
La guida definitiva alla creazione di web scraper scalabili con Scrapy
Pubblicato: 2022-03-10Il web scraping è un modo per acquisire dati dai siti Web senza dover accedere alle API o al database del sito Web. Hai solo bisogno di accedere ai dati del sito: finché il tuo browser può accedere ai dati, sarai in grado di estrarli.
Realisticamente, la maggior parte delle volte potresti semplicemente passare attraverso un sito Web manualmente e acquisire i dati "a mano" usando il copia e incolla, ma in molti casi ciò richiederebbe molte ore di lavoro manuale, il che potrebbe finire per costarti un molto più del valore dei dati, soprattutto se hai assunto qualcuno che svolga il compito per te. Perché assumere qualcuno che lavori a 1-2 minuti per query quando puoi fare in modo che un programma esegua automaticamente una query ogni pochi secondi?
Ad esempio, supponiamo che desideri compilare un elenco dei vincitori dell'Oscar per il miglior film, insieme al loro regista, agli attori protagonisti, alla data di uscita e alla durata. Usando Google, puoi vedere che ci sono diversi siti che elencheranno questi film per nome e forse alcune informazioni aggiuntive, ma in genere dovrai seguire i collegamenti per acquisire tutte le informazioni che desideri.
Ovviamente, sarebbe poco pratico e dispendioso in termini di tempo passare attraverso ogni collegamento dal 1927 ad oggi e cercare manualmente di trovare le informazioni attraverso ogni pagina. Con il web scraping, dobbiamo solo trovare un sito Web con pagine che contengano tutte queste informazioni e quindi indirizzare il nostro programma nella giusta direzione con le giuste istruzioni.
In questo tutorial, useremo Wikipedia come nostro sito Web in quanto contiene tutte le informazioni di cui abbiamo bisogno e quindi utilizzeremo Scrapy su Python come strumento per raschiare le nostre informazioni.
Alcuni avvertimenti prima di iniziare:
Lo scraping dei dati comporta l'aumento del carico del server per il sito che stai eseguendo lo scraping, il che significa un costo maggiore per le società che ospitano il sito e un'esperienza di qualità inferiore per gli altri utenti di quel sito. La qualità del server che esegue il sito Web, la quantità di dati che stai cercando di ottenere e la velocità con cui invii le richieste al server modereranno l'effetto che hai sul server. Tenendo presente questo, dobbiamo assicurarci di attenerci ad alcune regole.
La maggior parte dei siti ha anche un file chiamato robots.txt nella directory principale. Questo file stabilisce le regole per le directory a cui i siti non vogliono che accedano. La pagina Termini e condizioni di un sito Web di solito ti consente di sapere qual è la loro politica sullo scraping dei dati. Ad esempio, la pagina delle condizioni di IMDB ha la seguente clausola:
Robot e screen scraping: non è possibile utilizzare data mining, robot, screen scraping o strumenti simili di raccolta ed estrazione di dati su questo sito, se non con il nostro esplicito consenso scritto come indicato di seguito.
Prima di provare a ottenere i dati di un sito Web, dovremmo sempre controllare i termini del sito Web e il robots.txt per assicurarci di ottenere dati legali. Quando costruiamo i nostri scraper, dobbiamo anche assicurarci di non sovraccaricare un server con richieste che non è in grado di gestire.
Fortunatamente, molti siti Web riconoscono la necessità per gli utenti di ottenere dati e li rendono disponibili tramite API. Se sono disponibili, in genere è molto più semplice ottenere i dati tramite l'API che tramite lo scraping.
Wikipedia consente lo scraping dei dati, a condizione che i bot non vadano "troppo veloci", come specificato nel loro robots.txt . Forniscono anche set di dati scaricabili in modo che le persone possano elaborare i dati sulle proprie macchine. Se andiamo troppo veloci, i server bloccheranno automaticamente il nostro IP, quindi implementeremo dei timer per rispettare le loro regole.
Guida introduttiva, installazione di librerie pertinenti utilizzando Pip
Prima di tutto, per iniziare, installiamo Scrapy.
finestre
Installa l'ultima versione di Python da https://www.python.org/downloads/windows/
Nota: gli utenti Windows avranno anche bisogno di Microsoft Visual C++ 14.0, che puoi prendere da "Strumenti di compilazione Microsoft Visual C++" qui.
Dovrai anche assicurarti di avere l'ultima versione di pip.
In cmd.exe , digita:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyQuesto installerà Scrapy e tutte le dipendenze automaticamente.
Linux
Per prima cosa vorrai installare tutte le dipendenze:
In Terminale, inserisci:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devUna volta installato tutto, digita:
pip install --upgrade pipPer assicurarti che pip sia aggiornato, quindi:
pip install scrapyEd è tutto fatto.
Mac
Per prima cosa devi assicurarti di avere un compilatore c sul tuo sistema. In Terminale, inserisci:
xcode-select --installSuccessivamente, installa homebrew da https://brew.sh/.
Aggiorna la tua variabile PATH in modo che i pacchetti homebrew vengano utilizzati prima dei pacchetti di sistema:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcInstalla Python:
brew install pythonE poi assicurati che tutto sia aggiornato:
brew update; brew upgrade pythonFatto ciò, installa Scrapy usando pip:
pip install Scrapy > ## Panoramica di Scrapy, come i pezzi si incastrano, parser, ragni, eccScriverai uno script chiamato "Spider" per l'esecuzione di Scrapy, ma non preoccuparti, i ragni Scrapy non fanno affatto paura nonostante il loro nome. L'unica somiglianza che hanno i ragni raschiati e i veri ragni è che a loro piace gattonare sul web.
All'interno dello spider c'è una class che definisci che dice a Scrapy cosa fare. Ad esempio, da dove iniziare la scansione, i tipi di richieste che effettua, come seguire i collegamenti nelle pagine e come analizza i dati. Puoi anche aggiungere funzioni personalizzate per elaborare i dati, prima di ritrasmetterli in un file.
Per iniziare il nostro primo ragno, dobbiamo prima creare un progetto Scrapy. Per fare ciò, inserisci questo nella tua riga di comando:
scrapy startproject oscarsQuesto creerà una cartella con il tuo progetto.
Inizieremo con un ragno di base. Il codice seguente deve essere inserito in uno script Python. Apri un nuovo script Python in /oscars/spiders e oscars_spider.py
Importeremo Scrapy.
import scrapyIniziamo quindi a definire la nostra classe Spider. Per prima cosa, impostiamo il nome e poi i domini che lo spider può raschiare. Infine, diciamo al ragno da dove iniziare a raschiare.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']Successivamente, abbiamo bisogno di una funzione che catturi le informazioni che desideriamo. Per ora, prenderemo solo il titolo della pagina. Usiamo i CSS per trovare il tag che contiene il testo del titolo, quindi lo estraiamo. Infine, restituiamo le informazioni a Scrapy per essere registrate o scritte su un file.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data Ora salva il codice in /oscars/spiders/oscars_spider.py
Per eseguire questo ragno, vai semplicemente alla tua riga di comando e digita:
scrapy crawl oscarsDovresti vedere un output come questo:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
Congratulazioni, hai costruito il tuo primo raschietto Scrapy di base!

Codice completo:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataOvviamente, vogliamo che faccia un po' di più, quindi esaminiamo come utilizzare Scrapy per analizzare i dati.
Per prima cosa, acquisiamo familiarità con la shell Scrapy. La shell Scrapy può aiutarti a testare il tuo codice per assicurarti che Scrapy stia acquisendo i dati desiderati.
Per accedere alla shell, inserisci questo nella tua riga di comando:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”Questo fondamentalmente aprirà la pagina a cui l'hai indirizzato e ti consentirà di eseguire singole righe di codice. Ad esempio, puoi visualizzare l'HTML grezzo della pagina digitando:
print(response.text)Oppure apri la pagina nel tuo browser predefinito digitando:
view(response)Il nostro obiettivo qui è trovare il codice che contiene le informazioni che vogliamo. Per ora, proviamo a prendere solo i nomi dei titoli dei film.
Il modo più semplice per trovare il codice di cui abbiamo bisogno è aprire la pagina nel nostro browser e controllare il codice. In questo esempio, sto usando Chrome DevTools. Basta fare clic con il tasto destro del mouse su qualsiasi titolo del film e selezionare "ispeziona":
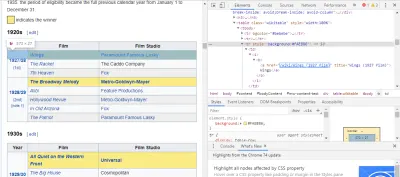
Come puoi vedere, i vincitori dell'Oscar hanno uno sfondo giallo mentre i candidati hanno uno sfondo semplice. C'è anche un collegamento all'articolo sul titolo del film e i collegamenti ai film finiscono in film) . Ora che lo sappiamo, possiamo utilizzare un selettore CSS per acquisire i dati. Nella shell Scrapy, digita:
response.css(r"tr[] a[href*='film)']").extract()Come puoi vedere, ora hai un elenco di tutti i vincitori dell'Oscar per il miglior film!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']Tornando al nostro obiettivo principale, vogliamo un elenco dei vincitori dell'Oscar per il miglior film, insieme al loro regista, agli attori protagonisti, alla data di uscita e alla durata. Per fare ciò, abbiamo bisogno che Scrapy prenda dati da ciascuna di quelle pagine di film.
Dovremo riscrivere alcune cose e aggiungere una nuova funzione, ma non preoccuparti, è piuttosto semplice.
Inizieremo avviando il raschietto nello stesso modo di prima.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] Ma questa volta cambieranno due cose. Innanzitutto, importeremo il time insieme a scrapy perché vogliamo creare un timer per limitare la velocità di scraping del bot. Inoltre, quando analizziamo le pagine per la prima volta, vogliamo ottenere solo un elenco dei collegamenti a ciascun titolo, in modo da poter invece estrarre informazioni da quelle pagine.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req Qui facciamo un ciclo per cercare ogni link nella pagina che finisce in film) con lo sfondo giallo e poi uniamo quei link in un elenco di URL, che invieremo alla funzione parse_titles per passare ulteriormente. Inseriamo anche un timer per richiedere solo pagine ogni 5 secondi. Ricorda, possiamo usare la shell Scrapy per testare i nostri campi response.css per assicurarci di ottenere i dati corretti!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data Il vero lavoro viene svolto nella nostra funzione parse_data , in cui creiamo un dizionario chiamato data e quindi riempiamo ogni chiave con le informazioni che desideriamo. Ancora una volta, tutti questi selettori sono stati trovati utilizzando Chrome DevTools come dimostrato in precedenza e quindi testati con la shell Scrapy.
La riga finale restituisce il dizionario dei dati a Scrapy per l'archiviazione.
Codice completo:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataA volte vorremo utilizzare i proxy poiché i siti Web cercheranno di bloccare i nostri tentativi di scraping.
Per fare questo, abbiamo solo bisogno di cambiare alcune cose. Usando il nostro esempio, nel nostro def parse() , dobbiamo cambiarlo come segue:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqQuesto indirizzerà le richieste attraverso il tuo server proxy.
Distribuzione e registrazione, mostra come gestire effettivamente uno Spider in produzione
Ora è il momento di eseguire il nostro ragno. Per fare in modo che Scrapy inizi lo scraping e quindi l'output in un file CSV, inserisci quanto segue nel prompt dei comandi:
scrapy crawl oscars -o oscars.csvVedrai un output di grandi dimensioni e, dopo un paio di minuti, verrà completato e avrai un file CSV nella cartella del progetto.
Compilazione dei risultati, mostra come utilizzare i risultati compilati nei passaggi precedenti
Quando apri il file CSV, vedrai tutte le informazioni che volevamo (ordinate per colonne con intestazioni). È davvero così semplice.
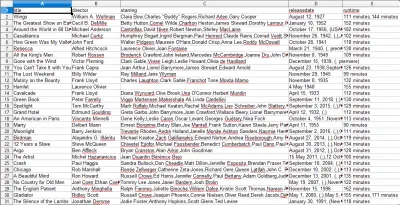
Con lo scraping dei dati, possiamo ottenere quasi tutti i set di dati personalizzati che desideriamo, purché le informazioni siano pubblicamente disponibili. Quello che vuoi fare con questi dati dipende da te. Questa abilità è estremamente utile per fare ricerche di mercato, mantenere aggiornate le informazioni su un sito Web e molte altre cose.
È abbastanza facile configurare il tuo web scraper per ottenere da solo set di dati personalizzati, tuttavia, ricorda sempre che potrebbero esserci altri modi per ottenere i dati di cui hai bisogno. Le aziende investono molto nel fornire i dati che desideri, quindi è giusto che rispettiamo i loro termini e condizioni.
Risorse aggiuntive per saperne di più su Scrapy e Web Scraping in generale
- Il sito ufficiale di Scrapy
- Pagina GitHub di Scrapy
- "I 10 migliori strumenti di scraping dei dati e strumenti di scraping Web", API Scraper
- "5 suggerimenti per il web scraping senza essere bloccati o inseriti nella lista nera", API Scraper
- Parsel, una libreria Python per utilizzare espressioni regolari per estrarre dati da HTML.