠のトランザクションを提供し、機能としてリレーショナルクエリと正規化データをサポートします。 動物相は、サーバーレスアプリケーションと従来のバックエンドの両方で使用でき、最も一般的な言語で動作するライブラリを提供します。 動物相はさらに、認証のためのワークフローと、簡単で効率的なマルチテナンシーを提供します。 これらは両方とも、2つのテクノロジーが評価でノーズツーノーズである場合に変動要因となる可能性があるため、注意すべき確かな追加機能です。
これらの長所をすべて調べた後、短所を評価する必要があります。 そのうちの1つは、動物相はオープンソースではありません。 これは、ベンダーロックイン、またはビジネスや価格の変更が制御不能になるリスクがあることを意味します。 オープンソースは、プロジェクトに喜んで貢献したり、貢献したりする可能性がある場合に、テクノロジーを別のベンダーに提供できることが多いため、便利です。
エージェンシーの世界では、ベンダーロックインは私たちが注意深く見なければならないものであり、価格のせいではありませんが、基盤となるビジネスの実行可能性は重要です。 開発中または数年前のプロジェクトでデータベースを変更しなければならないことは、どちらも代理店にとって悲惨なことです。 多くの場合、クライアントはこのための費用を負担する必要がありますが、これは楽しい会話ではありません。
私たちが懸念していたもう1つの弱点は、 JAMstackに焦点を当てていることです。 私たちはJAMstackが大好きですが、さまざまな従来のWebアプリケーションをより頻繁に構築していることに気づきます。 Faunaがこれらのユースケースを引き続きサポートすることを確認したいと思います。 過去にJAMstackにオールインしたホスティングプロバイダーとの悪い経験があり、サービスからかなり広い範囲のサイトを移行する必要があったため、すべてのユースケースが引き続き表示されることを確信したいと思います。支持を固める。 今のところ、これは事実のようであり、Faunaが提供するサーバーレスワークフローは、実際には、より従来のアプリケーションを非常にうまく補完することができます。
この時点で、私たちは機能調査を行いました。このソリューションが実行可能かどうかを知る唯一の方法は、降りてコードを書くことです。 代理店環境では、人々が複数のソリューションを評価するためのスケジュールから数週間かかることはできません。 これは、代理店とSaaS環境での作業の性質です。 後者では、適切なソリューションを取得するために、いくつかのプロトタイプを作成する場合があります。 エージェンシーでは、実験に数日かかるか、サイドプロジェクトを行う機会がありますが、概して、この段階でこれを1つまたは2つのテクノロジーに絞り込んでから、キーボードに指を置く必要があります。
開発者エクスペリエンス
新しいテクノロジーの経験面を判断することは、本質的に主観的であるため、おそらく3つの領域の中で最も難しいでしょう。 また、チームごとにばらつきがあります。 たとえば、Rubyプログラマー、Pythonプログラマー、およびRustプログラマーに、さまざまな言語機能に関する意見について尋ねると、かなりの数の応答が得られます。 したがって、経験を判断する前に、まずチーム全体にとって最も重要な特性を決定する必要があります。

エージェンシーにとって、開発者の経験に関して浮かび上がる2つの主要なボトルネックがあると思います。

- セットアップ時間と構成
- 学習可能性
これらは両方とも、さまざまな方法で新しいテクノロジーの長期的な実行可能性に影響を与えます。 代理店で開発者の一時的なチームの同期を維持することは、頭痛の種になる可能性があります。 事前のセットアップコストと構成が多いツールは、代理店が使用するのが難しいことで有名です。 もう1つは、学習可能性と、開発者が新しいテクノロジーを成長させるのがいかに簡単かということです。 これらについて詳しく説明し、開発者の経験を評価し始めるときに、なぜそれらが私のベースであるのかを説明します。
セットアップ時間と構成
エージェンシーは、構成のための忍耐力と時間がほとんどない傾向があります。 私にとっては、人間工学に基づいたデザインの鋭利なツールが大好きです。これにより、目前のビジネス上の問題にすばやく取り組むことができます。 数年前、私は多くの構成を含む複雑なローカルセットアップを持ち、セットアッププロセスのランダムなポイントで失敗することが多いSaaS会社で働いていました。 一度セットアップすると、従来の知識は何にも触れないことでした。別のマシンで再度セットアップする必要があるほど長く会社にいなかったことを願っています。 私は、emacsセットアップの各小さな部分を構成することを大いに楽しんでいて、壊れたローカル環境に数時間を失うことを何も考えていない開発者に会いました。
一般的に、代理店のエンジニアは、日常業務でこの種のことを軽蔑していることがわかりました。 家にいる間、彼らはこれらのタイプのツールをいじくり回すかもしれませんが、締め切りになると、ちょうど機能するツールのようなものはありません。 代理店では、通常、各技術を各個人の好みに合わせて構成できるようにするのではなく、一貫してうまく機能するいくつかの新しいことを学びたいと考えています。
オープンソースではないクラウドプラットフォームを使用することの良い点の1つは、セットアップと構成を完全に所有していることです。 これの欠点はベンダーロックインですが、利点は、これらのタイプのツールが、うまく機能するように設定されていることを実行することが多いことです。 環境をいじくり回したり、ローカルセットアップを行ったり、展開パイプラインを作成したりする必要はありません。 また、決定する必要が少なくなります。
これは本質的にサーバーレスの魅力です。 サーバーレスは一般に、独自のサービスやツールに大きく依存しています。 ホスティングとソースコードの柔軟性を交換して、安定性を高め、解決しようとしているビジネスドメインの問題に集中できるようにします。 また、テクノロジーを評価しているときに、プラットフォームからの移行が必要になる可能性があると感じた場合、これは最初は悪い兆候であることがよくあります。
データベースの場合、データベースのニーズがあいまいになる可能性があるクライアントを操作する場合は、set-it-and-forget-itセットアップが理想的です。 プログラムやアプリケーションがどれほど人気があるかわからないクライアントがいます。 技術的にはこの方法でサポートする契約を結んでいないクライアントがいますが、データベースやアプリケーションの拡張が必要になったときにパニックに陥りました。
以前は、SOWを作成するときに、冗長性、データレプリケーション、スケーリングのシャーディングなどを常に考慮に入れる必要がありました。 データベースが拡張されていない場合にビジネスの完全な本を移動する準備をしながら、各シナリオをカバーしようとすることは、準備するのが不可能な状況です。 結局、サーバーレスデータベースはこれらのことを容易にします。
データを失うことはなく、ネットワーク全体でデータを複製することを心配する必要も、それを実行するためのより大きなデータベースとマシンをプロビジョニングする必要もありません。すべてが正常に機能します。 私たちは目前のビジネス上の問題にのみ焦点を当て、技術的なアーキテクチャと規模は常に管理されます。 私たちの開発チームにとって、これは大きな勝利です。 ファイアドリル、監視、コンテキスト切り替えが少なくなります。
学習可能性
古典的なユーザーエクスペリエンスの尺度がありますが、これは開発者のエクスペリエンスに適用できると思います。それは学習可能性です。 特定のユーザーエクスペリエンスを考慮して設計する場合、最初の試行で何かが明らかであるか簡単であるかを確認するだけではありません。 テクノロジーは、ほとんどの場合よりも複雑です。 重要なのは、新しいユーザーがシステムをどれだけ簡単に習得して習得できるかです。
技術的なツール、特に強力なツールに関しては、学習曲線がゼロになるように求めるのは大変なことです。 通常、私たちが探しているのは、最も一般的なユースケースの優れたドキュメントがあり、プロジェクトに参加するときにその知識を簡単かつ迅速に構築できるようにすることです。 テクノロジーを使った最初のプロジェクトで学ぶために少し時間を失っても大丈夫です。 その後、プロジェクトを進めるたびに効率が向上するはずです。
ここで特に探しているのは、すでに知っている知識とパターンを活用して、学習曲線を短縮する方法です。 たとえば、サーバーレスデータベースでは、データベースをクラウドにセットアップしてデプロイするための学習曲線は事実上ゼロになります。 データベースの使用に関して、私が気に入っていることの1つは、リレーショナルデータベースをマスターしてきた長年の経験を活用し、それらの学習を新しいセットアップに適用できることです。 この場合、新しいツールの使用方法を学習していますが、データモデリングをゼロから再考する必要はありません。

この例として、Firebase、MongoDB、DynamoDBを使用すると、異なるドキュメントを結合しようとするのではなく、非正規化されたデータが促進されることがわかりました。 これにより、データをモデル化する際に、ビジネスエンティティではなくアクセスパターンの観点から考える必要があるため、多くの認知的摩擦が生じました。 この動物相の反対側では、モデリングデータに関して、長年のリレーショナル知識と正規化されたデータの好みを活用することができました。
私たちが慣れなければならなかったのは、インデックスと新しいクエリ言語を使用してそれらをまとめることでした。 一般に、より大きなソフトウェア設計パラダイムの一部である概念を保持することで、学習可能性と採用の点で開発チームが容易になることがわかりました。
チームが新しいテクノロジーを採用し、愛していることをどうやって知ることができますか? 最良の兆候は、そのツールが前述の新しいテクノロジーと統合されているかどうかを自問するときだと思います。 新しいテクノロジーが、チームがそれをより多くのプロジェクトに組み込む方法を模索しているという望ましさと楽しさのレベルに達したとき、それはあなたが勝者を持っている良い兆候です。
ビジネス
このセクションでは、新しいテクノロジーがビジネスニーズをどのように満たすかを確認する必要があります。 これらには、次のような質問が含まれます。
- 価格設定とサポートプランへの統合はどれほど簡単にできますか?
- クライアントに簡単に移行できますか?
- 必要に応じて、クライアントをこのツールにオンボーディングできますか?
- このツールが実際にどれくらいの時間を節約しますか?
パラダイムとしてのサーバーレスの台頭は、エージェンシーにぴったりです。 データベースとDevOpsについて話すとき、代理店でこれらの分野のスペシャリストの必要性は限られています。 多くの場合、プロジェクトが終了したとき、または限られた容量で長期的にプロジェクトをサポートしたときに、プロジェクトを引き渡します。 フルスタックエンジニアは、DevOpsのニーズを大幅に上回っているため、バイアスをかける傾向があります。 DevOpsエンジニアを雇った場合、プロジェクトの展開に数時間かかり、火災を待つためにさらに多くの時間を費やす可能性があります。
この点で、私たちは常にいくつかのDevOps請負業者を準備していますが、これらのポジションにフルタイムでスタッフを配置することはありません。 これは、予期しない問題にジャンプする準備ができていることをDevOpsエンジニアに頼ることができないことを意味します。 AWSに直接アクセスすることで、ホスティングの料金を引き上げることができますが、Herokuを使用することで、ほとんどの問題をデバッグするために既存のスタッフに頼ることができることもわかっています。 特定のバックエンドのニーズで長期的にサポートする必要のあるクライアントがない限り、デフォルトでサービスとしてのマネージドプラットフォームを使用します。
データベースも例外ではありません。 このプロセスをできるだけ簡単にするために、MongoAtlasやHerokuPostgresなどのサービスを利用するのが大好きです。 Vercel、Netlify、AWS Lambdaなどのサーバーレスツールへのスタックヘッドがますます増えているため、データベースのニーズはそれに合わせて進化する必要がありました。 Firebase、DynamoDB、Faunaなどのサーバーレスデータベースは、サーバーレスアプリとうまく統合できるだけでなく、プロビジョニングやスケーリングからビジネスを完全に解放できるため、優れています。
これらのソリューションは、サーバーレスアプリケーションがない従来のアプリケーションでもうまく機能しますが、データベースレベルでサーバーレスの効率を活用できます。 ビジネスとして、コンテキストスイッチよりも両方の世界に適用できる単一のデータベースを学ぶ方が生産的です。 これは、Nodeと同形JavaScript(およびTypeScript)を採用するという私たちの決定に似ています。
サーバーレスで私たちが見つけた欠点の1つは、これらのサービスを管理するクライアントの価格設定を考え出すことです。 より伝統的なアーキテクチャでは、定額制の階層により、増加や超過が発生する予測可能な状況にあるクライアントの料金にそれらを非常に簡単に変換できます。 サーバーレスになると、これはあいまいになる可能性があります。 金融関係者は通常、100万を超える読み取りごとに1ペニーの1/10を請求するなど、聞くのが好きではありません。
使用法がわからないアプリケーションを作成することが多いため、エンジニアでもこれを固定数に変換するのは困難です。 多くの場合、自分でティアを作成する必要がありますが、ラムダのコスト計算に使用される多くの変数は、頭を悩ませるのが難しい場合があります。 最終的に、SaaS製品の場合、これらの従量課金制の価格設定モデルは優れていますが、代理店の場合、会計士はより具体的で予測可能な数値を好みます。
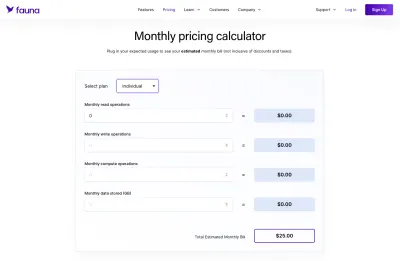
動物相に関して言えば、これは、一定量のスペースに対して定額ホスティングを備えた標準のMySQLデータベースと言うよりも、理解するのが明らかに曖昧でした。 利点は、Faunaが、独自の価格設定スキームをまとめるために使用できる優れた計算機を提供することです。
サーバーレスのもう1つの難しい側面は、これらのプロバイダーの多くが、ホストされている各アプリケーションの簡単な内訳を許可していないことです。 たとえば、Herokuプラットフォームでは、新しいパイプラインとチームを作成することで、これを非常に簡単にしています。 クライアントが私たちのホスティングプランを使用したくない場合に備えて、クライアントのクレジットカードを入力することもできます。 これはすべて同じダッシュボード内で実行できるため、複数のログインを作成する必要はありませんでした。
他のサーバーレスツールに関しては、これははるかに困難でした。 サーバーレスデータベースの評価において、Firebaseはプロジェクトごとの支払いの分割をサポートしています。 FaunaまたはDynamoDBの場合、これは不可能であるため、ダッシュボードで使用状況を監視するためにいくつかの作業を行う必要があります。クライアントがサービスを終了したい場合は、データベースを自分のアカウントに転送する必要があります。
最終的に、サーバーレスツールは、コスト削減、管理、およびプロセス効率の点で優れたビジネスチャンスを提供します。 ただし、価格設定とアカウント管理に関しては、多くの場合、代理店にとっては困難であることがわかります。 これは、コスト計算ツールを活用して独自の予測可能な価格帯を作成するか、クライアントが直接支払いを行えるように独自のアカウントを設定する必要があった領域の1つです。
結論
新しいテクノロジーを代理店として採用するのは難しい作業になる可能性があります。 私たちは、新しいテクノロジーの機会がある新しいグリーンフィールドプロジェクトに取り組むというユニークな立場にありますが、これらの長期的な投資も考慮する必要があります。 彼らはどのように機能しますか? 私たちの人々は生産的であり、それらを使用することを楽しんでいますか? それらをビジネスオファリングに組み込むことはできますか?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
参考文献
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience