
Le 15 migliori domande e risposte per le interviste Hadoop nel 2022
Pubblicato: 2021-01-09Con l'aumento dell'analisi dei dati, c'è stato un aumento della domanda di persone in grado di gestire i Big Data. Da analisti di dati a scienziati di dati, oggi i Big Data stanno creando una serie di profili professionali. La prima e più importante cosa con cui dovresti essere pratico è Hadoop.
Indipendentemente dal ruolo/profilo lavorativo, probabilmente lavorerai su Hadoop in un modo o nell'altro. Quindi, puoi invariabilmente aspettarti che gli intervistatori girino alcune domande su Hadoop a modo tuo.
Per questo e altro, diamo un'occhiata alle 15 principali domande dell'intervista Hadoop che ci si può aspettare in qualsiasi intervista a cui ti siedi.
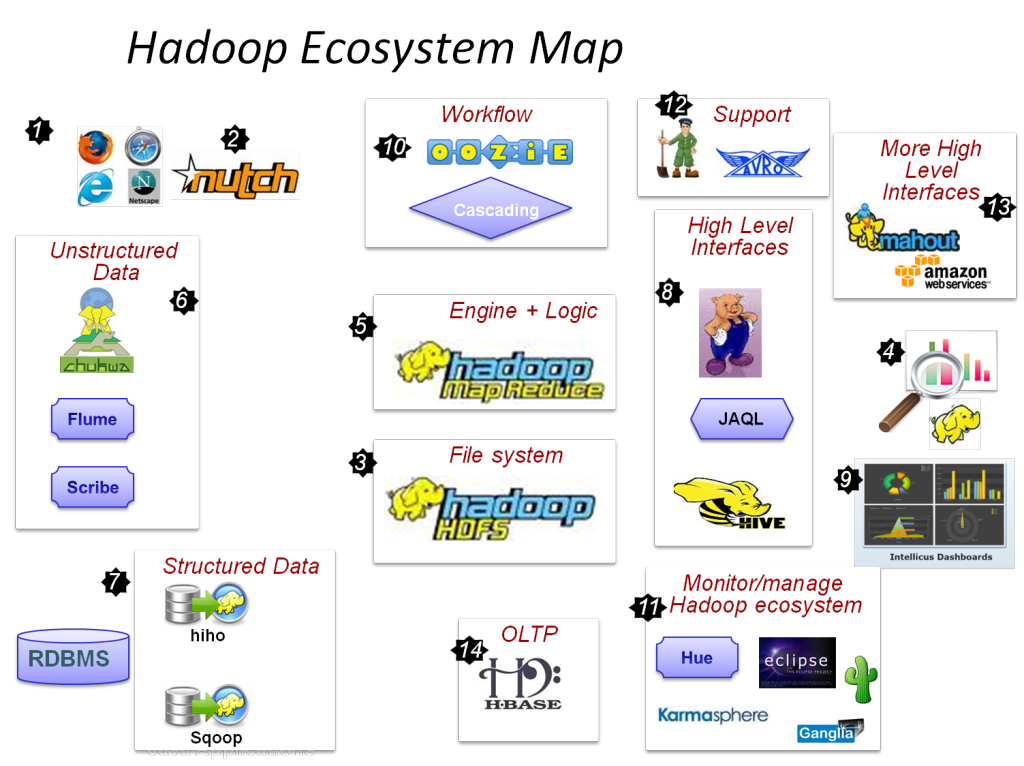
Cos'è Hadoop? Quali sono i componenti principali Hadoop?
Hadoop è un'infrastruttura dotata di strumenti e servizi pertinenti necessari per elaborare e archiviare i Big Data. Per essere precisi, Hadoop è la 'soluzione' a tutte le sfide dei Big Data. Inoltre, il framework Hadoop aiuta anche le organizzazioni ad analizzare i Big Data e prendere decisioni aziendali migliori.
I componenti principali di Hadoop sono:
- HDFS
- Hadoop MapReduce
- Hadoop comune
- FILATO
- PIG e HIVE – I componenti per l'accesso ai dati.
- HBase: per l'archiviazione dei dati
- Ambari, Oozie e ZooKeeper - Componente di gestione e monitoraggio dei dati
- Thrift e Avro: componenti per la serializzazione dei dati
- Apache Flume, Sqoop, Chukwa: i componenti di integrazione dei dati
- Apache Mahout e Drill – Componenti di Data Intelligence
Quali sono i concetti chiave del framework Hadoop?
Hadoop si basa fondamentalmente su due concetti fondamentali. Loro sono:
- HDFS: HDFS o Hadoop Distributed File System è un file system affidabile basato su Java utilizzato per archiviare vasti set di dati nel formato a blocchi. L'architettura Master-Slave lo alimenta.
- MapReduce: MapReduce è una struttura di programmazione che aiuta a elaborare grandi set di dati. Questa funzione è ulteriormente suddivisa in due parti: mentre "map" separa i set di dati in tuple, "reduce" utilizza le tuple della mappa e crea una combinazione di blocchi più piccoli di tuple.
Assegna un nome ai formati di input più comuni in Hadoop?
Esistono tre formati di input comuni in Hadoop:
- Formato di input del testo: questo è il formato di input predefinito in Hadoop.
- Formato di input del file di sequenza: questo formato di input viene utilizzato per leggere i file in sequenza.
- Formato di input del valore chiave: questo viene utilizzato per leggere file di testo normale.
Cos'è YARN?
YARN è l'abbreviazione di Yet Another Resource Negotiator. È il framework di elaborazione dati di Hadoop che gestisce le risorse di dati e crea un ambiente per un'elaborazione di successo. 
Che cos'è la "consapevolezza del rack"?
"Rack Awareness" è un algoritmo che NameNode utilizza per determinare il modello in cui i blocchi di dati e le relative repliche sono archiviati all'interno del cluster Hadoop. Ciò si ottiene con l'aiuto di definizioni di rack che riducono la congestione tra i nodi di dati contenuti nello stesso rack.

Cosa sono i NameNode attivi e passivi?
Un sistema Hadoop ad alta disponibilità di solito contiene due NameNode: Active NameNode e Passive NameNode.
Il NameNode che esegue il cluster Hadoop è denominato Active NameNode e il NameNode in standby che archivia i dati dell'Active NameNode è Passive NameNode.
Lo scopo di avere due NameNode è che se il NameNode attivo si arresta in modo anomalo, il NameNode passivo può prendere il comando. Pertanto, il NameNode è sempre in esecuzione nel cluster e il sistema non si guasta mai.
Quali sono i diversi scheduler nel framework Hadoop?
Ci sono tre diversi schedulatori nel framework Hadoop:
- COSHH – COSHH aiuta a pianificare le decisioni rivedendo il cluster e il carico di lavoro combinati con l'eterogeneità.
- FIFO Scheduler – FIFO allinea i lavori in una coda in base all'ora di arrivo, senza utilizzare l'eterogeneità.
- Condivisione equa: la condivisione equa crea un pool per i singoli utenti contenente più mappe e riduce gli slot su una risorsa che possono utilizzare per eseguire lavori specifici.
Che cos'è l'esecuzione speculativa?
Spesso nel framework Hadoop, alcuni nodi possono essere eseguiti più lentamente degli altri. Questo tende a vincolare l'intero programma. Per ovviare a questo, Hadoop prima rileva o "specula" quando un'attività viene eseguita più lentamente del solito, quindi avvia un backup equivalente per tale attività. Quindi, nel processo, il nodo master esegue entrambe le attività contemporaneamente e quella che viene completata per prima viene accettata mentre l'altra viene interrotta. Questa funzionalità di backup di Hadoop è nota come esecuzione speculativa.

Nominare i componenti principali di Apache HBase?
Apache HBase è composto da tre componenti:
- Server della regione: dopo che una tabella è stata divisa in più regioni, i cluster di queste regioni vengono inoltrati ai client tramite il server della regione.
- HMaster: questo è uno strumento che aiuta a gestire e coordinare il server della regione.
- ZooKeeper: ZooKeeper è un coordinatore all'interno dell'ambiente distribuito HBase. Aiuta a mantenere uno stato del server all'interno del cluster attraverso la comunicazione nelle sessioni.
Che cos'è il "punto di controllo"? Qual è il suo vantaggio?
Il checkpoint si riferisce alla procedura mediante la quale un registro FsImage e Edit vengono combinati per formare una nuova FsImage. Pertanto, invece di riprodurre il registro delle modifiche, NameNode può caricare direttamente lo stato in memoria finale da FsImage. Il NameNode secondario è responsabile di questo processo.
Il vantaggio offerto da Checkpointing è che riduce al minimo il tempo di avvio del NameNode, rendendo così l'intero processo più efficiente.
Applicazioni Big Data nella cultura pop
Come eseguire il debug di un codice Hadoop?
Per eseguire il debug di un codice Hadoop, devi prima controllare l'elenco delle attività MapReduce attualmente in esecuzione. Quindi è necessario verificare se le attività orfane sono in esecuzione contemporaneamente. In tal caso, è necessario trovare la posizione dei registri di Gestione risorse seguendo questi semplici passaggi:
Esegui “ps –ef | grep –I ResourceManager” e nel risultato visualizzato, prova a trovare se è presente un errore relativo a un ID lavoro specifico.
Ora, identifica il nodo di lavoro che è stato utilizzato per eseguire l'attività. Accedi al nodo ed esegui “ps –ef | grep –iNodeManager.”
Infine, esamina il registro di Node Manager. La maggior parte degli errori viene generata dai registri a livello di utente per ogni processo di riduzione della mappa.
Qual è lo scopo di RecordReader in Hadoop?
Hadoop suddivide i dati in formati di blocco. RecordReader aiuta a integrare questi blocchi di dati in un unico record leggibile. Ad esempio, se i dati di input sono divisi in due blocchi –
Riga 1 – Benvenuti a
Riga 2 – Aggiornamento
RecordReader lo leggerà come "Benvenuto in UpGrad ".
Quali sono le modalità in cui può funzionare Hadoop?
Le modalità in cui Hadoop può essere eseguito sono:
- Modalità standalone: questa è una modalità predefinita di Hadoop utilizzata per scopi di debug. Non supporta HDFS.
- Modalità pseudodistribuita: questa modalità richiedeva la configurazione dei file mapred-site.xml, core-site.xml e hdfs-site.xml. Sia il nodo Master che Slave sono gli stessi qui.
- Modalità completamente distribuita: la modalità completamente distribuita è la fase di produzione di Hadoop in cui i dati vengono distribuiti su vari nodi su un cluster Hadoop. Qui, i nodi Master e Slave sono assegnati separatamente.
Nomina alcune applicazioni pratiche di Hadoop.
Ecco alcuni esempi di vita reale in cui Hadoop sta facendo la differenza:
- Gestione del traffico stradale
- Rilevamento e prevenzione delle frodi
- Analizza i dati dei clienti in tempo reale per migliorare il servizio clienti
- Accesso a dati medici non strutturati di medici, operatori sanitari, ecc., per migliorare i servizi sanitari.
Quali sono gli strumenti Hadoop vitali che possono migliorare le prestazioni dei Big Data?
Gli strumenti Hadoop che migliorano significativamente le prestazioni dei Big Data lo sono

• Alveare
• HDFS
• Base H
• SQL
• NoSQL
• Oozie
• Nuvole
• Avro
• Canale
• Custode dello zoo
Big Data Engineers: miti contro realtà
Conclusione
Queste domande dell'intervista Hadoop dovrebbero esserti di grande aiuto nella tua prossima intervista. Sebbene a volte sia la tendenza degli intervistatori a distorcere alcune domande dell'intervista Hadoop, non dovrebbe essere un problema per te se hai ordinato le tue basi.
Se sei interessato a saperne di più sui Big Data, dai un'occhiata al nostro PG Diploma in Software Development Specialization nel programma Big Data, progettato per professionisti che lavorano e fornisce oltre 7 casi di studio e progetti, copre 14 linguaggi e strumenti di programmazione, pratiche pratiche workshop, oltre 400 ore di apprendimento rigoroso e assistenza all'inserimento lavorativo con le migliori aziende.