
音声アシスタントの代替音声UI
公開: 2022-03-10ほとんどの人にとって、音声ユーザーインターフェースについて考えるときに最初に頭に浮かぶのは、Siri、Amazon Alexa、Googleアシスタントなどの音声アシスタントです。 実際、アシスタントは、ほとんどの人がコンピュータシステムと対話するために音声を使用したことがある唯一のコンテキストです。
音声アシスタントは音声ユーザーインターフェイスを主流にしていますが、音声ユーザーインターフェイスを使用、設計、および作成するための最良の方法は、アシスタントパラダイムだけではありません。
この記事では、音声アシスタントが抱える問題について説明し、直接音声対話と呼ばれる音声ユーザーインターフェイスの新しいアプローチを紹介します。
音声アシスタントは音声ベースのチャットボットです
音声アシスタントは、ユーザーインターフェイスとしてアイコンやメニューの代わりに自然言語を使用するソフトウェアです。 アシスタントは通常、質問に答え、多くの場合、積極的にユーザーを支援しようとします。
アシスタントは、単純なトランザクションやコマンドの代わりに、人間の会話を模倣し、対話モダリティとして双方向に自然言語を使用します。つまり、ユーザーからの入力と、自然言語を使用したユーザーへの回答の両方を受け取ります。
最初のアシスタントは、対話ベースの質問応答システムでした。 初期の例の1つは、Microsoft Officeのユーザーが達成しようとしていると思ったことに基づいて指示を与えることで、MicrosoftOfficeのユーザーを支援しようとしたMicrosoftのClippyです。 現在、アシスタントパラダイムの一般的な使用例はチャットボットであり、チャットディスカッションのカスタマーサポートによく使用されます。
一方、音声アシスタントは、入力やテキストの代わりに音声を使用するチャットボットです。 ユーザー入力は選択やテキストではなく、音声とシステムからの応答も大声で話されます。 これらのアシスタントは、合理的な方法で多数の質問に答えることができるGoogleアシスタントやAlexaなどの一般的なアシスタント、またはファーストフードの注文などの特別な目的のために構築されたカスタムアシスタントです。
多くの場合、ユーザーの入力は1〜2語であり、実際のテキストではなく選択肢として表示できますが、テクノロジーが進化するにつれて、会話はより自由で複雑になります。 チャットボットとアシスタントの最初の定義機能は、アイコン、メニュー、および一般的なモバイルアプリやWebサイトのユーザーエクスペリエンスを定義するトランザクションスタイルの代わりに、自然言語と会話スタイルを使用することです。
推奨読書: WebSpeechAPIとNode.jsを使用したシンプルなAIチャットボットの構築
自然言語の反応に由来する2番目の明確な特徴は、ペルソナの錯覚です。 システムが使用する音色、品質、および言語は、アシスタントエクスペリエンス、サービスに対する共感と感受性の錯覚、およびそのペルソナの両方を定義します。 優れたアシスタントエクスペリエンスのアイデアは、実在の人物と関わりを持つようなものです。
音声は私たちがコミュニケーションするための最も自然な方法であるため、これは素晴らしいように聞こえるかもしれませんが、自然言語の応答を使用することには2つの大きな問題があります。 コンピュータが人間をどれだけうまく模倣できるかに関連するこれらの問題の1つは、会話型AIテクノロジーの開発によって将来修正される可能性がありますが、人間の脳が情報を処理する方法の問題は人間の問題であり、予見可能な将来には修正できません。 次に、これらの問題を調べてみましょう。
自然言語応答に関する2つの問題
音声ユーザーインターフェイスはもちろん、音声をモダリティとして使用するユーザーインターフェイスです。 ただし、音声モダリティは、ユーザーからの情報の入力とシステムからの情報のユーザーへの出力の両方向に使用できます。 たとえば、一部のエレベータは、ユーザーがボタンを押した後にユーザーの選択を確認するために音声合成を使用します。 後で、情報の入力に音声のみを使用し、ユーザーに情報を表示するために従来のグラフィカルユーザーインターフェイスを使用する音声ユーザーインターフェイスについて説明します。
一方、音声アシスタントは、入力と出力の両方に音声を使用します。 このアプローチには2つの主な問題があります。
問題#1:人間の模倣は失敗する
人間として、私たちは人間のような特徴を人間以外の物体に帰するという生来の傾向があります。 雲の中の男の特徴が漂っているのを見たり、サンドイッチを見たりすると、ニヤリと笑っているように見えます。 これは擬人化と呼ばれます。

この現象はアシスタントにも当てはまり、自然言語の反応によって引き起こされます。 グラフィカルユーザーインターフェイスはある程度ニュートラルに構築できますが、誰かの声が若い人なのか年配の人なのか、男性なのか女性なのかを人間が考え始めることはできません。 このため、ユーザーはアシスタントが実際に人間であるとほとんど考え始めます。
しかし、私たち人間は偽物の検出に非常に優れています。 不思議なことに、何かが人間に似ているほど、小さな偏差が私たちの邪魔をし始めます。 人間のようになろうとしているものの、それまでは十分に測定されていないものに対して、不気味な気持ちがあります。 ロボット工学やコンピューターアニメーションでは、これは「不気味の谷」と呼ばれます。

私たちがアシスタントを作ろうとするより良い、より人間的なように、何かがうまくいかないとき、ユーザーエクスペリエンスはより不気味で失望する可能性があります。 アシスタントを試したことのある人なら誰でも、ばかげている、あるいは失礼だと感じる何かで応答するという問題に遭遇したことでしょう。
音声アシスタントの不気味の谷は、克服するのが難しいアシスタントユーザーエクスペリエンスの品質の問題を引き起こします。 実際、チューリングテスト(有名な数学者アランチューリングにちなんで名付けられました)は、2人のエージェント間の会話を示す人間の評価者が、どちらが機械でどちらが人間であるかを区別できない場合に合格します。 これまでのところ、それは通過したことがありません。
これは、アシスタントパラダイムが、決して実現できない人間のようなサービスエクスペリエンスの約束を設定し、ユーザーががっかりすることを意味します。 ユーザーが人間のようなアシスタントを信頼し始めるので、成功した経験は最終的な失望を構築するだけです。
問題2:シーケンシャルで遅い相互作用
音声アシスタントの2番目の問題は、自然言語応答のターンベースの性質が対話の遅延を引き起こすことです。 これは、私たちの脳が情報を処理する方法によるものです。
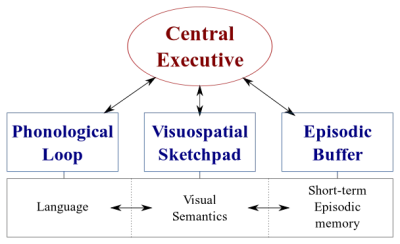
私たちの脳には2種類のデータ処理システムがあります。
- 音声を処理する言語システム。
- 視覚的および空間的情報の処理に特化した視覚空間システム。
これらの2つのシステムは並行して動作できますが、両方のシステムが一度に処理するのは1つだけです。 これが、話すことと車を運転することを同時に行うことができる理由ですが、これらの活動は両方とも視空間システムで行われるため、テキストを送信して運転することはできません。

同様に、音声アシスタントと話しているときは、アシスタントは静かにしておく必要があり、その逆も同様です。 これにより、ターンベースの会話が作成され、他の部分は常に完全にパッシブになります。
ただし、友達と話し合いたい難しいトピックを考えてみてください。 電話ではなく、対面で話し合うと思いますよね? これは、対面での会話では、非言語コミュニケーションを使用して、会話パートナーにリアルタイムの視覚的フィードバックを提供するためです。 これにより、双方向の情報交換ループが作成され、両方の当事者が同時に会話に積極的に参加できるようになります。
アシスタントはリアルタイムの視覚的フィードバックを提供しません。 彼らはエンドポインティングと呼ばれる技術に依存して、ユーザーがいつ会話をやめ、その後だけ返信するかを決定します。 また、返信するときに、ユーザーからの入力を同時に受け取ることはありません。 体験は完全に一方向でターンベースです。

双方向のリアルタイムの対面会話では、両方の当事者が視覚的信号と言語的信号の両方に即座に反応できます。 これは人間の脳のさまざまな情報処理システムを利用し、会話がよりスムーズで効率的になります。
音声アシスタントは、入力チャネルと出力チャネルの両方で自然言語を使用しているため、単方向モードでスタックします。 音声は入力のために入力するよりも最大4倍高速ですが、読むよりも消化が大幅に遅くなります。 情報は順番に処理する必要があるため、このアプローチは、アシスタントからの出力をあまり必要としない「ライトをオフにする」などの単純なコマンドに対してのみ適切に機能します。
以前、ユーザーからのデータ入力にのみ音声を使用する音声ユーザーインターフェイスについて説明することを約束しました。 この種の音声ユーザーインターフェイスは、音声ユーザーインターフェイスの優れた部分(自然さ、速度、使いやすさ)の恩恵を受けますが、不気味の谷や連続した相互作用などの悪い部分に悩まされることはありません。
この代替案を考えてみましょう。
音声アシスタントのより良い代替手段
音声アシスタントのこれらの問題を克服するための解決策は、自然言語の応答を手放し、それらをリアルタイムの視覚的フィードバックに置き換えることです。 フィードバックをビジュアルに切り替えると、ユーザーはフィードバックの提供と取得を同時に行うことができます。 これにより、ユーザーの邪魔をせずにアプリケーションが反応し、双方向の情報フローが可能になります。 情報の流れは双方向であるため、スループットは大きくなります。
現在、音声アシスタントの主な使用例は、アラームの設定、音楽の再生、天気の確認、簡単な質問です。 これらはすべて、失敗したときにユーザーをそれほど苛立たせない、リスクの低いタスクです。
ウォールストリートジャーナルのDavidPierceがかつて書いたように:
「フライトの予約や音声アシスタントによる予算の管理、スピーカーで食材を叫んで食事を追跡することは想像できません。」
—ウォールストリートジャーナルのDavid Pierce
これらは、正しく実行する必要がある情報量の多いタスクです。
ただし、最終的には、音声ユーザーインターフェイスは失敗します。 重要なのは、これをできるだけ早くカバーすることです。 キーボードで入力したり、対面で会話したりすると、多くのエラーが発生します。 ただし、ユーザーはバックスペースをクリックして再試行するか、説明を求めるだけで回復できるため、これはまったくイライラすることではありません。
このエラーからの迅速な回復により、ユーザーはより効率的になり、アシスタントとの奇妙な会話を強いられることはありません。
直接音声対話
ほとんどのアプリケーションでは、アクションは、画面上のグラフィック要素の操作、(タッチスクリーン上での)ポークまたはスワイプ、マウスのクリック、および/またはキーボードのボタンの押下によって実行されます。 音声入力は、これらのグラフィック要素を操作するための追加オプションまたはモダリティとして追加できます。 このタイプのインタラクションは、直接音声インタラクションと呼ぶことができます。
直接の音声対話とアシスタントの違いは、アシスタントであるアバターにタスクの実行を依頼する代わりに、ユーザーが音声を使用してグラフィカルユーザーインターフェイスを直接操作することです。
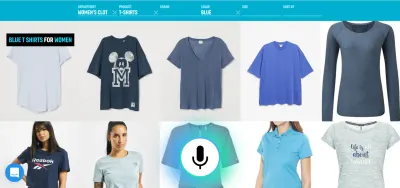
「これはセマンティクスではありませんか?」とあなたは尋ねるかもしれません。 コンピューターと話す場合、コンピューターと直接話しているのか、仮想ペルソナを介して話しているのかは本当に重要ですか? どちらの場合も、あなたはただコンピュータと話しているだけです!
はい、違いは微妙ですが重要です。 GUI (グラフィカルユーザーインターフェイス)のボタンまたはメニュー項目をクリックすると、マシンを操作していることが明らかになります。 人の幻想はありません。 そのクリックを音声コマンドに置き換えることで、人間とコンピューターの相互作用を改善しています。 一方、アシスタントパラダイムでは、人間同士の相互作用の劣化したバージョンを作成しているため、不気味の谷に旅しています。
音声機能をグラフィカルユーザーインターフェイスにブレンドすることで、さまざまなモダリティの力を活用できる可能性もあります。 ユーザーは音声を使用してアプリケーションを操作できますが、従来のグラフィカルインターフェイスを使用することもできます。 これにより、ユーザーはタッチと音声をシームレスに切り替えて、コンテキストとタスクに基づいて最適なオプションを選択できます。
たとえば、音声は豊富な情報を入力するための非常に効率的な方法です。 いくつかの有効な選択肢から選択する場合は、タッチまたはクリックする方がおそらく適切です。 次に、ユーザーは「明日出発するロンドンからニューヨークへのフライトを表示してください」などと言って入力と閲覧を置き換え、タッチを使用してリストから最適なオプションを選択できます。
ここで、「わかりました。これは見栄えがよいので、このような音声ユーザーインターフェイスの例をこれまでに見たことがないのはなぜですか。 なぜ大手テクノロジー企業はこのようなツールを作成しないのですか?」 そうですね、それにはおそらく多くの理由があります。 理由の1つは、現在の音声アシスタントパラダイムが、エンドユーザーから取得したデータを活用するための最良の方法である可能性があることです。 もう1つの理由は、音声技術の構築方法に関係しています。
正常に機能する音声ユーザーインターフェイスには、次の2つの異なる部分が必要です。
- 音声をテキストに変換する音声認識。
- そのテキストから意味を抽出する自然言語理解コンポーネント。
第二部は、「居間の照明を消してください」と「居間の照明を消してください」という発話を同じ行動に変える魔法です。
推奨読書: API.AIを使用してGoogleホーム用に独自のアクションを構築する方法
ディスプレイ付きのアシスタント(SiriやGoogleアシスタントなど)を使用したことがある場合は、ほぼリアルタイムでトランスクリプトを取得していることに気付いたと思いますが、話すのをやめた後、システムが起動するまでに数秒かかります要求したアクションを実際に実行します。 これは、音声認識と自然言語理解の両方が連続して行われるためです。
これをどのように変更できるか見てみましょう。
リアルタイムの口頭言語理解:より効率的な音声コマンドの秘訣
アプリケーションがユーザー入力にどれだけ速く反応するかは、アプリケーションの全体的なユーザーエクスペリエンスの主要な要素です。 オリジナルのiPhoneの最も重要な革新は、非常に応答性が高く反応性の高いタッチスクリーンでした。 音声入力に瞬時に反応する音声ユーザーインターフェイスの機能も同様に重要です。
ユーザーとUIの間に高速な双方向の情報交換ループを確立するには、音声対応のGUIが、ユーザーが何か実用的なことを言ったときはいつでも、文の途中でも即座に反応できる必要があります。 これには、ストリーミング音声言語理解と呼ばれる手法が必要です。
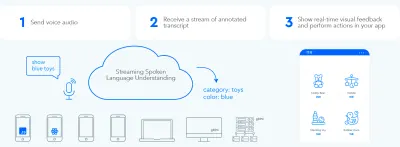
ユーザーの要求を処理する前にユーザーが話すのをやめるのを待つ従来のターンベースの音声アシスタントシステムとは異なり、ストリーミング音声言語理解を使用するシステムは、ユーザーが話し始めた瞬間からユーザーの意図を積極的に理解しようとします。 ユーザーが実用的なことを言うとすぐに、UIはそれに反応します。
即時応答は、システムがユーザーを理解していることを即座に検証し、ユーザーに続行を促します。 これは、人間同士のコミュニケーションにおけるうなずきや短い「a-ha」に似ています。 これにより、より長く、より複雑な発話がサポートされます。 それぞれ、システムがユーザーを理解していない場合、またはユーザーのミスピークが発生した場合、即時フィードバックにより迅速な回復が可能になります。 ユーザーはすぐに修正して続行するか、口頭で修正することもできます。「これが欲しい、いや、それが欲しい」。 この種のアプリケーションは、音声検索デモで自分で試すことができます。
デモでわかるように、リアルタイムの視覚的フィードバックにより、ユーザーは自然に自分自身を修正し、音声体験を継続するように促します。 それらは仮想ペルソナと混同されないため、個人的な侮辱としてではなく、タイプミスと同様の方法で発生する可能性のあるエラーに関連する可能性があります。 ユーザーに提供される情報は、1分あたり約150語の一般的な発話速度によって制限されないため、エクスペリエンスはより速く、より自然になります。
推奨読書:リンドン・セレホによる音声体験のデザイン
結論
これまでのところ、音声アシスタントは音声ユーザーインターフェイスの最も一般的な使用法ですが、自然言語の応答を使用すると、非効率的で不自然になります。 音声は情報を入力するための優れたモダリティですが、機械の話を聞くことはあまり刺激的ではありません。 これは音声アシスタントの大きな問題です。
したがって、音声の未来は、コンピューターとの会話ではなく、面倒なユーザータスクを最も自然なコミュニケーション方法であるスピーチに置き換えることです。 直接の音声対話を使用して、Webまたはモバイルアプリケーションでのフォーム入力エクスペリエンスを改善し、より優れた検索エクスペリエンスを作成し、アプリケーションでの制御またはナビゲートをより効率的に行うことができます。
デザイナーやアプリ開発者は、アプリやウェブサイトの摩擦を減らす方法を常に模索しています。 現在のグラフィカルユーザーインターフェイスを音声モダリティで強化すると、特にエンドユーザーがモバイルや外出先で入力が難しい場合など、特定の状況でユーザーとの対話が数倍速くなります。 実際、音声検索は、デスクトップコンピュータを使用している場合でも、従来の検索フィルタリングユーザーインターフェイスよりも最大5倍高速になる可能性があります。
次回、アプリケーション内の特定のユーザータスクをより使いやすく、より楽しく使用する方法を検討している場合、またはコンバージョンを増やすことに関心がある場合は、そのユーザータスクを自然言語で正確に記述できるかどうかを検討してください。 はいの場合、音声モダリティでユーザーインターフェイスを補完しますが、ユーザーにコンピューターとの会話を強制しないでください。
資力
- 「VoiceFirstと未来のマルチモーダルユーザーインターフェイス」、UXmattersのJoan Palmiter Bajorek
- 「生産的な音声対応アプリを作成するためのガイドライン」、Hannes Heikinheimo、Speechly
- 「タッチスクリーンアプリに音声機能が必要な6つの理由」、Ottomatias Peura、UXmatters
- 有形と無形の混合:Adobe XD、Nick Babich、SmashingMagazineを使用したマルチモーダルインターフェイスの設計
( Adobe XDは、類似したもののプロトタイピングに使用できます) - 「音速での効率:音声対応操作の約束」、RAIN、Eric Turkington
- eコマース音声検索フィルタリングのリアルタイムの視覚的フィードバックを紹介するデモ(ビデオバージョン)
- Speechlyは、この種のユーザーインターフェイス用の開発者ツールを提供します
- オープンソースの代替:voice2json