
Node.jsを使用してAmazon製品スクレーパーを構築する方法
公開: 2022-03-10特定の製品の市場を詳しく知る必要がある立場にあったことはありますか? たぶん、あなたはいくつかのソフトウェアを立ち上げていて、それを価格設定する方法を知る必要があります。 または、すでに市場に独自の製品があり、競争上の優位性のために追加する機能を確認したい場合もあります。 あるいは、自分のために何かを購入して、自分の支出に見合う最高の価値を確実に手に入れたいと思うかもしれません。
これらすべての状況には共通点が1つあります。それは、正しい判断を下すために正確なデータが必要であるということです。 実際、彼らが共有する別のことがあります。 すべてのシナリオで、Webスクレイパーを使用することでメリットを得ることができます。
Webスクレイピングは、ソフトウェアを使用して大量のWebデータを抽出する方法です。 つまり、本質的には、「コピー」を押してから「貼り付け」を200回押すという面倒なプロセスを自動化する方法です。 もちろん、ボットはこの文を読むのにかかった時間内にそれを行うことができるので、退屈ではないだけでなく、はるかに高速です。
しかし、非常に難しい質問は、なぜ誰かがAmazonページをこすりたいのかということです。
あなたはこれから調べようとしています! しかし、まず第一に、私は今何かを明確にしたいと思います—公開されているデータをスクレイピングする行為は合法ですが、Amazonは彼らのページでそれを防ぐためのいくつかの対策を講じています。 そのため、スクレイピング中は常にWebサイトに注意し、損傷しないように注意し、倫理的なガイドラインに従うことをお勧めします。
推奨読書: AndreasAltheimerによる「Node.jsとPuppeteerを使用した動的Webサイトの倫理的スクレイピングガイド」
Amazon製品データを抽出する必要がある理由
地球上で最大のオンライン小売業者であるため、何かを購入したい場合は、おそらくAmazonで入手できると言っても過言ではありません。 ですから、言うまでもなく、ウェブサイトのデータの宝物の大きさは言うまでもありません。
Webをスクレイピングするときの主な質問は、そのすべてのデータをどうするかということです。 個々の理由はたくさんありますが、それは2つの顕著なユースケースに要約されます。それは、製品の最適化と最良の取引の発見です。
「「
最初のシナリオから始めましょう。 真に革新的な新製品を設計していない限り、Amazonで少なくとも類似したものをすでに見つけることができる可能性があります。 これらの製品ページをスクレイピングすると、次のような貴重なデータが得られる可能性があります。
- 競合他社の価格戦略
そのため、価格を調整して競争力を高め、他の人がプロモーション取引をどのように処理するかを理解できます。 - お客様のご意見
あなたの将来のクライアントベースが最も気にかけていることと彼らの経験を改善する方法を見るために; - 最も一般的な機能
どの機能が重要で、どれを後で残すことができるかを知るために、競合他社が何を提供しているかを確認します。
本質的に、Amazonには、市場と製品の詳細な分析に必要なものがすべて揃っています。 そのデータを使用して製品ラインナップを設計、立ち上げ、拡張する準備が整います。
2番目のシナリオは、企業と一般の人々の両方に適用できます。 考え方は、前に述べたものと非常によく似ています。 選択できるすべての製品の価格、機能、およびレビューをスクレイプできるため、最低価格で最大のメリットを提供する製品を選択できます。 結局のところ、誰が大したことを好きではないのですか?
すべての製品がこのレベルの細部への注意に値するわけではありませんが、高価な購入で大きな違いを生む可能性があります。 残念ながら、メリットは明らかですが、Amazonをスクレイピングすることには多くの困難が伴います。
Amazon製品データをスクレイピングする際の課題
すべてのウェブサイトが同じというわけではありません。 経験則として、Webサイトが複雑で広まっているほど、Webサイトをスクレイプするのは難しくなります。 アマゾンが最も有名なeコマースサイトだと言ったのを覚えていますか? まあ、それはそれを非常に人気があり、かなり複雑にします。
まず、Amazonはスクレイピングボットがどのように機能するかを知っているため、Webサイトには対策が講じられています。 つまり、スクレーパーが予測可能なパターンに従い、一定の間隔で、人間よりも速く、またはほぼ同じパラメーターでリクエストを送信する場合、AmazonはIPに気づき、ブロックします。 プロキシはこの問題を解決できますが、例ではあまり多くのページをスクレイピングしないので、プロキシは必要ありませんでした。
次に、Amazonは製品にさまざまなページ構造を意図的に使用しています。 つまり、さまざまな製品のページを調べると、それらの構造と属性に大きな違いが見つかる可能性が高くなります。 この背後にある理由は非常に単純です。 スクレーパーのコードを特定のシステムに適合させる必要があり、新しい種類のページで同じスクリプトを使用する場合は、その一部を書き直す必要があります。 つまり、それらは本質的にあなたがデータのためにより多くの仕事をするようにしています。
最後に、Amazonは広大なウェブサイトです。 大量のデータを収集したい場合は、コンピューターでスクレイピングソフトウェアを実行すると、ニーズに時間がかかりすぎることがあります。 この問題は、速すぎるとスクレーパーがブロックされるという事実によってさらに強化されます。 したがって、大量のデータをすばやく必要とする場合は、真に強力なスクレーパーが必要になります。
さて、それは問題についての十分な話です、解決策に焦点を合わせましょう!
アマゾンのためのウェブスクレイパーを構築する方法
物事を単純にするために、コードを書くための段階的なアプローチを取ります。 ガイドと並行して自由に作業してください。
必要なデータを探す
それで、ここにシナリオがあります:私は数ヶ月で新しい場所に引っ越します、そして私は本と雑誌を保持するためにいくつかの新しい棚が必要になるでしょう。 私は自分のすべての選択肢を知り、できる限り良い取引をしたいと思っています。 それでは、Amazonマーケットに行き、「棚」を検索して、何が得られるかを見てみましょう。
この検索のURLとスクレイピングするページはこちらです。
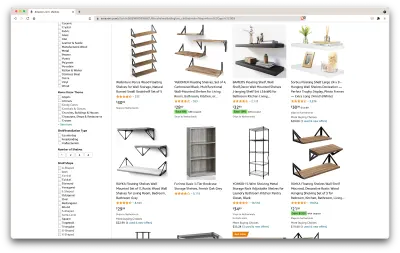
さて、ここにあるものを見てみましょう。 ページを一瞥するだけで、次のことについての良い画像を得ることができます。
- 棚がどのように見えるか。
- パッケージに含まれるもの;
- 顧客がそれらをどのように評価するか。
- 彼らの価格;
- 製品へのリンク。
- いくつかのアイテムのより安価な代替品の提案。
それは私たちが求めることができる以上のものです!
必要なツールを入手する
次の手順に進む前に、次のすべてのツールがインストールおよび構成されていることを確認しましょう。
- クロム
こちらからダウンロードできます。 - VSCode
このページの指示に従って、特定のデバイスにインストールしてください。 - Node.js
AxiosまたはCheerioの使用を開始する前に、Node.jsとNodePackageManagerをインストールする必要があります。 Node.jsとNPMをインストールする最も簡単な方法は、Node.Jsの公式ソースからインストーラーの1つを取得して実行することです。
それでは、新しいNPMプロジェクトを作成しましょう。 プロジェクト用の新しいフォルダーを作成し、次のコマンドを実行します。
npm init -yWebスクレイパーを作成するには、プロジェクトにいくつかの依存関係をインストールする必要があります。
- Cheerio
マークアップを解析し、結果のデータを操作するためのAPIを提供することで、有用な情報を抽出するのに役立つオープンソースライブラリ。 Cheerioでは、セレクター$("div")を使用してHTMLドキュメントのタグを選択できます。 この特定のセレクターは、ページ上のすべての<div>要素を選択するのに役立ちます。 Cheerioをインストールするには、プロジェクトのフォルダーで次のコマンドを実行してください。
npm install cheerio- アクシオス
Node.jsからHTTPリクエストを行うために使用されるJavaScriptライブラリ。
npm install axiosページソースを調べる
次の手順では、ページ上で情報がどのように編成されているかについて詳しく学習します。 アイデアは、ソースから何を取得できるかをよりよく理解することです。
開発者ツールは、Webサイトのドキュメントオブジェクトモデル(DOM)をインタラクティブに探索するのに役立ちます。 Chromeの開発者ツールを使用しますが、使い慣れた任意のWebブラウザーを使用できます。
ページの任意の場所を右クリックして[検査]オプションを選択して開きます。
これにより、ページのソースコードを含む新しいウィンドウが開きます。 前に述べたように、私たちはすべての棚の情報をこすり落とそうとしています。
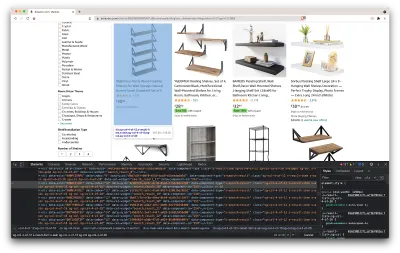
上のスクリーンショットからわかるように、すべてのデータを保持するコンテナーには次のクラスがあります。
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20次のステップでは、Cheerioを使用して、必要なデータを含むすべての要素を選択します。
データを取得する
上記のすべての依存関係をインストールしたら、新しいindex.jsファイルを作成して、次のコード行を入力します。
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); ご覧のとおり、最初の2行に必要な依存関係をインポートしてから、Cheerioを使用して、ページから製品の情報を含むすべての要素を取得するfetchShelves()関数を作成します。

それぞれを繰り返し処理し、空の配列にプッシュして、より適切な形式の結果を取得します。
fetchShelves()関数は現時点では商品のタイトルのみを返すので、必要な残りの情報を取得しましょう。 変数titleを定義した行の後に、次のコード行を追加してください。
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } そして、 shelves.push(title)をshelves.push(element)に置き換えます。
現在、必要なすべての情報を選択し、それをelementという新しいオブジェクトに追加しています。 次に、すべての要素がshelves配列にプッシュされ、探しているデータのみを含むオブジェクトのリストが取得されます。
リストに追加する前のshelfオブジェクトは次のようになります。
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }データをフォーマットする
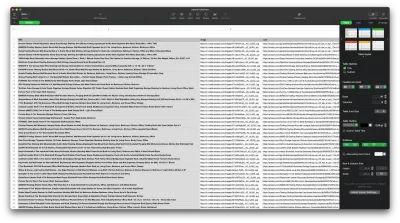
必要なデータを取得できたので、読みやすさを向上させるために、データを.CSVファイルとして保存することをお勧めします。 すべてのデータを取得したら、Node.jsが提供するfsモジュールを使用して、 saved-shelves.csvという新しいファイルをプロジェクトのフォルダーに保存します。 ファイルの先頭にあるfsモジュールをインポートし、次のコード行に沿ってコピーまたは書き込みます。
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) ご覧のとおり、最初の3行で、コンマを使用してシェルフオブジェクトのすべての値を結合することにより、以前に収集したデータをフォーマットします。 次に、 fsモジュールを使用して、 saved-shelves.csvというファイルを作成し、列ヘッダーを含む新しい行を追加し、フォーマットしたばかりのデータを追加して、エラーを処理するコールバック関数を作成します。
結果は次のようになります。
ボーナスのヒント!
シングルページアプリケーションのスクレイピング
Webサイトがこれまでになく複雑になっているため、動的コンテンツが標準になりつつあります。 可能な限り最高のユーザーエクスペリエンスを提供するには、開発者は動的コンテンツにさまざまな読み込みメカニズムを採用する必要があり、作業が少し複雑になります。 それが何を意味するのかわからない場合は、グラフィカルユーザーインターフェイスがないブラウザを想像してみてください。 幸いなことに、Puppeteerがあります。これは、DevToolsプロトコルを介してChromeインスタンスを制御するための高レベルのAPIを提供する魔法のノードライブラリです。 それでも、ブラウザと同じ機能を提供しますが、数行のコードを入力してプログラムで制御する必要があります。 それがどのように機能するか見てみましょう。
以前に作成したプロジェクトで、 npm install puppeteerを実行してPuppeteerライブラリをインストールし、新しいpuppeteer.jsファイルを作成して、次のコード行に沿ってコピーまたは書き込みます。
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() 上記の例では、Chromeインスタンスを作成し、このリンクに移動するために必要な新しいブラウザページを開きます。 次の行では、クラスrpBJOHq2PR60pnwJlUyP0の要素がページに表示されるまで待機するようにヘッドレスブラウザに指示しています。 また、ブラウザがページの読み込みを待機する時間(2000ミリ秒)も指定しました。
page変数のevaluateメソッドを使用して、要素が最終的に読み込まれた直後に、ページのコンテキスト内でJavascriptスニペットを実行するようにPuppeteerに指示しました。 これにより、ページのHTMLコンテンツにアクセスし、ページの本文を出力として返すことができます。 次に、 chrome変数のcloseメソッドを呼び出してChromeインスタンスを閉じます。 結果として得られる作業は、動的に生成されたすべてのHTMLコードで構成されている必要があります。 これが、PuppeteerがダイナミックHTMLコンテンツのロードに役立つ方法です。
Puppeteerの使用に不安がある場合は、NightwatchJS、NightmareJS、CasperJSなどの代替手段がいくつかあることに注意してください。 それらはわずかに異なりますが、最終的にはプロセスはかなり似ています。
user-agent設定
user-agentは、アクセスしているWebサイト、つまりブラウザーとOSを通知する要求ヘッダーです。 これは、セットアップのコンテンツを最適化するために使用されますが、Webサイトは、IPSを変更した場合でも、大量のリクエストを送信するボットを識別するためにも使用します。
user-agentヘッダーは次のようになります。
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36検出およびブロックされないようにするために、このヘッダーを定期的に変更する必要があります。 空のヘッダーや古いヘッダーを送信しないように特に注意してください。これは、一般ユーザーには決して発生しないため、目立つようになります。
レート制限
Webスクレイパーはコンテンツを非常に高速に収集できますが、最高速度で実行することは避けてください。 これには2つの理由があります。
- 短い順序でリクエストが多すぎると、Webサイトのサーバーの速度が低下したり、サーバーがダウンしたりして、所有者や他の訪問者に問題が発生する可能性があります。 本質的にはDoS攻撃になる可能性があります。
- プロキシをローテーションしない場合、人間が1秒間に数百または数千のリクエストを送信することはないため、ボットを使用していることを大声でアナウンスすることに似ています。
解決策は、リクエスト間に遅延を導入することです。これは「レート制限」と呼ばれる手法です。 (実装も非常に簡単です! )
上記のPuppeteerの例では、 body変数を作成する前に、Puppeteerが提供するwaitForTimeoutメソッドを使用して、別のリクエストを行う前に数秒待つことができます。
await page.waitForTimeout(3000); ここで、 msは待機する秒数です。
また、axiosの例で同じthigを実行する場合は、 setTimeout()メソッドを呼び出すpromiseを作成して、目的のミリ秒数を待機できるようにすることができます。
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))このようにして、ターゲットサーバーに過度のプレッシャーをかけることを回避し、Webスクレイピングに対してより人間的なアプローチをもたらすことができます。
まとめ
これで、Amazon製品データ用の独自のWebスクレイパーを作成するためのステップバイステップガイドが完成しました。 ただし、これは1つの状況にすぎなかったことを忘れないでください。 別のWebサイトをスクレイプしたい場合は、意味のある結果を得るためにいくつかの調整を行う必要があります。
関連読書
それでも実際にウェブスクレイピングをもっと見たい場合は、ここにあなたのためのいくつかの有用な読み物があります:
- 「JavaScriptとNode.Jsを使用したWebスクレイピングの究極のガイド」RobertSfichi
- 「Puppeteerを使用した高度なNode.JSWebスクレイピング」、Gabriel Cioci
- 「PythonWebスクレイピング:スクレイパーを構築するための究極のガイド」、Raluca Penciuc