
Pipeline di test 101 per test front-end
Pubblicato: 2022-03-10Immagina questa situazione: ti stai avvicinando rapidamente a una scadenza e stai utilizzando ogni minuto libero per raggiungere il tuo obiettivo di completare questo complesso refactoring, con molte modifiche ai tuoi file CSS. Stai anche lavorando sugli ultimi passaggi durante il tuo viaggio in autobus. Tuttavia, i tuoi test locali sembrano fallire ogni volta e non riesci a farli funzionare. Il tuo livello di stress sta aumentando .
C'è davvero una scena simile in una serie ben nota: è della terza stagione della serie TV di Netflix, "Come vendere droga online (veloce)":
Cypress + Vue è presente *IN UN PROGRAMMA TV NETFLIX*
— jess (@_jessicasachs) 7 agosto 2021
È una commedia intitolata "Come vendere droga (veloce)" e contiene alcune delle rappresentazioni più realistiche di webdev.
Stagione 3, Episodio 1 @ 20:20 e una o due volte prima. pic.twitter.com/ICSAwMxyFB
Beh, almeno sta usando dei test, potresti pensare. Perché è ancora in pericolo, potresti chiederti? C'è ancora molto spazio per migliorare e per evitare una situazione del genere, anche se scrivi dei test. Come pensi di monitorare la tua base di codice e tutte le modifiche dall'inizio? Di conseguenza, non sperimenterai queste brutte sorprese, giusto? Non è troppo difficile includere tali routine di test automatizzate: creiamo insieme questa pipeline di test dall'inizio alla fine.
Andiamo!
Per prima cosa: termini di base
Una routine di costruzione può aiutarti a rimanere fiducioso nel refactoring più complesso, anche nei tuoi piccoli progetti collaterali. Tuttavia, ciò non significa che devi essere un ingegnere DevOps. È essenziale imparare un paio di termini e strategie, ed è per questo che sei qui, giusto? Fortunatamente sei nel posto giusto! Iniziamo con i termini fondamentali che incontrerai presto quando avrai a che fare con una pipeline di test per il tuo progetto front-end.
Se cerchi su Google il mondo dei test in generale, può succedere che ti sia già imbattuto nei termini "CI/CD" come uno dei primi termini. È l'abbreviazione di "Integrazione continua, distribuzione continua" e "Distribuzione continua" e descrive esattamente questo: come probabilmente avrai già sentito, è un metodo di distribuzione del software utilizzato dai team di sviluppo per distribuire le modifiche al codice in modo più frequente e affidabile. CI/CD implica due approcci complementari, che si basano fortemente sull'automazione.
- Integrazione continua
È un termine per misure di automazione per implementare piccole modifiche al codice regolari e unirle in un repository condiviso. L'integrazione continua include le fasi di creazione e test del codice.
CD è l'acronimo di "Continuous Delivery" e "Continuous Deployment", entrambi concetti simili tra loro ma talvolta utilizzati in contesti diversi. La differenza tra i due risiede nell'ambito dell'automazione:
- Consegna continua
Si riferisce al processo del codice che era già stato testato in precedenza, da cui il team operativo può ora distribuirlo in un ambiente di produzione live. Tuttavia, quest'ultimo passaggio potrebbe essere manuale. - Distribuzione continua
Si concentra sull'aspetto della "distribuzione", come suggerisce il nome. È un termine per il processo di rilascio completamente automatizzato delle modifiche degli sviluppatori dal repository direttamente alla produzione, dove il cliente può utilizzarle direttamente.
Tali processi mirano a consentire a sviluppatori e team di avere un prodotto, che è possibile rilasciare in qualsiasi momento se lo desiderano: avere la sicurezza di un'applicazione continuamente monitorata, testata e distribuita.
Per ottenere una strategia CI/CD ben progettata, la maggior parte delle persone e delle organizzazioni utilizza processi chiamati "condutture". “Pipeline” è una parola che abbiamo già usato in questa guida senza spiegarla. Se si pensa a tali gasdotti, non è troppo inverosimile pensare ai tubi che servono come linee a lunga distanza per trasportare cose come il gas. Una pipeline nell'area DevOps funziona in modo abbastanza simile: sono software di "trasporto" da distribuire.
Aspetta che suona come molte cose da imparare e ricordare, giusto? Non abbiamo parlato di test? Hai ragione su quello: coprire il concetto completo di una pipeline CI/CD fornirà contenuti sufficienti per più articoli e vogliamo occuparci di una pipeline di test per piccoli progetti front-end. Oppure ti manca solo l'aspetto di test delle tue pipeline, concentrandoti quindi solo sui processi di integrazione continua. Quindi, in particolare, ci concentreremo sulla parte "Testing" delle pipeline. Pertanto, in questa guida creeremo una "piccola" pipeline di test.
Va bene, quindi la "parte di test" è il nostro obiettivo principale. In questo contesto, quali test conosci già e ti vengono in mente a prima vista? Se penso al test in questo modo, questi sono i tipi di test a cui penso spontaneamente:
- Il test unitario è un tipo di test in cui parti o unità testabili minori di un'applicazione, chiamate unità, vengono testate individualmente e indipendentemente per il corretto funzionamento.
- I test di integrazione si concentrano sull'interazione tra componenti o sistemi. Questo tipo di test significa che stiamo controllando l'interazione delle unità e come stanno lavorando insieme.
- Test end-to-end , o test E2E, significa che le effettive interazioni dell'utente sono simulate dal computer; in tal modo, i test E2E dovrebbero includere il maggior numero possibile di aree funzionali e parti dello stack tecnologico utilizzato nell'applicazione.
- Il test visivo è il processo di verifica dell'output visibile di un'applicazione e di confronto con i risultati attesi. In altre parole, aiuta a trovare "bug visivi" nell'aspetto di una pagina o di una schermata diversa dai bug puramente funzionali.
- L'analisi statica non è un test preciso, ma penso che sia essenziale menzionarlo qui. Puoi immaginare che funzioni come una correzione ortografica: esegue il debug del codice senza eseguire il programma e rileva i problemi di stile del codice. Questa semplice misura può prevenire molti bug.
Per essere sicuri di unire un massiccio refactoring nel nostro progetto unico, dovremmo considerare l'utilizzo di tutti questi tipi di test nella nostra pipeline di test. Ma partire in vantaggio porta rapidamente alla frustrazione: potresti sentirti perso nel valutare questi tipi di test. Da dove dovrei iniziare? Quanti test di quali tipi sono ragionevoli?
Strategia: piramidi e trofei
Dobbiamo lavorare su una strategia di test prima di immergerci nella costruzione della nostra pipeline. Cercando le risposte a tutte queste domande prima, potresti trovare una possibile soluzione in alcune metafore: nel web e nelle comunità di test in particolare, le persone tendono a usare analogie per darti un'idea di quanti test dovresti usare di quale tipo.
La prima metafora in cui probabilmente ti imbatterai è la piramide dell'automazione dei test. Mike Cohn ha escogitato questo concetto nel suo libro "Succeeding with Agile", ulteriormente sviluppato come "Practical Test Pyramid" da Martin Fowler. Si presenta così:
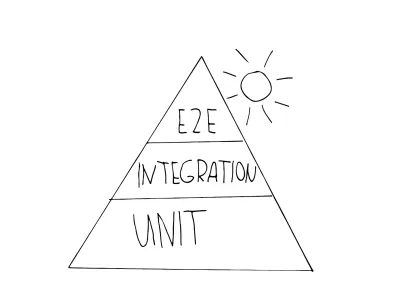
Come vedete, si compone di tre livelli, che corrispondono ai tre livelli di test presentati. La piramide ha lo scopo di chiarire il giusto mix di diversi test, per guidarti durante lo sviluppo di una strategia di test:
- Unità
Trovi questi test sullo strato di base della piramide perché sono di rapida esecuzione e di semplice manutenzione. Ciò è dovuto al loro isolamento e al fatto che prendono di mira le unità più piccole. Vedi questo per un esempio di un tipico test unitario che testa un prodotto molto piccolo. - Integrazione
Questi sono nel mezzo della piramide, poiché sono ancora accettabili quando si tratta di velocità di esecuzione, ma ti danno comunque la sicurezza di essere più vicino all'utente di quanto possano essere gli unit test. Un esempio di test di tipo integrazione è un test API, anche i test dei componenti possono essere considerati di questo tipo. - Test E2E (chiamati anche test UI )
Come abbiamo visto, questi test simulano un utente autentico e la sua interazione. Questi test richiedono più tempo per essere eseguiti e quindi sono più costosi, essendo posizionati in cima alla piramide. Se vuoi esaminare un tipico esempio per un test E2E, vai a questo.
Tuttavia, negli ultimi anni questa metafora è sembrata fuori dal tempo. Uno dei suoi difetti, in particolare, per me è fondamentale: le analisi statiche vengono aggirate in questa strategia. L'uso di correttori in stile codice o altre soluzioni di linting non è considerato in questa metafora, essendo un grosso difetto, secondo me. Lint e altri strumenti di analisi statica sono parte integrante della pipeline in uso e non devono essere ignorati.
Quindi, tagliamo corto: dovremmo usare una strategia più aggiornata. Ma la mancanza di strumenti per la sfilacciatura non è l'unico difetto: c'è anche un punto più significativo da considerare. Invece, potremmo spostare leggermente la nostra attenzione: la seguente citazione lo riassume abbastanza bene:
“Scrivi le prove. Non troppi. Principalmente integrazione".
— Guillermo Rauch
Analizziamo questa citazione per conoscerla:
- Scrivi test
Abbastanza autoesplicativo: dovresti sempre scrivere dei test. I test sono fondamentali per infondere fiducia all'interno della tua applicazione, sia per gli utenti che per gli sviluppatori. Anche per te stesso! - Non troppi
Scrivere test a caso non ti porterà da nessuna parte; la piramide dei test è ancora valida nella sua dichiarazione per mantenere i test prioritari. - Prevalentemente integrazione
Un asso nella manica dei test più "costosi" che la piramide ignora è che la fiducia nei test aumenta man mano che ci si sposta in alto nella piramide. Questo aumento significa che sia l'utente che te stesso come sviluppatore hanno maggiori probabilità di fidarsi di quei test.
Ciò significa che dovremmo optare per test più vicini all'utente, in base alla progettazione. Di conseguenza, potresti pagare di più, ma riavere molto valore. Potresti chiederti perché non scegliere il test E2E? Dato che imitano gli utenti, non sono i più vicini all'utente, tanto per cominciare? Questo è vero, ma sono ancora molto più lenti da eseguire e richiedono l'intero stack di applicazioni. Quindi questo ritorno sull'investimento si ottiene più tardi rispetto ai test di integrazione: di conseguenza, i test di integrazione offrono un giusto equilibrio tra fiducia da un lato e velocità e impegno dall'altro.
Se segui Kent C.Dodds, questi argomenti potrebbero suonarti familiari, soprattutto se leggi questo articolo di lui in particolare. Questi argomenti non sono una coincidenza: ha escogitato una nuova strategia nel suo lavoro. Sono pienamente d'accordo con i suoi punti e collego qui il più importante e altri nella sezione delle risorse. Il suo approccio suggerito deriva dalla piramide dei test, ma la eleva a un altro livello modificandone la forma per riflettere la priorità più alta sui test di integrazione. Si chiama "Trofeo di prova".
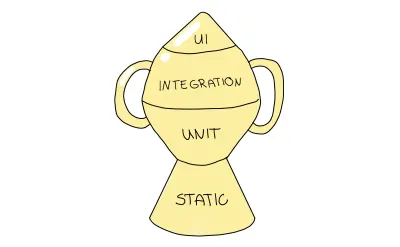
Il trofeo dei test è una metafora che descrive la granularità dei test in un modo leggermente diverso; dovresti distribuire i tuoi test nei seguenti tipi di test:
- L'analisi statica gioca un ruolo fondamentale in questa metafora. In questo modo, catturerai errori di battitura, errori di digitazione e altri bug semplicemente eseguendo i passaggi di debug menzionati.
- I test unitari dovrebbero garantire che la tua unità più piccola sia adeguatamente testata, ma il trofeo dei test non li enfatizzerà nella stessa misura della piramide dei test.
- L'integrazione è l'obiettivo principale in quanto bilancia i costi e la maggiore fiducia nel modo migliore.
- I test dell'interfaccia utente , inclusi i test E2E e Visual, sono in cima al trofeo dei test, in modo simile al loro ruolo nella piramide dei test.
Ho scelto questa strategia per i trofei di test nella maggior parte dei miei progetti e continuerò a farlo in questa guida. Tuttavia, ho bisogno di dare un piccolo disclaimer qui: ovviamente, la mia scelta si basa sui progetti su cui sto lavorando nella mia vita quotidiana. Pertanto, i vantaggi e la selezione di una strategia di test di corrispondenza dipendono sempre dal progetto su cui stai lavorando. Quindi, non sentirti male se non si adatta alle tue esigenze, aggiungerò risorse ad altre strategie nel paragrafo corrispondente.
Avviso spoiler minore: in un certo senso, dovrò deviare anche un po' da questo concetto, come vedrai presto. Tuttavia, penso che vada bene, ma ci arriveremo tra un po'. Il mio punto è pensare alla definizione delle priorità e alla distribuzione dei tipi di test prima di pianificare e implementare le pipeline.
Come costruire quelle condutture online (veloce)
Il protagonista nella terza stagione della serie TV di Netflix "Come vendere droga online (Fast)" viene mostrato utilizzando Cypress per i test E2E mentre era vicino a una scadenza, tuttavia, in realtà si trattava solo di test locali. Non si vedeva nessun CI/CD, il che gli causava uno stress inutile. Dovremmo evitare la pressione del protagonista dato negli episodi corrispondenti con la teoria che abbiamo appreso. Tuttavia, come possiamo applicare questi insegnamenti alla realtà?
Prima di tutto, abbiamo bisogno di una base di codice come base di prova per cominciare. Idealmente, dovrebbe essere un progetto che molti di noi sviluppatori front-end incontreranno. Il suo caso d'uso dovrebbe essere frequente, essendo adatto per un approccio pratico e consentendoci di implementare una pipeline di test da zero. Quale potrebbe essere un progetto del genere?
Il mio suggerimento di una conduttura primaria
La prima cosa che mi è venuta in mente è stata ovvia: il mio sito Web, cioè la pagina del mio portfolio, è adatto per essere considerato un esempio di base di codice da testare dalla nostra aspirante pipeline. È pubblicato open-source su Github, quindi puoi visualizzarlo e usarlo liberamente. Qualche parola sullo stack tecnologico del sito: Fondamentalmente, ho costruito questo sito su Vue.js (purtroppo ancora sulla versione 2 quando ho scritto questo articolo) come framework JavaScript con Nuxt.js come framework web aggiuntivo. Puoi trovare l'esempio di implementazione completo nel suo repository GitHub.
Con la nostra base di codice di esempio selezionata, dovremmo iniziare ad applicare le nostre conoscenze. Dato che vogliamo usare il trofeo dei test come punto di partenza per la nostra strategia di test, ho escogitato il seguente concetto:
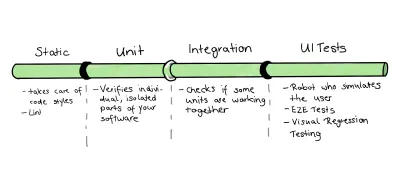
Poiché abbiamo a che fare con una base di codice relativamente piccola, unirò le parti dei test Unit e Integration. Tuttavia, questa è solo una piccola ragione per farlo. Altri e più importanti motivi sono quelli:
- La definizione di un'unità è spesso "da discutere": se chiedi a un gruppo di sviluppatori di definire un'unità, otterrai per lo più risposte diverse e diverse. Poiché alcuni si riferiscono a una funzione, una classe o un servizio (unità minori) un altro sviluppatore conterà nel componente completo.
- Oltre a queste difficoltà di definizione, tracciare un confine tra unità e integrazione può essere complicato, poiché è molto sfocato. Questa lotta è reale, specialmente per Frontend, poiché spesso abbiamo bisogno del DOM per convalidare con successo la base del test.
- Di solito è possibile utilizzare gli stessi strumenti e le stesse librerie per scrivere entrambi i test di integrazione. Quindi, potremmo essere in grado di risparmiare risorse unendole.
Strumento di scelta: azioni GitHub
Poiché sappiamo cosa vogliamo immaginare all'interno di una pipeline, il passo successivo è la scelta della piattaforma di integrazione e consegna continua (CI/CD). Quando scelgo una piattaforma del genere per il nostro progetto, penso a quelle con cui ho già maturato esperienza:
- GitLab, dalla routine quotidiana del mio posto di lavoro,
- Azioni GitHub nella maggior parte dei miei progetti collaterali.
Tuttavia, ci sono molte altre piattaforme tra cui scegliere. Suggerirei di basare sempre la tua scelta sui tuoi progetti e sui loro requisiti specifici, considerando le tecnologie e i framework utilizzati, in modo che non si verifichino problemi di compatibilità. Ricorda, utilizziamo un progetto Vue 2 che è già stato rilasciato su GitHub, coincidente casualmente con la mia precedente esperienza. Inoltre, le azioni GitHub menzionate richiedono solo il repository GitHub del tuo progetto come punto di partenza; per creare ed eseguire un flusso di lavoro GitHub Actions specifico per esso. Di conseguenza, andrò con GitHub Actions per questa guida.
Quindi, quelle azioni GitHub ti forniscono una piattaforma per eseguire flussi di lavoro specificatamente definiti se si verificano determinati eventi. Questi eventi sono attività particolari nel nostro repository che attivano il flusso di lavoro, ad esempio, inviare modifiche a un ramo. In questa guida, quegli eventi sono legati a CI/CD, ma tali flussi di lavoro possono automatizzare anche altri flussi di lavoro come l'aggiunta di etichette per estrarre le richieste. GitHub può eseguirli su macchine virtuali Windows, Linux e macOS.
Per visualizzare un tale flusso di lavoro, sarebbe simile a questo:

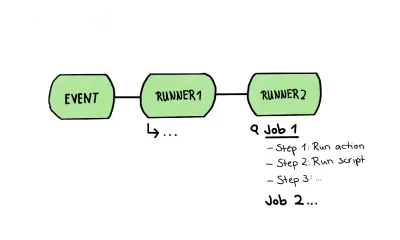
In questo articolo, utilizzerò un flusso di lavoro per immaginare una pipeline; ciò significa che un flusso di lavoro conterrà tutti i nostri passaggi di test, dall'analisi statica ai test dell'interfaccia utente di tutti i tipi. Questa pipeline, o chiamata "flusso di lavoro" nei paragrafi seguenti, sarà composta da uno o più lavori, che sono un insieme di passaggi eseguiti sullo stesso runner.
Questo flusso di lavoro è esattamente la struttura che volevo disegnare nel disegno sopra. In esso, diamo un'occhiata più da vicino a un tale corridore contenente più lavori; Le fasi di un lavoro stesso sono composte da fasi diverse. Questi passaggi possono essere di due tipi:
- Un passaggio può eseguire un semplice script.
- Un passaggio può essere in grado di eseguire un'azione. Tale azione è un'estensione riutilizzabile ed è spesso un'applicazione personalizzata completa.
Tenendo presente questo, un flusso di lavoro effettivo di un'azione GitHub è simile al seguente:
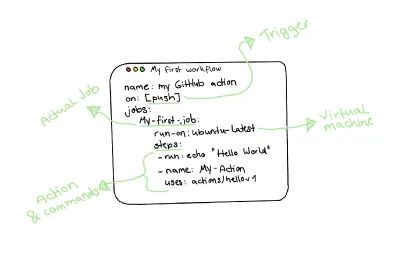
Scrivere la nostra prima azione su GitHub
Infine, possiamo scrivere la nostra prima azione Github e scrivere del codice! Inizieremo con il nostro flusso di lavoro di base e il nostro primo schema dei lavori che vogliamo rappresentare. Ricordando il nostro trofeo di test, ogni lavoro assomiglierà a uno strato nel trofeo di test. I passaggi saranno le cose che dobbiamo fare per automatizzare quei livelli.
Pertanto, creo la .github/workflows/ per archiviare prima i nostri flussi di lavoro. Creeremo un nuovo file chiamato tests.yml per contenere il nostro flusso di lavoro di test all'interno di questa directory. Oltre alla sintassi del flusso di lavoro standard vista nel disegno sopra, procederò come segue:
- Chiamerò il nostro flusso di lavoro
Tests CI. - Poiché desidero eseguire il mio flusso di lavoro su ogni push ai miei rami remoti e fornire un'opzione manuale per avviare la mia pipeline, configurerò il mio flusso di lavoro per l'esecuzione su
pusheworkflow_dispatch. - Ultimo ma non meno importante, come affermato nel paragrafo “Il mio suggerimento di una pipeline di base”, il mio flusso di lavoro conterrà tre lavori:
-
static-eslintper l'analisi statica; -
unit-integration-jestper test di unità e integrazione uniti in un unico lavoro; -
ui-cypresscome fase dell'interfaccia utente, inclusi test E2E di base e test di regressione visiva.
-
- Una macchina virtuale basata su Linux dovrebbe eseguire tutti i lavori, quindi andrò con
ubuntu-latest.
Inserisci la sintassi corretta di un file YAML , il primo schema del nostro flusso di lavoro potrebbe assomigliare a questo:
name: Tests CI on: [push, workflow_dispatch] # On push and manual jobs: static-eslint: runs-on: ubuntu-latest steps: # 1 steps unit-integration-jest: runs-on: ubuntu-latest steps: # 1 step ui-cypress: runs-on: ubuntu-latest steps: # 2 steps: e2e and visualSe vuoi approfondire i dettagli sui flussi di lavoro nell'azione GitHub, sentiti libero di andare alla sua documentazione in qualsiasi momento. Ad ogni modo, sei indubbiamente consapevole che mancano ancora i passaggi. Non preoccuparti, ne sono consapevole anch'io. Quindi, per riempire di vita questo schema di flusso di lavoro, dobbiamo definire questi passaggi e decidere quali strumenti e framework di test utilizzare per il nostro piccolo progetto di portfolio. Tutti i prossimi paragrafi descriveranno i rispettivi lavori e conterranno diversi passaggi per rendere possibile l'automazione di detti test.
Analisi statica
Come suggerisce il trofeo di test, inizieremo con linter e altri fixer in stile codice nel nostro flusso di lavoro. In questo contesto, puoi scegliere tra molti strumenti e alcuni esempi includono quelli:
- Eslint come riparatore di stili di codice Javascript.
- Stylelint per la correzione del codice CSS.
- Possiamo considerare di andare ancora oltre, ad esempio, per analizzare la complessità del codice, potresti guardare strumenti come scrutinizer.
Questi strumenti hanno in comune il fatto di evidenziare errori nei modelli e nelle convenzioni. Tuttavia, tieni presente che alcune di queste regole sono una questione di gusti. Sta a te decidere quanto rigoroso vuoi farli rispettare. Per fare un esempio, se hai intenzione di tollerare un rientro di due o quattro schede. È molto più importante concentrarsi sulla richiesta di uno stile di codice coerente e sull'individuazione delle cause più critiche degli errori, come l'utilizzo di "==" rispetto a "===".
Per il nostro progetto portfolio e questa guida, voglio iniziare a installare Eslint, poiché utilizziamo molto Javascript. Lo installerò con il seguente comando:
npm install eslint --save-dev Ovviamente posso anche usare un comando alternativo con il gestore di pacchetti Yarn se preferisco non usare NPM. Dopo l'installazione, devo creare un file di configurazione chiamato .eslintrc.json . Usiamo una configurazione di base per ora, poiché questo articolo non ti insegnerà come configurare Eslint in primo luogo:
{ "extends": [ "eslint:recommended", ] } Se vuoi conoscere in dettaglio la configurazione di Eslint, vai a questa guida. Successivamente, vogliamo fare i nostri primi passi per automatizzare l'esecuzione di Eslint. Per cominciare, voglio impostare il comando per eseguire Eslint come script NPM. Ottengo questo usando questo comando nel nostro file package.json nella sezione script :
"scripts": { "lint": "eslint --ext .js .", }, Posso quindi eseguire questo script appena creato nel nostro flusso di lavoro GitHub. Tuttavia, dobbiamo assicurarci che il nostro progetto sia disponibile prima di farlo. Pertanto utilizziamo le actions/checkout@v2 che fa esattamente questo: controllare il nostro progetto, in modo che il flusso di lavoro della tua azione GitHub possa accedervi. Il passaggio successivo sarebbe l'installazione di tutte le dipendenze NPM di cui abbiamo bisogno per il mio progetto di portfolio. Dopodiché, siamo finalmente pronti per eseguire il nostro script eslint! Il nostro ultimo lavoro per usare i pelucchi è ora questo:
static-eslint: runs-on: ubuntu-latest steps: # Action to check out my codebase - uses: actions/checkout@v2 # install NPM dependencies - run: npm install # Run lint script - run: npm run lint Potresti chiederti ora: questa pipeline "fallisce" automaticamente quando il nostro npm run lint in un test non riuscito? Sì, questo funziona fuori dagli schemi. Non appena avremo finito di scrivere il nostro flusso di lavoro, esamineremo gli screenshot su Github.
Unità e integrazione
Successivamente, voglio creare il nostro lavoro contenente l'unità e i passaggi di integrazione. Per quanto riguarda il framework utilizzato in questo articolo, vorrei presentarvi il framework Jest per i test di frontend. Naturalmente, non è necessario utilizzare Jest se non lo si desidera, ci sono molte alternative tra cui scegliere:
- Cypress fornisce anche test dei componenti per essere adatti ai test di integrazione.
- Jasmine è anche un altro framework a cui dare un'occhiata.
- E ce ne sono molti altri; Volevo solo citarne alcuni.
Jest è fornito come open source da Facebook. Il framework attribuisce la sua attenzione alla semplicità pur essendo compatibile con molti framework e progetti JavaScript, inclusi Vue.js, React o Angular. Sono anche in grado di usare jest in tandem con TypeScript. Questo rende il framework molto interessante, soprattutto per il mio piccolo progetto di portfolio, poiché è compatibile e adatto.
Possiamo avviare direttamente l'installazione di Jest da questa cartella principale del mio progetto portfolio inserendo il seguente comando:
npm install --save-dev jest Dopo l'installazione, sono già in grado di iniziare a scrivere i test. Tuttavia, questo articolo è incentrato sull'automazione di questi test utilizzando le azioni Github. Quindi, per imparare a scrivere un'unità o un test di integrazione, fare riferimento alla seguente guida. Quando impostiamo il lavoro nel nostro flusso di lavoro, possiamo procedere in modo simile al lavoro static-eslint . Quindi, il primo passo è di nuovo creare un piccolo script NPM da utilizzare nel nostro lavoro in seguito:
"scripts": { "test": "jest", }, Successivamente, definiremo il lavoro chiamato unit-integration-jest in modo simile a quello che abbiamo già fatto prima per i nostri linter. Quindi, il flusso di lavoro verificherà il nostro progetto. In aggiunta a ciò, utilizzeremo due lievi differenze per il nostro primo lavoro static-eslint :
- Useremo un'azione come passaggio per installare Node.
- Successivamente, utilizzeremo il nostro script npm appena creato per eseguire il nostro test Jest.
In questo modo, il nostro lavoro unit-integration-jest sarà simile a questo::
unit-integration-jest: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 # Set up node - name: Run jest uses: actions/setup-node@v1 with: node-version: '12' - run: npm install # Run jest script - run: npm testTest dell'interfaccia utente: E2E e test visivi
Ultimo ma non meno importante, scriveremo il nostro lavoro ui-cypress , che conterrà sia i test E2E che i test visivi. È intelligente combinare questi due in un unico lavoro poiché userò il framework Cypress per entrambi. Naturalmente, puoi considerare altri framework come quelli di seguito, NightwatchJS e CodeceptJS.
Ancora una volta, tratteremo solo le basi per configurarlo nel nostro flusso di lavoro GitHub. Se vuoi imparare a scrivere i test Cypress in dettaglio, ti ho coperto con un'altra delle mie guide che affronta proprio questo. Questo articolo ti guiderà attraverso tutto ciò di cui abbiamo bisogno per definire i nostri passaggi di test E2E. Va bene, prima installeremo Cypress, allo stesso modo in cui abbiamo fatto con gli altri framework, usando il seguente comando nella nostra cartella principale:
npm install --save-dev cypress Questa volta, non è necessario definire uno script NPM. Cypress ci fornisce già la propria azione GitHub da utilizzare, cypress-io/github-action@v2 . Lì, abbiamo solo bisogno di configurare alcune cose per farlo funzionare:
- Dobbiamo assicurarci che la nostra applicazione sia completamente configurata e funzionante, poiché un test E2E richiede lo stack di applicazioni completo disponibile.
- Dobbiamo dare un nome al browser in cui stiamo eseguendo il nostro test E2E.
- Dobbiamo aspettare che il webserver sia completamente funzionante, in modo che il computer possa comportarsi come un utente reale.
Fortunatamente, la nostra azione Cypress ci aiuta a memorizzare tutte quelle configurazioni con l'area with . In questo modo, il nostro attuale lavoro su GitHub appare in questo modo:
steps: - name: Checkout uses: actions/checkout@v2 # Install NPM dependencies, cache them correctly # and run all Cypress tests - name: Cypress Run uses: cypress-io/github-action@v2 with: browser: chrome headless: true # Setup: Nuxt-specific things build: npm run generate start: npm run start wait-on: 'http://localhost:3000'Test visivi: presta alcuni occhi al tuo test
Ricorda la nostra prima intenzione di scrivere questa guida: ho il mio significativo refactoring con molte modifiche nei file SCSS: voglio aggiungere il test come parte della routine di compilazione per assicurarmi che non abbia interrotto nient'altro. Avendo analisi statica, unità, integrazione e test E2E, dovremmo essere abbastanza fiduciosi, giusto? Vero, ma c'è ancora qualcosa che posso fare per rendere il mio gasdotto ancora più a prova di proiettile e perfetto. Si potrebbe dire che sta diventando la crema. Soprattutto quando si ha a che fare con il refactoring CSS, un test E2E può essere solo di aiuto limitato, poiché fa solo ciò che hai detto di fare scrivendolo nel tuo test.
Fortunatamente, c'è un altro modo per catturare i bug a parte i comandi scritti e, quindi, a parte il concetto. Si chiama test visivo: puoi immaginare che questo tipo di test sia come un puzzle per individuare la differenza. Tecnicamente parlando, il test visivo è un confronto di schermate che acquisirà schermate della tua applicazione e la confronterà con lo status quo, ad esempio, dal ramo principale del tuo progetto. In questo modo, nessun problema di stile accidentale passerà inosservato, almeno nelle aree in cui utilizzi i test visivi. Questo può trasformare il test visivo in un salvavita per grandi refactoring CSS, almeno nella mia esperienza.
Ci sono molti strumenti di test visivi tra cui scegliere e vale la pena dare un'occhiata:
- Percy.io, uno strumento di Browserstack che sto usando per questa guida;
- Visual Regression Tracker se preferisci non utilizzare una soluzione SaaS e andare completamente open source allo stesso tempo;
- Applitools con supporto AI. C'è un'entusiasmante guida da guardare sulla rivista Smashing su questo strumento;
- Cromatico di Storybook.
Per questa guida e sostanzialmente per il mio progetto di portfolio, era fondamentale riutilizzare i miei test Cypress esistenti per i test visivi. Come accennato in precedenza, userò Percy per questo esempio grazie alla sua semplicità di integrazione. Sebbene sia una soluzione SaaS, ci sono ancora molte parti fornite open source e c'è un piano gratuito che dovrebbe essere sufficiente per molti progetti open source o altri progetti collaterali. Tuttavia, se ti senti più a tuo agio con l'hosting completamente autonomo mentre utilizzi anche uno strumento open source, puoi provare il Visual Regression Tracker.
Questa guida ti fornirà solo una breve panoramica di Percy, che altrimenti fornirebbe il contenuto per un articolo completamente nuovo. Tuttavia, ti darò le informazioni per iniziare. Se vuoi approfondire i dettagli ora, ti consiglio di guardare la documentazione di Percy. Quindi, come possiamo dare ai nostri test gli occhi, per così dire? Supponiamo di aver già scritto uno o due test Cypress ormai. Immagina che assomiglino a questo:
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); });Certo, se vogliamo installare Percy come nostra soluzione di test visivi, possiamo farlo con un plug-in di cipresso. Quindi, come abbiamo fatto un paio di volte oggi, lo stiamo installando nella nostra cartella principale usando NPM:
npm install --save-dev @percy/cli @percy/cypress Successivamente, devi solo importare il pacchetto percy/cypress nel tuo file di indice cypress/support/index.js :
import '@percy/cypress';Questa importazione ti consentirà di utilizzare il comando snapshot di Percy, che acquisirà uno snapshot dalla tua applicazione. In questo contesto, uno snapshot indica una raccolta di screenshot presi da diverse finestre o browser che puoi configurare.
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); // Take a snapshot cy.percySnapshot('Home page'); }); Tornando al nostro file di flusso di lavoro, voglio definire il test di Percy come il secondo passaggio del lavoro. In esso, eseguiremo lo script npx percy exec -- cypress run per eseguire il nostro test insieme a Percy. Per collegare i nostri test e risultati al nostro progetto Percy, dovremo passare il nostro token Percy, nascosto da un segreto GitHub.
steps: # Before: Checkout, NPM, and E2E steps - name: Percy Test run: npx percy exec -- cypress run env: PERCY_TOKEN: ${{ secrets.PERCY_TOKEN }}Perché ho bisogno di un token Percy? È perché Percy è una soluzione SaaS per il mantenimento dei nostri screenshot. Manterrà gli screenshot e lo status quo per il confronto e ci fornirà un flusso di lavoro di approvazione degli screenshot. Qui puoi approvare o rifiutare qualsiasi modifica imminente:
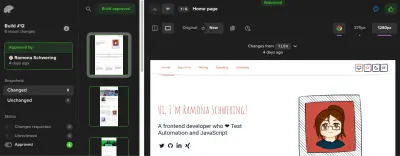
Visualizzazione dei nostri lavori: integrazione con GitHub
Congratulazioni! Stavamo creando con successo il nostro primo flusso di lavoro di azioni GitHub. Diamo un'ultima occhiata al nostro file di flusso di lavoro completo nel repository della mia pagina portfolio. Non ti chiedi come appare nell'uso pratico? Puoi trovare le tue azioni GitHub funzionanti nella scheda "Azioni" del tuo repository:
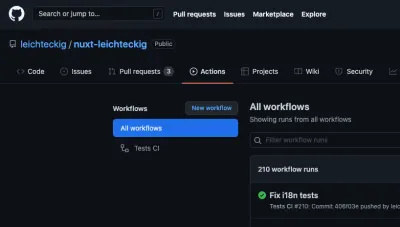
Lì puoi trovare tutti i flussi di lavoro, che sono equivalenti ai tuoi file di flusso di lavoro. Se dai un'occhiata a un flusso di lavoro, ad esempio il mio flusso di lavoro "Test CI", puoi esaminarne tutti i lavori:
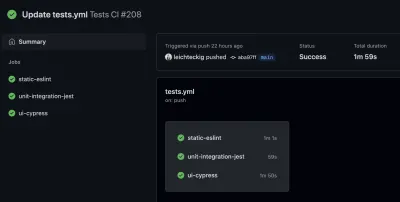
Se desideri dare un'occhiata a uno dei tuoi lavori, puoi selezionarlo anche nella barra laterale. Lì, puoi ispezionare il registro dei tuoi lavori:
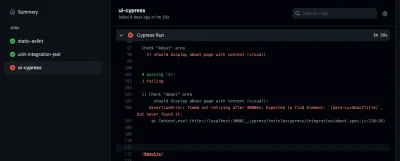
Vedi, sei in grado di rilevare gli errori se si verificano all'interno della tua pipeline. A proposito, la scheda "azione" non è l'unico posto in cui puoi controllare i risultati delle tue azioni GitHub. Puoi anche esaminarli nelle tue richieste pull:
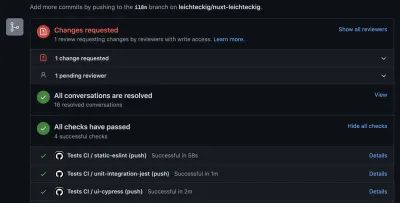
I like to configure those GitHub actions the way they need to be executed successfully: Otherwise, it's not possible to merge any pull requests into my repository.
Conclusione
CI/CD helps us perform even major refactorings — and dramatically minimizes the risk of running into nasty surprises. The testing part of CI/CD is taking care of our codebase being continuously tested and monitored. Consequently, we will notice errors very early, ideally before anyone merges them into your main branch. Plus, we will not get into the predicament of correcting our local tests on the way to work — or even worse — actual errors in our application. I think that's a great perspective, right?
To include this testing build routine, you don't need to be a full DevOps engineer: With the help of some testing frameworks and GitHub actions, you're able to implement these for your side projects as well. I hope I could give you a short kick-off and got you on the right track.
I'm looking forward to seeing more testing pipelines and GitHub action workflows out there! ️
Risorse
- An excellent guide on CI/CD by GitHub
- “The practical test pyramid”, Ham Vocke
- Articles on the testing trophy worth reading, by Kent C.Dodds:
- “Write tests. Not too many. Mostly integration”
- “The Testing Trophy and Testing Classifications”
- “Static vs Unit vs Integration vs E2E Testing for Frontend Apps”
- I referred to some examples of the Cypress real world app
- Documentation of used tools and frameworks:
- GitHub actions
- Eslint docs
- Documentazione scherzosa
- Documentazione sui cipressi
- Percy documentation