
Creazione di abilità vocali per Google Assistant e Amazon Alexa
Pubblicato: 2022-03-10Negli ultimi dieci anni, c'è stato uno spostamento sismico verso le interfacce conversazionali. Man mano che le persone raggiungono lo "schermo di picco" e iniziano persino a ridimensionare l'utilizzo del dispositivo con funzionalità di benessere digitale integrate nella maggior parte dei sistemi operativi.
Per combattere l'affaticamento dello schermo, gli assistenti vocali sono entrati nel mercato per diventare un'opzione preferita per recuperare rapidamente le informazioni. Una statistica ben ripetuta afferma che il 50% delle ricerche sarà effettuato a voce nel 2020. Inoltre, con l'aumento dell'adozione, spetta agli sviluppatori aggiungere "Interfacce di conversazione" e "Assistenti vocali" alla loro cintura degli strumenti.
Progettare l'invisibile
Per molti, intraprendere un progetto di Voice UI (VUI) può essere un po' come entrare nello Sconosciuto. Scopri di più sulle lezioni apprese da William Merrill durante la progettazione per la voce. Leggi un articolo correlato →
Che cos'è un'interfaccia di conversazione?
Un'interfaccia conversazionale (a volte abbreviata in CUI, è qualsiasi interfaccia in un linguaggio umano. È considerata un'interfaccia più naturale per il pubblico in generale rispetto alla GUI dell'interfaccia utente grafica, che gli sviluppatori front-end sono abituati a creare. Una GUI richiede l'essere umano per apprendere le sue sintassi specifiche dell'interfaccia (pulsanti di pensiero, cursori e menu a discesa).
Questa differenza fondamentale nell'uso del linguaggio umano rende la CUI più naturale per le persone; richiede poche conoscenze e pone l'onere della comprensione sul dispositivo.
Comunemente le CUI sono disponibili in due forme: chatbot e assistenti vocali. Entrambi hanno visto un massiccio aumento dell'adozione nell'ultimo decennio grazie ai progressi nell'elaborazione del linguaggio naturale (NLP).
Capire il gergo vocale

| Parola chiave | Significato |
|---|---|
| Abilità/Azione | Un'applicazione vocale, che può soddisfare una serie di intenti |
| Intento | Azione prevista per l'abilità da soddisfare, ciò che l'utente desidera che l'abilità faccia in risposta a ciò che dice. |
| Espressione | La frase che un utente dice o pronuncia. |
| Sveglia Parola | La parola o la frase utilizzata per avviare l'ascolto di un assistente vocale, ad esempio "Ehi google", "Alexa" o "Ehi Siri" |
| Contesto | Le informazioni contestuali all'interno di un enunciato, che aiutano l'abilità a realizzare un intento, ad esempio "oggi", "adesso", "quando torno a casa". |
Che cos'è un assistente vocale?
Un assistente vocale è un software capace di NLP (Natural Language Processing). Riceve un comando vocale e restituisce una risposta in formato audio. Negli ultimi anni l'ambito di come interagire con un assistente si sta espandendo e si sta evolvendo, ma il punto cruciale della tecnologia è il linguaggio naturale, un sacco di calcoli, il linguaggio naturale fuori.
Per chi cerca qualche dettaglio in più:
- Il software riceve una richiesta audio da un utente, elabora il suono in fonemi, i mattoni del linguaggio.
- Grazie alla magia dell'IA (Specifically Speech-To-Text), questi fonemi vengono convertiti in una stringa della richiesta approssimata, questa viene conservata all'interno di un file JSON che contiene anche informazioni extra sull'utente, la richiesta e la sessione.
- Il JSON viene quindi elaborato (di solito nel cloud) per elaborare il contesto e l'intento della richiesta.
- In base all'intento, viene restituita una risposta, sempre all'interno di una risposta JSON più grande, come stringa o come SSML (ne parleremo più avanti)
- La risposta viene elaborata utilizzando l'IA (naturalmente il contrario - Sintesi vocale) che viene quindi restituita all'utente.
C'è molto da fare, la maggior parte delle quali non richiede un secondo pensiero. Ma ogni piattaforma lo fa in modo diverso e sono le sfumature della piattaforma che richiedono un po' più di comprensione.

Dispositivi abilitati alla voce
I requisiti per un dispositivo per poter avere un assistente vocale integrato sono piuttosto bassi. Richiedono un microfono, una connessione Internet e un altoparlante. Gli altoparlanti intelligenti come Nest Mini ed Echo Dot offrono questo tipo di controllo vocale a bassa fedeltà.
Il prossimo in classifica è voce + schermo, questo è noto come un dispositivo "multimodale" (ne parleremo più avanti) e sono dispositivi come Nest Hub e Echo Show. Poiché gli smartphone hanno questa funzionalità, possono anche essere considerati un tipo di dispositivo multimodale abilitato alla voce.
Abilità vocali
Prima di tutto, ogni piattaforma ha un nome diverso per le loro "Competenze vocali", Amazon va con le abilità, che rimarrò con un termine universalmente compreso. Google opta per "Azioni" e Samsung per "capsule".
Ogni piattaforma ha le sue abilità intrinseche, come chiedere l'ora, il tempo e i giochi sportivi. Le competenze dello sviluppatore (di terze parti) possono essere invocate con una frase specifica o, se la piattaforma lo desidera, possono essere invocate implicitamente, senza una frase chiave.
Invocazione esplicita : "Ok Google, parla con <nome app>".
Viene esplicitamente indicato quale abilità viene richiesta:
Invocazione implicita : "Ehi Google, com'è il tempo oggi?"
È implicito nel contesto della richiesta quale servizio desidera l'utente.
Quali assistenti vocali ci sono?
Nel mercato occidentale, gli assistenti vocali sono una corsa a tre cavalli. Apple, Google e Amazon hanno approcci molto diversi ai loro assistenti e, in quanto tali, si rivolgono a diversi tipi di sviluppatori e clienti.
Siri di Apple
Nome dispositivo : "Siri"
Frase di risveglio : "Ehi Siri"
Siri ha oltre 375 milioni di utenti attivi, ma per brevità, non entrerò troppo nel dettaglio di Siri. Sebbene possa essere globalmente ben adottato e integrato nella maggior parte dei dispositivi Apple, richiede agli sviluppatori di avere già un'app su una delle piattaforme Apple ed è scritto in swift (mentre gli altri possono essere scritti nel preferito da tutti: Javascript). A meno che tu non sia uno sviluppatore di app che desidera espandere l'offerta della propria app, al momento puoi saltare Apple fino a quando non aprono la loro piattaforma.
Assistente Google
Nomi dei dispositivi : "Google Home, Nest"
Frase di attivazione : "Ehi Google"
Google ha il maggior numero di dispositivi dei tre grandi, con oltre 1 miliardo in tutto il mondo, ciò è dovuto principalmente alla massa di dispositivi Android che hanno l'Assistente Google integrato, per quanto riguarda i loro altoparlanti intelligenti dedicati, i numeri sono un po' più piccoli. La missione generale di Google con il suo assistente è quella di deliziare gli utenti e sono sempre stati molto bravi a fornire interfacce leggere e intuitive.
Il loro obiettivo principale sulla piattaforma è utilizzare il tempo, con l'idea di diventare una parte regolare della routine quotidiana dei clienti. In quanto tali, si concentrano principalmente sull'utilità, sul divertimento in famiglia e sulle esperienze deliziose.
Le competenze sviluppate per Google sono le migliori quando si tratta di pezzi e giochi di fidanzamento, incentrati principalmente sul divertimento adatto alle famiglie. La loro recente aggiunta di tele per i giochi è una testimonianza di questo approccio. La piattaforma Google è molto più rigida per l'invio di competenze e, in quanto tale, la loro directory è molto più piccola.
Amazon Alexa
Nomi dei dispositivi : "Amazon Fire, Amazon Echo"
Frase di risveglio : "Alexa"
Amazon ha superato i 100 milioni di dispositivi nel 2019, ciò deriva principalmente dalle vendite dei suoi altoparlanti intelligenti e display intelligenti, nonché dalla loro gamma "fuoco" o tablet e dispositivi di streaming.
Le competenze sviluppate per Amazon tendono ad essere mirate all'acquisto di competenze. Se stai cercando una piattaforma per espandere il tuo e-commerce/servizio o offrire un abbonamento, Amazon fa per te. Detto questo, l'ISP non è un requisito per Alexa Skills, supportano tutti i tipi di usi e sono molto più aperti agli invii.
Gli altri
Ci sono ancora più assistenti vocali là fuori, come Bixby di Samsung, Cortana di Microsoft e il popolare assistente vocale open source Mycroft. Tutti e tre hanno un discreto seguito, ma sono ancora in minoranza rispetto ai tre Golia di Amazon, Google e Apple.
Basandosi su Amazon Alexa
L'ecosistema per la voce di Amazon si è evoluto per consentire agli sviluppatori di sviluppare tutte le proprie competenze all'interno della console Alexa, quindi, come semplice esempio, utilizzerò le sue funzionalità integrate.
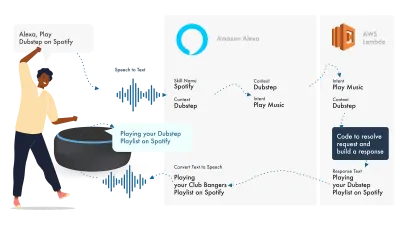
Alexa si occupa dell'elaborazione del linguaggio naturale e quindi trova un Intento appropriato, che viene passato alla nostra funzione Lambda per gestire la logica. Questo restituisce alcuni bit di conversazione (SSML, testo, schede e così via) ad Alexa, che converte quei bit in audio e immagini da mostrare sul dispositivo.
Lavorare su Amazon è relativamente semplice, poiché ti consentono di creare tutte le parti delle tue abilità all'interno della Console per gli sviluppatori Alexa. La flessibilità è disponibile per utilizzare AWS o un endpoint HTTPS, ma per competenze semplici, eseguire tutto all'interno della console Dev dovrebbe essere sufficiente.
Costruiamo una semplice abilità Alexa
Vai alla console Amazon Alexa, crea un account se non ne hai uno e accedi,
Fai clic su Create Skill , quindi assegnagli un nome,
Scegli custom come tuo modello,
e scegli Alexa-Hosted (Node.js) come risorsa di back-end.
Una volta terminato il provisioning, avrai un'abilità di base di Alexa, avrai il tuo intento creato per te e del codice back-end per iniziare.
Se fai clic su HelloWorldIntent nei tuoi intenti, vedrai alcune espressioni di esempio già impostate per te, aggiungiamone una nuova in alto. La nostra abilità si chiama ciao mondo, quindi aggiungi Hello World come espressione di esempio. L'idea è di catturare tutto ciò che l'utente potrebbe dire per attivare questo intento. Questo potrebbe essere "Hi World", "Howdy World" e così via.
Cosa sta succedendo in The Fulfillment JS?
Allora cosa sta facendo il codice? Ecco il codice predefinito:
const HelloWorldIntentHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'IntentRequest' && Alexa.getIntentName(handlerInput.requestEnvelope) === 'HelloWorldIntent'; }, handle(handlerInput) { const speakOutput = 'Hello World!'; return handlerInput.responseBuilder .speak(speakOutput) .getResponse(); } }; Questo sta utilizzando ask-sdk-core e sta essenzialmente costruendo JSON per noi. canHandle sta facendo sapere a ask che può gestire gli intenti, in particolare "HelloWorldIntent". handle prende l'input e costruisce la risposta. Ciò che genera è simile a questo:

{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }
Possiamo vedere che speak emette ssml nel nostro json, che è ciò che l'utente sentirà come parlato da Alexa.
Costruire per l'Assistente Google
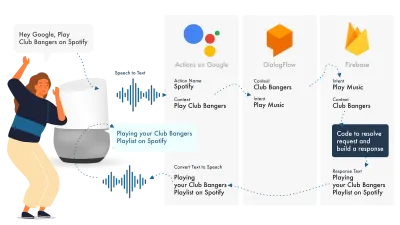
Il modo più semplice per creare Actions su Google è utilizzare la loro console AoG in combinazione con Dialogflow, puoi estendere le tue abilità con Firebase, ma come con il tutorial Amazon Alexa, manteniamo le cose semplici.
Google Assistant utilizza tre parti principali, AoG, che si occupa della NLP, Dialogflow, che elabora le tue intenzioni e Firebase, che soddisfa la richiesta e produce la risposta che verrà rispedita ad AoG.
Proprio come con Alexa, Dialogflow ti consente di creare le tue funzioni direttamente all'interno della piattaforma.
Costruiamo un'azione su Google
Ci sono tre piattaforme per destreggiarsi contemporaneamente con la soluzione di Google, a cui si accede da tre diverse console, quindi fai un salto!
Impostazione del flusso di dialogo
Iniziamo accedendo alla console di Dialogflow. Dopo aver effettuato l'accesso, crea un nuovo agente dal menu a discesa appena sotto il logo Dialogflow.
Assegna un nome al tuo agente e aggiungi il "Google Project Dropdown", mentre hai selezionato "Crea un nuovo progetto Google".
Fai clic sul pulsante Crea e lascia che faccia la sua magia, ci vorrà un po' di tempo per configurare l'agente, quindi sii paziente.
Configurazione delle funzioni Firebase
Bene, ora possiamo iniziare a collegare la logica di Adempimento.
Vai alla scheda Adempimento. Spunta per abilitare l'editor inline e usa gli snippet JS di seguito:
index.js
'use strict'; // So that you have access to the dialogflow and conversation object const { dialogflow } = require('actions-on-google'); // So you have access to the request response stuff >> functions.https.onRequest(app) const functions = require('firebase-functions'); // Create an instance of dialogflow for your app const app = dialogflow({debug: true}); // Build an intent to be fulfilled by firebase, // the name is the name of the intent that dialogflow passes over app.intent('Default Welcome Intent', (conv) => { // Any extra logic goes here for the intent, before returning a response for firebase to deal with return conv.ask(`Welcome to a firebase fulfillment`); }); // Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);pacchetto.json
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": { "lint": "eslint .", "serve": "firebase serve --only functions", "shell": "firebase functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "10" }, "dependencies": { "actions-on-google": "^2.12.0", "firebase-admin": "~7.0.0", "firebase-functions": "^3.3.0" }, "devDependencies": { "eslint": "^5.12.0", "eslint-plugin-promise": "^4.0.1", "firebase-functions-test": "^0.1.6" }, "private": true }Ora torna alle tue intenzioni, vai a Intento di benvenuto predefinito e scorri verso il basso fino a Realizzazione, assicurati che "Abilita chiamata webhook per questo intento" sia selezionato per tutti gli intenti che desideri soddisfare con javascript. Premi Salva.
Configurazione di AoG
Ormai ci stiamo avvicinando al traguardo. Vai alla scheda Integrazioni e fai clic su Impostazioni integrazione nell'opzione Assistente Google in alto. Questo aprirà un modale, quindi facciamo clic su test, che integrerà il tuo Dialogflow con Google e aprirà una finestra di test su Actions on Google.
Nella finestra di test, possiamo fare clic su Parla con la mia app di test (lo cambieremo in un secondo) e voilà, abbiamo il messaggio del nostro javascript visualizzato su un test dell'assistente di Google.
Possiamo cambiare il nome dell'assistente nella scheda Sviluppo, in alto.
Allora, cosa sta succedendo in The Fulfillment JS?
Prima di tutto, stiamo usando due pacchetti npm, actions-on-google che fornisce tutto l'adempimento di cui hanno bisogno sia AoG che Dialogflow, e in secondo luogo firebase-functions, che hai indovinato, contiene helper per firebase.
Quindi creiamo l '"app" che è un oggetto che contiene tutti i nostri intenti.
Ogni intento creato ha superato "conv", che è l'oggetto conversazione inviato da Actions On Google. Possiamo utilizzare il contenuto di conv per rilevare informazioni sulle interazioni precedenti con l'utente (come il suo ID e le informazioni sulla sua sessione con noi).
Restituiamo un "oggetto conv.ask", che contiene il nostro messaggio di ritorno all'utente, pronto per rispondere con un altro intento. Potremmo usare "conv.close" per terminare la conversazione se volessimo terminare la conversazione lì.
Infine, racchiudiamo tutto in una funzione HTTPS firebase, che si occupa della logica richiesta-risposta lato server per noi.
Ancora una volta, se osserviamo la risposta che viene generata:
{ "payload": { "google": { "expectUserResponse": true, "richResponse": { "items": [ { "simpleResponse": { "textToSpeech": "Welcome to a firebase fulfillment" } } ] } } } } Possiamo vedere che conv.ask ha il suo testo iniettato nell'area textToSpeech . Se avessimo scelto conv.close , expectUserResponse sarebbe impostato su false e la conversazione si chiuderebbe dopo che il messaggio è stato consegnato.
Costruttori di voci di terze parti
Proprio come il settore delle app, man mano che la voce guadagna terreno, gli strumenti di terze parti hanno iniziato a spuntare nel tentativo di alleviare il carico sugli sviluppatori, consentendo loro di creare una distribuzione due volte.
Jovo e Voiceflow sono attualmente i due più popolari, soprattutto dopo l'acquisizione di PullString da parte di Apple. Ogni piattaforma offre un diverso livello di astrazione, quindi dipende solo da quanto sei semplificato come la tua interfaccia.
Estendere la tua abilità
Ora che hai capito come costruire un'abilità di base "Hello World", ci sono campane e fischietti in abbondanza che possono essere aggiunti alla tua abilità. Questi sono la ciliegina sulla torta degli assistenti vocali e daranno ai tuoi utenti molto valore extra, portando a ripetere opportunità commerciali personalizzate e potenziali.
SSML
SSML sta per linguaggio di marcatura della sintesi vocale e opera con una sintassi simile all'HTML, la differenza fondamentale è che stai creando una risposta vocale, non contenuto su una pagina web.
'SSML' come termine è un po' fuorviante, può fare molto di più della sintesi vocale! Puoi fare in modo che le voci vadano in parallelo, puoi includere rumori d'ambiente, discorsi (vale la pena ascoltarli di per sé, pensare agli emoji per frasi famose) e musica.
Quando dovrei usare SSML?
SSML è fantastico; rende un'esperienza molto più coinvolgente per l'utente, ma ciò che fa anche è ridurre la flessibilità dell'uscita audio. Consiglio di usarlo per aree di discorso più statiche. Puoi usare le variabili in esso per i nomi, ecc, ma a meno che tu non intenda creare un generatore di SSML, la maggior parte di SSML sarà piuttosto statica.
Inizia con un discorso semplice nelle tue abilità e, una volta completato, migliora le aree che sono più statiche con SSML, ma ottieni il tuo core giusto prima di passare ai campanelli e ai fischietti. Detto questo, un recente rapporto afferma che il 71% degli utenti preferisce una voce umana (reale) a una sintetizzata, quindi se hai la possibilità di farlo, esci e fallo!

In Acquisti di abilità
Gli acquisti in-skill (o ISP) sono simili al concetto di acquisti in-app. Le abilità tendono ad essere gratuite, ma alcune consentono l'acquisto di contenuti/abbonamenti "premium" all'interno dell'app, questi possono migliorare l'esperienza per un utente, sbloccare nuovi livelli nei giochi o consentire l'accesso a contenuti con paywall.
Multimodale
Le risposte multimodali coprono molto più della voce, è qui che gli assistenti vocali possono davvero brillare con elementi visivi complementari sui dispositivi che li supportano. La definizione di esperienze multimodali è molto più ampia e significa essenzialmente input multipli (tastiera, mouse, touchscreen, voce e così via).
Le abilità multimodali hanno lo scopo di integrare l'esperienza vocale principale, fornendo informazioni complementari aggiuntive per migliorare l'esperienza utente. Quando costruisci un'esperienza multimodale, ricorda che la voce è il principale vettore di informazioni. Molti dispositivi non hanno uno schermo, quindi la tua abilità deve ancora funzionare senza uno, quindi assicurati di testare con più tipi di dispositivi; sia per davvero o nel simulatore.

Multilingue
Le abilità multilingue sono abilità che funzionano in più lingue e aprono le tue abilità a più mercati.
La complessità di rendere multilingue le tue abilità dipende dalla dinamica delle tue risposte. Le abilità con risposte relativamente statiche, ad esempio restituire la stessa frase ogni volta, o usare solo un piccolo secchio di frasi, sono molto più facili da rendere multilingue rispetto alle abilità dinamiche tentacolari.
Il trucco con il multilingue è avere un partner di traduzione affidabile, che sia tramite un'agenzia o un traduttore su Fiverr. Devi essere in grado di fidarti delle traduzioni fornite, soprattutto se non capisci la lingua in cui viene tradotta. Google Translate non taglierà la senape qui!
Conclusione
Se mai ci fosse un momento per entrare nel settore della voce, sarebbe adesso. Sia nella sua prima infanzia che nella sua infanzia, così come i grandi nove, stanno investendo miliardi per farla crescere e portare gli assistenti vocali nelle case e nella routine quotidiana di tutti.
Scegliere quale piattaforma utilizzare può essere complicato, ma in base a ciò che intendi costruire, la piattaforma da utilizzare dovrebbe brillare o, in caso contrario, utilizzare uno strumento di terze parti per coprire le tue scommesse e costruire su più piattaforme, soprattutto se la tua abilità è meno complicato con meno parti mobili.
Io, per esempio, sono entusiasta del futuro della voce man mano che diventa onnipresente; l'affidamento allo schermo si ridurrà e i clienti potranno interagire in modo naturale con il proprio assistente. Ma prima, sta a noi sviluppare le competenze che le persone vorranno dal loro assistente.