
Che cos'è l'albero decisionale nel data mining? Tipi, esempi e applicazioni del mondo reale
Pubblicato: 2021-06-15Sommario
Introduzione al data mining
I dati sono spesso presenti come dati grezzi che devono essere elaborati in modo efficace per convertirli in informazioni utili. La previsione dei risultati spesso si basa sul processo di ricerca di modelli, anomalie o correlazioni all'interno dei dati. Il processo è stato definito "scoperta della conoscenza nei database".
Solo negli anni '90 è stato coniato il termine "data mining". Il data mining è stato fondato su tre discipline: statistica, intelligenza artificiale e apprendimento automatico. Il data mining automatizzato ha spostato il processo di analisi da un approccio noioso a uno più veloce. Il data mining consente all'utente di farlo
- Rimuovere tutti i dati rumorosi e caotici
- Comprendere i dati rilevanti e utilizzarli per la previsione di informazioni utili.
- Il processo di previsione delle decisioni informate è accelerato .
Il data mining potrebbe anche essere definito come il processo di identificazione di modelli nascosti di informazioni che richiedono una categorizzazione. Solo allora i dati possono essere convertiti in dati utili. I dati utili possono essere inseriti in un data warehouse, algoritmi di data mining, analisi dei dati per il processo decisionale.
Albero decisionale nel data mining
Un tipo di tecnica di data mining, Decision tree nel data mining, costruisce un modello per la classificazione dei dati. I modelli sono costruiti nella forma della struttura ad albero e quindi appartengono alla forma di apprendimento supervisionato. Oltre ai modelli di classificazione, gli alberi decisionali vengono utilizzati per costruire modelli di regressione per prevedere etichette o valori di classe che aiutano il processo decisionale. Sia i dati numerici che quelli categoriali come sesso, età, ecc. possono essere utilizzati da un albero decisionale.
Struttura di un albero decisionale
La struttura di un albero decisionale consiste in un nodo radice, rami e nodi foglia. I nodi ramificati sono i risultati di un albero ei nodi interni rappresentano il test su un attributo. I nodi foglia rappresentano un'etichetta di classe.
Funzionamento di un albero decisionale
1. Un albero decisionale funziona nell'ambito dell'approccio di apprendimento supervisionato per variabili discrete e continue. Il set di dati è suddiviso in sottoinsiemi sulla base dell'attributo più significativo del set di dati. L'identificazione dell'attributo e la suddivisione avviene tramite gli algoritmi.
2. La struttura dell'albero decisionale è costituita dal nodo radice, che è il nodo predittivo significativo. Il processo di scissione avviene dai nodi decisionali che sono i sottonodi dell'albero. I nodi che non si dividono ulteriormente sono chiamati nodi foglia o terminali.
3. Il set di dati è suddiviso in regioni omogenee e non sovrapposte secondo un approccio top-down. Lo strato superiore fornisce le osservazioni in un unico punto che poi si divide in rami. Il processo è definito "Approccio avido" a causa del suo focus solo sul nodo corrente piuttosto che sui nodi futuri.
4. Fino al raggiungimento di un criterio di arresto, l'albero decisionale continuerà a funzionare.
5. Con la creazione di un albero decisionale, vengono generati molto rumore e valori anomali. Per rimuovere questi dati anomali e rumorosi, viene applicato un metodo di "potatura degli alberi". Quindi, l'accuratezza del modello aumenta.
6. L'accuratezza di un modello viene verificata su un set di test composto da tuple di test ed etichette di classe. Un modello accurato viene definito in base alle percentuali di tuple e classi di test di classificazione impostate dal modello.
Figura 1 : Un esempio di un albero non potato e di un albero potato
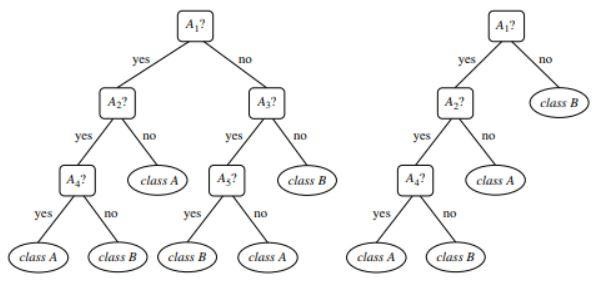
Fonte
Tipi di albero decisionale
Gli alberi decisionali portano allo sviluppo di modelli di classificazione e regressione basati su una struttura ad albero. I dati sono suddivisi in sottoinsiemi più piccoli. Il risultato di un albero decisionale è un albero con nodi decisionali e nodi foglia. Di seguito vengono spiegati due tipi di alberi decisionali:
1. Classificazione
La classificazione include la costruzione di modelli che descrivono importanti etichette di classe. Sono applicati nelle aree dell'apprendimento automatico e del riconoscimento dei modelli. Gli alberi decisionali nell'apprendimento automatico attraverso modelli di classificazione portano al rilevamento delle frodi, alla diagnosi medica, ecc. Il processo in due fasi di un modello di classificazione include:
- Apprendimento: viene costruito un modello di classificazione basato sui dati di addestramento.
- Classificazione: l'accuratezza del modello viene verificata e quindi utilizzata per la classificazione dei nuovi dati. Le etichette delle classi sono sotto forma di valori discreti come "sì" o "no", ecc.
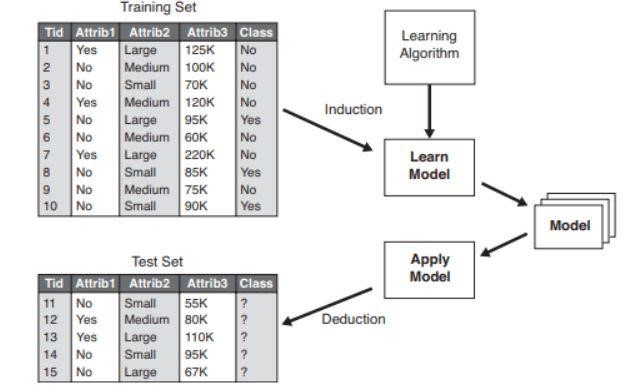
Figura 2 : Esempio di un modello di classificazione .
Fonte
2. Regressione
I modelli di regressione vengono utilizzati per l'analisi di regressione dei dati, ovvero la previsione di attributi numerici. Questi sono anche chiamati valori continui. Pertanto, invece di prevedere le etichette di classe, il modello di regressione prevede i valori continui.
Elenco degli algoritmi utilizzati
Un algoritmo dell'albero decisionale noto come "ID3" è stato sviluppato nel 1980 da un ricercatore di macchine di nome J. Ross Quinlan. Questo algoritmo è stato seguito da altri algoritmi come C4.5 da lui sviluppati. Entrambi gli algoritmi hanno applicato l'approccio avido. L'algoritmo C4.5 non utilizza il backtracking e gli alberi sono costruiti in modo ricorsivo dall'alto verso il basso divide et impera. L'algoritmo ha utilizzato un set di dati di addestramento con etichette di classe che vengono divise in sottoinsiemi più piccoli man mano che l'albero viene costruito.
- Inizialmente vengono selezionati tre parametri: elenco degli attributi, metodo di selezione degli attributi e partizione dei dati. Gli attributi del training set sono descritti nell'elenco degli attributi.
- Il metodo di selezione dell'attribuzione include il metodo per la selezione dell'attributo migliore per la discriminazione tra le tuple.
- Una struttura ad albero dipende dal metodo di selezione degli attributi.
- La costruzione di un albero inizia con un singolo nodo.
- La divisione delle tuple si verifica quando in una tupla sono rappresentate diverse etichette di classe. Questo porterà alla formazione di rami dell'albero.
- Il metodo di suddivisione determina quale attributo deve essere selezionato per la partizione dati. Sulla base di questo metodo, i rami vengono cresciuti da un nodo in base all'esito del test.
- Il metodo di suddivisione e partizionamento viene eseguito in modo ricorsivo, risultando infine in un albero decisionale per le tuple del set di dati di addestramento.
- Il processo di formazione dell'albero continua fino a quando ea meno che le tuple rimaste non possano essere ulteriormente partizionate.
- La complessità dell'algoritmo è indicata da
n * |D| * registro |D|
Dove n è il numero di attributi nel set di dati di addestramento D e |D| è il numero di tuple.
Fonte
Figura 3: una suddivisione del valore discreto
Gli elenchi di algoritmi utilizzati in un albero decisionale sono:
ID3
L'intero insieme di dati S è considerato il nodo radice mentre forma l'albero decisionale. L'iterazione viene quindi eseguita su ogni attributo e la suddivisione dei dati in frammenti. L'algoritmo controlla e prende quegli attributi che non sono stati presi prima di quelli iterati. La suddivisione dei dati nell'algoritmo ID3 richiede tempo e non è un algoritmo ideale in quanto si adatta ai dati.
C4.5
È una forma avanzata di algoritmo in quanto i dati sono classificati come campioni. Sia i valori continui che quelli discreti possono essere gestiti in modo efficiente a differenza di ID3. È presente il metodo di potatura che rimuove i rami indesiderati.
CARRELLO
Sia le attività di classificazione che di regressione possono essere eseguite dall'algoritmo. A differenza di ID3 e C4.5, i punti di decisione vengono creati considerando l'indice di Gini. Un greedy algoritmo viene applicato per il metodo di suddivisione con l'obiettivo di ridurre la funzione di costo. Nelle attività di classificazione, l'indice di Gini viene utilizzato come funzione di costo per indicare la purezza dei nodi foglia. Nelle attività di regressione, l'errore somma al quadrato viene utilizzato come funzione di costo per trovare la migliore previsione.
CAIDO
Come suggerisce il nome, sta per Chi-square Automatic Interaction Detector, un processo che si occupa di qualsiasi tipo di variabile. Possono essere variabili nominali, ordinali o continue. Gli alberi di regressione utilizzano il test F, mentre il test del chi quadrato viene utilizzato nel modello di classificazione.

MARTE
È l'acronimo di Multivariate Adaptive Regression Splines. L'algoritmo è implementato specialmente nelle attività di regressione, in cui i dati sono per lo più non lineari.
Divisione binaria ricorsiva avida
Si verifica un metodo di divisione binaria risultante in due rami. La suddivisione delle tuple viene effettuata con il calcolo della funzione di split cost. Viene selezionata la suddivisione dei costi più bassa e il processo viene eseguito ricorsivamente per calcolare la funzione di costo delle altre tuple.
Albero decisionale con esempio del mondo reale
Prevedi il processo di ammissibilità del prestito dai dati forniti.
Passaggio 1: caricamento dei dati
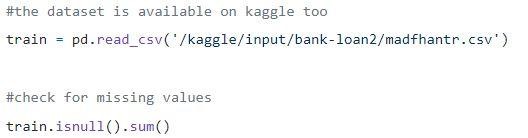
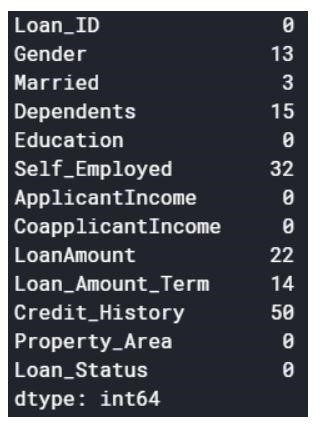
I valori null possono essere eliminati o riempiti con alcuni valori. La forma del set di dati originale era (614,13) e il nuovo set di dati dopo aver eliminato i valori null è (480,13).
Step2: uno sguardo al set di dati.

Passaggio 3: suddivisione dei dati in set di training e test.
Passaggio 4: costruisci il modello e adatta il treno

Prima della visualizzazione devono essere effettuati alcuni calcoli.
Calcolo 1: calcola l'entropia del dataset totale.

Calcolo 2: trova l'entropia e il guadagno per ogni colonna.
- Colonna di genere
- Condizione 1: set di dati con tutti i maschi e poi,
p = 278, n=116 , p+n=489
Entropia(G=Maschio) = 0,87
- Condizione 2: set di dati con tutte le femmine e poi,
p = 54 , n = 32 , p+n = 86
Entropia(G=Femmina) = 0,95
- Informazioni medie nella colonna del genere

- Colonna sposata
- Condizione 1: Sposato = Sì(1)
In questa divisione l'intero set di dati con stato di Coniuge sì
p = 227 , n = 84 , p+n = 311
E(Coniugato = Sì) = 0,84
- Condizione 2: Sposato = No(0)
In questa suddivisione l'intero set di dati con stato di Coniuge n
p = 105 , n = 64 , p+n = 169
E(Sposato = No) = 0,957
- Le informazioni medie nella colonna Sposati sono
- Rubrica didattica
- Condizione 1: Istruzione = Laureato(1)
p = 271 , n = 112 , p+n = 383
E(Istruzione = Laureato) = 0,87
- Condizione 2: Istruzione = Non laureato(0)
p = 61 , n = 36 , p+n = 97
E(Istruzione = Non laureato) = 0,95
- Colonna Informazioni medie sull'istruzione = 0,886
Guadagno = 0,01
4) Colonna di lavoro autonomo
- Condizione 1: lavoratore autonomo = Sì(1)
p = 43 , n = 23 , p+n = 66
E(lavoratore autonomo=sì) = 0,93
- Condizione 2: lavoratore autonomo = No(0)
p = 289 , n = 125 , p+n = 414
E(lavoratore autonomo=no) = 0,88
- Informazioni medie nella colonna dei lavoratori autonomi nell'istruzione = 0,886
Guadagno = 0,01
- Colonna Credit Score: la colonna ha 0 e 1 valore.
- Condizione 1: Punteggio di credito = 1
p = 325 , n = 85 , p+n = 410
E(Punteggio credito = 1) = 0,73
- Condizione 2: Punteggio di credito = 0
p = 63 , n = 7 , p+n = 70
E(Punteggio credito = 0) = 0,46
- Informazioni medie nella colonna Punteggio di credito = 0,69
Guadagno = 0,2
Confronta tutti i valori di guadagno

Il punteggio di credito ha il guadagno più alto. Quindi, verrà utilizzato come nodo radice.
Passaggio 5: visualizzare l'albero decisionale

Figura 5: Albero decisionale con criterio Gini
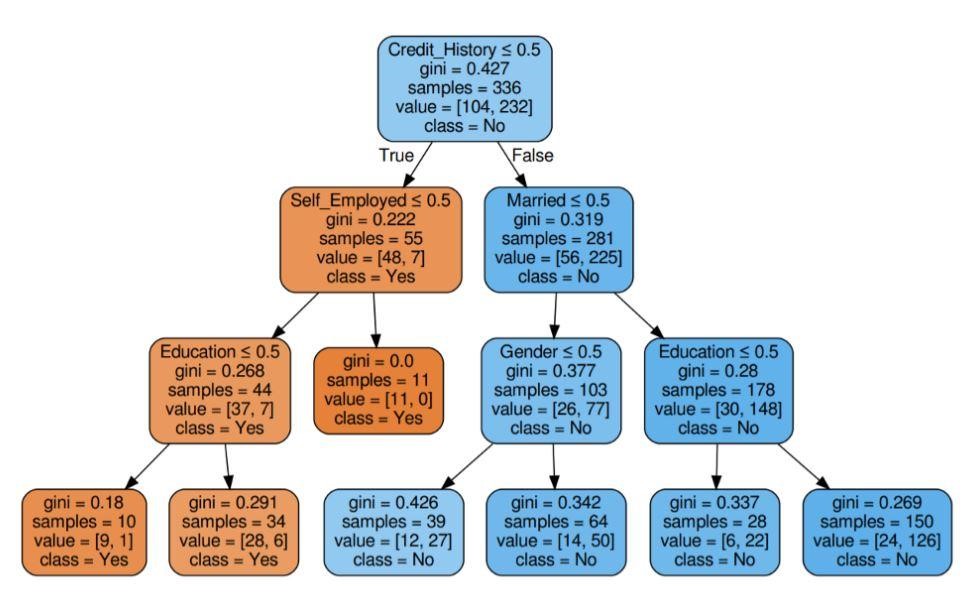 Fonte
Fonte
Figura 6: Albero decisionale con entropia del criterio
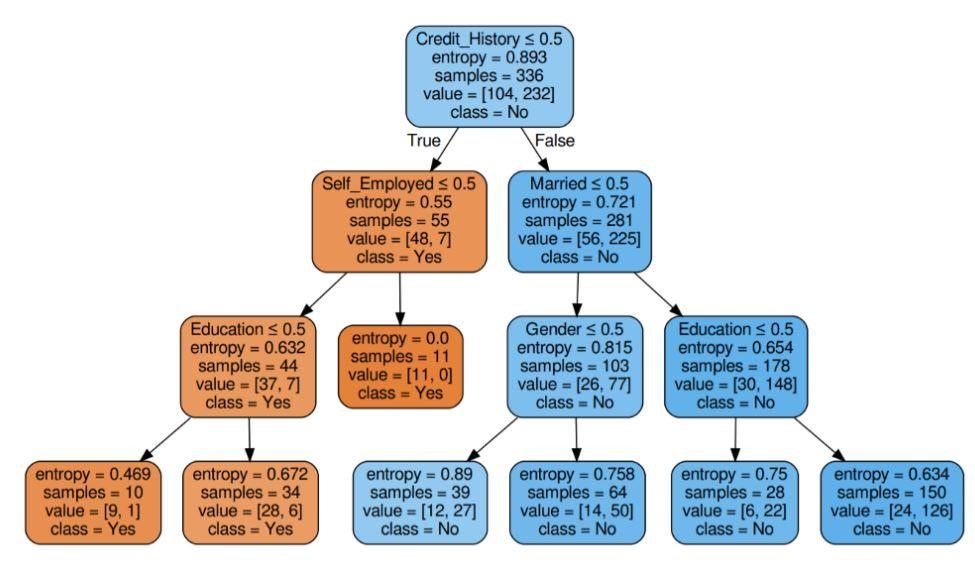
Fonte
Passaggio 6: verifica il punteggio del modello
Punteggio di quasi l'80% di precisione.
Elenco delle applicazioni
Gli alberi decisionali sono utilizzati principalmente dagli esperti di informazioni per condurre un'indagine analitica. Potrebbero essere ampiamente utilizzati per scopi commerciali per analizzare o prevedere difficoltà. La flessibilità dell'albero decisionale consente di utilizzarli in un'area diversa:
1. Sanità
Gli alberi decisionali consentono di prevedere se un paziente soffre di una particolare malattia con condizioni di età, peso, sesso, ecc. Altre previsioni includono la decisione dell'effetto della medicina considerando fattori come composizione, periodo di produzione, ecc.
2. Settori bancari
Gli alberi decisionali aiutano a prevedere se una persona è ammissibile a un prestito considerando la sua situazione finanziaria, lo stipendio, i membri della famiglia, ecc. Può anche identificare frodi con carte di credito, inadempienze del prestito, ecc.
3. Settori educativi
La preselezione di uno studente in base al suo punteggio di merito, frequenza, ecc. può essere decisa con l'aiuto di alberi decisionali.
Elenco dei vantaggi
- I risultati interpretabili di un modello decisionale possono essere rappresentati all'alta dirigenza e agli stakeholder.
- Durante la creazione di un modello di albero decisionale, non è richiesta la preelaborazione dei dati, ovvero la normalizzazione, il ridimensionamento, ecc.
- Entrambi i tipi di dati, numerici e categoriali, possono essere gestiti da un albero decisionale che mostra la sua maggiore efficienza d'uso rispetto ad altri algoritmi.
- Il valore mancante nei dati non influisce sul processo di un albero decisionale, rendendolo così un algoritmo flessibile.
Cosa succede dopo?
Se sei interessato ad acquisire esperienza pratica nel data mining e ad essere formato da esperti in materia, puoi dare un'occhiata al programma Executive PG di upGrad in Data Science. Il corso è rivolto a qualsiasi fascia di età compresa tra i 21 ei 45 anni di età con criteri di ammissibilità minimi del 50% o voti equivalenti alla laurea. Tutti i professionisti che lavorano possono aderire a questo programma PG esecutivo certificato da IIIT Bangalore.
Gli alberi decisionali nel data mining hanno la capacità di gestire dati molto complicati. Tutti gli alberi decisionali hanno tre nodi o porzioni vitali. Discutiamo ciascuno di essi di seguito. Ora che abbiamo compreso il funzionamento degli alberi decisionali, proviamo a guardare alcuni vantaggi dell'utilizzo degli alberi decisionali nel data miningChe cos'è un albero decisionale nel data mining?
Un albero decisionale è un modo per creare modelli nel data mining. Può essere inteso come un albero binario invertito. Include un nodo radice, alcuni rami e nodi foglia alla fine.
Ciascuno dei nodi interni in un albero decisionale indica uno studio su un attributo. Ciascuna delle divisioni indica la conseguenza di quel particolare studio o esame. Infine, ogni nodo foglia rappresenta un tag di classe.
L'obiettivo principale della costruzione di un albero decisionale è creare un ideale che può essere utilizzato per prevedere la classe particolare utilizzando procedure di giudizio sui dati precedenti.
Iniziamo con il nodo radice, creiamo alcune relazioni con la variabile radice e facciamo le divisioni che concordano con quei valori. Sulla base delle scelte di base, si passa ai nodi successivi. Quali sono alcuni dei nodi importanti utilizzati negli alberi decisionali?
Quando colleghiamo tutti questi nodi, otteniamo divisioni. Possiamo formare alberi con una varietà di difficoltà usando questi nodi e divisioni per un numero infinito di volte. Quali sono i vantaggi dell'utilizzo degli alberi decisionali?
1. Quando li confrontiamo con altri metodi, gli alberi decisionali non richiedono tanto calcolo per l'addestramento dei dati durante la pre-elaborazione.
2. La stabilizzazione delle informazioni non è coinvolta negli alberi decisionali.
3. Inoltre, non richiedono nemmeno il ridimensionamento delle informazioni.
4. Anche se alcuni valori vengono omessi nel set di dati, ciò non interferisce nella costruzione degli alberi.
5. Questi modelli sono istintivi identici. Sono privi di stress anche per la descrizione.