
FaunaDB、Netlify、11tyでブックマークアプリケーションを作成する
公開: 2022-03-10JAMstack(JavaScript、API、Markup)の革命が本格化しています。 静的サイトは、安全で、高速で、信頼性が高く、作業が楽しいものです。 JAMstackの中心には、データをフラットファイル(Markdown、YAML、JSON、HTMLなど)として保存する静的サイトジェネレーター(SSG)があります。 この方法でデータを管理することは、非常に複雑になる場合があります。 時々、まだデータベースが必要です。
そのことを念頭に置いて、静的サイトホストであるNetlifyとサーバーレスクラウドデータベースであるFaunaDBが連携して、両方のシステムの組み合わせを容易にしました。
なぜブックマークサイトなのか?
JAMstackは多くの専門的な用途に最適ですが、この一連のテクノロジーの私のお気に入りの側面の1つは、個人用ツールやプロジェクトへの参入障壁が低いことです。
私が思いつくことができるほとんどのアプリケーションのために市場にはたくさんの良い製品がありますが、どれも私のために正確に設定されることはありません。 コンテンツを完全に制御できるものはありません。 費用(金銭的または情報的)がなければ、誰も来ません。
そのことを念頭に置いて、JAMstackメソッドを使用して独自のミニサービスを作成できます。 この場合、私は毎日のテクノロジーの読書で出くわした興味深い記事を保存して公開するためのサイトを作成します。
Twitterで共有されている記事を読むのに多くの時間を費やしています。 気に入ったら「ハート」のアイコンを押します。 その後、数日以内に、新しいお気に入りの流入で見つけることはほぼ不可能です。 「心」の安らぎに近いものを作りたいのですが、それは私が所有し、コントロールしています。
どのようにそれを行うつもりですか? よろしくお願いします。
コードの取得に興味がありますか? Githubで取得するか、そのリポジトリからNetlifyに直接デプロイできます。 こちらで完成品をご覧ください。
私たちの技術
ホスティングおよびサーバーレス機能:Netlify
ホスティングおよびサーバーレス機能には、Netlifyを利用します。 追加のボーナスとして、上記の新しいコラボレーションにより、NetlifyのCLI(「NetlifyDev」)は自動的にFaunaDBに接続し、APIキーを環境変数として保存します。
データベース:FaunaDB
FaunaDBは「サーバーレス」のNoSQLデータベースです。 ブックマークデータを保存するために使用します。
静的サイトジェネレーター:11ty
私はHTMLを大いに信じています。 このため、チュートリアルではブックマークのレンダリングにフロントエンドJavaScriptを使用しません。 代わりに、静的サイトジェネレーターとして11tyを利用します。 11tyには、いくつかの短いJavaScript関数を作成するのと同じくらい簡単にAPIからデータをフェッチできるデータ機能が組み込まれています。
iOSのショートカット
データベースにデータを投稿する簡単な方法が必要です。 この場合、iOSのShortcutsアプリを使用します。 これは、AndroidまたはデスクトップのJavaScriptブックマークレットに変換することもできます。
NetlifyDevを介したFaunaDBのセットアップ
すでにFaunaDBにサインアップしている場合でも、新しいアカウントを作成する必要がある場合でも、FaunaDBとNetlifyの間にリンクを設定する最も簡単な方法は、NetlifyのCLIであるNetlifyDevを使用することです。 ここでFaunaDBからの完全な手順を見つけるか、以下に従ってください。
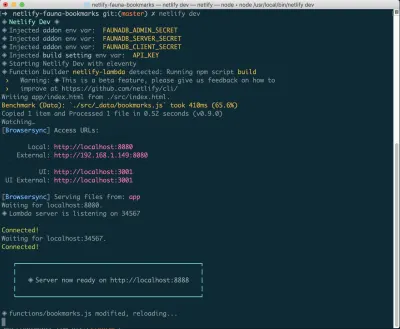
これをまだインストールしていない場合は、ターミナルで次のコマンドを実行できます。
npm install netlify-cli -gプロジェクトディレクトリ内から、次のコマンドを実行します。
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account これがすべて接続されたら、プロジェクトでnetlify devを実行できます。 これにより、設定したビルドスクリプトが実行されますが、NetlifyおよびFaunaDBサービスに接続し、必要な環境変数を取得します。 ハンディ!
最初のデータの作成
ここから、FaunaDBにログインして、最初のデータセットを作成します。 まず、「ブックマーク」と呼ばれる新しいデータベースを作成します。 データベース内には、コレクション、ドキュメント、インデックスがあります。
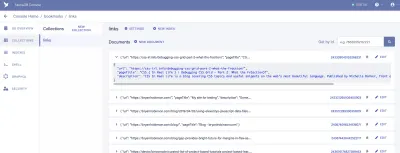
コレクションは、分類されたデータのグループです。 各データはドキュメントの形式を取ります。 Faunaのドキュメントによると、ドキュメントは「FaunaDBデータベース内の単一の変更可能なレコード」です。 コレクションは従来のデータベーステーブル、ドキュメントは行と考えることができます。
このアプリケーションでは、「リンク」と呼ばれる1つのコレクションが必要です。 「リンク」コレクション内の各ドキュメントは、3つのプロパティを持つ単純なJSONオブジェクトになります。 まず、最初のデータフェッチの構築に使用する新しいドキュメントを追加します。
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }これにより、ブックマークから取得する必要のある情報の基礎が作成され、テンプレートに取得する最初のデータセットが提供されます。
あなたが私のようなら、あなたはあなたの労働の成果をすぐに見たいと思うでしょう。 ページに何かを載せましょう!
11tyのインストールとテンプレートへのデータのプル
ブックマークをブラウザでフェッチせずにHTMLでレンダリングする必要があるため、レンダリングを行うために何かが必要になります。 それを行うには多くの素晴らしい方法がありますが、使いやすさとパワーのために、私は11ty静的サイトジェネレーターを使用するのが大好きです。
11tyはJavaScriptの静的サイトジェネレーターであるため、NPMを介してインストールできます。
npm install --save @11ty/eleventy そのインストールから、プロジェクトで11またはeleventy --serve eleventy実行して、起動して実行できます。
Netlify Devは、多くの場合、要件として11tyを検出し、コマンドを実行します。 これを機能させるために、そしてデプロイの準備ができていることを確認するために、 package.jsonに「serve」コマンドと「build」コマンドを作成することもできます。
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }11tyのデータファイル
ほとんどの静的サイトジェネレーターには、「データファイル」が組み込まれているという考えがあります。 通常、これらのファイルは、サイトに追加情報を追加できるJSONまたはYAMLファイルになります。
11tyでは、JSONデータファイルまたはJavaScriptデータファイルを使用できます。 JavaScriptファイルを利用することで、実際にAPI呼び出しを行い、データを直接テンプレートに返すことができます。
デフォルトでは、11tyはデータファイルを_dataディレクトリに保存することを望んでいます。 その後、テンプレートの変数としてファイル名を使用してデータにアクセスできます。 この例では、 _data/bookmarks.jsにファイルを作成し、 {{ bookmarks }}変数名を介してファイルにアクセスします。
データファイルの構成をさらに深く掘り下げたい場合は、11tyドキュメントの例を読むか、MeetupAPIでの11tyデータファイルの使用に関するこのチュートリアルを確認してください。
ファイルはJavaScriptモジュールになります。 したがって、何かを機能させるには、データまたは関数のいずれかをエクスポートする必要があります。 この例では、関数をエクスポートします。
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } それを分解しましょう。 ここで主な作業を行う関数は、 mapBookmarks()とgetBookmarks()の2つです。
getBookmarks()関数はFaunaDBデータベースからデータをフェッチし、 mapBookmarks()はブックマークの配列を取得して、テンプレートでより適切に機能するように再構築します。
getBookmarks()をさらに深く掘り下げてみましょう。
getBookmarks()
まず、FaunaDBJavaScriptドライバーのインスタンスをインストールして初期化する必要があります。
npm install --save faunadbインストールしたので、データファイルの先頭に追加しましょう。 このコードは、Faunaのドキュメントから直接引用したものです。
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); その後、関数を作成できます。 まず、ドライバーに組み込まれているメソッドを使用して最初のクエリを作成します。 この最初のコードは、ブックマークされたすべてのリンクの完全なデータを取得するために使用できるデータベース参照を返します。 11tyに渡す前にデータをページ付けすることにした場合にカーソルの状態を管理するヘルパーとして、 Paginateメソッドを使用します。 この場合、すべての参照を返すだけです。
この例では、Netlify DevCLIを介してFaunaDBをインストールして接続したことを前提としています。 このプロセスを使用して、FaunaDBシークレットのローカル環境変数を取得します。 この方法でインストールしなかった場合、またはプロジェクトでnetlify devを実行していない場合は、環境変数を作成するためにdotenvなどのパッケージが必要になります。 また、後でデプロイを機能させるために、環境変数をNetlifyサイト構成に追加する必要があります。
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })このコードは、すべてのリンクの配列を参照形式で返します。 これで、データベースに送信するクエリリストを作成できます。
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) ここから、返されたデータをクリーンアップする必要があります。 そこでmapBookmarks()が登場します!
mapBookmarks()
この関数では、データの2つの側面を扱います。
まず、FaunaDBで無料のdateTimeを取得します。 作成されたデータには、タイムスタンプ( ts )プロパティがあります。 Liquidのデフォルトの日付フィルターを満足させるような形式ではないので、修正しましょう。
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } これで、データ用の新しいオブジェクトを作成できます。 この場合、 timeプロパティがあり、Spread演算子を使用してdataオブジェクトを分解し、すべてを1つのレベルで実行できるようにします。
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }関数の前のデータは次のとおりです。
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }関数の後のデータは次のとおりです。
{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }これで、テンプレートの準備ができた、適切にフォーマットされたデータが得られました。

簡単なテンプレートを書いてみましょう。 ブックマークをループして、それぞれにpageTitleとurlがあることを検証して、ばかげているように見えないようにします。
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>現在、FaunaDBからデータを取り込んで表示しています。 少し時間を取って、これが純粋なHTMLをレンダリングし、クライアント側でデータをフェッチする必要がないことがどれほど素晴らしいかを考えてみましょう。
しかし、それだけでは、これを私たちにとって便利なアプリにするのに十分ではありません。 FaunaDBコンソールにブックマークを追加するよりも良い方法を考えてみましょう。
Netlify関数を入力してください
NetlifyのFunctionsアドオンは、AWSラムダ関数をデプロイするためのより簡単な方法の1つです。 設定手順がないため、コードを記述したいだけのDIYプロジェクトに最適です。
この関数は、次のようなプロジェクト内のURLに存在します: https://myproject.com/.netlify/functions/bookmarks ://myproject.com/.netlify/functions/bookmarks関数フォルダーに作成するファイルがbookmarks.jsであると仮定します。
基本的な流れ
- URLをクエリパラメータとして関数URLに渡します。
- この関数を使用してURLをロードし、可能な場合はページのタイトルと説明をスクレイプします。
- FaunaDBの詳細をフォーマットします。
- 詳細をFaunaDBコレクションにプッシュします。
- サイトを再構築します。
要件
これを構築するときに必要なパッケージがいくつかあります。 netlify-lambda CLIを使用して、関数をローカルでビルドします。 request-promiseは、リクエストを行うために使用するパッケージです。 Cheerio.jsは、リクエストされたページから特定のアイテムを取得するために使用するパッケージです(jQuery for Nodeを考えてみてください)。 そして最後に、FaunaDb(すでにインストールされているはずです)が必要になります。
npm install --save netlify-lambda request-promise cheerioそれがインストールされたら、ローカルで関数をビルドして提供するようにプロジェクトを構成しましょう。
package.jsonの「build」スクリプトと「serve」スクリプトを次のように変更します。
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } 警告: Netlifyの関数がビルドに使用するWebpackでコンパイルすると、FaunaのNodeJSドライバーにエラーが発生します。 これを回避するには、Webpackの構成ファイルを定義する必要があります。 次のコードを新しい(または既存の) webpack.config.jsに保存できます。
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; このファイルが存在するようになったら、 netlify-lambdaコマンドを使用するときに、この構成から実行するように指示する必要があります。 これが、「serve」および「buildスクリプトがそのコマンドに--config値を使用する理由です。
機能ハウスキーピング
メインの関数ファイルをできるだけクリーンに保つために、別のbookmarksディレクトリに関数を作成し、メインの関数ファイルにインポートします。
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
getDetails()関数は、エクスポートされたハンドラーから渡されたURLを受け取ります。 そこから、そのURLのサイトにアクセスし、ページの関連部分を取得して、ブックマークのデータとして保存します。
まず、必要なNPMパッケージを要求します。
const rp = require('request-promise'); const cheerio = require('cheerio'); 次に、 request-promiseモジュールを使用して、要求されたページのHTML文字列を返し、それをcheerioに渡して、非常にjQuery風のインターフェイスを提供します。
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }ここから、ページタイトルとメタ説明を取得する必要があります。 そのために、jQueryの場合と同じようにセレクターを使用します。
注:このコードでは、ページのタイトルを取得するためのセレクターとして'head > title'を使用しています。 これを指定しないと、ページ上のすべてのSVG内に<title>タグが含まれる可能性があり、これは理想的とは言えません。
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }データが手元にあるので、FaunaDBのコレクションにブックマークを送信します。
saveBookmark(details)
保存機能では、 getDetailsから取得した詳細とURLを単一のオブジェクトとして渡します。 Spreadオペレーターが再び攻撃します!
const savedResponse = await saveBookmark({url, ...details}); create.jsファイルでは、FaunaDBドライバーも要求してセットアップする必要があります。 これは、11tyデータファイルから非常によく知られているはずです。
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });それが邪魔にならないようになったら、コーディングできます。
まず、詳細を、Faunaがクエリに期待するデータ構造にフォーマットする必要があります。 動物相は、保存したいデータを含むデータプロパティを持つオブジェクトを期待しています。
const saveBookmark = async function(details) { const data = { data: details }; ... }次に、コレクションに追加する新しいクエリを開きます。 この場合、クエリヘルパーを使用し、Createメソッドを使用します。 Create()は2つの引数を取ります。 1つはデータを保存するコレクションで、もう1つはデータ自体です。
保存した後、成功または失敗のいずれかをハンドラーに返します。
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }完全な関数ファイルを見てみましょう。
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
目の肥えた目は、ハンドラーにインポートされたもう1つの関数rebuildSite()があることに気付くでしょう。 この関数は、NetlifyのDeploy Hook機能を使用して、新しい(成功した)ブックマーク保存を送信するたびに、新しいデータからサイトを再構築します。
Netlifyのサイトの設定で、ビルドとデプロイの設定にアクセスして、新しい「ビルドフック」を作成できます。 フックには、[デプロイ]セクションに表示される名前と、必要に応じてマスター以外のブランチをデプロイするためのオプションがあります。 この例では、「new_link」という名前を付けて、マスターブランチをデプロイします。
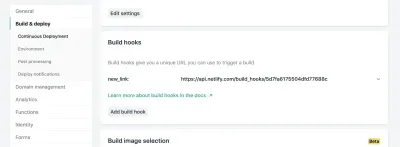
そこから、指定されたURLにPOSTリクエストを送信する必要があります。
リクエストを行う方法が必要です。すでにrequest-promiseをインストールしているので、ファイルの先頭にパッケージを要求することで、そのパッケージを引き続き使用します。
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } iOSショートカットの設定
そのため、データベース、データを表示する方法、データを追加する機能がありますが、それでもあまりユーザーフレンドリーではありません。
NetlifyはLambda関数のURLを提供しますが、モバイルデバイスに入力するのは面白くありません。 また、クエリパラメータとしてURLを渡す必要があります。 それはたくさんの努力です。 どうすればこれをできるだけ少なくすることができますか?
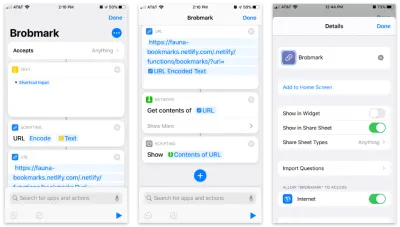
AppleのShortcutsアプリを使用すると、カスタムアイテムを作成して共有シートに入れることができます。 これらのショートカット内で、共有プロセスで収集されたデータのさまざまなタイプのリクエストを送信できます。
ステップバイステップのショートカットは次のとおりです。
- すべてのアイテムを受け入れ、そのアイテムを「テキスト」ブロックに保存します。
- そのテキストを「スクリプト」ブロックに渡してURLエンコードします(念のため)。
- その文字列を、Netlify関数のURLと
urlのクエリパラメータを使用してURLブロックに渡します。 - 「ネットワーク」から「コンテンツの取得」ブロックを使用して、URLにJSONにPOSTします。
- オプション:「スクリプト」から最後のステップの内容を「表示」します(送信するデータを確認するため)。
共有メニューからこれにアクセスするには、このショートカットの設定を開き、[共有シートに表示]オプションをオンにします。
iOS13以降、これらの共有「アクション」をお気に入りに追加して、ダイアログの高い位置に移動することができます。
これで、複数のプラットフォーム間でブックマークを共有するための機能する「アプリ」ができました。
期待された以上の仕事をする!
これを自分で試してみたいと思われる場合は、機能を追加する他の多くの可能性があります。 DIY Webの喜びは、これらの種類のアプリケーションを機能させることができることです。 ここにいくつかのアイデアがあります:
- 迅速な認証のために偽の「APIキー」を使用して、他のユーザーがあなたのサイトに投稿しないようにします(私はAPIキーを使用しているので、投稿しようとしないでください!)。
- ブックマークを整理するためのタグ機能を追加します。
- 他の人が購読できるように、サイトのRSSフィードを追加します。
- 追加したリンクについては、プログラムで毎週まとめのメールを送信します。
本当に空が限界なので、実験を始めましょう!