
実世界の例を使用したPythonでの二項分布[2022]
公開: 2021-01-09データサイエンスの分野における確率と統計の価値は計り知れず、人工知能と機械学習はそれらに大きく依存しています。 A / Bテストと投資モデリングを行うたびに、正規分布のプロセスモデルを使用しています。
ただし、 Pythonの二項分布は、複数のプロセスを実行するために複数の方法で適用されます。 ただし、 Pythonで二項分布を開始する前に、一般的な二項分布と日常生活でのその使用について知っておく必要があります。 初心者でデータサイエンスについて詳しく知りたい場合は、一流大学のデータサイエンストレーニングをご覧ください。
目次
二項分布とは何ですか?
コインを投げたことがありますか? 持っている場合は、頭または尾を取得する確率が等しいことを知っている必要があります。 しかし、コインの合計10回のフリップで7つのテールを取得する可能性はどうですか? これは、二項分布が各フリップの結果を計算するのに役立ち、したがって、コインの10回のフリップで7つのテールを取得する確率を見つけるのに役立ちます。
確率分布の核心は、あらゆるイベントの分散に由来します。 10枚のコイン投げセットごとに、表と裏が出る確率は1〜10倍の間で、同じように可能性が高くなります。 結果の不確実性(分散とも呼ばれます)は、生成された結果の分布を生成するのに役立ちます。
言い換えると、二項分布は、真または偽の2つの可能な結果のみが存在するプロセスです。 したがって、毎回同じアクションが実行されるため、すべてのイベントで両方の結果の確率が等しくなります。 条件は1つだけです…ステップは互いに完全に影響を受けないようにする必要があり、結果は同じように発生する場合と発生しない場合があります。
したがって、二項分布の確率関数は次のようになります。
f f( k k 、 n n、 p p) = P r Pr( k k; n n、 p p) = P r Pr( X X = k k) =
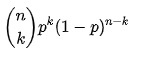
ソース
どこ、
![]() = n n! k k !( n n! -k k!)
= n n! k k !( n n! -k k!)
ここで、n=試行の総数
p=成功確率
k=成功の目標数
Pythonでの二項分布
Pythonを介した二項分布の場合、binom.rvs()関数から個別の確率変数を生成できます。ここで、「n」は試行の合計頻度として定義され、「p」は成功確率に等しくなります。
loc関数を使用して分布を移動することもできます。サイズは、一連のアクションで繰り返されるアクションの頻度を定義します。 random_stateを追加すると、再現性を維持するのに役立ちます。

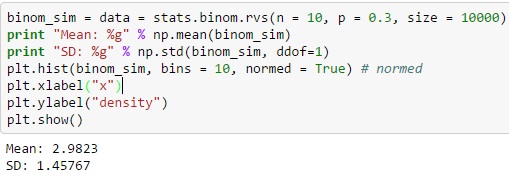
ソース
Pythonでの二項分布の実際の例
Pythonの二項分布で対処できるイベント(コイントスよりも大きい)は他にもたくさんあります。 いくつかのユースケースは、大企業と中小企業のROI(投資収益率)を追跡および改善するのに役立ちます。 方法は次のとおりです。
- 各従業員に平均して毎日50回の電話が割り当てられるコールセンターについて考えてみてください。
- 各呼び出しでのコンバージョンの確率は4%です。
- このような各変換に基づく会社の平均収益は、20米ドルです。
- 毎日200米ドルの支払いを受ける100人のそのような従業員を分析すると、
n = 50
p = 4%
コードは次のように出力を生成できます。
- 各従業員の平均コンバージョン率=2.13
- 各コールセンター担当者のコンバージョンの標準偏差=1.48
- 総変換=213
- 総収入=21,300米ドル
- 総経費=20,000米ドル
- 粗利益=1,300米ドル
二項分布モデルおよびその他の確率分布は、アクションパラメータ「n」および「p」に関して実世界に近づくことができる近似のみを予測できます。 これは、重点分野を理解して特定し、パフォーマンスと効果を向上させる全体的な可能性を高めるのに役立ちます。
また読む:初心者のための13の興味深いデータ構造プロジェクトのアイデアとトピック
次は何?
データサイエンスについて知りたい場合は、IIIT-B&upGradのデータサイエンスのエグゼクティブPGプログラムをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップを提供します。1業界のメンターとの1対1、400時間以上の学習、トップ企業との仕事の支援。
離散確率分布と連続確率分布の違いは何ですか?
離散確率分布または単純な離散分布は、離散する可能性のある確率変数の確率を計算します。 たとえば、コインを2回投げた場合、頭の総数を表す確率変数Xの推定値は{0、1、2}になり、ランダムな値にはなりません。 ベルヌーイ、二項、超幾何分布は、離散確率分布のいくつかの例です。 一方、連続確率分布は、任意の乱数にすることができるランダム値の確率を提供します。 たとえば、都市の市民の身長を表す確率変数Xの値は、161.2、150.9などの任意の数値にすることができます。通常、スチューデントのT、カイ2乗は、連続分布の例の一部です。
データサイエンスにおける確率の重要性は何ですか?
データサイエンスはデータの研究がすべてであるため、ここでは確率が重要な役割を果たします。 次の理由は、確率がデータサイエンスの不可欠な部分である方法を説明しています。これは、アナリストや研究者がデータセットから予測を行うのに役立ちます。 これらの種類の推定結果は、データをさらに分析するための基盤となります。 確率は、機械学習モデルで使用されるアルゴリズムを開発する際にも使用されます。 これは、モデルのトレーニングに使用されるデータセットの分析に役立ちます。 これにより、データを定量化し、導関数、平均、分布などの結果を導き出すことができます。 確率を使用して達成されたすべての結果は、最終的にデータを要約します。 この要約は、データセット内の既存の外れ値の識別にも役立ちます。
超幾何分布を説明します。 どのような場合、それは二項分布になる傾向がありますか?
置換なしの試行回数を超える成功。 赤と緑のボールでいっぱいのバッグがあり、5回の試行で緑のボールを選ぶ確率を見つける必要があるとしましょう。しかし、ボールを選ぶたびに、ボールをバッグに戻すことはありません。 これは、超幾何分布の適切な例です。
Nが大きい場合、超幾何分布を計算することは非常に困難ですが、Nが小さい場合、この場合は二項分布になる傾向があります。