
Che cos'è l'apprendimento automatico con Java? Come implementarlo?
Pubblicato: 2021-03-10Sommario
Che cos'è l'apprendimento automatico?
L'apprendimento automatico è una divisione dell'intelligenza artificiale che apprende dai dati, dagli esempi e dalle esperienze disponibili per imitare il comportamento e l'intelligenza umana. Un programma creato utilizzando l'apprendimento automatico può creare logica da solo senza che un essere umano debba scrivere manualmente il codice.
Tutto iniziò con The Turing Test nei primi anni '50, quando Alan Turning concluse che per avere un'intelligenza reale, un computer avrebbe dovuto manipolare o convincere un essere umano che anche lui era umano. L'apprendimento automatico è un concetto relativamente vecchio, ma è solo oggi che questo campo emergente è soggetto a realizzazione poiché i computer ora possono elaborare algoritmi complessi. Gli algoritmi di apprendimento automatico si sono evoluti negli ultimi dieci anni per includere complesse capacità di calcolo che a loro volta hanno portato a un miglioramento delle loro capacità di imitazione.
Anche le applicazioni di apprendimento automatico sono aumentate a un ritmo allarmante. Dall'assistenza sanitaria, alla finanza, all'analisi e all'istruzione, alla produzione, al marketing e alle operazioni governative, ogni settore ha visto un aumento significativo della qualità e dell'efficienza dopo l'implementazione delle tecnologie di apprendimento automatico. Ci sono stati miglioramenti qualitativi diffusi in tutto il mondo, quindi, guidando la domanda di professionisti dell'apprendimento automatico.
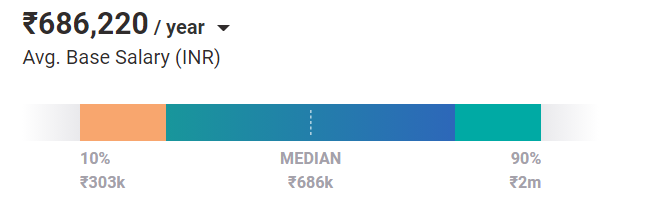
In media, gli ingegneri dell'apprendimento automatico valgono uno stipendio di ₹ 686.220 all'anno oggi. E questo è il caso di una posizione entry-level. Con esperienza e competenze, possono guadagnare fino a ₹ 2 milioni all'anno in India.
Tipi di algoritmi di apprendimento automatico
Gli algoritmi di apprendimento automatico sono di tre tipi:
1. Apprendimento supervisionato : in questo tipo di apprendimento, i set di dati di addestramento guidano un algoritmo per fare previsioni accurate o decisioni analitiche. Impiega l'apprendimento dai set di dati di addestramento precedenti per elaborare nuovi dati. Di seguito sono riportati alcuni esempi di modelli di apprendimento automatico supervisionato:

- Regressione lineare
- Regressione logistica
- Albero decisionale
2. Apprendimento non supervisionato : in questo tipo di apprendimento, un modello di apprendimento automatico apprende da informazioni senza etichetta. Impiega il raggruppamento dei dati raggruppando oggetti o comprendendo la relazione tra loro o sfruttando le loro proprietà statistiche per condurre analisi. Esempi di algoritmi di apprendimento senza supervisione sono:
- K-mezzi di raggruppamento
- Raggruppamento gerarchico
3. Apprendimento per rinforzo : questo processo si basa su colpi e prove. Sta imparando interagendo con lo spazio o con un ambiente. Un algoritmo RL apprende dalle sue esperienze passate interagendo con l'ambiente e determinando la migliore linea d'azione.
Come implementare l'apprendimento automatico con Java?
Java è tra i principali linguaggi di programmazione utilizzati per l'implementazione di algoritmi di apprendimento automatico. La maggior parte delle sue librerie sono open-source, fornendo ampio supporto per la documentazione, facile manutenzione, commerciabilità e facile leggibilità.
A seconda della popolarità, ecco le prime 10 librerie di machine learning utilizzate per implementare l'apprendimento automatico in Java.
1. ADAMS
Advanced-Data Mining And Machine Learning System o ADAMS si occupa della creazione di sistemi di flusso di lavoro nuovi e flessibili e della gestione di complessi processi del mondo reale. ADAMS utilizza un'architettura ad albero per gestire il flusso di dati invece di effettuare connessioni input-output manuali.
Elimina qualsiasi necessità di connessioni esplicite. Si basa sul principio "less is more" ed esegue il recupero, la visualizzazione e le visualizzazioni basate sui dati. ADAMS è esperto nell'elaborazione dei dati, nello streaming di dati, nella gestione di database, nello scripting e nella documentazione.
2. JavaML
JavaML offre una varietà di algoritmi di ML e data mining scritti per Java per supportare ingegneri software, programmatori, data scientist e ricercatori. Ogni algoritmo ha un'interfaccia comune che è facile da usare e ha un ampio supporto per la documentazione anche se non c'è una GUI.
È piuttosto semplice e diretto da implementare rispetto ad altri algoritmi di clustering. Le sue funzionalità principali includono la manipolazione dei dati, la documentazione, la gestione del database, la classificazione dei dati, il clustering, la selezione delle funzionalità e così via.
Partecipa al corso di Machine Learning online dalle migliori università del mondo: master, programmi post-laurea per dirigenti e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
3. WEKA
Weka è anche una libreria di machine learning open source scritta per Java che supporta il deep learning. Fornisce una serie di algoritmi di apprendimento automatico e trova ampio uso nel data mining, nella preparazione dei dati, nel clustering dei dati, nella visualizzazione dei dati e nella regressione, tra le altre operazioni sui dati.
Esempio: lo dimostreremo utilizzando un piccolo set di dati sul diabete.
Passaggio 1 : carica i dati utilizzando Weka
| importare istanze.weka.core; importare weka.core.converters.ConverterUtils.DataSource; classe pubblica Principale { public static void main(String[] args) genera un'eccezione { // Specificando l'origine dati DataSource dataSource = new DataSource(“data.arff”); // Caricamento del set di dati Istanze dataInstances = dataSource.getDataSet(); // Visualizzazione del numero di istanze log.info(“Il numero di istanze caricate è: ” + dataInstances.numInstances()); log.info("data:" + dataInstances.toString()); } } |
Passaggio 2: il set di dati ha 768 istanze. Dobbiamo accedere al numero di attributi, cioè 9.
| log.info(“Il numero di attributi (caratteristiche) nel set di dati: ” + dataInstances.numAttributes()); |
Passaggio 3 : è necessario determinare la colonna di destinazione prima di creare un modello e trovare il numero di classi.
| // Identificazione dell'indice dell'etichetta dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // Ottenere il numero di log.info(“Il numero di classi: ” + dataInstances.numClasses()); |
Passaggio 4 : ora costruiremo il modello utilizzando un semplice classificatore ad albero, J48.
| // Creazione di un classificatore dell'albero decisionale J48 treeClassifier = nuovo J48(); treeClassifier.setOptions(new String[] { “-U” }); treeClassifier.buildClassifier(dataInstances); |
Il codice precedente illustra come creare un albero non potato che consiste nelle istanze di dati richieste per l'addestramento del modello. Una volta che la struttura ad albero è stata stampata dopo l'addestramento del modello, possiamo determinare come le regole sono state costruite internamente.
| pla <= 127 | massa <= 26,4 | | preg <= 7: testato_negativo (117.0/1.0) | | pregna > 7 | | | massa <= 0: testato_positivo (2.0) | | | massa > 0: testato_negativo (13.0) | massa > 26.4 | | età <= 28: testato_negativo (180,0/22,0) | | età > 28 | | | plas <= 99: testato_negativo (55.0/10.0) | | | pla > 99 | | | | pedi <= 0,56: testato_negativo (84,0/34,0) | | | | pedi > 0,56 | | | | | preg <= 6 | | | | | | età <= 30: testato_positivo (4,0) | | | | | | età > 30 | | | | | | | età <= 34: testato_negativo (7.0/1.0) | | | | | | | età > 34 | | | | | | | | massa <= 33,1: testato_positivo (6,0) | | | | | | | | massa > 33.1: testato_negativo (4.0/1.0) | | | | | preg > 6: testato_positivo (13.0) pla > 127 | massa <= 29,9 | | plas <= 145: testato_negativo (41.0/6.0) | | pla > 145 | | | età <= 25: testato_negativo (4.0) | | | età > 25 | | | | età <= 61 anni | | | | | massa <= 27,1: testato_positivo (12,0/1,0) | | | | | massa > 27.1 | | | | | | pres <= 82 | | | | | | | pedi <= 0,396: testato_positivo (8,0/1,0) | | | | | | | pedi > 0.396: testato_negativo (3.0)  | | | | | | pres > 82: testato_negativo (4.0) | | | | età > 61: testato_negativo (4.0) | massa > 29.9 | | pla <= 157 | | | pres <= 61: testato_positivo (15,0/1,0) | | | stampa > 61 | | | | età <= 30: testato_negativo (40.0/13.0) | | | | età > 30: testato_positivo (60.0/17.0) | | plas > 157: testato_positivo (92.0/12.0) Numero di foglie: 22 Dimensioni dell'albero: 43 |
4. Apache Mahaut
Mahaut è una raccolta di algoritmi per aiutare a implementare l'apprendimento automatico utilizzando Java. È un framework di algebra lineare scalabile che utilizza il quale gli sviluppatori possono eseguire analisi matematiche e statistici. Di solito viene utilizzato da data scientist, ingegneri di ricerca e professionisti dell'analisi per creare applicazioni pronte per l'azienda. La sua scalabilità e flessibilità consente agli utenti di implementare il clustering dei dati, i sistemi di raccomandazione e di creare app di machine learning performanti in modo rapido e semplice.
5. Apprendimento profondo4j
Deeplearning4j è una libreria di programmazione scritta in Java e offre un ampio supporto per il deep learning. È un framework open source che combina reti neurali profonde e apprendimento per rinforzo profondo per servire le operazioni aziendali. È compatibile con Scala, Kotlin, Apache Spark, Hadoop e altri linguaggi JVM e framework di big data computing.
Viene in genere utilizzato per rilevare schemi ed emozioni nella voce, nel parlato e nel testo scritto. Serve come uno strumento fai-da-te in grado di scoprire discrepanze nelle transazioni e gestire più attività. È una libreria distribuita di livello commerciale che ha una documentazione API dettagliata grazie alla sua natura open source.
Ecco un esempio di come implementare l'apprendimento automatico utilizzando Deeplearning4j.
Esempio : utilizzando Deeplearning4j, costruiremo un modello di Convolution Neural Network (CNN) per classificare le cifre scritte a mano con l'aiuto della libreria MNIST.
Passaggio 1 : carica il set di dati per visualizzarne le dimensioni.
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = nuovo MnistDataSetIterator(batchSize,false,seed); |
Passaggio 2 : assicurati che il set di dati ci fornisca dieci etichette univoche.
| log.info(“Il numero di etichette totali trovate nel set di dati di addestramento ” + MNISTTrain.totalOutcomes()); log.info("Il numero di etichette totali trovate nel set di dati di test " + MNISTTest.totalOutcomes()); |
Passaggio 3 : ora configureremo l'architettura del modello utilizzando due livelli di convoluzione insieme a un livello appiattito per visualizzare l'output.
Ci sono opzioni in Deeplearning4j che ti consentono di inizializzare lo schema di pesi.
| // Costruire il modello CNN MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed) // seme casuale .l2(0.0005) // regolarizzazione .weightInit(WeightInit.XAVIER) // inizializzazione dello schema di pesi .updater(new Adam(1e-3)) // Impostazione dell'algoritmo di ottimizzazione .elenco() .layer(nuovo ConvolutionLayer.Builder(5, 5) //Impostazione del passo, della dimensione del kernel e della funzione di attivazione. .nIn(nCanali) .passo(1,1) .nUscita(20) .attivazione(Attivazione.IDENTITÀ) .costruire()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // downsampling della convoluzione .kernelSize(2,2) .passo(2,2) .costruire()) .layer(nuovo ConvolutionLayer.Builder(5, 5) // Impostazione del passo, della dimensione del kernel e della funzione di attivazione. .passo(1,1) .nUscita(50) .attivazione(Attivazione.IDENTITÀ) .costruire()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // downsampling della convoluzione .kernelSize(2,2) .passo(2,2) .costruire()) .layer(nuovo DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(nuovo OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(outputNum) .attivazione(Attivazione.SOFTMAX) .costruire()) // il livello di output finale è 28×28 con una profondità di 1. .setInputType(InputType.convolutionalFlat(28,28,1)) .costruire(); |
Passaggio 4 : dopo aver configurato l'architettura, inizializzeremo la modalità e il set di dati di addestramento e inizieremo l'addestramento del modello.
| Modello MultiLayerNetwork = nuovo MultiLayerNetwork(conf); // inizializza i pesi del modello. model.init(); log.info(“Fase 2: inizia ad addestrare il modello”); //Impostazione di un listener ogni 10 iterazioni e valutazione su test set su ogni epoch model.setListeners(nuovo ScoreIterationListener(10), nuovo EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // Addestrare il modello model.fit(MNISTTrain, nEpochs); |
All'inizio dell'addestramento del modello, avrai la matrice di confusione dell'accuratezza della classificazione.
Ecco la precisione del modello dopo dieci epoche di addestramento:
| ==========================Matrice di confusione======================== == 0 1 2 3 4 5 6 7 8 9 —————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKI
Ambiente per lo sviluppo di applicazioni KDD supportate da Index-structure o ELKI è una raccolta di algoritmi e programmi integrati utilizzati per il data mining. Scritta in Java, è una libreria open source che comprende parametri altamente configurabili in algoritmi. Viene in genere utilizzato da ricercatori e studenti per ottenere informazioni dettagliate sui set di dati. Come suggerisce il nome, fornisce un ambiente per lo sviluppo di sofisticati programmi di data mining e database utilizzando una struttura a indici.
7. JSAT
Java Statistical Analysis Tool o JSAT è una libreria GPL3 che utilizza un framework orientato agli oggetti per aiutare gli utenti a implementare l'apprendimento automatico con Java. Viene in genere utilizzato per scopi di autoeducazione da studenti e sviluppatori. Rispetto ad altre librerie di implementazione AI, JSAT ha il maggior numero di algoritmi ML ed è il più veloce tra tutti i framework. Senza dipendenze esterne, è altamente flessibile ed efficiente e offre prestazioni elevate.
8. Il quadro di apprendimento automatico Encog
Encog è scritto in Java e C# e comprende librerie che aiutano a implementare algoritmi di apprendimento automatico. Viene utilizzato per costruire algoritmi genetici, reti bayesiane, modelli statistici come il modello Hidden Markov e altro ancora.
9. Maglio
Machine Learning for Language Toolkit o Mallet viene utilizzato nell'elaborazione del linguaggio naturale (NLP). Come la maggior parte degli altri framework di implementazione ML, Mallet fornisce anche supporto per la modellazione dei dati, il clustering dei dati, l'elaborazione dei documenti, la classificazione dei documenti e così via.
10. Spark MLlib
Spark MLlib viene utilizzato dalle aziende per migliorare l'efficienza e la scalabilità della gestione del flusso di lavoro. Elabora grandi quantità di dati e supporta algoritmi ML con carichi pesanti.
Checkout: idee per progetti di apprendimento automatico
Conclusione
Questo ci porta alla fine dell'articolo. Per ulteriori informazioni sui concetti di Machine Learning, contatta i migliori docenti di IIIT Bangalore e Liverpool John Moores University attraverso il programma di Master of Science in Machine Learning e AI di upGrad.
Perché dovremmo usare Java insieme a Machine Learning?
I professionisti dell'apprendimento automatico troveranno più facile interfacciarsi con gli attuali repository di codice se scelgono Java come linguaggio di programmazione per i loro progetti. È un linguaggio di Machine Learning preferito grazie a funzionalità come facilità d'uso, servizi a pacchetto, migliore interazione con l'utente, debug rapido e illustrazione grafica dei dati. Java consente agli sviluppatori di Machine Learning di scalare facilmente i propri sistemi, rendendolo una scelta eccellente per la creazione di applicazioni di Machine Learning grandi e sofisticate da zero. Java Virtual Machine (JVM) supporta una serie di ambienti di sviluppo integrati (IDE) che consentono ai machine learning di progettare nuovi strumenti rapidamente.
Imparare Java è facile?
Poiché Java è un linguaggio di alto livello, è semplice da comprendere. Come studente, non dovrai entrare nei dettagli in quanto è un linguaggio ben strutturato e orientato agli oggetti che è abbastanza semplice da essere imparato dai principianti. Poiché ci sono numerose procedure che funzionano automaticamente, puoi padroneggiarle rapidamente. Non devi entrare nei dettagli su come funzionano le cose lì dentro. Java è un linguaggio di programmazione indipendente dalla piattaforma. Consente a un programmatore di creare un'applicazione mobile che può essere utilizzata su qualsiasi dispositivo. È il linguaggio preferito di Internet of Things, nonché il miglior strumento per lo sviluppo di applicazioni a livello aziendale.
Che cos'è ADAMS e in che modo è utile in Machine Learning?
L'Advanced Data Mining And Machine Learning System (ADAMS) è un motore di flusso di lavoro con licenza GPLv3 per la creazione e la gestione rapida di flussi di lavoro reattivi basati sui dati che possono essere facilmente incorporati nei processi aziendali. Il motore del flusso di lavoro, che segue il principio di meno è di più, è il cuore di ADAMS. ADAMS utilizza una struttura ad albero invece di consentire all'utente di disporre gli operatori (o attori in gergo ADAMS) su un'area di disegno e quindi collegare manualmente input e output. Non sono richieste connessioni esplicite perché questa struttura e gli attori del controllo determinano come i dati fluiscono nel processo. La rappresentazione interna dell'oggetto e l'annidamento dei sub-operatori all'interno dei gestori degli operatori risultano in una struttura ad albero. ADAMS fornisce una serie diversificata di agenti per il recupero, l'elaborazione, l'estrazione e la visualizzazione dei dati.