
Flask、GoogleのCloud SQL、AppEngineを使用したAPIのセットアップ
公開: 2022-03-10いくつかのPythonフレームワークを使用してAPIを作成できますが、そのうちの2つはFlaskとDjangoです。 フレームワークには、ユーザーがアプリケーションと対話するために必要な機能を開発者が簡単に実装できるようにする機能が付属しています。 使用するフレームワークを選択するときは、Webアプリケーションの複雑さが決定的な要因になる可能性があります。
Django
Djangoは、機能が組み込まれた事前定義された構造を持つ堅牢なフレームワークです。 ただし、その堅牢性の欠点は、特定のプロジェクトではフレームワークが複雑になりすぎる可能性があることです。 Djangoの高度な機能を活用する必要がある複雑なWebアプリケーションに最適です。
フラスコ
一方、Flaskは、APIを構築するための軽量フレームワークです。 使い始めるのは簡単で、パッケージを利用して堅牢にすることができます。 この記事では、ビュー機能とコントローラーの定義、およびGoogleCloud上のデータベースへの接続とGoogleCloudへのデプロイに焦点を当てます。
学習の目的で、お気に入りの曲のコレクションを管理するためのいくつかのエンドポイントを備えたFlaskAPIを構築します。 エンドポイントは、 GETおよびPOSTリクエスト(リソースのフェッチと作成)用になります。 それに加えて、GoogleCloudプラットフォームで一連のサービスを使用します。 データベース用にGoogleのCloudSQLをセットアップし、AppEngineにデプロイしてアプリを起動します。 このチュートリアルは、アプリでGoogleCloudを初めて使用する初心者を対象としています。
Flaskプロジェクトの設定
このチュートリアルは、Python3.xがインストールされていることを前提としています。 そうでない場合は、公式Webサイトにアクセスして、ダウンロードしてインストールしてください。
Pythonがインストールされているかどうかを確認するには、コマンドラインインターフェイス(CLI)を起動し、次のコマンドを実行します。
python -V 最初のステップは、プロジェクトが存在するディレクトリを作成することです。 これをflask-appと呼びます:
mkdir flask-app && cd flask-appPythonプロジェクトを開始するときに最初に行うことは、仮想環境を作成することです。 仮想環境は、作業中のPython開発を分離します。 これは、このプロジェクトが、マシン上の他のプロジェクトとは異なる独自の依存関係を持つことができることを意味します。 venvは、Python3に同梱されているモジュールです。
flask-appディレクトリに仮想環境を作成しましょう。
python3 -m venv env このコマンドは、ディレクトリにenvフォルダを作成します。 名前(この場合はenv )は仮想環境のエイリアスであり、任意の名前を付けることができます。
仮想環境を作成したので、それを使用するようにプロジェクトに指示する必要があります。 仮想環境をアクティブ化するには、次のコマンドを使用します。
source env/bin/activate CLIプロンプトの先頭にenvが表示され、環境がアクティブであることを示します。

(env)はプロンプトの前に表示されます(大プレビュー)それでは、Flaskパッケージをインストールしましょう。
pip install flask 現在のディレクトリにapiという名前のディレクトリを作成します。 このディレクトリを作成して、アプリの他のフォルダーが存在するフォルダーを作成します。
mkdir api && cd api 次に、アプリへのエントリポイントとして機能するmain.pyファイルを作成します。
touch main.py main.pyを開き、次のコードを入力します。
#main.py from flask import Flask app = Flask(__name__) @app.route('/') def home(): return 'Hello World' if __name__ == '__main__': app.run() ここで何をしたかを理解しましょう。 最初にFlaskクラスをFlaskパッケージからインポートしました。 次に、クラスのインスタンスを作成し、それをappに割り当てました。 次に、アプリのルートを指す最初のエンドポイントを作成しました。 要約すると、これは/ routeを呼び出すビュー関数です— Hello Worldを返します。
アプリを実行してみましょう:
python main.py これにより、ローカルサーバーが起動し、 https://127.0.0.1:5000/でアプリが提供されます。 ブラウザにURLを入力すると、 Hello Worldの応答が画面に印刷されます。
そして出来上がり! 私たちのアプリは稼働しています。 次のタスクは、それを機能させることです。
エンドポイントを呼び出すために、開発者がエンドポイントをテストするのを支援するサービスであるPostmanを使用します。 公式サイトからダウンロードできます。
main.pyにいくつかのデータを返させましょう:
#main.py from flask import Flask, jsonify app = Flask(__name__) songs = [ { "title": "Rockstar", "artist": "Dababy", "genre": "rap", }, { "title": "Say So", "artist": "Doja Cat", "genre": "Hiphop", }, { "title": "Panini", "artist": "Lil Nas X", "genre": "Hiphop" } ] @app.route('/songs') def home(): return jsonify(songs) if __name__ == '__main__': app.run() ここには、曲のタイトルやアーティスト名など、曲のリストが含まれています。 次に、ルート/ルートを/songsに変更しました。 このルートは、指定した曲の配列を返します。 リストをJSON値として取得するために、 jsonifyを介してリストをJSON化しました。 これで、単純なHello worldではなく、 https://127.0.0.1:5000/songsエンドポイントにアクセスしたときにアーティストのリストが表示されます。
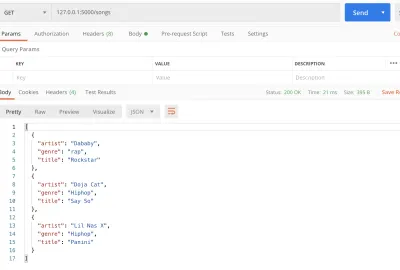
get (大プレビュー) 変更するたびに、サーバーを再起動する必要があることに気付いたかもしれません。 コードが変更されたときに自動リロードを有効にするには、デバッグオプションを有効にしましょう。 これを行うには、 app.runを次のように変更します。
app.run(debug=True) 次に、postリクエストを使用して配列に曲を追加しましょう。 まず、 requestオブジェクトをインポートして、ユーザーからの着信リクエストを処理できるようにします。 後でview関数のrequestオブジェクトを使用して、JSONでユーザーの入力を取得します。
#main.py from flask import Flask, jsonify, request app = Flask(__name__) songs = [ { "title": "Rockstar", "artist": "Dababy", "genre": "rap", }, { "title": "Say So", "artist": "Doja Cat", "genre": "Hiphop", }, { "title": "Panini", "artist": "Lil Nas X", "genre": "Hiphop" } ] @app.route('/songs') def home(): return jsonify(songs) @app.route('/songs', methods=['POST']) def add_songs(): song = request.get_json() songs.append(song) return jsonify(songs) if __name__ == '__main__': app.run(debug=True) add_songsビュー関数は、ユーザーが送信した曲を受け取り、それを既存の曲のリストに追加します。
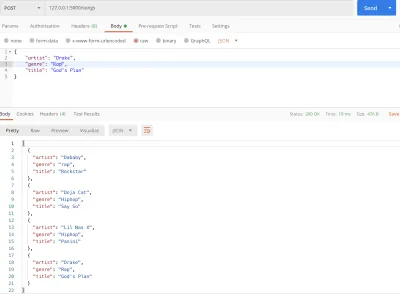
これまでのところ、Pythonリストからデータを返してきました。 より堅牢な環境では、サーバーを再起動すると、新しく追加されたデータが失われるため、これは単なる実験的なものです。 これは現実的ではないため、データを保存および取得するにはライブデータベースが必要になります。 クラウドSQLが登場します。
クラウドSQLインスタンスを使用する理由
公式サイトによると:
「GoogleCloudSQLは、クラウド内のリレーショナルMySQLおよびPostgreSQLデータベースのセットアップ、保守、管理、および管理を容易にするフルマネージドデータベースサービスです。 Google CloudPlatformでホストされるCloudSQLは、どこでも実行されるアプリケーションにデータベースインフラストラクチャを提供します。」
これは、柔軟な価格設定で、データベースのインフラストラクチャの管理を完全にGoogleにアウトソーシングできることを意味します。
クラウドSQLと自己管理型コンピューティングエンジンの違い
Google Cloudでは、GoogleのCompute Engineインフラストラクチャで仮想マシンを起動し、SQLインスタンスをインストールできます。 これは、垂直スケーラビリティ、レプリケーション、およびその他の構成のホストを担当することを意味します。 Cloud SQLを使用すると、すぐに使用できる多くの構成が得られるため、コードにより多くの時間を費やすことができ、セットアップにかかる時間を短縮できます。
始める前に:
- GoogleCloudにサインアップします。 Googleは、新規ユーザーに300ドルの無料クレジットを提供しています。
- プロジェクトを作成します。 これは非常に簡単で、コンソールから直接実行できます。
クラウドSQLインスタンスを作成する
Google Cloudにサインアップした後、左側のパネルで[SQL]タブまでスクロールしてクリックします。
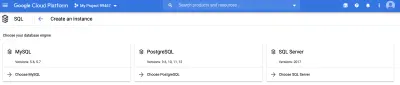
まず、SQLエンジンを選択する必要があります。 この記事ではMySQLを使用します。
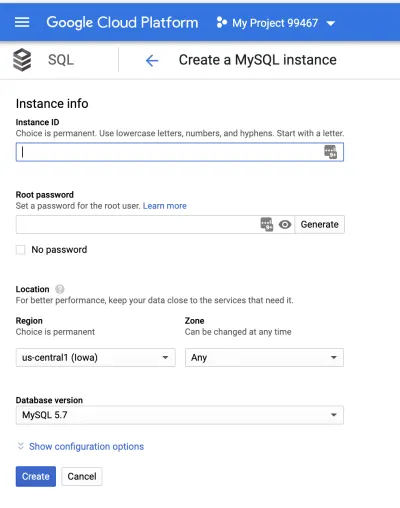
次に、インスタンスを作成します。 デフォルトでは、インスタンスは米国で作成され、ゾーンが自動的に選択されます。
ルートパスワードを設定し、インスタンスに名前を付けてから、「作成」ボタンをクリックします。 [構成オプションの表示]ドロップダウンをクリックして、インスタンスをさらに構成できます。 設定により、インスタンスのサイズ、ストレージ容量、セキュリティ、可用性、バックアップなどを構成できます。 この記事では、デフォルト設定を使用します。 心配しないでください。これらの変数は後で変更できます。
プロセスが完了するまでに数分かかる場合があります。 緑色のチェックマークが表示されると、インスタンスの準備ができていることがわかります。 インスタンスの名前をクリックして、詳細ページに移動します。
これで、稼働しているので、いくつかのことを行います。
- データベースを作成します。
- 新しいユーザーを作成します。
- IPアドレスをホワイトリストに登録します。
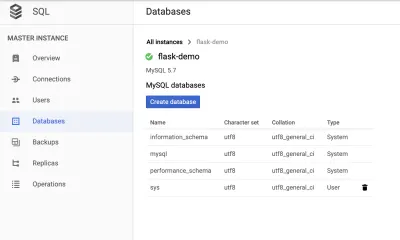
データベースを作成する
「データベース」タブに移動して、データベースを作成します。
新しいユーザーを作成する
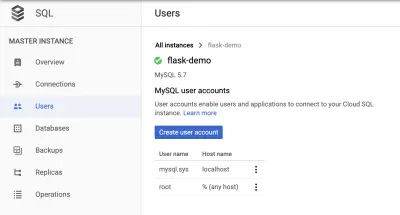
「ホスト名」セクションで、「%(任意のホスト)」を許可するように設定します。

ホワイトリストのIPアドレス
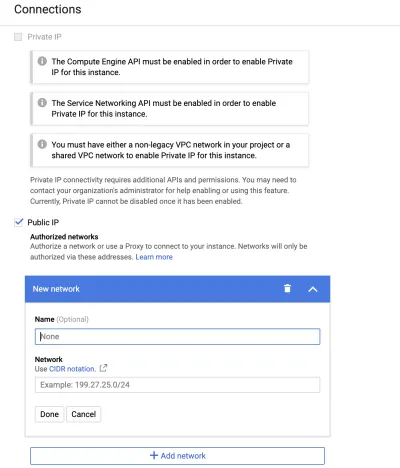
2つの方法のいずれかでデータベースインスタンスに接続できます。 プライベートIPアドレスには、仮想プライベートクラウド(VPC)が必要です。 このオプションを選択すると、Google CloudはGoogleが管理するVPCを作成し、その中にインスタンスを配置します。 この記事では、デフォルトのパブリックIPアドレスを使用します。 IPアドレスがホワイトリストに登録されている人だけがデータベースにアクセスできるという意味で公開されています。
IPアドレスをホワイトリストに登録するには、Google検索にmy ipと入力して、IPを取得します。 次に、[接続]タブと[ネットワークの追加]に移動します。
インスタンスに接続する
次に、「概要」パネルに移動し、クラウドシェルを使用して接続します。
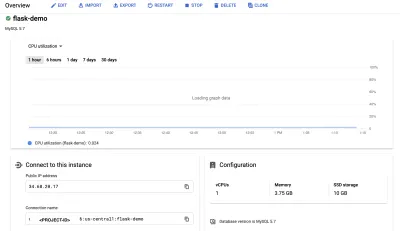
Cloud SQLインスタンスに接続するコマンドは、コンソールに事前に入力されています。
rootユーザーまたは以前に作成されたユーザーのいずれかを使用できます。 以下のコマンドでは、次のように言っています。ユーザーUSERNAMEとしてflask-demoインスタンスに接続します。 ユーザーのパスワードを入力するように求められます。
gcloud sql connect flask-demo --user=USERNAMEプロジェクトIDがないというエラーが表示された場合は、次のコマンドを実行してプロジェクトのIDを取得できます。
gcloud projects list 上記のコマンドから出力されたプロジェクトIDを取得し、以下のコマンドに入力して、 PROJECT_IDに置き換えます。
gcloud config set project PROJECT_ID 次に、 gcloud sql connectコマンドを実行すると、接続されます。
次のコマンドを実行して、アクティブなデータベースを確認します。
> show databases; 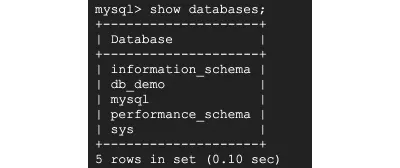
私のデータベースの名前はdb_demoで、以下のコマンドを実行してdb_demoデータベースを使用します。 information_schemaやperformance_schemaなどの他のデータベースが表示される場合があります。 これらは、テーブルのメタデータを格納するためにあります。
> use db_demo;次に、Flaskアプリのリストを反映したテーブルを作成します。 以下のコードをメモ帳に入力して、クラウドシェルに貼り付けます。
create table songs( song_id INT NOT NULL AUTO_INCREMENT, title VARCHAR(255), artist VARCHAR(255), genre VARCHAR(255), PRIMARY KEY(song_id) ); このコードは、4つの列( song_id 、 title 、 artist 、 genre )を持つs songsという名前のテーブルを作成するSQLコマンドです。 また、テーブルでsong_idを主キーとして定義し、1から自動的にインクリメントするように指示しました。
次に、showtablesを実行show tables; テーブルが作成されたことを確認します。
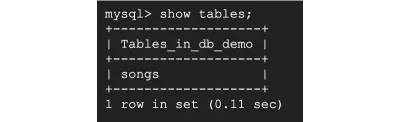
そして、そのように、データベースとsongsのテーブルを作成しました。
次のタスクは、アプリをデプロイできるようにGoogle AppEngineをセットアップすることです。
Google App Engine
App Engineは、大規模なWebアプリケーションを開発およびホストするためのフルマネージドプラットフォームです。 App Engineにデプロイする利点は、着信トラフィックに合わせてアプリを自動的にスケーリングできることです。
AppEngineのウェブサイトには次のように書かれています。
「サーバー管理と構成の展開がゼロであるため、開発者は管理オーバーヘッドなしで優れたアプリケーションの構築にのみ集中できます。」
AppEngineをセットアップする
App Engineを設定するには、Google CloudConsoleのUIまたはGoogleCloudSDKを使用する方法がいくつかあります。 このセクションではSDKを使用します。 これにより、ローカルマシンからGoogle Cloudインスタンスをデプロイ、管理、監視できます。
Google CloudSDKをインストールします
指示に従って、MacまたはWindows用のSDKをダウンロードしてインストールします。 このガイドでは、CLIでSDKを初期化する方法と、GoogleCloudプロジェクトを選択する方法についても説明します。
SDKがインストールされたので、Pythonスクリプトをデータベースのクレデンシャルで更新し、AppEngineにデプロイします。
ローカルセットアップ
ローカル環境では、CloudSQLとAppEngineを含む新しいアーキテクチャに合わせてセットアップを更新します。
まず、 app.yamlファイルをルートフォルダーに追加します。 これは、AppEngineがアプリをホストして実行するために必要な構成ファイルです。 AppEngineにランタイムと必要になる可能性のあるその他の変数を通知します。 このアプリでは、データベースのクレデンシャルを環境変数として追加して、AppEngineがデータベースのインスタンスを認識できるようにする必要があります。
app.yamlファイルに、以下のスニペットを追加します。 データベースのセットアップからランタイム変数とデータベース変数を取得します。 値を、Cloud SQLのセットアップ時に使用したユーザー名、パスワード、データベース名、および接続名に置き換えます。
#app.yaml runtime: python37 env_variables: CLOUD_SQL_USERNAME: YOUR-DB-USERNAME CLOUD_SQL_PASSWORD: YOUR-DB-PASSWORD CLOUD_SQL_DATABASE_NAME: YOUR-DB-NAME CLOUD_SQL_CONNECTION_NAME: YOUR-CONN-NAME次に、PyMySQLをインストールします。 これは、MySQLデータベースに接続してクエリを実行するPythonMySQLパッケージです。 CLIで次の行を実行して、PyMySQLパッケージをインストールします。
pip install pymysqlこの時点で、PyMySQLを使用してアプリからCloudSQLデータベースに接続する準備が整いました。 これにより、データベースにクエリを取得して挿入できるようになります。
データベースコネクタを初期化する
まず、ルートフォルダーにdb.pyファイルを作成し、以下のコードを追加します。
#db.py import os import pymysql from flask import jsonify db_user = os.environ.get('CLOUD_SQL_USERNAME') db_password = os.environ.get('CLOUD_SQL_PASSWORD') db_name = os.environ.get('CLOUD_SQL_DATABASE_NAME') db_connection_name = os.environ.get('CLOUD_SQL_CONNECTION_NAME') def open_connection(): unix_socket = '/cloudsql/{}'.format(db_connection_name) try: if os.environ.get('GAE_ENV') == 'standard': conn = pymysql.connect(user=db_user, password=db_password, unix_socket=unix_socket, db=db_name, cursorclass=pymysql.cursors.DictCursor ) except pymysql.MySQLError as e: print(e) return conn def get_songs(): conn = open_connection() with conn.cursor() as cursor: result = cursor.execute('SELECT * FROM songs;') songs = cursor.fetchall() if result > 0: got_songs = jsonify(songs) else: got_songs = 'No Songs in DB' conn.close() return got_songs def add_songs(song): conn = open_connection() with conn.cursor() as cursor: cursor.execute('INSERT INTO songs (title, artist, genre) VALUES(%s, %s, %s)', (song["title"], song["artist"], song["genre"])) conn.commit() conn.close()ここでいくつかのことを行いました。
まず、 os.environ.getメソッドを使用してapp.yamlファイルからデータベースのクレデンシャルを取得しました。 App Engineは、 app.yamlで定義されている環境変数をアプリで利用できるようにすることができます。
次に、 open_connection関数を作成しました。 クレデンシャルを使用してMySQLデータベースに接続します。
3番目に、 get_songsとadd_songsの2つの関数を追加しました。 1つ目は、 open_connection関数を呼び出してデータベースへの接続を開始します。 次に、すべての行についてsongsテーブルを照会し、空の場合は「DBに曲がありません」を返します。 add_songs関数は、新しいレコードをsongsテーブルに挿入します。
最後に、最初のmain.pyファイルに戻ります。 ここで、前に行ったようにオブジェクトから曲を取得する代わりに、 add_songs関数を呼び出してレコードを挿入し、 get_songs関数を呼び出してデータベースからレコードを取得します。
main.pyをリファクタリングしましょう:
#main.py from flask import Flask, jsonify, request from db import get_songs, add_songs app = Flask(__name__) @app.route('/', methods=['POST', 'GET']) def songs(): if request.method == 'POST': if not request.is_json: return jsonify({"msg": "Missing JSON in request"}), 400 add_songs(request.get_json()) return 'Song Added' return get_songs() if __name__ == '__main__': app.run() add_songs get_songsをインポートし、 songs()ビュー関数で呼び出しました。 postリクエストを行う場合は、 add_songs関数を呼び出し、 getリクエストを行う場合は、 get_songs関数を呼び出します。
そして、私たちのアプリは完了です。
次は、 requirements.txtファイルを追加します。 このファイルには、アプリの実行に必要なパッケージのリストが含まれています。 App Engineはこのファイルをチェックし、リストされたパッケージをインストールします。
pip freeze | grep "Flask\|PyMySQL" > requirements.txt この行は、アプリに使用している2つのパッケージ(FlaskとPyMySQL)を取得し、 requirements.txtファイルを作成して、パッケージとそのバージョンをファイルに追加します。
この時点で、 db.py 、 app.yaml 、 requirements.txtの3つの新しいファイルを追加しました。
Google AppEngineにデプロイする
次のコマンドを実行して、アプリをデプロイします。
gcloud app deployうまくいけば、コンソールはこれを出力します:
これで、アプリはAppEngineで実行されます。 ブラウザで表示するには、CLIでgcloud app browseを実行します。
Postmanを起動して、 postをテストし、リクエストをgetます。
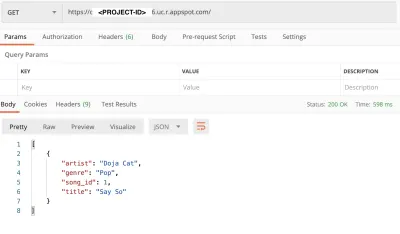
getリクエストのデモンストレーション(大プレビュー)現在、アプリはGoogleのインフラストラクチャでホストされており、サーバーレスアーキテクチャのすべてのメリットを活用するために、構成を微調整できます。 今後は、この記事に基づいてサーバーレスアプリケーションをより堅牢にすることができます。
結論
AppEngineやCloudSQLなどのPaaS(Platform-as-a-Service)インフラストラクチャを使用すると、基本的にインフラストラクチャレベルが抽象化され、より迅速に構築できるようになります。 開発者は、構成、バックアップと復元、オペレーティングシステム、自動スケーリング、ファイアウォール、トラフィックの移行などについて心配する必要はありません。 ただし、基盤となる構成を制御する必要がある場合は、カスタムビルドのサービスを使用する方がよい場合があります。
参考文献
- 「Pythonをダウンロード」
- 「venv—仮想環境の作成」、Python(ドキュメント)
- 「Postmanをダウンロード」
- 「クラウドSQL」、Google Cloud
- Google Cloud
- 「GoogleCloudFree Tier」、Google Cloud
- 「プロジェクトの作成と管理」、Google Cloud
- 「VPCの概要」(仮想プライベートクラウド)、Google Cloud
- 「AppEngine」、Google Cloud
- 「クイックスタート」(Google Cloud SDKをダウンロード)、Google Cloud
- PyMySQLドキュメント