
社内で中央ログサービスを構築する
公開: 2022-03-10アプリケーションのパフォーマンスと機能を向上させるためにデバッグがいかに重要であるかは誰もが知っています。 BrowserStackは、高度に分散されたアプリケーションスタックで1日に100万セッションを実行します。 クライアントの単一セッションは複数の地理的地域にまたがる複数のコンポーネントにまたがることができるため、それぞれにいくつかの可動部分が含まれます。
適切なフレームワークとツールがないと、デバッグプロセスは悪夢になる可能性があります。 私たちの場合、セッション中に発生するすべてのことを深く理解するために、各プロセスのさまざまな段階で発生するイベントを収集する方法が必要でした。 私たちのインフラストラクチャでは、各コンポーネントにリクエストの処理のライフサイクルから複数のイベントが発生する可能性があるため、この問題の解決は複雑になりました。
そのため、セッション中にログに記録されたすべての重要なイベントを記録するために、独自の中央ログサービスツール(CLS)を開発しました。 これらのイベントは、開発者がセッションで問題が発生した状態を特定するのに役立ち、特定の主要な製品メトリックを追跡するのに役立ちます。
データのデバッグは、API応答の待ち時間などの単純なものから、ユーザーのネットワークの状態の監視まで多岐にわたります。 この記事では、100以上のコンポーネントから1日あたり70Gの関連する時系列データを大規模かつ2つのM3.largeEC2インスタンスで確実に収集するCLSツールを構築するストーリーを共有します。
社内で構築するという決定
まず、既存のソリューションを使用するのではなく、CLSツールを社内で構築した理由を考えてみましょう。 各セッションは、複数のコンポーネントからサービスに平均15のイベントを送信します。これは、1日あたり合計約1,500万のイベントに相当します。
私たちのサービスには、このすべてのデータを保存する機能が必要でした。 イベントの保存、送信、およびイベント間でのクエリをサポートするための完全なソリューションを探しました。 AmplitudeやKeenなどのサードパーティソリューションを検討したとき、評価指標には、コスト、高度な並列要求の処理におけるパフォーマンス、および採用の容易さが含まれていました。 残念ながら、予算内ですべての要件を満たす適合を見つけることができませんでしたが、時間の節約とアラートの最小化などのメリットがありました。 追加の作業が必要になりますが、社内ソリューションを自社で開発することにしました。

技術的な詳細
コンポーネントの設計に関して、次の基本的な要件の概要を説明しました。
- クライアントのパフォーマンス
イベントを送信するクライアント/コンポーネントのパフォーマンスには影響しません。 - 規模
多数のリクエストを並行して処理できます。 - サービスパフォーマンス
送信されるすべてのイベントをすばやく処理します。 - データへの洞察
ログに記録される各イベントには、コンポーネントまたはユーザー、アカウントまたはメッセージを一意に識別し、開発者がより高速にデバッグできるように、より多くの情報を提供できるようにするためのメタ情報が必要です。 - クエリ可能なインターフェイス
開発者は、特定のセッションのすべてのイベントを照会して、特定のセッションのデバッグ、コンポーネントヘルスレポートの作成、またはシステムの意味のあるパフォーマンス統計の生成を支援できます。 - より速く、より簡単な採用
チームに負担をかけたり、リソースを消費したりすることなく、既存または新規のコンポーネントと簡単に統合できます。 - 低メンテナンス
私たちは小さなエンジニアリングチームなので、アラートを最小限に抑えるソリューションを探しました。
CLSソリューションの構築
決定1:公開するインターフェースの選択
CLSの開発では、明らかにデータを失いたくありませんでしたが、コンポーネントのパフォーマンスにも影響を与えたくありませんでした。 全体的な採用とリリースを遅らせるため、既存のコンポーネントがより複雑になるのを防ぐ追加の要因は言うまでもありません。 インターフェイスを決定する際に、次の選択肢を検討しました。
- バックグラウンドプロセッサがイベントをCLSにプッシュするときに、各コンポーネントのローカルRedisにイベントを保存します。 ただし、これには、まだ含まれていないコンポーネントにRedisを導入するとともに、すべてのコンポーネントを変更する必要があります。
- パブリッシャー-サブスクライバーモデル。RedisはCLSに近いです。 誰もがイベントを公開しているので、ここでもコンポーネントが世界中で実行されているという要素があります。 トラフィックが多い時間帯は、コンポーネントが遅延します。 さらに、この書き込みは断続的に最大5秒までジャンプする可能性があります(インターネットのみが原因)。
- UDPを介してイベントを送信します。これにより、アプリケーションのパフォーマンスへの影響が少なくなります。 この場合、データは送信されて忘れられますが、ここでの欠点はデータの損失です。
興味深いことに、UDPでのデータ損失は0.1%未満でした。これは、このようなサービスの構築を検討する上で許容できる量でした。 この量の損失はパフォーマンスに見合う価値があることをすべてのチームに納得させることができ、送信されるすべてのイベントをリッスンするUDPインターフェイスを活用することができました。
1つの結果はアプリケーションのパフォーマンスへの影響が小さかったものの、UDPトラフィックがすべてのネットワーク、主にユーザーから許可されなかったため、問題が発生しました。場合によっては、データをまったく受信できませんでした。 回避策として、HTTPリクエストを使用したイベントのログ記録をサポートしました。 ユーザー側からのすべてのイベントはHTTP経由で送信されますが、コンポーネントから記録されるすべてのイベントはUDP経由で送信されます。
決定2:技術スタック(言語、フレームワーク、ストレージ)
私たちはルビーショップです。 ただし、特定の問題に対してRubyがより適切な選択であるかどうかはわかりませんでした。 私たちのサービスは、多くの着信要求を処理するだけでなく、多くの書き込みを処理する必要があります。 グローバルインタプリタロックを使用すると、Rubyでマルチスレッドまたは同時実行を実現するのは困難になります(不快感を与えないでください。Rubyが大好きです!)。 そのため、この種の並行性を実現するのに役立つソリューションが必要でした。
また、技術スタックで新しい言語を評価することにも熱心でした。このプロジェクトは、新しいことを試すのに最適なようでした。 並行性と軽量スレッドおよびゴールーチンの組み込みサポートを提供していたので、Golangを試してみることにしました。 ログに記録された各データポイントは、キーと値のペアに似ています。ここで、「key」はイベントであり、「value」は関連する値として機能します。

しかし、単純なキーと値を持っているだけでは、セッション関連のデータを取得するのに十分ではありません-それにはより多くのメタデータがあります。 これに対処するために、ログに記録する必要のあるイベントには、そのキーと値とともにセッションIDが必要であると判断しました。 また、タイムスタンプ、ユーザーID、データをログに記録するコンポーネントなどのフィールドを追加して、データの取得と分析をより簡単にしました。
ペイロード構造を決定したので、データストアを選択する必要がありました。 Elastic Searchを検討しましたが、キーの更新リクエストもサポートしたいと考えていました。 これにより、ドキュメント全体のインデックスが再作成され、書き込みのパフォーマンスに影響を与える可能性があります。 追加されるデータフィールドのいずれかに基づいてすべてのイベントをクエリする方が簡単なため、MongoDBはデータストアとしてより理にかなっています。 これは簡単でした!
決定3:DBのサイズは巨大であり、クエリとアーカイブはうまくいきません!
メンテナンスを削減するために、私たちのサービスはできるだけ多くのイベントを処理する必要があります。 BrowserStackが機能と製品をリリースする速度を考えると、イベントの数は時間の経過とともにより高い速度で増加することを確信していました。つまり、サービスは引き続き良好に機能する必要があります。 スペースが増えると、読み取りと書き込みに時間がかかります。これは、サービスのパフォーマンスに大きな打撃を与える可能性があります。
私たちが調査した最初の解決策は、特定の期間のログをデータベースから移動することでした(この場合、15日に決定しました)。 これを行うために、毎日異なるデータベースを作成し、すべての書き込まれたドキュメントをスキャンしなくても、特定の期間より古いログを見つけることができるようにしました。 現在、Mongoから15日以上経過したデータベースを継続的に削除していますが、万が一の場合に備えてバックアップを保持しています。
残ったのは、セッション関連のデータを照会するための開発者インターフェースだけでした。 正直なところ、これは解決するのが最も簡単な問題でした。 特定のセッションIDを持つデータについて、MongoDBの対応するデータベースでセッション関連のイベントをクエリできるHTTPインターフェイスを提供します。
建築
次の点を考慮して、サービスの内部コンポーネントについて説明しましょう。
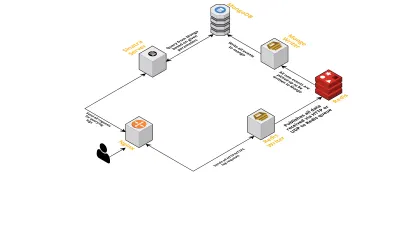
- 前に説明したように、2つのインターフェイスが必要でした。1つはUDPでリッスンし、もう1つはHTTPでリッスンします。 そこで、イベントをリッスンするために、インターフェイスごとに1つずつ、合計2つのサーバーを構築しました。 イベントが到着するとすぐに、イベントを解析して、必要なフィールド(セッションID、キー、および値)があるかどうかを確認します。 そうでない場合、データはドロップされます。 それ以外の場合、データはGoチャネルを介して別のゴルーチンに渡されます。別のゴルーチンの唯一の責任はMongoDBへの書き込みです。
- ここで考えられる懸念は、MongoDBへの書き込みです。 MongoDBへの書き込みが、データの受信速度よりも遅い場合、ボトルネックが発生します。 これにより、他の着信イベントが不足し、データがドロップされることを意味します。 したがって、サーバーは受信ログの処理が高速で、次のログを処理する準備ができている必要があります。 この問題に対処するために、サーバーを2つの部分に分割します。1つ目はすべてのイベントを受信し、2つ目はそれらをキューに入れ、MongoDBに処理して書き込みます。
- キューイングにはRedisを選択しました。 コンポーネント全体をこれらの2つの部分に分割することで、サーバーのワークロードを削減し、より多くのログを処理できるようにしました。
- Sinatraサーバーを使用して、指定されたパラメーターを使用してMongoDBにクエリを実行するすべての作業を処理する小さなサービスを作成しました。 開発者が特定のセッションに関する情報を必要とする場合、開発者にHTML / JSON応答を返します。
これらのプロセスはすべて、単一のm3.largeインスタンスで問題なく実行されます。
機能リクエスト
私たちのCLSツールは時間の経過とともに使用されるようになったため、より多くの機能が必要になりました。 以下では、これらとそれらがどのように追加されたかについて説明します。
メタデータがありません
BrowserStackのコンポーネントの数が増えるにつれて、CLSにさらに多くのコンポーネントを要求するようになりました。 たとえば、セッションIDがないコンポーネントからのイベントをログに記録する機能が必要でした。 そうしないと、アプリケーションのパフォーマンスに影響を与えたり、メインサーバーでトラフィックが発生したりするという形で、インフラストラクチャに負担がかかります。
これには、端末IDやユーザーIDなどの他のキーを使用してイベントログを有効にすることで対処しました。 これで、セッションが作成または更新されるたびに、CLSにセッションIDと、それぞれのユーザーIDおよび端末IDが通知されます。 MongoDBへの書き込みプロセスで取得できるマップを格納します。 ユーザーIDまたは端末IDのいずれかを含むイベントが取得されるたびに、セッションIDが追加されます。
スパムの処理(他のコンポーネントのコードの問題)
CLSは、スパムイベントの処理に関する通常の問題にも直面していました。 多くの場合、CLSに送信される大量のリクエストを生成するコンポーネントにデプロイが見つかりました。 サーバーがビジー状態になり、これらのログを処理できなくなり、重要なログが削除されたため、他のログは処理中に影響を受けます。
ほとんどの場合、ログに記録されるデータのほとんどはHTTPリクエストを介したものでした。 それらを制御するために、nginxでレート制限を有効にします(limit_req_zoneモジュールを使用)。これにより、短時間で特定の数を超えるリクエストにヒットすることがわかったIPからのリクエストがブロックされます。 もちろん、ブロックされたすべてのIPのヘルスレポートを活用し、責任のあるチームに通知します。
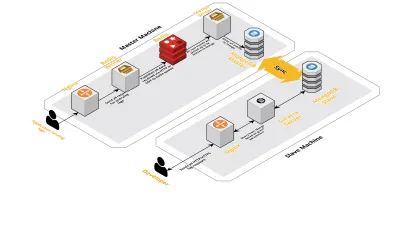
スケールv2
1日あたりのセッション数が増えると、CLSに記録されるデータも増えていきました。 これは、開発者が毎日実行しているクエリに影響を与え、すぐに私たちが抱えていたボトルネックはマシン自体にありました。 私たちのセットアップは、上記のすべてのコンポーネントを実行する2つのコアマシンと、Mongoにクエリを実行し、各製品の主要なメトリックを追跡するための一連のスクリプトで構成されていました。 時間の経過とともに、マシン上のデータが大幅に増加し、スクリプトに多くのCPU時間がかかり始めました。 Mongoクエリを最適化しようとした後でも、常に同じ問題が発生しました。
これを解決するために、ヘルスレポートスクリプトを実行するための別のマシンと、これらのセッションをクエリするためのインターフェイスを追加しました。 このプロセスでは、新しいマシンを起動し、メインマシンで実行されているMongoのスレーブをセットアップしました。 これにより、これらのスクリプトによって毎日見られるCPUスパイクを減らすことができました。
結論
データの量が増えると、データロギングのように単純なタスクのサービスを構築することは複雑になる可能性があります。 この記事では、この問題を解決する際に直面する課題とともに、調査したソリューションについて説明します。 Golangを試して、エコシステムにどれだけ適合するかを確認しました。これまでのところ、満足しています。 外部サービスにお金を払うのではなく、内部サービスを作成するという私たちの選択は、驚くほど費用対効果が高くなっています。 また、セッションの量が増えるまで、セットアップを別のマシンにスケーリングする必要はありませんでした。 もちろん、CLSの開発における私たちの選択は、私たちの要件と優先順位に完全に基づいていました。
現在、CLSは毎日最大1500万のイベントを処理し、最大70GBのデータを構成しています。 このデータは、お客様がセッション中に直面する問題を解決するために使用されています。 このデータは他の目的にも使用します。 各セッションのデータがさまざまな製品や内部コンポーネントについて提供する洞察を踏まえ、このデータを活用して各製品を追跡し始めました。 これは、すべての重要なコンポーネントの主要なメトリックを抽出することによって実現されます。
全体として、独自のCLSツールの構築に大きな成功を収めています。 それがあなたにとって理にかなっているなら、私はあなたが同じことをすることを検討することをお勧めします!