
Comprensione dei generici TypeScript
Pubblicato: 2022-03-10In questo articolo, impareremo il concetto di generici in TypeScript ed esamineremo come i generici possono essere utilizzati per scrivere codice modulare, disaccoppiato e riutilizzabile. Lungo il percorso, discuteremo brevemente di come si adattano a modelli di test migliori, approcci alla gestione degli errori e separazione dominio/accesso ai dati.
Un esempio del mondo reale
Voglio entrare nel mondo dei generici non spiegando cosa sono, ma fornendo un esempio intuitivo del perché sono utili. Supponiamo che ti sia stato assegnato il compito di creare un elenco dinamico ricco di funzionalità. Potresti chiamarlo un array, un ArrayList , un List , uno std::vector o qualsiasi altra cosa, a seconda del tuo background linguistico. Forse questa struttura dati deve avere anche sistemi di buffer integrati o sostituibili (come un'opzione di inserimento del buffer circolare). Sarà un wrapper attorno al normale array JavaScript in modo da poter lavorare con la nostra struttura invece di semplici array.
Il problema immediato che incontrerai è quello dei vincoli imposti dal sistema dei tipi. Non puoi, a questo punto, accettare qualsiasi tipo tu voglia in una funzione o in un metodo in modo pulito (rivisiteremo questa affermazione più avanti).
L'unica soluzione ovvia è replicare la nostra struttura dati per tutti i diversi tipi:
const intList = IntegerList.create(); intList.add(4); const stringList = StringList.create(); stringList.add('hello'); const userList = UserList.create(); userList.add(new User('Jamie')); La sintassi .create() qui potrebbe sembrare arbitraria e, in effetti, new SomethingList() sarebbe più semplice, ma vedrai perché usiamo questo metodo di fabbrica statico in seguito. Internamente, il metodo create chiama il costruttore.
È terribile. Abbiamo molta logica all'interno di questa struttura di raccolta e la duplichiamo palesemente per supportare diversi casi d'uso, infrangendo completamente il principio DRY nel processo. Quando decidiamo di modificare la nostra implementazione, dovremo propagare/riflettere manualmente tali modifiche su tutte le strutture e i tipi che supportiamo, inclusi i tipi definiti dall'utente, come nell'ultimo esempio sopra. Supponiamo che la struttura della raccolta stessa fosse lunga 100 righe: sarebbe un incubo mantenere più implementazioni diverse in cui l'unica differenza tra loro sono i tipi.
Una soluzione immediata che potrebbe venire in mente, soprattutto se hai una mentalità OOP, è considerare un "supertipo" radice, se lo desideri. In C#, ad esempio, è costituito un tipo dal nome di object e object è un alias per la classe System.Object . Nel sistema dei tipi di C#, tutti i tipi, siano essi predefiniti o definiti dall'utente e siano tipi di riferimento o tipi di valore, ereditano direttamente o indirettamente da System.Object . Ciò significa che qualsiasi valore può essere assegnato a una variabile di tipo object (senza entrare nella semantica stack/heap e boxing/unboxing).
In questo caso, il nostro problema sembra risolto. Possiamo semplicemente usare un tipo come any e che ci permetterà di archiviare tutto ciò che vogliamo all'interno della nostra raccolta senza dover duplicare la struttura, e in effetti, è molto vero:
const intList = AnyList.create(); intList.add(4); const stringList = AnyList.create(); stringList.add('hello'); const userList = AnyList.create(); userList.add(new User('Jamie')); Diamo un'occhiata all'effettiva implementazione del nostro elenco utilizzando any :
class AnyList { private values: any[] = []; private constructor (values: any[]) { this.values = values; // Some more construction work. } public add(value: any): void { this.values.push(value); } public where(predicate: (value: any) => boolean): AnyList { return AnyList.from(this.values.filter(predicate)); } public select(selector: (value: any) => any): AnyList { return AnyList.from(this.values.map(selector)); } public toArray(): any[] { return this.values; } public static from(values: any[]): AnyList { // Perhaps we perform some logic here. // ... return new AnyList(values); } public static create(values?: any[]): AnyList { return new AnyList(values ?? []); } // Other collection functions. // ... }Tutti i metodi sono relativamente semplici, ma inizieremo con il costruttore. La sua visibilità è privata, poiché assumiamo che il nostro elenco sia complesso e desideriamo impedire la costruzione arbitraria. Potremmo anche voler eseguire la logica prima della costruzione, quindi per questi motivi, e per mantenere puro il costruttore, deleghiamo queste preoccupazioni a metodi factory/helper statici, che è considerata una buona pratica.
Vengono forniti i metodi statici from e create . Il metodo from accetta una matrice di valori, esegue una logica personalizzata e quindi li usa per costruire l'elenco. Il metodo create static accetta una matrice facoltativa di valori nel caso in cui desideriamo seminare il nostro elenco con i dati iniziali. L'"operatore di coalescenza nullo" ( ?? ) viene utilizzato per costruire l'elenco con un array vuoto nel caso in cui non ne venga fornito uno. Se il lato sinistro dell'operando è null o undefined , torneremo al lato destro, poiché in questo caso values sono facoltativi e quindi potrebbero essere undefined . Puoi saperne di più sulla coalescenza nulla nella pagina della documentazione di TypeScript pertinente.
Ho anche aggiunto un metodo select e where . Questi metodi avvolgono semplicemente la map e il filter di JavaScript rispettivamente. select ci consente di proiettare una matrice di elementi in una nuova forma basata sulla funzione di selezione fornita e where ci consente di filtrare alcuni elementi in base alla funzione di predicato fornita. Il metodo toArray converte semplicemente l'elenco in un array restituendo il riferimento all'array che conserviamo internamente.
Infine, supponiamo che la classe User contenga un metodo getName che restituisce un nome e accetta anche un nome come primo e unico argomento del costruttore.
Nota: alcuni lettori riconoscerannoWhereandSelectda LINQ di C#, ma tieni presente che sto cercando di mantenerlo semplice, quindi non sono preoccupato per la pigrizia o l'esecuzione posticipata. Queste sono ottimizzazioni che potrebbero e dovrebbero essere fatte nella vita reale.
Inoltre, come nota interessante, voglio discutere il significato di “predicato”. In Matematica Discreta e Logica Proposizionale, abbiamo il concetto di "proposizione". Una proposizione è un'affermazione che può essere considerata vera o falsa, come "quattro è divisibile per due". Un "predicato" è una proposizione che contiene una o più variabili, quindi la veridicità della proposizione dipende da quella di quelle variabili. Puoi pensarla come una funzione, comeP(x) = x is divisible by two, perché abbiamo bisogno di conoscere il valore dixper determinare se l'affermazione è vera o falsa. Puoi saperne di più sulla logica dei predicati qui.
Ci sono alcuni problemi che sorgeranno dall'uso di any . Il compilatore TypeScript non sa nulla degli elementi all'interno dell'elenco/array interno, quindi non fornirà alcun aiuto all'interno di where o select o quando si aggiungono elementi:
// Providing seed data. const userList = AnyList.create([new User('Jamie')]); // This is fine and expected. userList.add(new User('Tom')); userList.add(new User('Alice')); // This is an acceptable input to the TS Compiler, // but it's not what we want. We'll definitely // be surprised later to find strings in a list // of users. userList.add('Hello, World!'); // Also acceptable. We have a large tuple // at this point rather than a homogeneous array. userList.add(0); // This compiles just fine despite the spelling mistake (extra 's'): // The type of `users` is any. const users = userList.where(user => user.getNames() === 'Jamie'); // Property `ssn` doesn't even exist on a `user`, yet it compiles. users.toArray()[0].ssn = '000000000'; // `usersWithId` is, again, just `any`. const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Oops, it's "id" not "ID", but TS doesn't help us. // We compile just fine. console.log(usersWithId.toArray()[0].ID); Poiché TypeScript sa solo che il tipo di tutti gli elementi dell'array è any , non può aiutarci in fase di compilazione con le proprietà inesistenti o la funzione getNames che non esiste nemmeno, quindi questo codice risulterà in più errori di runtime imprevisti .
Ad essere onesti, le cose stanno cominciando a sembrare piuttosto tristi. Abbiamo provato a implementare la nostra struttura dati per ogni tipo concreto che desideravamo supportare, ma ci siamo subito resi conto che non era in alcun modo gestibile. Quindi, abbiamo pensato di arrivare da qualche parte usando any , che è analogo al dipendere da un supertipo radice in una catena di ereditarietà da cui derivano tutti i tipi, ma abbiamo concluso che perdiamo la sicurezza del tipo con quel metodo. Qual è la soluzione, allora?
Si scopre che, all'inizio dell'articolo, ho mentito (una specie di):
"Non puoi, a questo punto, accettare qualsiasi tipo tu voglia in una funzione o in un metodo in modo pulito."
In realtà puoi, ed è qui che entrano in gioco i generici. Notare che ho detto "a questo punto", perché presumevo che non sapessimo dei generici a quel punto dell'articolo.
Inizierò mostrando la piena implementazione della nostra struttura List con Generics, quindi faremo un passo indietro, discuteremo di cosa sono effettivamente e determineremo la loro sintassi in modo più formale. L'ho chiamato TypedList per differenziarlo dal nostro precedente AnyList :
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. }Proviamo a fare gli stessi errori di prima ancora una volta:
// Here's the magic. `TypedList` will operate on objects // of type `User` due to the `<User>` syntax. const userList = TypedList.create<User>([new User('Jamie')]); // The compiler expects this. userList.add(new User('Tom')); userList.add(new User('Alice')); // Argument of type '0' is not assignable to parameter // of type 'User'. ts(2345) userList.add(0); // Property 'getNames' does not exist on type 'User'. // Did you mean 'getName'? ts(2551) // Note: TypeScript infers the type of `users` to be // `TypedList<User>` const users = userList.where(user => user.getNames() === 'Jamie'); // Property 'ssn' does not exist on type 'User'. ts(2339) users.toArray()[0].ssn = '000000000'; // TypeScript infers `usersWithId` to be of type // `TypedList<`{ id: string, name: string }> const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Property 'ID' does not exist on type '{ id: string; name: string; }'. // Did you mean 'id'? ts(2551) console.log(usersWithId.toArray()[0].ID)Come puoi vedere, il compilatore TypeScript ci sta aiutando attivamente con la sicurezza dei tipi. Tutti questi commenti sono errori che ricevo dal compilatore durante il tentativo di compilare questo codice. I generici ci hanno permesso di specificare un tipo su cui desideriamo consentire al nostro elenco di operare, e da quello, TypeScript può dire i tipi di tutto, fino alle proprietà dei singoli oggetti all'interno dell'array.
I tipi che forniamo possono essere semplici o complessi come vogliamo che siano. Qui puoi vedere che possiamo passare sia le primitive che le interfacce complesse. Potremmo anche passare altri array, classi o altro:
const numberList = TypedList.create<number>(); numberList.add(4); const stringList = TypedList.create<string>(); stringList.add('Hello, World'); // Example of a complex type interface IAircraft { apuStatus: ApuStatus; inboardOneRPM: number; altimeter: number; tcasAlert: boolean; pushBackAndStart(): Promise<void>; ilsCaptureGlidescope(): boolean; getFuelStats(): IFuelStats; getTCASHistory(): ITCASHistory; } const aircraftList = TypedList.create<IAircraft>(); aircraftList.add(/* ... */); // Aggregate and generate report: const stats = aircraftList.select(a => ({ ...a.getFuelStats(), ...a.getTCASHistory() })); Gli usi peculiari di T e U e <T> e <U> nell'implementazione TypedList<T> sono esempi di generici in azione. Dopo aver soddisfatto la nostra direttiva di costruire una struttura di raccolta indipendente dai tipi, per ora lasceremo questo esempio alle spalle e ci torneremo una volta che avremo compreso cosa sono effettivamente i generici, come funzionano e la loro sintassi. Quando sto imparando un nuovo concetto, mi piace sempre iniziare vedendo un esempio complesso del concetto in uso, in modo che quando comincio ad imparare le basi, posso stabilire connessioni tra gli argomenti di base e l'esempio esistente che ho nel mio testa.
Cosa sono i generici?
Un modo semplice per comprendere i generici consiste nel considerarli relativamente analoghi ai segnaposto o alle variabili tranne che per i tipi. Questo non vuol dire che puoi eseguire le stesse operazioni su un segnaposto di tipo generico come puoi fare con una variabile, ma una variabile di tipo generico potrebbe essere considerata come un segnaposto che rappresenta un tipo concreto che verrà utilizzato in futuro. Cioè, l'uso di Generics è un metodo per scrivere programmi in termini di tipi che devono essere specificati in un secondo momento. Il motivo per cui questo è utile è perché ci consente di costruire strutture di dati che sono riutilizzabili nei diversi tipi su cui operano (o indipendenti dal tipo).
Questa non è particolarmente la migliore delle spiegazioni, quindi per dirla in termini più semplici, come abbiamo visto, è comune nella programmazione che potremmo aver bisogno di costruire una struttura di funzione/classe/dati che opererà su un certo tipo, ma è altrettanto comune che una tale struttura di dati debba funzionare anche su una varietà di tipi diversi. Se fossimo bloccati in una posizione in cui dovessimo dichiarare staticamente il tipo concreto su cui una struttura dati opererebbe nel momento in cui progettiamo la struttura dati (in fase di compilazione), scopriremmo molto rapidamente che dobbiamo ricostruire quelli strutture in modo quasi identico per ogni tipo che desideriamo supportare, come abbiamo visto negli esempi precedenti.
I generici ci aiutano a risolvere questo problema permettendoci di differire il requisito per un tipo concreto fino a quando non sia effettivamente noto.
Generici in dattiloscritto
Ora abbiamo un'idea in qualche modo organica del motivo per cui i generici sono utili e ne abbiamo visto un esempio leggermente complicato in pratica. Per la maggior parte, l' TypedList<T> probabilmente ha già molto senso, specialmente se provieni da un background linguistico tipizzato staticamente, ma ricordo di aver avuto difficoltà a capire il concetto quando stavo imparando per la prima volta, quindi voglio costruire fino a quell'esempio iniziando con funzioni semplici. I concetti relativi all'astrazione nel software possono essere notoriamente difficili da interiorizzare, quindi se la nozione di generici non ha ancora fatto clic, va benissimo e, si spera, alla fine di questo articolo, l'idea sarà almeno in qualche modo intuitiva.
Per essere in grado di comprendere quell'esempio, elaboriamo da semplici funzioni. Inizieremo con la "Funzione di identità", che è ciò che la maggior parte degli articoli, inclusa la stessa documentazione di TypeScript, ama usare.
Una "funzione di identità", in matematica, è una funzione che mappa il suo input direttamente sul suo output, come f(x) = x . Quello che metti dentro è quello che esci. Possiamo rappresentarlo, in JavaScript, come:
function identity(input) { return input; }Oppure, più concisamente:
const identity = input => input; Il tentativo di portarlo su TypeScript riporta gli stessi problemi di sistema di tipo che abbiamo visto prima. Le soluzioni stanno digitando con any , che sappiamo è raramente una buona idea, duplicando/sovraccaricando la funzione per ogni tipo (interrompe DRY) o usando Generics.
Con quest'ultima opzione, possiamo rappresentare la funzione come segue:
// ES5 Function function identity<T>(input: T): T { return input; } // Arrow Function const identity = <T>(input: T): T => input; console.log(identity<number>(5)); // 5 console.log(identity<string>('hello')); // hello La sintassi <T> qui dichiara questa funzione come generica. Proprio come una funzione ci consente di passare un parametro di input arbitrario nella sua lista di argomenti, con una funzione generica, possiamo anche passare un parametro di tipo arbitrario.
La parte <T> della firma di identity<T>(input: T): T e <T>(input: T): T in entrambi i casi dichiara che la funzione in questione accetterà un parametro di tipo generico denominato T . Proprio come le variabili possono avere qualsiasi nome, così possono fare i nostri segnaposto generici, ma è una convenzione usare una lettera maiuscola "T" ("T" per "Tipo") e spostarsi verso il basso nell'alfabeto secondo necessità. Ricorda, T è un tipo, quindi affermiamo anche che accetteremo un argomento di funzione di nome input con un tipo di T e che la nostra funzione restituirà un tipo di T . Questo è tutto ciò che dice la firma. Prova a lasciare T = string nella tua testa: sostituisci tutte le T con string in quelle firme. Vedi come non succede niente di tutto ciò che di magico? Vedi quanto è simile al modo non generico in cui usi le funzioni ogni giorno?
Tieni a mente ciò che già sai su TypeScript e le firme delle funzioni. Tutto quello che stiamo dicendo è che T è un tipo arbitrario che l'utente fornirà quando chiamerà la funzione, proprio come input è un valore arbitrario che l'utente fornirà quando chiamerà la funzione. In questo caso, input deve essere qualunque sia il tipo T quando la funzione viene chiamata in futuro .
Successivamente, nel "futuro", nelle due istruzioni log, "passiamo" il tipo concreto che desideriamo utilizzare, proprio come facciamo con una variabile. Notare l'opzione nella verbosità qui — nella forma iniziale di <T> signature , quando si dichiara la nostra funzione, è generica — ovvero funziona su tipi generici o tipi da specificare in seguito. Questo perché non sappiamo quale tipo il chiamante vorrà utilizzare quando scriviamo effettivamente la funzione. Ma, quando il chiamante chiama la funzione, sa esattamente con quali tipi vuole lavorare, che in questo caso sono string e number .
Puoi immaginare l'idea di avere una funzione di registro dichiarata in questo modo in una libreria di terze parti: l'autore della libreria non ha idea di quali tipi vorranno usare gli sviluppatori che usano la lib, quindi rendono la funzione generica, sostanzialmente rinviando la necessità per tipi concreti fino a quando non sono effettivamente conosciuti.
Voglio sottolineare che dovresti pensare a questo processo in modo simile al concetto di passare una variabile a una funzione allo scopo di ottenere una comprensione più intuitiva. Tutto ciò che stiamo facendo ora è passare anche un tipo.
Nel punto in cui abbiamo chiamato la funzione con il parametro number , la firma originale, a tutti gli effetti, potrebbe essere pensata come identity(input: number): number . E, nel punto in cui abbiamo chiamato la funzione con il parametro string , di nuovo, la firma originale potrebbe anche essere stata identity(input: string): string . Puoi immaginare che, durante la chiamata, ogni T generica venga sostituita con il tipo concreto che fornisci in quel momento.
Esplorazione della sintassi generica
Esistono diverse sintassi e semantiche per specificare i generici nel contesto di funzioni ES5, funzioni freccia, alias di tipo, interfacce e classi. Esploreremo queste differenze in questa sezione.
Esplorazione della sintassi generica: funzioni
Hai già visto alcuni esempi di funzioni generiche, ma è importante notare che una funzione generica può accettare più di un parametro di tipo generico, proprio come le variabili. Puoi scegliere di chiedere uno, due, tre o quanti tipi vuoi, tutti separati da virgole (di nuovo, proprio come gli argomenti di input).
Questa funzione accetta tre tipi di input e ne restituisce uno in modo casuale:
function randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } // Calling the function. // `value` has type `string | number | IAircraft` const value = randomValue< string, number, IAircraft >( myString, myNumber, myAircraft );Puoi anche vedere che la sintassi è leggermente diversa a seconda che utilizziamo una funzione ES5 o una funzione freccia, ma entrambi dichiarano i parametri di tipo nella firma:
const randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } Tieni presente che non vi è alcun "vincolo di unicità" imposto sui tipi: puoi passare in qualsiasi combinazione desideri, come due string s e un number , per esempio. Inoltre, proprio come gli argomenti di input sono "nell'ambito" del corpo della funzione, lo sono anche i parametri di tipo generico. Il primo esempio dimostra che abbiamo pieno accesso a T , U e V dall'interno del corpo della funzione e li abbiamo usati per dichiarare una tupla 3 locale.
Puoi immaginare che questi generici operino in un certo "contesto" o entro una certa "vita", e questo dipende da dove sono dichiarati. I generici sulle funzioni sono nell'ambito della firma e del corpo della funzione (e le chiusure create dalle funzioni nidificate), mentre i generici dichiarati su una classe o interfaccia o alias di tipo sono nell'ambito di tutti i membri della classe o interfaccia o alias di tipo.
La nozione di generici sulle funzioni non si limita a "funzioni libere" o "funzioni mobili" (funzioni non associate a un oggetto oa una classe, un termine C++), ma possono essere utilizzate anche su funzioni associate ad altre strutture.
Possiamo inserire quel randomValue in una classe e possiamo chiamarlo allo stesso modo:
class Utils { public randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // ... } // Or, as an arrow function: public randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // ... } }Potremmo anche inserire una definizione all'interno di un'interfaccia:
interface IUtils { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }O all'interno di un alias di tipo:
type Utils = { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }Proprio come prima, questi parametri di tipo generico sono "nell'ambito" di quella particolare funzione: non sono classe, interfaccia o tipo alias-wide. Vivono solo all'interno della funzione particolare su cui sono specificati. Per condividere un tipo generico tra tutti i membri di una struttura, devi annotare il nome della struttura stessa, come vedremo di seguito.
Esplorazione della sintassi generica — Digitare gli alias
Con Tipo Alias, la sintassi generica viene utilizzata sul nome dell'alias.
Ad esempio, alcune funzioni di "azione" che accettano un valore, eventualmente mutano quel valore, ma restituiscono void potrebbero essere scritte come:
type Action<T> = (val: T) => void;Nota : questo dovrebbe essere familiare agli sviluppatori C# che comprendono il delegato Action<T>.
Oppure, una funzione di callback che accetta sia un errore che un valore potrebbe essere dichiarata come tale:
type CallbackFunction<T> = (err: Error, data: T) => void; const usersApi = { get(uri: string, cb: CallbackFunction<User>) { /// ... } }Con la nostra conoscenza dei generici delle funzioni, potremmo andare oltre e rendere generica anche la funzione sull'oggetto API:
type CallbackFunction<T> = (err: Error, data: T) => void; const api = { // `T` is available for use within this function. get<T>(uri: string, cb: CallbackFunction<T>) { /// ... } } Ora, stiamo dicendo che la funzione get accetta un parametro di tipo generico e, qualunque esso sia, CallbackFunction lo riceve. Abbiamo essenzialmente "superato" la T che entra in get come T per CallbackFunction . Forse questo avrebbe più senso se cambiassimo i nomi:
type CallbackFunction<TData> = (err: Error, data: TData) => void; const api = { get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } } Il prefisso dei parametri di tipo con T è semplicemente una convenzione, proprio come il prefisso delle interfacce con I o delle variabili membro con _ . Quello che puoi vedere qui è che CallbackFunction accetta un tipo ( TData ) che rappresenta il carico utile di dati disponibile per la funzione, mentre get accetta un parametro di tipo che rappresenta il tipo/forma di dati della risposta HTTP ( TResponse ). Il client HTTP ( api ), simile ad Axios, utilizza qualunque cosa TResponse sia come TData per CallbackFunction . Ciò consente al chiamante dell'API di selezionare il tipo di dati che riceverà dall'API (supponiamo da qualche altra parte nella pipeline di avere un middleware che analizza il JSON in un DTO).
Se volessimo andare un po' oltre, potremmo modificare i parametri di tipo generico su CallbackFunction per accettare anche un tipo di errore personalizzato:
type CallbackFunction<TData, TError> = (err: TError, data: TData) => void;E, proprio come puoi rendere opzionali gli argomenti delle funzioni, puoi farlo anche con i parametri di tipo. Nel caso in cui l'utente non fornisca un tipo di errore, lo imposteremo sul costruttore di errori per impostazione predefinita:
type CallbackFunction<TData, TError = Error> = (err: TError, data: TData) => void;Con questo, ora possiamo specificare un tipo di funzione di callback in più modi:
const apiOne = { // `Error` is used by default for `CallbackFunction`. get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } }; apiOne.get<string>('uri', (err: Error, data: string) => { // ... }); const apiTwo = { // Override the default and use `HttpError` instead. get<TResponse>(uri: string, cb: CallbackFunction<TResponse, HttpError>) { // ... } }; apiTwo.get<string>('uri', (err: HttpError, data: string) => { // ... });Questa idea di parametri predefiniti è accettabile per funzioni, classi, interfacce e così via, non si limita solo agli alias di tipo. In tutti gli esempi che abbiamo visto finora, avremmo potuto assegnare qualsiasi parametro di tipo che volevamo a un valore predefinito. Gli alias di tipo, proprio come le funzioni, possono accettare tutti i parametri di tipo generico che desideri.
Esplorazione della sintassi generica — Interfacce
Come hai visto, un parametro di tipo generico può essere fornito a una funzione su un'interfaccia:
interface IUselessFunctions { // Not generic printHelloWorld(); // Generic identity<T>(t: T): T; } In questo caso, T vive solo per la funzione di identity come tipo di input e restituito.
Possiamo anche rendere disponibile un parametro di tipo a tutti i membri di un'interfaccia, proprio come con le classi e gli alias di tipo, specificando che l'interfaccia stessa accetta un generico. Parleremo del Repository Pattern un po' più avanti quando discuteremo di casi d'uso più complessi per i generici, quindi va bene se non ne hai mai sentito parlare. Il Repository Pattern ci consente di astrarre la nostra memorizzazione dei dati in modo da rendere la logica aziendale indipendente dalla persistenza. Se desideri creare un'interfaccia di repository generica che opera su tipi di entità sconosciuti, potremmo digitarla come segue:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; removeById(id: string): Promise<void>; }Nota : ci sono molti pensieri diversi sui repository, dalla definizione di Martin Fowler alla definizione di DDD Aggregate. Sto semplicemente tentando di mostrare un caso d'uso per i generici, quindi non sono troppo preoccupato di essere completamente corretto dal punto di vista dell'implementazione. C'è sicuramente qualcosa da dire per non utilizzare repository generici, ma ne parleremo più avanti.
Come puoi vedere qui, IRepository è un'interfaccia che contiene metodi per archiviare e recuperare dati. Opera su un parametro di tipo generico denominato T e T viene utilizzato come input per add e updateById , così come il risultato della risoluzione promessa di findById .
Tieni presente che c'è una differenza molto grande tra l'accettazione di un parametro di tipo generico sul nome dell'interfaccia invece di consentire a ciascuna funzione stessa di accettare un parametro di tipo generico. Il primo, come abbiamo fatto qui, assicura che ogni funzione all'interno dell'interfaccia operi sullo stesso tipo T . Ovvero, per un IRepository<User> , ogni metodo che usa T nell'interfaccia ora funziona sugli oggetti User . Con quest'ultimo metodo, ogni funzione potrebbe funzionare con qualsiasi tipo desideri. Sarebbe molto particolare poter aggiungere solo gli User al repository ma essere in grado di ricevere indietro le Policies o Orders , ad esempio, che è la situazione potenziale in cui ci troveremmo se non potessimo far rispettare che il tipo è uniforme in tutti i metodi.
Una determinata interfaccia può contenere non solo un tipo condiviso, ma anche tipi univoci per i suoi membri. Ad esempio, se volessimo imitare un array, potremmo digitare un'interfaccia come questa:
interface IArray<T> { forEach(func: (elem: T, index: number) => void): this; map<U>(func: (elem: T, index: number) => U): IArray<U>; } In questo caso, sia forEach che map hanno accesso a T dal nome dell'interfaccia. Come affermato, puoi immaginare che T sia nell'ambito di tutti i membri dell'interfaccia. Nonostante ciò, nulla impedisce alle singole funzioni interne di accettare anche i propri parametri di tipo. La funzione map lo fa, con U . Ora, la map ha accesso sia a T che a U . Abbiamo dovuto nominare il parametro con una lettera diversa, come U , perché T è già stata presa e non vogliamo una collisione di nomi. Proprio come il suo nome, map "mapperà" gli elementi di tipo T all'interno dell'array a nuovi elementi di tipo U . Mappa T s a U s. Il valore di ritorno di questa funzione è l'interfaccia stessa, ora operante sul nuovo tipo U , in modo da poter imitare in qualche modo la sintassi concatenabile fluida di JavaScript per gli array.
Vedremo a breve un esempio della potenza di Generics e Interfaces quando implementeremo il Repository Pattern e discuteremo di Dependency Injection. Ancora una volta, possiamo accettare tanti parametri generici e selezionare uno o più parametri predefiniti impilati alla fine di un'interfaccia.
Esplorazione della sintassi generica — Classi
Allo stesso modo in cui possiamo passare un parametro di tipo generico a un alias, una funzione o un'interfaccia di tipo, possiamo anche passarne uno o più a una classe. In questo modo, quel parametro di tipo sarà accessibile a tutti i membri di quella classe, nonché alle classi base estese o alle interfacce implementate.
Costruiamo un'altra classe di raccolta, ma un po' più semplice di TypedList sopra, in modo da poter vedere l'interoperabilità tra tipi generici, interfacce e membri. Vedremo un esempio di passaggio di un tipo a una classe base e dell'ereditarietà dell'interfaccia un po' più avanti.
La nostra raccolta supporterà semplicemente le funzioni CRUD di base oltre a una map e al metodo forEach .
class Collection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): Collection<U> { return new Collection<U>(this.elements.map(func)); } } const stringCollection = new Collection<string>(); stringCollection.add('Hello, World!'); const numberCollection = new Collection<number>(); numberCollection.add(3.14159); const aircraftCollection = new Collection<IAircraft>(); aircraftCollection.add(myAircraft); Discutiamo di cosa sta succedendo qui. La classe Collection accetta un parametro di tipo generico denominato T . Quel tipo diventa accessibile a tutti i membri della classe. Lo usiamo per definire un array privato di tipo T[] , che avremmo anche potuto denotare nella forma Array<T> (vedi? Di nuovo Generics per la normale digitazione di array TS). Inoltre, la maggior parte delle funzioni membro utilizza tale T in qualche modo, ad esempio controllando i tipi che vengono aggiunti e rimossi o controllando se la raccolta contiene un elemento.

Infine, come abbiamo visto prima, il metodo map richiede un proprio parametro di tipo generico. We need to define in the signature of map that some type T is mapped to some type U through a callback function, thus we need a U . That U is unique to that function in particular, which means we could have another function in that class that also accepts some type named U , and that'd be fine, because those types are only “in scope” for their functions and not shared across them, thus there are no naming collisions. What we can't do is have another function that accepts a generic parameter named T , for that'd conflict with the T from the class signature.
You can see that when we call the constructor, we pass in the type we want to work with (that is, what type each element of the internal array will be). In the calling code at the bottom of the example, we work with string s, number s, and IAircraft s.
How could we make this work with an interface? What if we have different collection interfaces that we might want to swap out or inject into calling code? To get that level of reduced coupling (low coupling and high cohesion is what we should always aim for), we'll need to depend on an abstraction. Generally, that abstraction will be an interface, but it could also be an abstract class.
Our collection interface will need to be generic, so let's define it:
interface ICollection<T> { add(t: T): void; contains(t: T): boolean; remove(t: T): void; forEach(func: (elem: T, index: number) => void): void; map<U>(func: (elem: T, index: number) => U): ICollection<U>; }Now, let's suppose we have different kinds of collections. We could have an in-memory collection, one that stores data on disk, one that uses a database, and so on. By having an interface, the dependent code can depend upon the abstraction, permitting us to swap out different implementations without affecting the existing code. Here is the in-memory collection.
class InMemoryCollection<T> implements ICollection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): ICollection<U> { return new InMemoryCollection<U>(this.elements.map(func)); } } The interface describes the public-facing methods and properties that our class is required to implement, expecting you to pass in a concrete type that those methods will operate upon. However, at the time of defining the class, we still don't know what type the API caller will wish to use. Thus, we make the class generic too — that is, InMemoryCollection expects to receive some generic type T , and whatever it is, it's immediately passed to the interface, and the interface methods are implemented using that type.
Calling code can now depend on the interface:
// Using type annotation to be explicit for the purposes of the // tutorial. const userCollection: ICollection<User> = new InMemoryCollection<User>(); function manageUsers(userCollection: ICollection<User>) { userCollection.add(new User()); } With this, any kind of collection can be passed into the manageUsers function as long as it satisfies the interface. This is useful for testing scenarios — rather than dealing with over-the-top mocking libraries, in unit and integration test scenarios, I can replace my SqlServerCollection<T> (for example) with InMemoryCollection<T> instead and perform state-based assertions instead of interaction-based assertions. This setup makes my tests agnostic to implementation details, which means they are, in turn, less likely to break when refactoring the SUT.
At this point, we should have worked up to the point where we can understand that first TypedList<T> example. Here it is again:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. } The class itself accepts a generic type parameter named T , and all members of the class are provided access to it. The instance method select and the two static methods from and create , which are factories, accept their own generic type parameter named U .
The create static method permits the construction of a list with optional seed data. It accepts some type named U to be the type of every element in the list as well as an optional array of U elements, typed as U[] . When it calls the list's constructor with new , it passes that type U as the generic parameter to TypedList . This creates a new list where the type of every element is U . It is exactly the same as how we could call the constructor of our collection class earlier with new Collection<SomeType>() . The only difference is that the generic type is now passing through the create method rather than being provided and used at the top-level.
I want to make sure this is really, really clear. I've stated a few times that we can think about passing around types in a similar way that we do variables. It should already be quite intuitive that we can pass a variable through as many layers of indirection as we please. Forget generics and types for a moment and think about an example of the form:
class MyClass { private constructor (t: number) {} public static create(u: number) { return new MyClass(u); } } const myClass = MyClass.create(2.17); This is very similar to what is happening with the more-involved example, the difference being that we're working on generic type parameters, not variables. Here, 2.17 becomes the u in create , which ultimately becomes the t in the private constructor.
In the case of generics:
class MyClass<T> { private constructor () {} public static create<U>() { return new MyClass<U>(); } } const myClass = MyClass.create<number>(); The U passed to create is ultimately passed in as the T for MyClass<T> . When calling create , we provided number as U , thus now U = number . We put that U (which, again, is just number ) into the T for MyClass<T> , so that MyClass<T> effectively becomes MyClass<number> . The benefit of generics is that we're opened up to be able to work with types in this abstract and high-level fashion, similar to how we can normal variables.
The from method constructs a new list that operates on an array of elements of type U . It uses that type U , just like create , to construct a new instance of the TypedList class, now passing in that type U for T .
The where instance method performs a filtering operation based upon a predicate function. There's no mapping happening, thus the types of all elements remain the same throughout. The filter method available on JavaScript's array returns a new array of values, which we pass into the from method. So, to be clear, after we filter out the values that don't satisfy the predicate function, we get an array back containing the elements that do. All those elements are still of type T , which is the original type that the caller passed to create when the list was first created. Those filtered elements get given to the from method, which in turn creates a new list containing all those values, still using that original type T . The reason why we return a new instance of the TypedList class is to be able to chain new method calls onto the return result. This adds an element of “immutability” to our list.
Hopefully, this all provides you with a more intuitive example of generics in practice, and their reason for existence. Next, we'll look at a few of the more advanced topics.
Generic Type Inference
Throughout this article, in all cases where we've used generics, we've explicitly defined the type we're operating on. It's important to note that in most cases, we do not have to explicitly define the type parameter we pass in, for TypeScript can infer the type based on usage.
If I have some function that returns a random number, and I pass the return result of that function to identity from earlier without specifying the type parameter, it will be inferred automatically as number :
// `value` is inferred as type `number`. const value = identity(getRandomNumber()); Per dimostrare l'inferenza del tipo, in precedenza ho rimosso tutte le annotazioni di tipo tecnicamente estranee dalla nostra struttura TypedList e puoi vedere, dalle immagini seguenti, che TSC deduce ancora tutti i tipi correttamente:
TypedList senza dichiarazioni di tipo estranee:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T) { this.values.push(value); } public where(predicate: (value: T) => boolean) { return TypedList.from(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U) { return TypedList.from(this.values.map(selector)); } public toArray() { return this.values; } public static from<U>(values: U[]) { // Perhaps we perform some logic here. // ... return new TypedList(values); } public static create<U>(values?: U[]) { return new TypedList(values ?? []); } // Other collection functions. // .. } In base ai valori restituiti dalla funzione e in base ai tipi di input passati from e dal costruttore, TSC comprende tutte le informazioni sui tipi. Nell'immagine qui sotto, ho unito più immagini che mostrano l'estensione del linguaggio di Code TypeScript di Visual Studio (e quindi il compilatore) che deduce tutti i tipi:
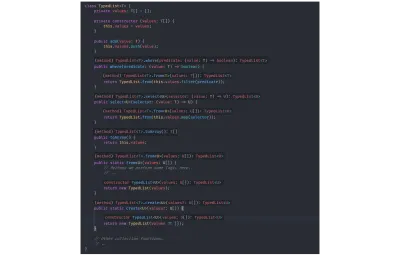
Vincoli generici
A volte, vogliamo mettere un vincolo attorno a un tipo generico. Forse non possiamo supportare tutti i tipi esistenti, ma possiamo supportarne un sottoinsieme. Diciamo di voler costruire una funzione che restituisca la lunghezza di una raccolta. Come visto sopra, potremmo avere molti tipi diversi di Array /raccolte, dall'array JavaScript predefinito a quelli personalizzati. Come facciamo a far sapere alla nostra funzione che un tipo generico ha una proprietà di length collegata ad esso? Allo stesso modo, come possiamo limitare i tipi concreti che passiamo nella funzione a quelli che contengono i dati di cui abbiamo bisogno? Un esempio come questo, ad esempio, non funzionerebbe:
function getLength<T>(collection: T): number { // Error. TS does not know that a type T contains a `length` property. return collection.length; }La risposta è utilizzare i vincoli generici. Possiamo definire un'interfaccia che descrive le proprietà di cui abbiamo bisogno:
interface IHasLength { length: number; }Ora, quando definiamo la nostra funzione generica, possiamo vincolare il tipo generico in modo che estenda quell'interfaccia:
function getLength<T extends IHasLength>(collection: T): number { // Restricting `collection` to be a type that contains // everything within the `IHasLength` interface. return collection.length; }Esempi del mondo reale
Nelle prossime due sezioni, discuteremo alcuni esempi reali di generici che creano codice più elegante e facile da ragionare. Abbiamo visto molti esempi banali, ma voglio discutere alcuni approcci alla gestione degli errori, ai modelli di accesso ai dati e allo stato/proprietà di React front-end.
Esempi del mondo reale: approcci alla gestione degli errori
JavaScript contiene un meccanismo di prima classe per la gestione degli errori, così come la maggior parte dei linguaggi di programmazione: try / catch . Nonostante ciò, non sono un grande fan di come appare quando viene utilizzato. Questo non vuol dire che non uso il meccanismo, lo faccio, ma tendo a cercare di nasconderlo il più possibile. Astraendo try / catch away, posso anche riutilizzare la logica di gestione degli errori in operazioni a rischio di esito negativo.
Supponiamo di creare un livello di accesso ai dati. Questo è un livello dell'applicazione che racchiude la logica di persistenza per gestire il metodo di archiviazione dei dati. Se stiamo eseguendo operazioni di database e se il database viene utilizzato in una rete, è probabile che si verifichino particolari errori specifici del DB ed eccezioni transitorie. Parte del motivo per avere un livello di accesso ai dati dedicato è quello di astrarre il database dalla logica aziendale. Per questo motivo, non è possibile che tali errori specifici del DB vengano generati dallo stack e fuori da questo livello. Dobbiamo prima avvolgerli.
Diamo un'occhiata a un'implementazione tipica che utilizzerebbe try / catch :
async function queryUser(userID: string): Promise<User> { try { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } Il passaggio a true è semplicemente un metodo per poter utilizzare le istruzioni switch case per la mia logica di controllo degli errori invece di dover dichiarare una catena di if/else if, un trucco che ho sentito per la prima volta da @Jeffijoe.
Se abbiamo più di queste funzioni, dobbiamo replicare questa logica di wrapping degli errori, che è una pessima pratica. Sembra abbastanza buono per una funzione, ma sarà un incubo con molte. Per astrarre questa logica, possiamo racchiuderla in una funzione di gestione degli errori personalizzata che passerà attraverso il risultato, ma catturerà e avvolgerà eventuali errori se vengono generati:
async function withErrorHandling<T>( dalOperation: () => Promise<T> ): Promise<T> { try { // This unwraps the promise and returns the type `T`. return await dalOperation(); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } Per garantire che ciò abbia senso, abbiamo una funzione intitolata withErrorHandling che accetta un parametro di tipo generico T . Questa T rappresenta il tipo del valore di risoluzione riuscito della promessa che ci aspettiamo restituita dalla funzione di callback dalOperation . Di solito, poiché stiamo solo restituendo il risultato di ritorno della funzione async dalOperation , non avremmo bisogno di await perché ciò avvolgerebbe la funzione in una seconda promessa estranea e potremmo lasciare l' await al codice chiamante. In questo caso, è necessario rilevare eventuali errori, quindi è necessario await .
Ora possiamo usare questa funzione per avvolgere le nostre operazioni DAL di prima:
async function queryUser(userID: string) { return withErrorHandling<User>(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); }); }E ci andiamo. Abbiamo una funzione di query utente sicura dai tipi e dagli errori.
Inoltre, come hai visto in precedenza, se il compilatore TypeScript ha informazioni sufficienti per dedurre i tipi in modo implicito, non è necessario passarli in modo esplicito. In questo caso, TSC sa che il risultato restituito dalla funzione è il tipo generico. Pertanto, se mapper.toDomain(user) restituito un tipo di User , non è necessario passare affatto il tipo:
async function queryUser(userID: string) { return withErrorHandling(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(user); }); } Un altro approccio alla gestione degli errori che tendo ad apprezzare è quello dei tipi monadici. La Both Monad è un tipo di dati algebrico nella forma Either<T, U> , dove T può rappresentare un tipo di errore e U può rappresentare un tipo di errore. L'uso dei tipi monadici dà ascolto alla programmazione funzionale e uno dei principali vantaggi è che gli errori diventano indipendenti dai tipi: una normale firma di funzione non dice nulla al chiamante dell'API su quali errori potrebbe generare quella funzione. Supponiamo di lanciare un errore NotFound dall'interno di queryUser . Una firma di queryUser(userID: string): Promise<User> non ci dice nulla al riguardo. Ma una firma come queryUser(userID: string): Promise<Either<NotFound, User>> lo fa assolutamente. Non spiegherò come funzionano le monadi come la Both Monad in questo articolo perché possono essere piuttosto complesse e ci sono una varietà di metodi che devono avere per essere considerati monadici, come il mapping/binding. Se vuoi saperne di più su di loro, ti consiglio due dei discorsi NDC di Scott Wlaschin, qui e qui, oltre al discorso di Daniel Chamber qui. Anche questo sito e questi post del blog possono essere utili.
Esempi del mondo reale: modello di repository
Diamo un'occhiata a un altro caso d'uso in cui Generics potrebbe essere utile. La maggior parte dei sistemi back-end deve interfacciarsi in qualche modo con un database: potrebbe essere un database relazionale come PostgreSQL, un database di documenti come MongoDB o forse anche un database di grafici, come Neo4j.
Dal momento che, come sviluppatori, dovremmo puntare a progetti poco accoppiati e altamente coesi, sarebbe un argomento legittimo considerare quali potrebbero essere le ramificazioni della migrazione dei sistemi di database. Sarebbe anche corretto considerare che esigenze di accesso ai dati diverse potrebbero preferire approcci di accesso ai dati diversi (questo inizia a entrare un po' in CQRS, che è un modello per separare letture e scritture. Se lo desideri, consulta il post di Martin Fowler e l'elenco MSDN Anche i libri "Implementing Domain Driven Design" di Vaughn Vernon e "Patterns, Principles, and Practices of Domain-Driven Design" di Scott Millet sono ottime letture). Dovremmo anche considerare i test automatizzati. La maggior parte dei tutorial che spiegano la creazione di sistemi back-end con Node.js mescolano il codice di accesso ai dati con la logica aziendale e il routing. Cioè, tendono a utilizzare MongoDB con Mongoose ODM, adottando un approccio Active Record e non avendo una netta separazione delle preoccupazioni. Tali tecniche sono disapprovate in grandi applicazioni; nel momento in cui decidi di voler migrare un sistema di database per un altro, o nel momento in cui ti rendi conto che preferiresti un approccio diverso all'accesso ai dati, devi strappare quel vecchio codice di accesso ai dati, sostituirlo con il nuovo codice, e spero che tu non abbia introdotto alcun bug nel routing e nella logica di business lungo il percorso.
Certo, potresti sostenere che i test unitari e di integrazione impediranno le regressioni, ma se quei test si trovano accoppiati e dipendenti da dettagli di implementazione a cui dovrebbero essere agnostici, anche loro probabilmente interromperanno il processo.
Un approccio comune per risolvere questo problema è il Repository Pattern. Dice che per chiamare il codice, dovremmo consentire al nostro livello di accesso ai dati di imitare una semplice raccolta in memoria di oggetti o entità di dominio. In questo modo, possiamo lasciare che l'azienda guidi il design piuttosto che il database (modello di dati). Per applicazioni di grandi dimensioni, diventa utile un modello architettonico chiamato Domain-Driven Design. I repository, nel Repository Pattern, sono componenti, più comunemente classi, che incapsulano e mantengono internamente tutta la logica per accedere alle origini dati. Con questo, possiamo centralizzare il codice di accesso ai dati su un livello, rendendolo facilmente testabile e facilmente riutilizzabile. Inoltre, possiamo inserire un livello di mappatura nel mezzo, che ci consente di mappare modelli di dominio indipendenti dal database su una serie di mappature di tabelle uno-a-uno. Ciascuna funzione disponibile sul Repository potrebbe facoltativamente utilizzare un metodo di accesso ai dati diverso, se lo desideri.
Esistono molti approcci e semantiche diversi per repository, unità di lavoro, transazioni di database tra tabelle e così via. Poiché questo è un articolo sui generici, non voglio entrare troppo nel merito, quindi illustrerò qui un semplice esempio, ma è importante notare che applicazioni diverse hanno esigenze diverse. Un repository per gli aggregati DDD sarebbe molto diverso da quello che stiamo facendo qui, per esempio. Il modo in cui descrivo le implementazioni del repository qui non è il modo in cui le implemento in progetti reali, poiché ci sono molte funzionalità mancanti e pratiche architettoniche non desiderate in uso.
Supponiamo di avere Users e Tasks come modelli di dominio. Questi potrebbero essere solo POTO: oggetti dattiloscritti normali. Non esiste la nozione di un database integrato in essi, quindi non chiamerai User.save() , ad esempio, come faresti con Mongoose. Utilizzando il Repository Pattern, potremmo rendere persistente un utente o eliminare un'attività dalla nostra logica aziendale come segue:
// Querying the DB for a User by their ID. const user: User = await userRepository.findById(userID); // Deleting a Task by its ID. await taskRepository.deleteById(taskID); // Deleting a Task by its owner's ID. await taskRepository.deleteByUserId(userID);Chiaramente, puoi vedere come tutta la logica di accesso ai dati disordinata e transitoria sia nascosta dietro questa facciata/astrazione del repository, rendendo la logica aziendale agnostica rispetto ai problemi di persistenza.
Iniziamo costruendo alcuni semplici modelli di dominio. Questi sono i modelli con cui interagirà il codice dell'applicazione. Sono anemici qui, ma manterrebbero la loro logica per soddisfare le invarianti commerciali nel mondo reale, cioè non sarebbero semplici borse di dati.
interface IHasIdentity { id: string; } class User implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _username: string ) {} public get id() { return this._id; } public get username() { return this._username; } } class Task implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _title: string ) {} public get id() { return this._id; } public get title() { return this._title; } } Vedrai tra poco perché estraiamo le informazioni sulla digitazione dell'identità in un'interfaccia. Questo metodo per definire i modelli di dominio e passare tutto attraverso il costruttore non è come lo farei nel mondo reale. Inoltre, fare affidamento su una classe modello di dominio astratta sarebbe stato più preferibile rispetto all'interfaccia per ottenere l'implementazione id gratuitamente.
Per il Repository, poiché, in questo caso, ci aspettiamo che molti degli stessi meccanismi di persistenza saranno condivisi su diversi modelli di dominio, possiamo astrarre i nostri metodi Repository su un'interfaccia generica:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; deleteById(id: string): Promise<void>; existsById(id: string): Promise<boolean>; }Potremmo andare oltre e creare anche un repository generico per ridurre la duplicazione. Per brevità, non lo farò qui, e dovrei notare che le interfacce dei repository generici come questa e i repository generici, in generale, tendono a essere disapprovati, poiché potresti avere determinate entità di sola lettura o scrivere -solo, o che non può essere cancellato, o simili. Dipende dall'applicazione. Inoltre, non abbiamo una nozione di "unità di lavoro" per condividere una transazione tra tabelle, una funzionalità che implementerei nel mondo reale, ma, ancora una volta, poiché questa è una piccola demo, non voglio diventare troppo tecnico
Iniziamo implementando il nostro UserRepository . IUserRepository un'interfaccia IUserRepository che contiene metodi specifici per gli utenti, consentendo così al codice chiamante di dipendere da quell'astrazione quando la dipendenza iniettiamo le implementazioni concrete:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository implements IUserRepository { // There are 6 methods to implement here all using the // concrete type of `User` - Five from IRepository<User> // and the one above. }Il Task Repository sarebbe simile ma conterrebbe metodi diversi a seconda dell'applicazione.
Qui stiamo definendo un'interfaccia che ne estende una generica, quindi dobbiamo passare il tipo concreto su cui stiamo lavorando. Come puoi vedere da entrambe le interfacce, abbiamo l'idea che inviamo questi modelli di dominio POTO e li estraiamo. Il codice chiamante non ha idea di quale sia il meccanismo di persistenza sottostante, e questo è il punto.
La prossima considerazione da fare è che, a seconda del metodo di accesso ai dati che scegliamo, dovremo gestire gli errori specifici del database. Ad esempio, potremmo posizionare Mongoose o Knex Query Builder dietro questo Repository e, in tal caso, dovremo gestire quegli errori specifici: non vogliamo che si espandano nella logica aziendale perché ciò romperebbe la separazione delle preoccupazioni e introdurre un maggior grado di accoppiamento.
Definiamo un repository di base per i metodi di accesso ai dati che desideriamo utilizzare in grado di gestire gli errori per noi:
class BaseKnexRepository { // A constructor. /** * Wraps a likely to fail database operation within a function that handles errors by catching * them and wrapping them in a domain-safe error. * * @param dalOp The operation to perform upon the database. */ public async withErrorHandling<T>(dalOp: () => Promise<T>) { try { return await dalOp(); } catch (e) { // Use a proper logger: console.error(e); // Handle errors properly here. } } }Ora possiamo estendere questa Classe Base nel Repository e accedere a quel metodo generico:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository extends BaseKnexRepository implements IUserRepository { private readonly dbContext: Knex | Knex.Transaction; public constructor (private knexInstance: Knex | Knex.Transaction) { super(); this.dbContext = knexInstance; } // Example `findById` implementation: public async findById(id: string): Promise<User> { return this.withErrorHandling<User>(async () => { const dbUser = await this.dbContext<DbUser>() .select() .where({ user_id: id }) .first(); // Maps type DbUser to User return mapper.toDomain(dbUser); }); } // There are 5 methods to implement here all using the // concrete type of `User`. } Si noti che la nostra funzione recupera un DbUser dal database e lo associa a un modello di dominio User prima di restituirlo. Questo è il modello Data Mapper ed è fondamentale per mantenere la separazione delle preoccupazioni. DbUser è un mapping uno-a-uno alla tabella del database — è il modello di dati su cui opera il Repository — ed è quindi fortemente dipendente dalla tecnologia di archiviazione dei dati utilizzata. Per questo motivo, DbUser s non lascerà mai il Repository e verrà mappato su un modello di dominio User prima di essere restituito. Non ho mostrato l'implementazione di DbUser , ma potrebbe essere solo una semplice classe o interfaccia.
Finora, utilizzando il Repository Pattern, basato su Generics, siamo riusciti ad astrarre i problemi di accesso ai dati in piccole unità, nonché a mantenere la sicurezza dei tipi e la riutilizzabilità.
Infine, ai fini del test di unità e integrazione, diciamo che manterremo un'implementazione del repository in memoria in modo che in un ambiente di test, possiamo iniettare quel repository ed eseguire asserzioni basate sullo stato su disco piuttosto che prendere in giro con un quadro beffardo. Questo metodo costringe tutto a fare affidamento sulle interfacce rivolte al pubblico piuttosto che consentire l'associazione dei test ai dettagli di implementazione. Poiché le uniche differenze tra ciascun repository sono i metodi che scelgono di aggiungere nell'interfaccia ISomethingRepository , possiamo creare un repository in memoria generico ed estenderlo all'interno di implementazioni specifiche del tipo:
class InMemoryRepository<T extends IHasIdentity> implements IRepository<T> { protected entities: T[] = []; public findById(id: string): Promise<T> { const entityOrNone = this.entities.find(entity => entity.id === id); return entityOrNone ? Promise.resolve(entityOrNone) : Promise.reject(new NotFound()); } // Implement the rest of the IRepository<T> methods here. } Lo scopo di questa classe base è di eseguire tutta la logica per la gestione dell'archiviazione in memoria in modo da non doverla duplicare all'interno di repository di test in memoria. A causa di metodi come findById , questo repository deve comprendere che le entità contengono un campo id , motivo per cui è necessario il vincolo generico sull'interfaccia IHasIdentity . Abbiamo già visto questa interfaccia: è ciò che i nostri modelli di dominio hanno implementato.
Con questo, quando si tratta di creare l'utente in memoria o il repository delle attività, possiamo semplicemente estendere questa classe e ottenere la maggior parte dei metodi implementati automaticamente:
class InMemoryUserRepository extends InMemoryRepository<User> { public async existsByUsername(username: string): Promise<boolean> { const userOrNone = this.entities.find(entity => entity.username === username); return Boolean(userOrNone); // or, return !!userOrNone; } // And that's it here. InMemoryRepository implements the rest. } Qui, il nostro InMemoryRepository deve sapere che le entità hanno campi come id e username , quindi passiamo User come parametro generico. User implementa già IHasIdentity , quindi il vincolo generico è soddisfatto e affermiamo anche che abbiamo anche una proprietà username .
Ora, quando desideriamo utilizzare questi repository dal livello di logica aziendale, è abbastanza semplice:
class UserService { public constructor ( private readonly userRepository: IUserRepository, private readonly emailService: IEmailService ) {} public async createUser(dto: ICreateUserDTO) { // Validate the DTO: // ... // Create a User Domain Model from the DTO const user = userFactory(dto); // Persist the Entity await this.userRepository.add(user); // Send a welcome email await this.emailService.sendWelcomeEmail(user); } } (Si noti che in un'applicazione reale, probabilmente sposteremmo la chiamata a emailService in una coda di lavoro per non aggiungere latenza alla richiesta e nella speranza di poter eseguire tentativi idempotenti sugli errori (- non che l'invio di e-mail sia particolarmente idempotente in primo luogo). Inoltre, anche il passaggio dell'intero oggetto utente al servizio è discutibile. L'altro problema da notare è che potremmo trovarci in una posizione in cui il server si arresta in modo anomalo dopo che l'utente è persistente ma prima che l'e-mail sia Ci sono modelli di mitigazione per impedirlo, ma ai fini del pragmatismo, l'intervento umano con una registrazione adeguata probabilmente funzionerà bene).
E il gioco è fatto: utilizzando il Repository Pattern con la potenza di Generics, abbiamo completamente disaccoppiato il nostro DAL dal nostro BLL e siamo riusciti a interfacciarci con il nostro repository in modo indipendente dai tipi. Abbiamo anche sviluppato un modo per costruire rapidamente repository in memoria ugualmente sicuri per i tipi ai fini dei test di unità e integrazione, consentendo veri test black-box e indipendenti dall'implementazione. Niente di tutto ciò sarebbe stato possibile senza i tipi generici.
Come disclaimer, voglio sottolineare ancora una volta che questa implementazione del repository è molto carente. Volevo mantenere l'esempio semplice poiché l'obiettivo è l'utilizzo di generici, motivo per cui non ho gestito la duplicazione o mi sono preoccupato delle transazioni. Implementazioni di repository decenti richiederebbero un articolo da sole per essere spiegato in modo completo e corretto e i dettagli di implementazione cambiano a seconda che tu stia eseguendo l'architettura N-Tier o DDD. Ciò significa che se desideri utilizzare il Repository Pattern, non dovresti considerare la mia implementazione qui come una best practice.
Esempi del mondo reale: reagisci allo stato e agli oggetti di scena
Anche lo stato, il riferimento e il resto degli hook per i componenti funzionali di React sono generici. Se ho un'interfaccia contenente proprietà per Task s e voglio conservarne una raccolta in un componente React, potrei farlo come segue:
import React, { useState } from 'react'; export const MyComponent: React.FC = () => { // An empty array of tasks as the initial state: const [tasks, setTasks] = useState<Task[]>([]); // A counter: // Notice, type of `number` is inferred automatically. const [counter, setCounter] = useState(0); return ( <div> <h3>Counter Value: {counter}</h3> <ul> { tasks.map(task => ( <li key={task.id}> <TaskItem {...task} /> </li> )) } </ul> </div> ); }; Inoltre, se vogliamo passare una serie di props nella nostra funzione, possiamo usare il tipo generico React.FC<T> e ottenere l'accesso a props :
import React from 'react'; interface IProps { id: string; title: string; description: string; } export const TaskItem: React.FC<IProps> = (props) => { return ( <div> <h3>{props.title}</h3> <p>{props.description}</p> </div> ); }; Il tipo di IProps props compilatore TS.
Conclusione
In questo articolo, abbiamo visto molti esempi diversi di generici e dei loro casi d'uso, dalle raccolte semplici, agli approcci di gestione degli errori, all'isolamento del livello di accesso ai dati e così via. In parole povere, i generici ci consentono di costruire strutture di dati senza la necessità di conoscere il tempo concreto in cui opereranno in fase di compilazione. Si spera che questo aiuti ad aprire un po' di più l'argomento, a rendere la nozione di generici un po' più intuitiva e a far emergere il loro vero potere.