
La matematica dietro l'apprendimento automatico: cosa devi sapere?
Pubblicato: 2021-03-10L'apprendimento automatico è una divisione dell'IA che si concentra sulla creazione di applicazioni elaborando accuratamente i dati disponibili. L'obiettivo principale dell'apprendimento automatico è aiutare i computer a elaborare i calcoli senza l'intervento umano. Ciò è reso possibile consentendo a una macchina di imparare a imitare l'intelligenza umana tramite metodi di apprendimento supervisionati o non supervisionati.
L'apprendimento automatico è una combinazione di molti campi che include statistica, probabilità, algebra lineare, calcolo e così via, in base ai quali un modello di apprendimento automatico può creare o alimentare algoritmi per improvvisare secondo l'intelligenza umana. Più complessa è l'applicazione, più complesso sarà il suo algoritmo.
Dagli assistenti digitali e dispositivi intelligenti ai siti Web che consigliano i tuoi prodotti preferiti in base alle tue attività online e ai telefoni cellulari che ti informano dell'orario dei voli, prodotti e strumenti basati sull'apprendimento automatico sono tutti intorno a noi. Con l'aumentare della nostra dipendenza da dispositivi ed elettrodomestici intelligenti, aumenterà anche la necessità di implementare l'apprendimento automatico.
A tal fine, in questo articolo, esploreremo i concetti matematici necessari per scrivere algoritmi di apprendimento automatico e implementarli.
Sommario
Qual è il significato della matematica nell'apprendimento automatico?
Le applicazioni di apprendimento automatico forniscono analisi e approfondimenti raccolti dai dati disponibili che contribuiscono a un processo decisionale attuabile nelle aziende. Poiché l'apprendimento automatico ruota attorno allo studio e all'implementazione di algoritmi, è importante rafforzare le tue abilità matematiche. Aiuta a eliminare l'incertezza e prevedere con precisione i valori dei dati laddove sono coinvolti parametri e caratteristiche dei dati complessi. Ci aiuta anche a comprendere meglio il compromesso Bias-Variance.
Padroneggiare l'apprendimento automatico richiede la conoscenza di concetti matematici come algebra lineare, calcolo vettoriale, geometria analitica, scomposizioni di matrici, probabilità e statistica. Una buona conoscenza di questi aiuta nella creazione di applicazioni di apprendimento automatico intuitive.

Algebra lineare
L'algebra lineare si occupa di vettori e matrici e ruota principalmente attorno al calcolo. Svolge un ruolo fondamentale nelle tecniche di machine learning e deep learning. Secondo Skyler Speakman , è la matematica del 21° secolo.
L'algebra lineare viene in genere utilizzata da ingegneri ML e data scientist o ricercatori per creare algoritmi lineari, regressioni logistiche, alberi decisionali e macchine vettoriali di supporto.
Calcolo
Il calcolo guida gli algoritmi di apprendimento automatico. Senza la conoscenza dei suoi concetti, non sarebbe possibile prevedere i risultati utilizzando un determinato set di dati. Il calcolo aiuta ad analizzare la velocità con cui le quantità cambiano e si occupa delle prestazioni ottimali degli algoritmi di apprendimento automatico. Integrazioni, differenziali, limiti e derivati sono alcuni concetti di calcolo che aiutano ad addestrare reti neurali profonde.
Probabilità
La probabilità nell'apprendimento automatico prevede l'insieme dei risultati, mentre le statistiche guidano il risultato favorevole alla sua conclusione. L'evento potrebbe essere semplice come lanciare una moneta. La probabilità può essere suddivisa in due categorie: probabilità condizionale e probabilità articolare. La probabilità congiunta si verifica quando gli eventi sono indipendenti l'uno dall'altro, mentre la probabilità condizionata si verifica quando un evento sostituisce l'altro.
Statistiche
La statistica si concentra sugli aspetti quantitativi e qualitativi dell'algoritmo. Ci aiuta a identificare gli obiettivi e trasformare i dati raccolti in osservazioni precise presentandoli in modo conciso. Le statistiche nell'apprendimento automatico si concentrano su statistiche descrittive e statistiche inferenziali.
La statistica descrittiva si occupa di descrivere e riassumere il piccolo set di dati su cui sta lavorando un modello. I metodi qui utilizzati sono media, mediana, moda, deviazione standard e variazione. I risultati finali sono presentati come rappresentazioni pittoriche.
La statistica inferenziale si occupa dell'estrazione di informazioni dettagliate da un determinato campione mentre si lavora con un set di dati di grandi dimensioni. Le statistiche inferenziali consentono alle macchine di analizzare i dati oltre l'ambito delle informazioni fornite. I test di ipotesi, le distribuzioni campionarie, l'analisi della varianza, sono alcuni aspetti della statistica inferenziale.
Oltre a questi, l'abilità di codifica è un prerequisito cruciale per l'apprendimento automatico. L'esperienza in linguaggi come Python e Java aiuta a comprendere meglio la modellazione dei dati. Formattazione di stringhe, definizione di funzioni, loop con più iteratori di variabili, se oppure espressioni condizionali sono alcune delle sue funzioni di base.
Per quanto riguarda la modellazione dei dati, è il processo attraverso il quale stimiamo la struttura dei set di dati e rileviamo possibili variazioni e modelli. Per poter fare previsioni accurate, è necessario essere consapevoli delle varie proprietà dei dati collettivi.
Come puoi imparare l'apprendimento automatico?
Sebbene l'apprendimento automatico sia un campo redditizio in cui entrare, richiede molta pratica e pazienza. Date le sue applicazioni in quasi tutti i settori oggi, gli ingegneri di machine learning sono molto richiesti.
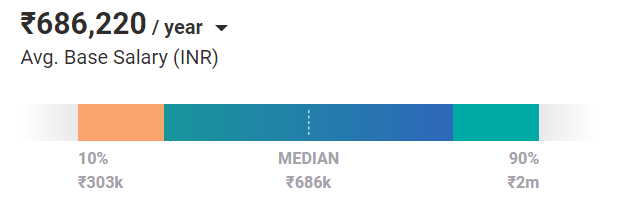
Lo stipendio medio di un ingegnere di livello base con un background in machine learning è di Rs 686k/anno. E con l'esperienza e il miglioramento delle competenze, il potenziale per guadagnare uno stipendio più alto aumenta in modo esponenziale.
Sono disponibili diversi corsi per chi desidera migliorare la propria base di conoscenze nell'apprendimento automatico. Ci vorrebbe un minimo di 6 mesi a 2 anni per padroneggiare la materia.
Con un minimo di una laurea e un anno di esperienza lavorativa, meglio ancora una laurea in matematica o statistica, puoi seguire uno qualsiasi dei seguenti corsi su upGrad per aumentare le tue possibilità di successo nel campo.
- Advanced Certificate Program in Machine Learning e Deep Learning da IIT Bangalore (6 mesi)
- Advanced Certificate Program in Machine Learning e NLP di IIT Bangalore (6 mesi)
- Programma Executive PG in Machine Learning e AI di IIT Bangalore (12 mesi)
- Certificazione Avanzata in Machine Learning e Cloud da IIT Madras (12 mesi)
- Master of Science in Machine Learning e AI presso LJMU e IIT Bangalore (18 mesi)
Tutti questi corsi offrono un minimo di 240+ ore di apprendimento e almeno 5 casi di studio che ti aiuterebbero ad acquisire una comprensione approfondita dell'apprendimento automatico e dei suoi vari campi ausiliari. Puoi coprire argomenti essenziali come Python, MySQL, Tensor, NLTK, statsmodels, excel, ecc. che costituiscono la spina dorsale della codifica. Ecco uno sguardo dettagliato ai vari corsi upGrad in Machine learning in modo da poter scegliere quello più adatto a te.

Partecipa al corso di intelligenza artificiale online dalle migliori università del mondo: master, programmi post-laurea esecutivi e programma di certificazione avanzata in ML e AI per accelerare la tua carriera.
Applicazioni dell'apprendimento automatico
L'apprendimento automatico gioca un ruolo cruciale nella nostra vita quotidiana, sia nella sfera professionale che personale. Le sue capacità analitiche e intuitive hanno il potenziale per avere un impatto drastico sul modo in cui svolgiamo le nostre attività quotidiane. Si è dimostrato pieno di risorse nel risparmiare tempo e denaro per un'organizzazione.
Sebbene l'apprendimento automatico sia un campo ampio con applicazioni in quasi tutti i settori, ecco alcuni esempi più importanti:
- Il riconoscimento delle immagini è una delle applicazioni più comunemente utilizzate in quanto aiuta nel rilevamento dei volti, creando così un database separato per ogni individuo. Può essere utilizzato anche per identificare gli stili di scrittura a mano.
- L'apprendimento automatico nel settore sanitario ha migliorato le capacità degli operatori sanitari. Può essere utilizzato per una diagnosi medica più rapida. In molti casi, l'IA ha aiutato nella diagnosi precoce delle malattie, consentendo così ai medici di suggerire trattamenti e misure preventive che hanno il potenziale per salvare vite umane.
- L'apprendimento automatico ha importanti applicazioni nel settore finanziario per quanto riguarda investimenti, fusioni e acquisizioni. Aiuta le banche e altre istituzioni economiche a fare scelte intelligenti.
- La sua efficacia è forse più evidente nel settore dell'assistenza clienti e dei servizi poiché l'apprendimento automatico semplifica le operazioni e fornisce soluzioni in modo rapido ed efficiente.
- L'apprendimento automatico automatizza le attività che altrimenti dovrebbero essere eseguite da un essere umano sul campo. Ad esempio, se dovessimo prendere in considerazione gli assistenti virtuali, potrebbe essere un compito semplice come cambiare la password o controllare la sera il tuo conto in banca. Con l'apprendimento automatico, ora è possibile allocare le risorse umane a compiti più urgenti che richiedono un processo decisionale complicato o un tocco umano per essere eseguiti.
Ambito futuro dell'apprendimento automatico
Anche se l'apprendimento automatico è in circolazione da decenni, la sua applicazione è più evidente oggi. Il settore deve ancora prosperare e improvvisare, il che implica che il futuro dell'apprendimento automatico è luminoso. La maggior parte delle aziende su larga scala sta già raccogliendo i vantaggi dell'apprendimento automatico e sta ridimensionando i propri servizi e prodotti per favorire la crescita.
Naturalmente, gli ingegneri ML sono molto richiesti e l'apprendimento automatico si presenta come una carriera redditizia in cui entrare. Rappresenta per le aziende il vantaggio di cui hanno bisogno. Finora l'IA ha generato circa 2,3 milioni di opportunità di lavoro. È stato previsto che, entro la fine del 2022, l' industria globale del riciclaggio di denaro crescerà a un CAGR del 42,2% per raggiungere i 9 miliardi di dollari .
Ecco alcune delle principali tendenze nell'apprendimento automatico:
- Sempre più algoritmi stanno imparando verso implementazioni non supervisionate. Le aziende stanno investendo nel Quantum Computing basato su questi algoritmi non supervisionati che hanno il potenziale per trasformare l'apprendimento automatico. Questi contribuiscono ad analizzare e trarre informazioni significative, aiutando così le aziende a ottenere risultati migliori che non sarebbero stati possibili utilizzando le classiche tecniche di apprendimento automatico.
- I robot basati sull'intelligenza artificiale vengono implementati per svolgere operazioni aziendali. Tuttavia, queste tecnologie sono in una fase nascente e poiché le aziende investono nella creazione di un punto d'appoggio di IA e ML, i robot aiuteranno presto ad aumentare la produttività in modo esponenziale. Per citare come esempio, abbiamo i droni che si presentano come potenti strumenti di business nel mercato dei consumatori, dove vengono utilizzati per eseguire operazioni commerciali e compiti semplici come la consegna di merci.
- Gli algoritmi di apprendimento automatico supportano la personalizzazione avanzata. Questi algoritmi esaminano il comportamento online dei potenziali clienti e inviano le informazioni alle aziende. Le aziende a loro volta inviano loro prodotti e consigli sui servizi. Queste tecniche di apprendimento automatico aiutano a identificare i gusti e le antipatie dei clienti. Attraverso l'apprendimento automatico, le aziende offrono ai propri clienti ciò che desiderano e quando lo desiderano, il che aumenta la fidelizzazione dei clienti e attira più affari nell'organizzazione. Una migliore personalizzazione è il futuro dell'apprendimento automatico.
- Grazie agli algoritmi di machine learning avanzati, le applicazioni mobili e web sono ora più intelligenti che mai. I servizi cognitivi migliorati consentono agli sviluppatori di creare database separati per ciascun client, basati sul riconoscimento visivo, sul parlato, sul suono, sulla voce e così via.
Questo ci porta alla fine dell'articolo. Ci auguriamo che tu abbia trovato queste informazioni utili!
Perché l'omoscedasticità è richiesta nella regressione lineare?
L'omoscedasticità descrive quanto simili o quanto lontano i dati si discostano dalla media. Questa è un'ipotesi importante da fare perché i test statistici parametrici sono sensibili alle differenze. L'eteroscedasticità non induce bias nelle stime dei coefficienti, ma ne riduce la precisione. Con una precisione inferiore, è più probabile che le stime dei coefficienti si discostino dal valore corretto della popolazione. Per evitare ciò, l'omoscedasticità è un presupposto cruciale da affermare.
Quali sono i due tipi di multicollinearità nella regressione lineare?
I dati e la multicollinearità strutturale sono i due tipi fondamentali di multicollinearità. Quando creiamo un termine modello da altri termini, otteniamo multicollinearità strutturale. In altre parole, più che essere presente nei dati stessi, è il risultato del modello che forniamo. Sebbene la multicollinearità dei dati non sia un artefatto del nostro modello, è presente nei dati stessi. La multicollinearità dei dati è più comune nelle indagini osservazionali.
Quali sono gli svantaggi dell'utilizzo di t-test per i test indipendenti?
Ci sono problemi con la ripetizione delle misurazioni invece delle differenze tra i progetti di gruppo quando si utilizzano test t di campioni accoppiati, il che porta a effetti di riporto. A causa di errori di tipo I, il test t non può essere utilizzato per confronti multipli. Sarà difficile rifiutare l'ipotesi nulla quando si esegue un t-test accoppiato su un insieme di campioni. Ottenere i soggetti per i dati del campione è un aspetto costoso e dispendioso in termini di tempo del processo di ricerca.