
Strategie per progetti senza testa con sistemi di gestione dei contenuti strutturati
Pubblicato: 2022-03-10Questa è la guida che vorrei avere negli ultimi due anni durante l'esecuzione di progetti con sistemi di gestione dei contenuti (CMS) senza testa. Sono stato uno sviluppatore, un consulente per l'esperienza utente e la tecnologia, un project manager, un architetto dell'informazione e un autore. I diversi cappelli mi hanno fatto capire che anche se da un po' di tempo abbiamo i cosiddetti CMS "senza testa", c'è ancora molta strada da fare per pensare a come usarli al meglio.
Ora siamo a un punto in cui molti di noi fanno affidamento su framework JavaScript per il lavoro di frontend, utilizzando sistemi di progettazione fatti di componenti e composizioni, piuttosto che implementare semplicemente layout di pagina piatta. C'è molta trazione verso JAMstacks e app isomorfe/universali che vengono eseguite sia sul server che sul client. L'ultimo pezzo del puzzle è quindi come gestiamo tutto il contenuto.
I CMS tradizionali aggiungono API per servire i contenuti tramite richieste di rete e il formato JSON. Inoltre, sono emersi CMS "headless" per servire esclusivamente contenuti tramite API. La mia argomentazione in questo articolo, tuttavia, è che dovremmo dedicare meno tempo a parlare di "senza testa" e di più a "contenuti strutturati" . Perché questa è la qualità essenziale di questi sistemi. Ci sono molte implicazioni per la nostra arte implicita in questi sistemi e abbiamo ancora molta strada da fare per capire i buoni schemi di come dovremmo affrontare queste tecnologie.
Venendo alla consulenza tecnologica da un background in discipline umanistiche, ho imparato molto su come organizzare e lavorare con progetti web che adottano un approccio incentrato sui contenuti, sia con i nuovi CMS basati su API che con i tradizionali CMS. Ho imparato ad apprezzare come iniziare presto con i contenuti live effettivi da un CMS; farlo in un contesto interdisciplinare non solo ha permesso di scoprire le complessità in una fase precedente, ma offre anche un'agenzia a tutti i soggetti coinvolti e offre opportunità di riflettere sulle sfide e sulle possibilità della tecnologia e del design nel suo senso più ampio.
WordPress senza testa
Tutti sanno che se un sito web è lento, gli utenti lo abbandoneranno. Diamo un'occhiata più da vicino alle basi della creazione di un WordPress disaccoppiato. Leggi un articolo correlato →
In questo articolo, suggerirò alcune strategie generali, con alcuni esempi concreti e reali su come pensare di lavorare con contenuti strutturati. Al momento in cui scrivo, ho appena iniziato a lavorare per un'azienda SaaS che fornisce un tale servizio di gestione dei contenuti, per l'hosting di contenuti forniti tramite API. Farò riferimenti ad esso, sia per la mia esperienza passata con esso in progetti in cui sono stato coinvolto come consulente, sia perché penso che illustri adeguatamente i punti che voglio sottolineare. Quindi considera questo una sorta di disclaimer.
Detto questo, ho pensato di scrivere questo articolo per un paio d'anni e mi sono sforzato di renderlo applicabile a qualsiasi piattaforma tu scelga di utilizzare. Quindi, senza ulteriori indugi, facciamo un salto indietro nel tempo di vent'anni per capire un po' di più dove siamo oggi.
Prime mosse con gli standard Web
All'inizio degli anni 2000, il movimento Web Standards ha ispirato un campo a cambiare il proprio modo di lavorare. Da un approccio "layout-first", hanno indirizzato la nostra attenzione su come il contenuto di una pagina dovrebbe essere contrassegnato semanticamente utilizzando HTML: il menu di un sito Web non è una <table> , è un <nav> ; Un'intestazione non è un <b> , è un <h1> . È stato un passo significativo verso la riflessione sui diversi ruoli che il contenuto del web gioca per aiutare gli utenti a trovarlo, identificarlo e accettarlo.
Il movimento Web Standards ha introdotto l'argomento secondo cui il markup semantico ha migliorato l'accessibilità, il che ha anche migliorato il suo posizionamento nei risultati di ricerca di Google. Ha anche segnato un cambiamento nel modo in cui abbiamo pensato ai contenuti web . Il tuo sito web non era più l' unico luogo in cui i tuoi contenuti erano rappresentati. Dovevi anche pensare a come le tue pagine web venivano presentate in altri contesti visivi, come nei risultati di ricerca o nelle utilità per la lettura dello schermo. Ciò è stato successivamente alimentato dai social media e dalle anteprime incorporate dei collegamenti condivisi. La mentalità si è spostata da come dovrebbe apparire il contenuto, a cosa dovrebbe significare . Questa è anche la chiave per lavorare con i contenuti strutturati.
Con l'adozione di dispositivi tascabili connessi a Internet, il Web è diventato improvvisamente un serio contendente nelle app. La concorrenza, tuttavia, era principalmente per gli occhi dell'utente finale. Molte organizzazioni avevano ancora bisogno di distribuire informazioni sui loro prodotti e servizi sia nelle loro app che nelle loro diverse presenze web. Contemporaneamente, il Web è maturato e JavaScript e AJAX hanno semplificato la connessione di diverse fonti di contenuto tramite le API. Oggi abbiamo GraphQL e strumenti che semplificano il recupero dei contenuti e la gestione dello stato. E così i pezzi del puzzle tecnologico cominciano a prendere posto.
"Crea una volta, pubblica ovunque"
Sebbene sia principalmente descritto come un "cambiamento tecnologico", l'incorporamento di contenuti nei payload JSON (che viaggiano lungo i tubi HTTP) ha un impatto smisurato sul modo in cui pensiamo ai contenuti digitali e ai flussi di lavoro circostanti. In un certo senso, lo ha già fatto. Quasi dieci anni fa, l'ospite della National Public Radio (NPR) Daniel Jacobson ha bloggato su programmableweb.com sul loro approccio, riassunto nell'acronimo COPE che sta per "Create Once, Publish Everywhere". Nell'articolo, introduce un sistema di gestione dei contenuti che fornisce contenuti a più interfacce digitali tramite un'API, non tramite una macchina di rendering HTML, come facevano la maggior parte dei CMS all'epoca (e probabilmente ora).
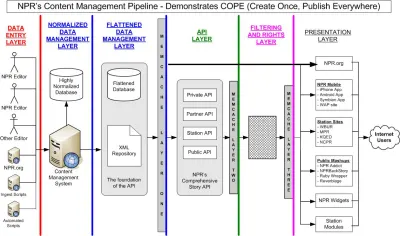
Il "livello di gestione dei dati" di COPE di NPR è quello che sarebbe diventato il concetto di "CMS headless". Agli albori di COPE, si otteneva strutturando il contenuto in XML. Oggi, JSON è diventato il formato di dati dominante per il trasferimento di dati tramite API, inclusi dispositivi Internet of Things e altri sistemi al di fuori del Web. Se vuoi scambiare contenuti con chatbot, interfacce vocali e persino software per la prototipazione visiva, molto spesso parli HTTP con un accento JSON.
"Uncoining" Il termine "CMS senza testa"
Secondo Google Trends, le ricerche di "CMS senza testa" hanno guadagnato popolarità fino al 2015, ovvero sei anni dopo l'articolo COPE di NPR. Il termine “headless” (almeno in relazione alla tecnologia digitale e non all'aristocrazia francese della fine del 18° secolo), è stato usato un bel po' di più per parlare di sistemi che funzionano senza un'interfaccia utente grafica.
Nota : si potrebbe obiettare che un'interfaccia a riga di comando è effettivamente "grafica" come il software su server o ambienti di test (ma salviamolo per un altro articolo).
Ho due menti che chiamano questi nuovi CMS "senza testa". Potremmo anche chiamarli "policefali", quello che ha molte teste. Sono le Idra e le Cerbeuse dei CMS. "Headless" significa anche definire questi sistemi in base alla capacità di cui sono privi (ad esempio, un motore di modelli per il rendering di pagine Web), invece di definirli in base alla loro vera forza: rendere possibile la struttura dei contenuti senza i vincoli del web. Detto questo, ad oggi molte delle soluzioni di questa categoria potrebbero chiamarsi anche “Nearly Headless Nick”. Perché l'interfaccia di editing è ancora strettamente collegata al sistema. La loro "senza testa" deriva dalla loro mancanza di un motore di modelli, ovvero il macchinario che produce markup dal contenuto.
Nota : userei quasi sicuramente un CMS chiamato "Mimsy-Porpington" (conosciuto dall'universo di Harry Potter).
Invece, rendono i contenuti disponibili tramite un'API, offrendoti quindi maggiore flessibilità su come, cosa e dove desideri visualizzare e utilizzare questi contenuti. Questo li rende compagni perfetti per i popolari framework frontend JavaScript come React, Angular e Vue. E nonostante la pretesa di essere in grado di fornire contenuti a "siti web, app e dispositivi", la maggior parte di essi è ancora limitata dal modo in cui funzionano i contenuti web. Questo è più evidente nel modo in cui la maggior parte gestisce il rich text, archiviandolo come HTML o Markdown.
I CMS tradizionali hanno anche iniziato ad aggiungere API in qualche modo generiche oltre ai loro sistemi di rendering dei modelli e lo chiamano "disaccoppiato" come un modo per distinguersi dai loro nuovi concorrenti. "Tutto questo, e anche le API!"* è l'affermazione. Alcuni di questi CMS sono anche piuttosto agnostici quando si tratta di modellazione dei contenuti. Ad esempio, Craft CMS non fa quasi supposizioni sul tuo modello di contenuto quando lo installi per la prima volta. Wordpress si sta anche muovendo verso l'utilizzo delle API per la consegna dei contenuti. Sospetto che il divario tra i vecchi giocatori nel campo CMS e i nuovi si ridurrà man mano che andiamo avanti.
Tuttavia, inserire la gestione dei contenuti dietro le API (invece di un renderer HTML) è un passo importante verso modalità di lavoro più sofisticate in un'epoca in cui il testo, le immagini, i video e i media di un'organizzazione sono digitalizzati ed esposti a utenti e clienti interni ed esterni. È giunto il momento, però, di allontanarsi dalla definizione delle loro capacità di rendering del frontend mancanti, a ciò che possono davvero fare per noi: darci un modo per lavorare con i contenuti strutturati . Quindi, dovremmo chiamarli "Sistemi di gestione dei contenuti strutturati"? Come in "No Bob, questo non è il tuo solito CMS. Questo è un SCMS, fidati di me, sarà una cosa.
Non si tratta di teste, si tratta di contenuti strutturati
Il cambiamento più radicale imposto dai sistemi di gestione dei contenuti strutturati (SCMS) è l'allontanamento dall'organizzazione dei contenuti secondo una gerarchia di pagine in cui sei libero di strutturare i contenuti per qualsiasi scopo tu ritenga opportuno. Evitare i contenuti duplicati è un chiaro vantaggio perché aumenta l'affidabilità e riduce il carico amministrativo (non è necessario far fronte a contenuti duplicati su più canali). In altre parole: crea una volta, pubblica ovunque . Se devi solo aggiornare la descrizione del tuo prodotto una volta, in un sistema, e si aggiorna ovunque il tuo prodotto sia esposto all'utente, questo è chiaramente un vantaggio.
Sebbene i fornitori di SCMS utilizzino spesso "il tuo sito Web e un'app" per giustificare un pensiero diverso sulla struttura della pagina, non è necessario attraversare il fiume per trarre vantaggi da una struttura di contenuto strutturata. Con la popolarità dei framework JavaScript, è sempre più comune creare siti web come una composizione di singoli componenti, che possono essere “riempiti” con contenuti diversi a seconda dello stato e del contesto. Potresti avere una scheda prodotto che appare in molti contesti diversi all'interno della tua applicazione web. Stiamo vedendo che lo sviluppo Web moderno si allontana dall'impostazione di documenti e pagine per comporre componenti in base a una combinazione di input dell'utente, algoritmi e personalizzazione.
Queste tendenze su come vengono realizzati i sistemi di progettazione e su come siamo incoraggiati a lavorare in team attraverso processi di test, apprendimento e iterazione, rendono il campo della gestione dei contenuti maturo per alcuni nuovi modi di pensare. Sono emersi alcuni modelli, ma abbiamo ancora molte strade da percorrere. Pertanto, sulla base della mia esperienza di lavoro in team e progetti che hanno messo i contenuti in primo piano e al centro, e poiché ora fanno parte di un team che costruisce un servizio per esso (e ti esorto a essere consapevole di qualsiasi pregiudizio qui), voglio proporre alcune strategie che ritengo possano essere utili e creare spunti per ulteriori discussioni.
1. Approccio ai contenuti nei team multidisciplinari
Credo che sia una cosa del passato che un grafico possa consegnare pagine stantie e perfette per i pixel a uno sviluppatore frontend la cui responsabilità era quella di "implementare" il design. Ora realizziamo sistemi di progettazione costituiti da componenti più piccoli, disposti in composizioni che presentano molteplici stati possibili fuori dagli schemi. Il più delle volte, questi componenti devono essere resilienti all'input generato dagli utenti, il che significa che prima si inseriscono contenuti live nel processo, meglio è. La responsabilità di uno sviluppatore frontend non è riprodurre la visione di un grafico ; serve per manovrare un campo complesso di come i browser eseguono il rendering di HTML, CSS e JavaScript, assicurandosi che le interfacce utente siano reattive, accessibili e performanti.
Quando lavoravo come consulente tecnologico presso Netlife (una società di consulenza specializzata nell'esperienza utente), ho visto grandi passi avanti verso la collaborazione tra sviluppatori, designer e utenti ricercatori. Anche se i nostri editor di contenuti sono stati sempre coinvolti nel progetto fin dall'inizio, i loro contributi non sono entrati nel flusso di lavoro di progettazione principalmente a causa di attriti tecnici.
Il collo di bottiglia era spesso un CMS legacy che non potevamo toccare o che richiedeva tempo per costruire la struttura del contenuto perché dipendeva dal layout del design. Ciò ha spesso comportato il raddoppio del lavoro: abbiamo realizzato un prototipo HTML, spesso basato su contenuto analizzato da file Markdown, che doveva essere re-implementato nello stack CMS quando il test dell'utente era terminato, e tutti erano perfettamente felici . Questo era spesso un processo costoso poiché le limitazioni nel CMS venivano scoperte nella fase avanzata del processo. Inoltre, crea pressione su tutte le parti per "farlo bene la prima volta" e lascia meno spazio per il tipo di sperimentazione che vorresti in un progetto di design.
Il lavoro multidisciplinare richiede sistemi agili
Il passaggio a un SCMS in cui ci sono voluti minuti per codificare un modello di contenuto (in cui campi e API erano pronti all'istante) ha capovolto il nostro processo, e in meglio. Ricordo di essermi seduto con l'editor di contenuti del nuovo u4.no nei primi giorni del progetto. Parlando di come hanno lavorato e vorrebbe lavorare con i loro contenuti. Piuttosto rapidamente, abbiamo tradotto le nostre conclusioni in semplici oggetti JavaScript che sono stati immediatamente trasformati in un ambiente di modifica nel browser. Capire titoli e descrizioni utili per i titoli. Abbiamo parlato di come volevano frammenti di testo da riutilizzare in diverse pagine e contesti, che hanno chiamato internamente "pepite", che abbiamo poi creato in quel momento.
Consentire questo tipo di esplorazione all'inizio dello sviluppo del progetto - un editor di contenuti e uno sviluppatore che parlavano insieme mentre l'interfaccia veniva creata di fronte a noi - sembrava potente. Sapendo che avremmo potuto continuare a progettare il frontend in React mentre lei e i suoi colleghi hanno iniziato a lavorare con il contenuto. E senza preoccuparci di metterci in un angolo, come facevamo spesso con i CMS in cui la struttura era strettamente accoppiata con il modo in cui dovevi codificare la parte front-end di essa.
Un sistema di contenuti dovrebbe consentire la sperimentazione e l'iterazione
A parte i progetti di riprogettazione creativa, un sistema per contenuti strutturati dovrebbe anche consentirti di continuare a migliorare, testare e iterare i tuoi contenuti come parte dell'intero sistema di progettazione. I designer di UX dovrebbero essere in grado di creare rapidamente prototipi con contenuti reali utilizzando strumenti come Sketch o Framer X. Dovresti essere in grado di aumentare la gestione dei contenuti con misurazioni quantitative, sia che si tratti di scale di leggibilità o di come si comporta il contenuto dove viene utilizzato.
Nota : ho usato il termine "UX designer" sopra nonostante fossi dell'opinione che tutti dovremmo, in qualche modo, relazionarci al processo di creazione di buone esperienze utente. Siamo tutti designer UX nei nostri diversi filoni di design.
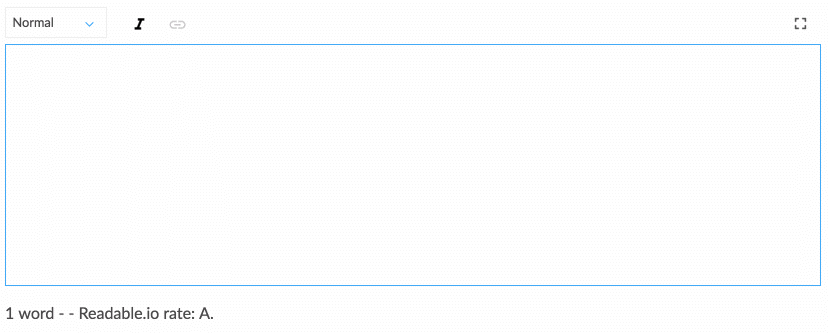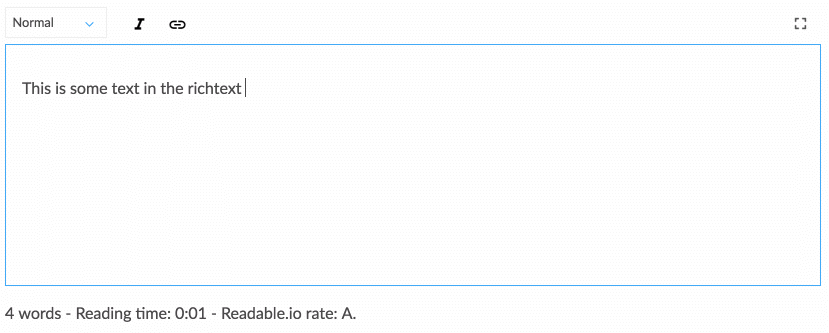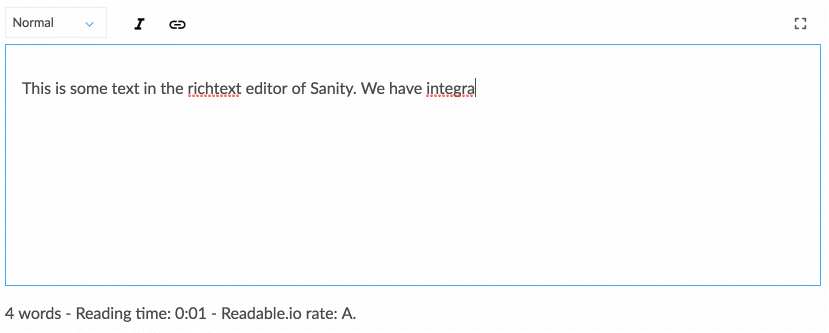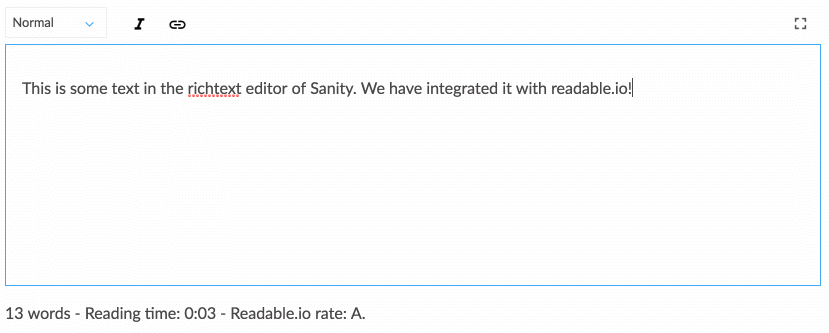
Lavorare con i contenuti strutturati richiede un po' di abitudine se sei abituato solo a inserire WYSIWYG direttamente nel layout della tua pagina web. Eppure, si presta a una conversazione più in linea con come si sta muovendo il campo del design digitale. I contenuti strutturati consentono a un team di designer, sviluppatori, editor di contenuti, ricercatori di utenti e project manager di pensare collettivamente a come dovrebbe funzionare un sistema per supportare le esigenze degli utenti e gli obiettivi strategici. Ciò richiede anche di pensare in modo diverso alla struttura dei contenuti, il che ci porta alla strategia successiva.
2. Potresti non aver bisogno di un ordine gerarchico
Uno dei cambiamenti più importanti per molti è che i sistemi per il contenuto strutturato sono orientati verso raccolte ed elenchi di documenti e non gerarchie simili a cartelle che riflettono le strutture di navigazione del sito web. Queste strutture smettono di avere senso non appena alcuni dei contenuti devono essere utilizzati in altri contesti, che si tratti di chatbot, supporti di stampa o altri siti Web. I CMS tradizionali hanno cercato di mitigare questo problema consentendo blocchi di contenuto riutilizzabili, ma devono comunque essere posizionati sui layout di pagina e ingombranti con cui ragionare tramite le API.
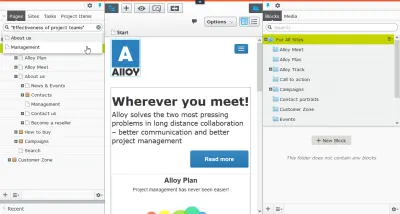
Ogni pagina a sé stante
Come illustrato in The Core Model, quando uno dei tuoi principali referrer è Google o condivide sui social media, dovresti considerare ogni pagina una landing page. E se osservi la distribuzione delle visualizzazioni di pagina, noterai che alcune delle tue pagine sono molto più popolari di altre. A meno che tu non sia un sito web di notizie, quelle tendono a non essere le notizie, ma quelle che consentono all'utente di ottenere ciò che sperava di ottenere sul tuo sito web. Sono dove gli affari stanno effettivamente accadendo.
I tuoi contenuti digitali dovrebbero essere al servizio dell'intersezione tra i tuoi obiettivi strategici e gli obiettivi individuali dei tuoi utenti. Quando l'agenzia digitale Benngler (il predecessore di sanity.io) ha realizzato il nuovo sito web per oma.eu, non ha strutturato il contenuto secondo un'elaborata gerarchia di pagine. Hanno creato tipi di contenuto che riflettevano la realtà quotidiana dell'organizzazione, ovvero dopo progetti , persone e pubblicazioni . In effetti, il sito OMA è quasi completamente piatto in termini di gerarchia dei contenuti e la prima pagina è generata da un mix di regole algoritmiche ed editoriali.

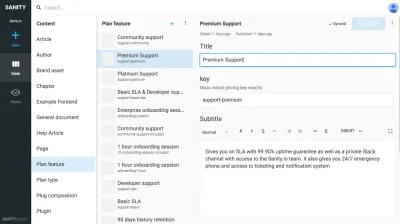
Allora, come procedere? Credo che un mix di pensare al tuo contenuto come riflesso di come il modello mentale della tua organizzazione e di cosa deve essere per essere utile per qualsiasi cosa i tuoi utenti ne abbiano bisogno.
Ecco un esempio di base: quando crei una pagina di dipendenti, dovresti probabilmente iniziare con un tipo di contenuto chiamato persona . Una persona può avere un nome, informazioni di contatto, un'immagine, diversi ruoli organizzativi e una breve biografia. Un documento personale può essere riutilizzato in elenchi di contatti, sottotitoli di autori di articoli, interfacce di supporto chat e badge di accesso agli edifici. Forse hai già un sistema interno che sa chi sono queste persone e che viene fornito con un'API? Ottimo, quindi sincronizzati con quello.
Non perderti in una tana ontologica del coniglio
È utile tornare al modo in cui Google indicizza le pagine Web e al modo in cui tenta di indicizzare le informazioni del mondo. Ecco perché stanno spendendo tempo e fatica sui dati collegati (RDFa, microformat, JSON-LD). Se annoti le tue pagine web con elementi JSON-LD, apparirai in modo più evidente nei risultati di ricerca. È anche rilevante quando le tue informazioni devono essere pronunciate dagli assistenti vocali e visualizzate nell'interfaccia utente dell'assistente. Se il tuo contenuto è già strutturato e facilmente disponibile in un'API, sarà relativamente facile implementarlo in questi microformati.
Non sono sicuro che consiglierei di approfondire le ontologie di schema.org e varie risorse di dati collegate, almeno non per scopi di editor. Puoi perderti rapidamente in una tana del coniglio cercando di creare strutture platoniche perfette dove tutto si adatta.
Newsflash : Non lo farà mai, perché il mondo è un posto disordinato e perché le persone pensano alle cose in modo diverso.
È più importante strutturare i tuoi contenuti in un sistema che abbia un senso intuitivo e si presti ad essere adattato al mutare delle esigenze. Questo è il motivo per cui è importante iniziare con la modellazione dei contenuti nelle prime fasi del processo di progettazione e sviluppo: è necessario conoscere come deve essere utilizzata.
Estratto dalla realtà, non dalle convenzioni CMS
Può essere allettante seguire le convenzioni con cui viene fornito il tuo CMS. Ricordi come Wordpress ti darà "Post" e "Pagine" e all'improvviso tutto deve essere inserito in quelle scatole? Un campo di testo RTF WYSIWYG è flessibile in quanto ti consente di inserire qualsiasi cosa, ma il contenuto non sarà strutturato e facilmente adattabile: è flessibile solo una volta. Ma hai bisogno di un posto per iniziare la mappatura di un modello di contenuto. Il mio suggerimento è di iniziare parlando con le persone, cioè gli autori ei lettori.
In che modo le persone parlano internamente del contenuto? Come chiamano le persone cose diverse? Potresti eseguire un esercizio di quotazione libera, un metodo utilizzato dagli etnografi per mappare le tassonomie popolari. Ad esempio, potresti chiedere:
"Nomina i diversi tipi di contenuto nella nostra organizzazione".
Oppure, a un livello più specifico:
"Puoi nominare i diversi tipi di rapporti che abbiamo in questa organizzazione?"
Il punto con questo sondaggio è quello di prendere in giro le tassonomie interiorizzate che le persone portano, e non le loro opinioni o sentimenti sulle cose (qualcosa che spesso tende a far deragliare i processi di progettazione). Non devi chiedere particolarmente a molti prima di avere un elenco piuttosto esauriente su cui puoi lavorare. Probabilmente scoprirai che parti del tuo elenco provengono da convenzioni nel tuo attuale CMS (è bene sapere se devi fare un po' di rimodellamento). Ora dovresti parlare con il tuo editore e provare a definire cosa devono fare i contenuti.
Alcune domande che puoi porre potrebbero essere le seguenti:
- Hai bisogno di utilizzare questo contenuto in più di un posto? Dove?
- Quali sono le diverse relazioni tra i tipi di contenuto?
- Dove abbiamo bisogno che il contenuto venga visualizzato oggi e domani?
- In che modo abbiamo bisogno che i contenuti siano ordinati? L'ordine può essere fatto algoritmicamente, dall'utente, o deve essere fatto manualmente?
- Ci sono sistemi o database in altri sistemi con cui possiamo sincronizzarci per prevenire la duplicazione?
- Dove vogliamo che viva il contenuto canonico? L'SCMS dovrebbe esserne la fonte, o semplicemente aumentare il contenuto esistente, ad esempio copia di marketing per prodotti che vivono in un sistema di gestione del prodotto?
Questo non significa che devi buttare via la tradizionale architettura dell'informazione con l'acqua del bagno ora tiepida. Ha comunque senso avere articoli come tipo di contenuto, se gli articoli fanno parte della realtà dei contenuti dell'organizzazione. Ma forse non hai davvero bisogno della convenzione astratta delle categorie , perché come questi articoli hanno riferimenti al tipo di servizi o prodotti in essi contenuti. E questa relazione consente di interrogare questi articoli in circostanze in cui ha senso, senza richiedere a qualcuno di avere una "gestione delle categorie di articoli" come parte della descrizione del lavoro.
L' articolo è anche ciò che rende difficile disaccoppiare completamente il contenuto dal livello di presentazione. Siamo così abituati a pensare al layout e allo stile dell'articolo, ma in un'epoca in cui ci si aspetta che tu ospiti i tuoi contenuti sul tuo dominio e poi li distribuisca su piattaforme come medium.com, hai già rinunciato controllo sulla presentazione visiva. Questo ci porta alla prossima strategia.
3. Anche i contesti di presentazione sono tipi di contenuto
Sii pronto per la riprogettazione
Vuoi essere in grado di adattare e modificare rapidamente anche la struttura di navigazione del tuo sito Web, senza dover ricostruire l'intera architettura dei contenuti o combattere contro un'interfaccia rigida simile a una cartella. Vuoi anche essere in grado di avere una gerarchia di contenuti, perché a volte ha senso ea volte diventa più profondo di due livelli, dove la maggior parte delle interfacce nel dipartimento dei CMS API-first non fornisce molto aiuto.
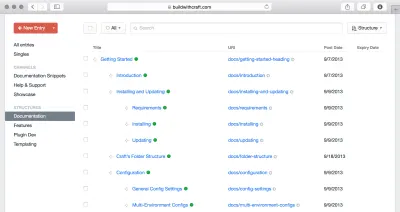
È interessante notare che i sistemi di gestione dei contenuti per i chatbot tendono a utilizzare strutture gerarchiche simili per organizzare alberi di intenti e flussi di dialogo. Questo significa che le gerarchie dei contenuti svolgono ruoli diversi in canali diversi, ma spesso forniscono modi per navigare attraverso i contenuti. Un modo per affrontare questo problema è creare tipi per la navigazione, in cui è possibile organizzare il contenuto in base ai riferimenti e creare percorsi per pagine Web, menu o percorsi per interfacce di conversazione.
Consigli sulle relazioni
I riferimenti (o le relazioni) sono ciò che rende possibile un sistema per contenuti strutturati, ed è davvero il fulcro di tutto ciò con cui abbiamo a che fare quando si tratta di contenuti sul web (è il motivo per cui è metaforicamente chiamato web in primo luogo). Essere in grado di fare riferimenti tra bit di contenuto è una cosa molto potente, ma può anche essere costoso in termini di come i backend sono in grado di scrivere e recuperare tali dati. Quindi potresti dover pensare in modo diverso se hai moltissimi documenti poiché la scalabilità raramente arriva gratuitamente.
Vale anche la pena considerare che non sempre è necessario un riferimento esplicito per unire i dati; il più delle volte può essere fatto in base a criteri che hanno a che fare con il contenuto, ad esempio "dammi tutte le persone e tutti gli edifici all'interno di questa geolocalizzazione". Non è necessario che l'edificio e le persone abbiano un riferimento esplicito l'uno all'altro, purché sia implicito in un campo posizione su entrambi i tipi di contenuto.
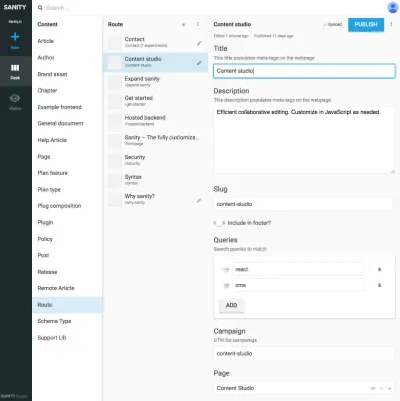
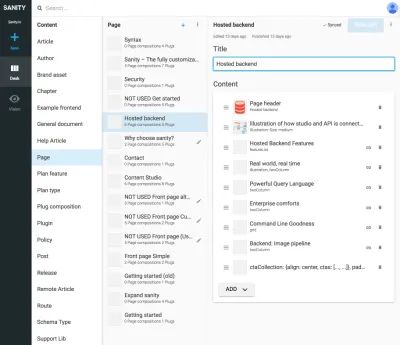
I riferimenti tra tipi di presentazione e altri tipi di contenuto sono utili quando non puoi lasciare che un algoritmo nel livello di presentazione unisca i dati. Può sembrare un po' complicato disegnare in modo esplicito questi tipi di presentazione e creare composizioni di contenuti di riferimento, ma è una soluzione a un problema che incontrerai spesso con gli SCMS: è difficile sapere dove viene utilizzato il contenuto. Includendo i tipi di navigazione, collegherai esplicitamente il contenuto alla presentazione, ma non solo a uno. Ciò consente di ragionare per lavorare con le strutture di navigazione indipendentemente dal contenuto a cui conducono.
Ad esempio, negli screenshot abbiamo legato Google Experiments al tipo di percorso , consentendo l'aggiunta di più pagine composte da riferimenti al contenuto, il che significa che possiamo eseguire A/B-test quasi senza duplicare i contenuti. Poiché riceviamo anche un avviso se proviamo a eliminare il contenuto a cui fanno riferimento altri documenti, questo modo di strutturare ci impedirà di eliminare qualcosa che non dovremmo.
Le relazioni tra i tipi di contenuto sono un'arma a doppio taglio. Aumenta la sostenibilità ed è fondamentale per evitare duplicazioni. D'altra parte, puoi facilmente tagliarti perché crei dipendenze tra i contenuti, il che (se non reso trasparente) può portare a modifiche indesiderate attraverso i canali in cui vengono visualizzati i tuoi dati. Ad esempio, sarebbe negativo se potessimo rimuovere una "pagina" utilizzata da un "percorso" senza preavviso.
Questo ci porta alla strategia successiva, che (scontato!) è in parte al di là del potere dell'utente normale ad oggi poiché ha a che fare con il modo in cui i diversi sistemi sono progettati. Tuttavia, vale la pena pensarci.
4. Non mettere Rich Text in un angolo
Il Rich Text è più di HTML
Posso capire perché l'HTML ha una tale prevalenza nei contenuti digitali, ma so che deriva anche da qualcosa; è un sottoinsieme di SGML, un modo generalizzato di strutturare documenti leggibili dalla macchina. Come sottolinea Claire L. Evans nel meraviglioso libro "Broad Band: The Untold Story of the Women who made the Internet" (2018), quando è stato introdotto l'HTML c'era già una vivace comunità di persone che pensavano ai documenti collegati. La proposta di Tim Berners-Lee era molto più semplice di molti altri sistemi dell'epoca, ma probabilmente è per questo che ha preso piede e ha reso possibile il Web libero e aperto, per ora.
Quando sei in un browser sul World Wide Web, l'HTML è fantastico. Se sei uno scrittore che vuole pubblicare qualcosa che finisce in un semplice HTML, Markdown è fantastico. Se vuoi che il tuo contenuto RTF sia facilmente integrato in qualcosa che non è un browser, o un popolare framework JavaScript che ti consente di aumentare l'HTML con JavaScript in componenti complessi (sì, stiamo parlando di React e Vue.js) , avere HTML nelle risposte dell'API inizia a essere un po' una seccatura, soprattutto se è necessario analizzarlo.
Quasi tutti lo fanno però, anche i nuovi arrivati sul blocco: ho esaminato tutti i fornitori su headlesscms.org e ho sfogliato la documentazione, e mi sono anche iscritto per quelli che non lo menzionavano. Con due eccezioni, tutti hanno archiviato il rich text come HTML o Markdown. Va bene se tutto ciò che fai è usare Jekyll per eseguire il rendering di un sito Web o se ti piace usare pericolosamenteSetInnerHTML in React. Ma cosa succede se desideri riutilizzare i tuoi contenuti in interfacce che non sono sul Web? O se desideri maggiore controllo e funzionalità nel tuo editor di testo RTF? O vuoi semplicemente che sia più facile eseguire il rendering del tuo testo RTF in uno dei framework frontend più diffusi e che i tuoi componenti si occupino di diverse parti del tuo contenuto RTF? Bene, dovrai trovare un modo intelligente per analizzare quel markdown o HTML in ciò di cui hai bisogno, o, più convenientemente, semplicemente archiviarlo in modo più sensato in primo luogo.
Ad esempio, cosa succede se desideri inviare il tuo testo RTF a un'interfaccia vocale? Sappiamo che gli assistenti vocali stanno aumentando di popolarità. Le piattaforme più popolari per questi assistenti hanno la capacità di ottenere il testo per i contenuti vocali tramite le API. Quindi vuoi sfruttare qualcosa come il linguaggio di markup della sintesi vocale. Un sistema per il testo portatile adotta un approccio più agnostico al RTF, che consente di adattare lo stesso contenuto a diversi tipi di interfacce.
Letture consigliate : Sperimentare con l'interfaccia SpeechSynthesis
Testo portatile come modello di testo ricco agnostico
Il testo portatile è utile anche quando si creano principalmente contenuti per il Web. E se volessi avere la possibilità di annidare e aumentare il tuo testo con strutture di dati, come una nota a piè di pagina in formato RTF o un commento editoriale in linea? O una frase o una formulazione alternativa per i casi di test A/B? Markdown e HTML non sono all'altezza e dovrai fare affidamento sull'aggiunta di qualcosa come tag shortcode speciali, proprio come Wordpress ha risolto. With portable text, you have an agnostic representation of content structures, without having to marry a certain implementation. Your content ends up being more sustainable and flexible for new redesigns and implementations.
There are also other advantages to portable text, especially if you want to be able to edit content collaboratively and in real time (as you do in Google Docs); you need to store rich text in another structure than HTML. If you do, you'll also be able to take advantage of microservices and bots, such as spaCy, in order to annotate and augment your content without locking the document.
As for now, portable text isn't widely adopted, but we're seeing movements towards it. The specification isn't very complex and can be explored at portabletext.org.
5. Make Sure Your SCMS Is In Service For Your Editors, And Not The Other Way Around
Digital content isn't just used for your organization's online web page leaflets anymore. For most of us, it encapsulates and defines how your organization is understood by the world, both from those within it and those outside: From product copy, micro texts to blog posts, chatbot responses, and strategy documents. We are millions of people that have to log into some CMS every day and navigate interfaces that were imagined twenty years ago with the assumptions of people who have never made much effort to user test or challenge their interfaces. Countless hours have been wasted away trying to fit a modern frontend experience into a page layout machine. Fortunately, this is soon a thing of the past.
As a technology consultant, I had to read through pages of technical specification whenever someone thought it was time to acquire a new CMS for themselves. There were demands from which server architecture it should run on (Windows servers, of course) to their ability to render “carousels” and “being able to edit web pages in place”, despite also requesting a “modular redesign”. When editors had been allowed to contribute to these specifications, they were also often dated to the what the editors had begotten used to. They seemed not aware that they could demand better user experiences, because enterprise software has to be big, lumpy and boring.
This is partly the fault of us making these systems. We tend to communicate technology features and specifications, and less what the everyday situation working with these systems look like. Sure, for a frontend designer, something supporting GraphQL is shorthand for how conveniently she is able to work against the backend, but on a higher level, it's about the systems ability to accommodate for emerging workflows, where a content model could survive visual redesigns and design systems should be resilient to changes of its content.
Questions To Ask Of Your (S)CMS
If we are to embrace design processes, we can't know prior to solving the problem whether the user tasks are best solved by making carousels ( newsflash: most probably not ), or whether A/B-testing makes sense for your case, even though it sounds cool.
Instead, ask questions like this:
- Is it possible, and how exactly will multi-disciplinary teams work with this system?
- How easy is it to change and migrate the content model?
- How does it deal with file and image assets?
- Has the editorial interface been user tested?
- To what extent can the system be configured and customized to special workflows and needs of the editorial team?
- How easy is it to export the content in a moveable format?
- How does the system accommodate for collaboration?
- Can content models be version controlled?
- How easy is it to integrate the system with a larger ecosystem of flowing information?
The goal of these questions is to explore to what degree a content management system allows for a cross-disciplinary team to work effortlessly together, without too many bottle-necks or long deployment cycles. They also push the focus to be more about the content should be doing, and less about how things should look in a given context. Leave that for the design processes, where user testing probably will challenge assumptions one may have when looking into getting a new content system.
There are, of course, many factors in addition to this that probably have to be taken into consideration. The easiest thing to assess is the fiscal cost of software licenses and API-related costs if you are on a hosted service. The invisible cost (in time and attention spent by the team working with the system), is harder to estimate. From my experience, many of the SCMSs in combination with one of the popular frontend frameworks can significantly cut development time and allow for an agile ( there's my coin for the swear jar ) design process. With the caveat that your team is prepared to solve some of the problems that come out of the box with traditional CMSs.
Towards Structured Content
The ways we work with digital content has changed dramatically since the World Wide Web made working with interconnected documents mainstream. Organizations, businesses, and corporations have amassed gigabytes of this content, which now is stuck in rigid page hierarchies, HTML markup, and clunky user interfaces.
Using a Structured Content Management System can be a great way to free your content from a paradigm that begins to feel its age. But it isn't a trivial exercise, and success comes from being able to work multi-disciplinary and put your content model to the test. You need to get rid of some conventions you have grown used to by dealing with CMSs designed to output hierarchical websites. That means that you need to think differently about ordering content, make presentations types in order to make it easier to orchestrate content across multiple channels and to consider how you structure rich text so that it can be used outside of HTML contexts.
This article deals with some of the high-level concerns working with SCMSs. There are, of course, loads of exciting challenges when you start working with this in your team. You have to rethink stuff we've taken for granted for many years, but that's probably a good thing. Because we are forced to evaluate our content, not only from its place on a digital page but from its role in a larger system that works for whatever goals your organization and your users may have.
I believe that we can achieve content models that are more meaningful and easier to sustain in the long run, and that means saving time and expenses. It means more flexibility in terms of inventing new outputs and services, and less tie in with software vendors. Because a well-made Structured Content Management System will make it easy for you to take your content and go elsewhere. And that makes for some interesting competition. Hopefully, all in favor of the users.