
Alberi nella struttura dei dati: 8 tipi di alberi che ogni scienziato di dati dovrebbe conoscere
Pubblicato: 2021-05-26Sommario
introduzione
Nel dominio dell'informatica, le strutture dei dati si riferiscono al modello di disposizione dei dati su un disco, che consente una comoda memorizzazione e visualizzazione. Riguardano il campo della scienza dei dati, che è stato previsto essere una scelta di carriera redditizia nel 2021. Sulla base delle previsioni per i prossimi anni, i modelli di deep learning su larga scala e i dispositivi intelligenti di nuova generazione apriranno il futuro di questo settore.
Pertanto, acquisire la conoscenza delle strutture dei dati sarebbe essenziale per trovare una carriera adeguata in mezzo al progresso tecnologico. Secondo la previsione dell'industria della scienza dei dati del 2021, gli Stati Uniti e l'India impiegherebbero circa 50000 data scientist e 300.000 analisti di dati all'interno delle loro oltre 2.50.000 aziende. [1]
Le strutture dati vengono applicate per progettare i percorsi per l'allocazione, la gestione e il recupero delle informazioni. Le strutture dati sono particolarmente necessarie per elaborare e migliorare l'efficienza dei dati complessivi elaborati. Gestiscono i dati raggruppandoli e organizzandoli per facilitare efficacemente lo scambio di informazioni.
Alberi nelle strutture dati
Gli "alberi" sono un tipo di ADT (Abstract Data Types), che seguono uno schema gerarchico per l'allocazione dei dati. In sostanza, un albero è una raccolta di più nodi collegati tramite bordi. Questi "alberi" formano una struttura di dati che ricorda un albero, in cui il nodo "radice" conduce ai nodi "genitori", che alla fine portano ai nodi "figli". I collegamenti sono realizzati con linee note come 'bordi'.
I nodi 'Leaf' sono endpoint senza ulteriori nodi figlio originati da essi. Gli alberi nelle strutture dati svolgono un ruolo fondamentale a causa della natura non lineare della loro disposizione. Ciò consente tempi di risposta più rapidi durante una ricerca, oltre a praticità durante le fasi di progettazione.
Tipi di alberi nella struttura dei dati
I vari tipi di alberi nelle strutture dati sono spiegati in modo approfondito di seguito:
1. Albero generale
Un albero generale è caratterizzato dalla mancanza di qualsiasi specifica o vincolo sul numero di figli che un nodo può avere. Qualsiasi albero con una struttura gerarchica può essere classificato come albero generale. Un nodo può avere più figli e può esserci qualsiasi tipo di combinazione per l'orientamento dell'albero. I nodi possono essere di qualsiasi grado, da 0 a n.
Di seguito è riportato un classico esempio di albero generale nella struttura dei dati, con '2' in alto come nodo radice.
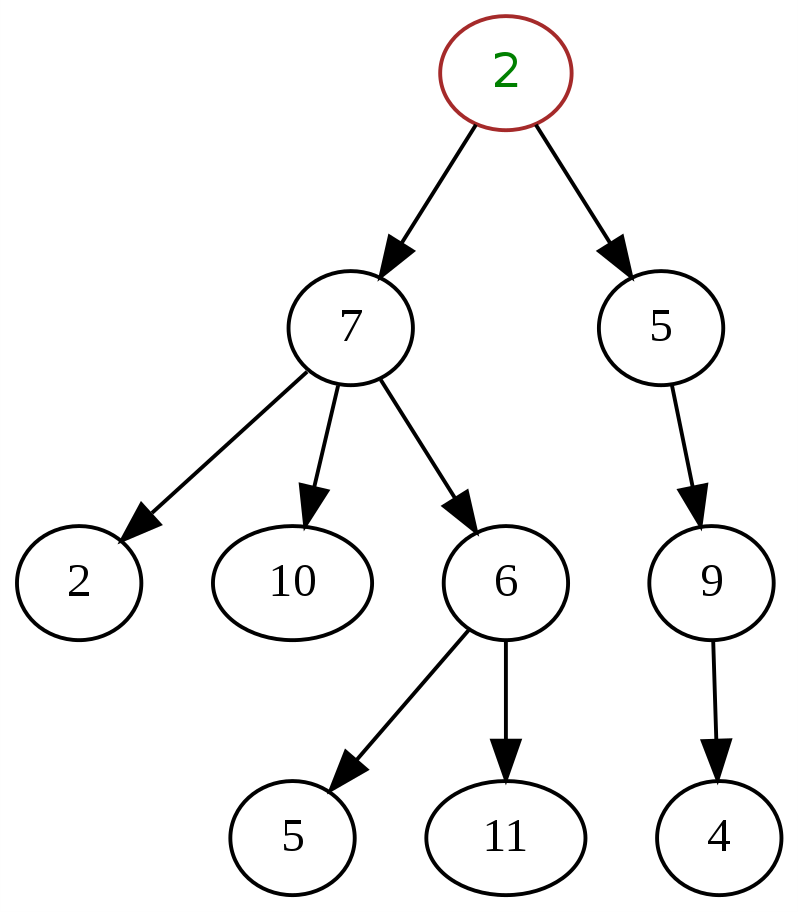
Fonte
2. Albero binario
Come definito dalla parola "binario", che significa due numeri, un albero binario è costituito da nodi che possono avere 2 nodi figli. Qualsiasi nodo in un albero binario può avere 0, 1 o 2 nodi al massimo. Gli alberi binari nelle strutture dati sono ADT altamente funzionali e possono essere ulteriormente suddivisi in molti tipi. Sono utilizzati principalmente nelle strutture di dati per due scopi:
- Per accedere ai nodi ed etichettarli, come osservato in Binary Search Trees.
- Per la rappresentazione dei dati attraverso una struttura biforcuta.
Quello che segue è un diagramma di base di un albero binario in una struttura dati:
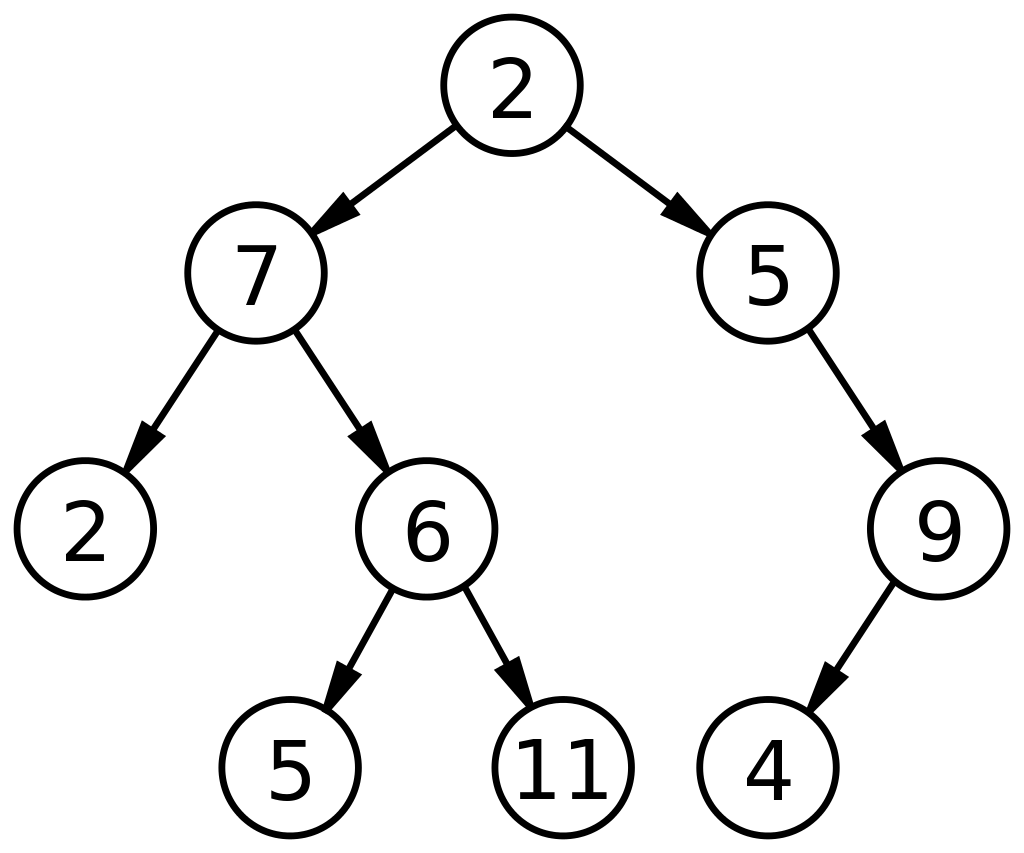
Fonte
3. Albero di ricerca binaria
Un Binary Search Tree (BST) è un sottotipo univoco di alberi binari che sono organizzati in modo da facilitare la ricerca/ricerca o l'aggiunta/rimozione di dati più veloci. Un BST è definito dalla rappresentazione dei nodi in base a tre campi: i dati, il figlio sinistro e il figlio destro. I fattori che governano la BST sono:
- Ogni nodo sul lato sinistro (figlio sinistro) deve contenere un valore inferiore al suo nodo padre.
- Ogni nodo sul lato destro (figlio destro) deve contenere un valore superiore al suo nodo padre.
Tale disposizione riduce i tempi di ricerca alla metà di una ricerca lineare, come trovata in un array. Pertanto, gli alberi di ricerca binari nelle strutture di dati sono ampiamente applicabili per la ricerca e l'ordinamento rispetto ad altri ADT.
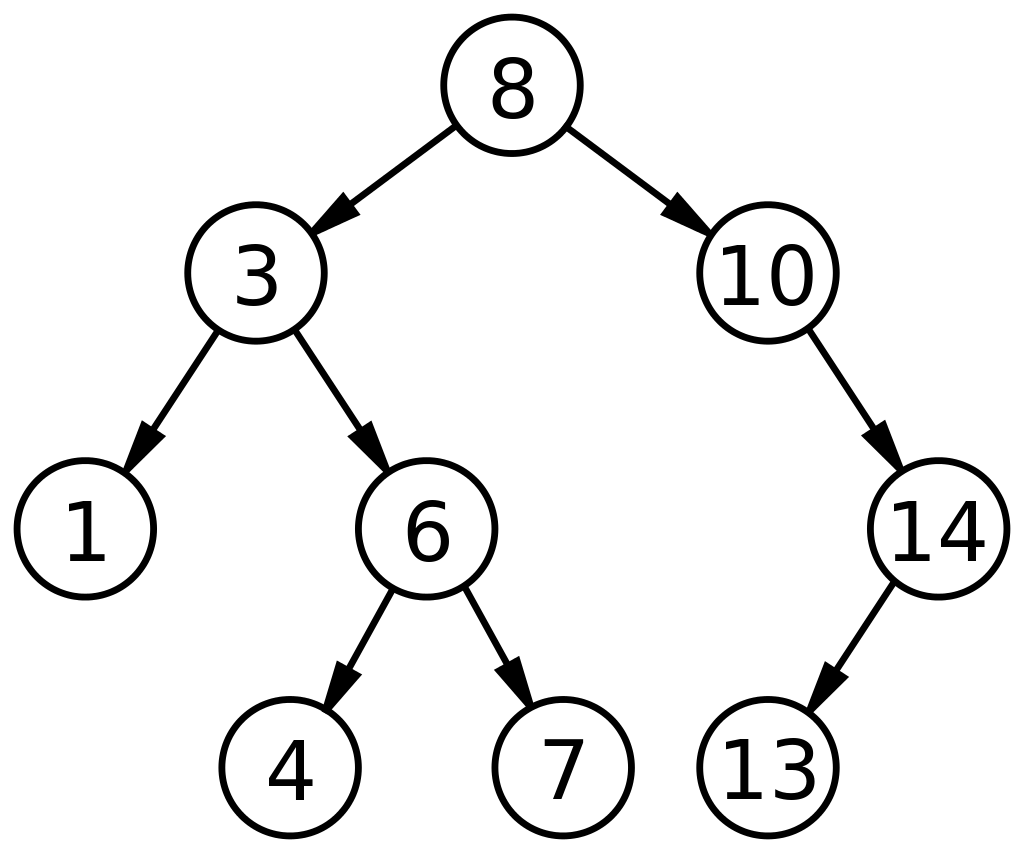
Fonte
Anche se sia BT che BST sono essenzialmente alberi nelle strutture dati , non lasciarti confondere dalla somiglianza dei loro nomi. Scopri in dettaglio la differenza tra un albero binario e un albero di ricerca binario su upGrad.
4. Albero AVL
L'albero AVL prende il nome dai suoi inventori: Adelson-Velsky e Landis. L'albero AVL è caratterizzato da una natura autoequilibrante. Le altezze di due sottoalberi dei suoi nodi radice sono limitate a meno di due. Quando la differenza di altezza aumenta al di sopra di 1, i nodi figli vengono ribilanciati.
Gli alberi AVL sono bilanciati in altezza e questo riequilibrio avviene attraverso rotazioni singole o doppie. Il fattore di bilanciamento è la differenza tra le altezze del sottoalbero sinistro e del sottoalbero destro e i valori sono -1, 0 e 1.
5. Albero nero rosso
Questo tipo ricorda gli alberi AVL poiché anche gli alberi neri rossi sono bilanciati in altezza. Ciò che li separa è che non sono necessarie più di due rotazioni per bilanciarli. Contengono un bit in più che definisce il colore rosso o nero di un nodo, che assicura che gli alberi siano bilanciati durante le eliminazioni e gli inserimenti. Anche la codifica del colore rosso nero viene ridipinta durante le modifiche, ma quasi senza alcun costo aggiuntivo di memoria.

6. Albero strombato
Un altro sottotipo dell'albero di ricerca binario, l'albero splay, ha la proprietà unica di eseguire operazioni di rotazione per regolare il nodo recente. Il nodo a cui si accede di recente viene organizzato come nodo radice eseguendo una rotazione. È un albero equilibrato, ma non equilibrato in altezza.
L'atto di "visualizzazione" viene eseguito dopo la ricerca iniziale dell'albero binario, poiché le rotazioni dell'albero vengono eseguite in un modo specifico. Dopo ogni operazione, l'albero viene ruotato per bilanciarsi e l'elemento cercato viene posizionato in alto come nodo radice.
7. Trappola
I "treap" nelle strutture di dati sono una combinazione di alberi e heap. Nei BST, il valore del figlio sinistro deve essere inferiore al nodo radice e il valore del figlio destro deve essere maggiore. In una struttura di dati heap, il nodo radice ha il valore più basso e i suoi nodi figlio (sia a sinistra che a destra) hanno valori più grandi.
Pertanto, un treap contiene un valore sotto forma di una chiave (simile ai BST) e una priorità (come gli heap). I nodi con priorità più alta vengono inseriti per primi in un albero di ricerca binario in modo che i numeri di priorità siano numeri casuali indipendenti. Mantengono un insieme dinamico di chiavi ordinate e consentono ricerche binarie all'interno delle loro chiavi.
8. Albero B
Essendo un tipo di albero autobilanciato nelle strutture di dati, B-Tree ordina i dati per consentire la ricerca, l'accesso sequenziale, le eliminazioni e gli inserimenti in tempo logaritmico. A differenza di un albero binario, un albero B consente ai suoi nodi di avere più di due figli. Sono compatibili con database e file system che leggono e scrivono blocchi di dati più grandi.
Un B-tree nelle strutture dati viene utilizzato per sistemi di archiviazione più grandi, come i dischi. Tutte le foglie non portano informazioni e appaiono all'interno dello stesso livello. I nodi interni di un B-tree possono avere una dimensione variabile di nodi figlio delimitati da un intervallo.
Questi sono gli alberi nelle strutture dati , che vengono implementati dai programmatori che progettano il flusso di dati. Imparare le loro caratteristiche e applicazioni uniche è essenziale per diventare un data scientist. Un altro metodo per migliorare te stesso sarebbe esercitarti attraverso vari progetti che richiedono la conoscenza degli alberi nelle strutture dati e in altre forme di ADT.
Per applicare le tue conoscenze ai progetti DS, i seguenti link al blog hanno 13 idee e argomenti interessanti per progetti di struttura dati per principianti [2021] .
Conclusione
L'apprendimento di concetti come gli alberi in una struttura di dati può essere complicato e gli aspiranti alla programmazione hanno bisogno di una guida esperta per istruirsi. Per saperne di più sugli alberi in una struttura dati, dai un'occhiata ai corsi online di upGrad . Programma Executive PG in Software Development – La specializzazione in DevOps con DevOps di IIIT-B e upGrad può aiutarti a costruire la tua carriera di programmatore.
Poiché la padronanza delle strutture dati è parte integrante del processo di codifica, può aiutare lo studente a diventare un programmatore esperto e uno sviluppatore di software. I programmatori e gli scienziati dei dati saranno sicuramente richiesti per i decenni a venire.
Abbiamo 500 milioni di utenti Internet in India, che generano e consumano grandi quantità di dati, che richiedono l'impiego di migliaia di data scientist per soddisfare la domanda. [2] Questi data scientist hanno bisogno della giusta istruzione, con competenze tecnologiche pertinenti, per cercare lavoro in questo settore.
Un programma Executive PG in Software Development - Specializzazione in Full Stack Development , curato da upGrad e IIIT-Bangalore, può aiutarti a migliorare il tuo profilo e garantire migliori opportunità di lavoro come programmatore.
- Un albero di ricerca è una struttura di dati che viene utilizzata per individuare determinate chiavi all'interno di un insieme di dati. La chiave di ogni nodo deve essere più grande di qualsiasi chiave nei sottoalberi a sinistra ma inferiore alle chiavi nei sottoalberi appena a destra affinché un albero agisca come un albero di ricerca. I dati gerarchici, come la struttura delle cartelle, la struttura organizzativa e i dati XML/HTML, devono essere archiviati in alberi. Un albero binario perfetto è quello in cui ogni nodo interno ha due discendenti e ogni foglia ha la stessa profondità o livello. La carta degli antenati (non incestuosi) di una persona a una profondità particolare è un esempio di un perfetto albero binario, poiché ogni persona ha esattamente due genitori biologici (una madre e un padre).Che tipo di alberi possono essere utilizzati per la ricerca?<br />
- Quando l'albero è abbastanza equilibrato, cioè le foglie alle due estremità hanno profondità equivalenti, gli alberi di ricerca hanno un vantaggio in termini di tempo di ricerca. Esistono diverse strutture di dati dell'albero di ricerca, alcune delle quali consentono inoltre l'inserimento e l'eliminazione efficienti degli elementi, le cui azioni devono quindi preservare l'equilibrio dell'albero.
- Un array associativo viene spesso implementato utilizzando alberi di ricerca. L'algoritmo dell'albero di ricerca individua un luogo utilizzando la chiave dalla coppia chiave-valore, quindi l'applicazione memorizza la coppia chiave-valore completa in quella posizione.
- Gli alberi di ricerca binari, gli alberi B, gli alberi (a,b) e gli alberi di ricerca ternari sono esempi di alberi di ricerca. Quali sono le principali applicazioni della struttura dati ad albero?
1. Un albero di ricerca binario è un albero che consente di cercare, inserire ed eliminare rapidamente i dati che sono stati ordinati. Ti aiuta anche a localizzare l'oggetto più vicino a te.
2. Heap è una struttura di dati ad albero che utilizza array e viene utilizzata per costruire code di priorità.
3. B-Tree e B+ Tree sono due tipi di alberi di indicizzazione utilizzati nei database.
4. I compilatori utilizzano l'albero della sintassi.
5. Un albero di partizionamento dello spazio utilizzato per organizzare i punti nello spazio dimensionale K è noto come albero KD.
6. Trie è una struttura di dati utilizzata per creare dizionari con ricerca di prefissi.
7. L'albero dei suffissi viene utilizzato per cercare rapidamente i modelli in un testo fisso.
8. Nelle reti di computer, router e bridge utilizzano rispettivamente spanning tree e shortest path tree. Cos'è un albero perfetto?