
Previsione del mercato azionario utilizzando l'apprendimento automatico [implementazione passo passo]
Pubblicato: 2021-02-26Sommario
introduzione
La previsione e l'analisi del mercato azionario sono alcuni dei compiti più complicati da fare. Ci sono diverse ragioni per questo, come la volatilità del mercato e tanti altri fattori dipendenti e indipendenti per decidere il valore di un particolare titolo sul mercato. Questi fattori rendono molto difficile per qualsiasi analista del mercato azionario prevedere l'aumento e il calo con livelli di precisione elevati.
Tuttavia, con l'avvento del Machine Learning e dei suoi robusti algoritmi, le ultime analisi di mercato e gli sviluppi di Stock Market Prediction hanno iniziato a incorporare tali tecniche nella comprensione dei dati del mercato azionario.
In breve, gli algoritmi di apprendimento automatico sono ampiamente utilizzati da molte organizzazioni per analizzare e prevedere i valori delle azioni. Questo articolo esaminerà una semplice implementazione dell'analisi e della previsione dei valori delle azioni di un negozio al dettaglio online popolare in tutto il mondo utilizzando diversi algoritmi di apprendimento automatico in Python.
Dichiarazione problema
Prima di entrare nell'implementazione del programma per prevedere i valori del mercato azionario, visualizziamo i dati su cui lavoreremo. Qui, analizzeremo il valore delle azioni di Microsoft Corporation (MSFT) dalla National Association of Securities Dealers Automated Quotations (NASDAQ). I dati sul valore delle azioni verranno presentati sotto forma di un file separato da virgole (.csv), che può essere aperto e visualizzato utilizzando Excel o un foglio di calcolo.
MSFT ha le sue azioni registrate nel NASDAQ e ha i suoi valori aggiornati durante ogni giorno lavorativo del mercato azionario. Nota che il mercato non consente il trading di sabato e domenica; quindi c'è un divario tra le due date. Per ciascuna data vengono annotati il Valore di Apertura del titolo, i valori Massimo e Minimo di quel titolo negli stessi giorni, insieme al Valore di Chiusura alla fine della giornata.
Il valore di chiusura rettificato mostra il valore del titolo dopo la pubblicazione dei dividendi (troppo tecnico!). Inoltre, viene fornito anche il volume totale delle azioni sul mercato. Con questi dati, spetta al lavoro di un Machine Learning/Data Scientist studiare i dati e implementare diversi algoritmi in grado di estrarre modelli dallo storico delle azioni di Microsoft Corporation dati.

Memoria a lungo termine
Per sviluppare un modello di Machine Learning per prevedere i prezzi delle azioni di Microsoft Corporation, utilizzeremo la tecnica della memoria a lungo termine (LSTM). Sono usati per apportare piccole modifiche alle informazioni mediante moltiplicazioni e addizioni. Per definizione, la memoria a lungo termine (LSTM) è un'architettura di rete neurale ricorrente (RNN) artificiale utilizzata nel deep learning.
A differenza delle reti neurali feed-forward standard, LSTM ha connessioni di feedback. Può elaborare singoli punti dati (come immagini) e intere sequenze di dati (come voce o video). Per comprendere il concetto alla base di LSTM, prendiamo un semplice esempio di recensione online di un telefono cellulare da parte di un cliente.
Supponiamo di voler acquistare il Mobile Phone, di solito ci riferiamo alle recensioni nette degli utenti certificati. A seconda del loro pensiero e dei loro input, decidiamo se il cellulare è buono o cattivo e quindi lo acquistiamo. Mentre continuiamo a leggere le recensioni, cerchiamo parole chiave come "incredibile", "buona fotocamera", "miglior backup della batteria" e molti altri termini relativi a un telefono cellulare.
Tendiamo a ignorare le parole comuni in inglese come "it", "gave", "this", ecc. Pertanto, quando decidiamo se acquistare o meno il cellulare, ricordiamo solo queste parole chiave sopra definite. Molto probabilmente, dimentichiamo le altre parole.
Questo è lo stesso modo in cui funziona l'algoritmo della memoria a lungo termine. Ricorda solo le informazioni rilevanti e le usa per fare previsioni ignorando i dati non rilevanti. In questo modo, dobbiamo costruire un modello LSTM che essenzialmente riconosca solo i dati essenziali su quel titolo e ne trascuri i valori anomali.
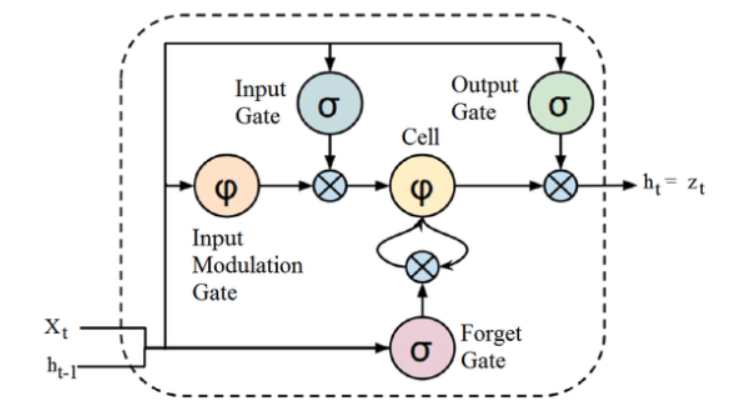
Fonte
Sebbene la struttura sopra indicata di un'architettura LSTM possa sembrare intrigante all'inizio, è sufficiente ricordare che LSTM è una versione avanzata di Recurrent Neural Networks che conserva la memoria per elaborare sequenze di dati. Può rimuovere o aggiungere informazioni allo stato cellulare, attentamente regolato da strutture chiamate porte.
L'unità LSTM comprende una cella, una porta di ingresso, una porta di uscita e una porta di dimenticanza. La cella ricorda i valori su intervalli di tempo arbitrari e le tre porte regolano il flusso di informazioni in entrata e in uscita dalla cella.
Attuazione del programma
Passeremo alla parte in cui utilizzeremo LSTM per prevedere il valore delle azioni utilizzando Machine Learning in Python.
Passaggio 1: importare le librerie
Come tutti sappiamo, il primo passo è importare le librerie necessarie per preelaborare i dati di stock di Microsoft Corporation e le altre librerie necessarie per costruire e visualizzare gli output del modello LSTM. Per questo, utilizzeremo la libreria Keras nel framework TensorFlow. I moduli richiesti vengono importati singolarmente dalla libreria Keras.
#Importare le biblioteche
importa panda come PD
importa NumPy come np
%matplotlib in linea
importa matplotlib. pyplot come plt
importa matplotlib
da sklearn. Importazione di preelaborazione MinMaxScaler
di Keras. i livelli importano LSTM, Dense, Dropout
da sklearn.model_selection importa TimeSeriesSplit
da sklearn.metrics import mean_squared_error, r2_score
importa matplotlib. date come mandati
da sklearn. Importazione di preelaborazione MinMaxScaler
da sklearn import linear_model
di Keras. Importazione modelli sequenziale
di Keras. I livelli importano Denso
importa Keras. Backend come K
di Keras. Le richiamate importano EarlyStopping
di Keras. Gli ottimizzatori importano Adam
di Keras. I modelli importano load_model
di Keras. I livelli importano LSTM
di Keras. utils.vis_utils importa plot_model
Passaggio 2: visualizzazione dei dati
Utilizzando la libreria del lettore di dati Pandas, caricheremo i dati delle scorte del sistema locale come file Comma Separated Value (.csv) e li memorizzeremo in un DataFrame pandas. Infine, esamineremo anche i dati.
#Ottieni il set di dati
df = pd.read_csv("MicrosoftStockData.csv",na_values=['null'],index_col='Date',parse_dates=True,infer_datetime_format=True)
df.head()
Ottieni la certificazione AI online dalle migliori università del mondo: master, programmi post-laurea esecutivi e programma di certificazione avanzata in ML e AI per accelerare la tua carriera.
Passaggio 3: stampare la forma DataFrame e verificare la presenza di valori Null.
In questo ulteriore passaggio cruciale, stampiamo prima la forma del set di dati. Per assicurarci che non ci siano valori nulli nel frame di dati, li controlliamo. La presenza di valori nulli nel set di dati tende a causare problemi durante l'addestramento poiché agiscono come valori anomali causando un'ampia varianza nel processo di addestramento.
#Stampa forma dataframe e verifica valori nulli
print("Forma dataframe: ", forma df.)
print("Null Value Present: ", df.IsNull().values.any())
>> Forma frame dati: (7334, 6)
>>Null Value Present: Falso
| Data | Aprire | Alto | Basso | Vicino | Agg Chiudi | Volume |
| 02-01-1990 | 0.605903 | 0.616319 | 0,598090 | 0.616319 | 0,447268 | 53033600 |
| 03-01-1990 | 0.621528 | 0.626736 | 0,614583 | 0.619792 | 0,449788 | 113772800 |
| 04-01-1990 | 0.619792 | 0.638889 | 0.616319 | 0.638021 | 0,463017 | 125740800 |
| 05-01-1990 | 0.635417 | 0.638889 | 0.621528 | 0.622396 | 0,451678 | 69564800 |
| 08-01-1990 | 0.621528 | 0.631944 | 0,614583 | 0.631944 | 0,458607 | 58982400 |
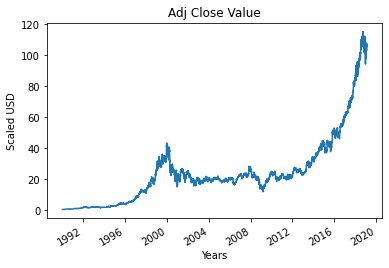
Passaggio 4: tracciare il valore di chiusura corretto corretto
Il valore di output finale che deve essere previsto utilizzando il modello di Machine Learning è il valore di chiusura rettificato. Questo valore rappresenta il valore di chiusura del titolo in quel particolare giorno di negoziazione del mercato azionario.
#Traccia il valore di chiusura dell'adj vero
df['Chiudi adj'].plot()
Passaggio 5: impostazione della variabile target e selezione delle funzionalità
Nel passaggio successivo, assegniamo la colonna di output alla variabile di destinazione. In questo caso, è il valore relativo rettificato di Microsoft Stock. Inoltre, selezioniamo anche le caratteristiche che fungono da variabile indipendente rispetto alla variabile target (variabile dipendente). Per tenere conto dello scopo della formazione, scegliamo quattro caratteristiche, che sono:

- Aprire
- Alto
- Basso
- Volume
#Imposta variabile di destinazione
output_var = PD.DataFrame(df['Chiudi adj'])
#Selezione delle caratteristiche
caratteristiche = ['Aperto', 'Alto', 'Basso', 'Volume']
Passaggio 6: ridimensionamento
Per ridurre il costo di calcolo dei dati nella tabella, riduciamo i valori stock a valori compresi tra 0 e 1. In questo modo, tutti i dati in grandi numeri vengono ridotti, riducendo così l'utilizzo della memoria. Inoltre, possiamo ottenere una maggiore precisione ridimensionando poiché i dati non sono distribuiti in valori enormi. Questo viene eseguito dalla classe MinMaxScaler della libreria sci-kit-learn.
#Ridimensionamento
scaler = MinMaxScaler()
feature_transform = scaler.fit_transform(df[caratteristiche])
feature_transform= pd.DataFrame(colonne=features, data=feature_transform, index=df.index)
feature_transform.head()
| Data | Aprire | Alto | Basso | Volume |
| 02-01-1990 | 0.000129 | 0.000105 | 0.000129 | 0,064837 |
| 03-01-1990 | 0.000265 | 0.000195 | 0.000273 | 0,144673 |
| 04-01-1990 | 0.000249 | 0.000300 | 0.000288 | 0.160404 |
| 05-01-1990 | 0.000386 | 0.000300 | 0.000334 | 0,086566 |
| 08-01-1990 | 0.000265 | 0.000240 | 0.000273 | 0,072656 |
Come accennato in precedenza, vediamo che i valori delle variabili di funzionalità vengono ridimensionati a valori inferiori rispetto ai valori reali indicati sopra.
Passaggio 7: suddivisione in un set di allenamento e in un set di test.
Prima di inserire i dati nel modello di addestramento, è necessario suddividere l'intero set di dati in set di addestramento e test. Il modello Machine Learning LSTM sarà addestrato sui dati presenti nel set di addestramento e testato sul set di test per accuratezza e backpropagation.
Per questo, utilizzeremo la classe TimeSeriesSplit della libreria sci-kit-learn. Impostiamo il numero di suddivisioni su 10, il che indica che il 10% dei dati verrà utilizzato come set di test e il 90% dei dati verrà utilizzato per il training del modello LSTM. Il vantaggio dell'utilizzo di questa suddivisione delle serie temporali è che i campioni di dati delle serie temporali parziali vengono osservati a intervalli di tempo fissi.
#Splitting to Training set e Test set
timesplit= TimeSeriesSplit(n_splits=10)
per train_index, test_index in timesplit.split(feature_transform):
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
Passaggio 8: elaborazione dei dati per LSTM
Una volta che i set di addestramento e test sono pronti, possiamo inserire i dati nel modello LSTM una volta creato. Prima di ciò, è necessario convertire i dati di training e test set in un tipo di dati che il modello LSTM accetterà. Prima convertiamo i dati di addestramento e testiamo in array NumPy, quindi li rimodelliamo nel formato (Numero di campioni, 1, Numero di funzionalità) poiché LSTM richiede che i dati vengano inseriti in forma 3D. Come sappiamo, il numero di campioni nel set di addestramento è il 90% di 7334, che è 6667, e il numero di funzioni è 4, il set di addestramento viene rimodellato in (6667, 1, 4). Allo stesso modo, anche il set di test viene rimodellato.
#Elabora i dati per LSTM
trenoX =np.array(X_treno)
testX =np.array(X_test)
X_train = trenoX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
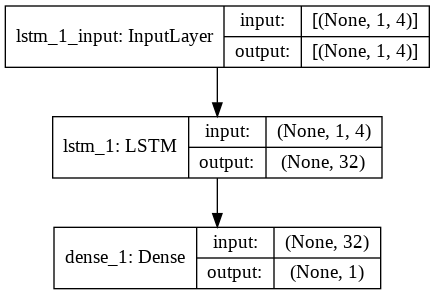
Passaggio 9: costruire il modello LSTM
Infine, arriviamo alla fase in cui costruiamo il modello LSTM. Qui creiamo un modello Keras sequenziale con un livello LSTM. Lo strato LSTM ha 32 unità ed è seguito da uno strato denso di 1 neurone.
Usiamo Adam Optimizer e Mean Squared Error come funzione di perdita per la compilazione del modello. Questi due sono la combinazione più preferita per un modello LSTM. Inoltre, anche il modello viene tracciato e visualizzato di seguito.
#Costruire il modello LSTM
lstm = sequenziale()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), activation='relu', return_sequences=False))
lstm.add(Dense(1))
lstm.compile(loss='mean_squared_error', ottimizzatore='adam')
plot_model(lstm, show_shapes=True, show_layer_names=True)
Passaggio 10: addestrare il modello
Infine, addestriamo il modello LSTM progettato sopra sui dati di allenamento per 100 epoche con una dimensione batch di 8 utilizzando la funzione di adattamento.
#Formazione modello
history = lstm.fit(X_train, y_train, epochs=100, batch_size=8, verbose=1, shuffle=False)
Epoca 1/100
834/834 [================================] – 3s 2ms/passo – perdita: 67.1211
Epoca 2/100
834/834 [================================] – 1s 2ms/passo – perdita: 70.4911
Epoca 3/100
834/834 [================================] – 1s 2ms/passo – perdita: 48.8155
Epoca 4/100
834/834 [================================] – 1s 2ms/passo – perdita: 21.5447
Epoca 5/100
834/834 [================================] – 1s 2ms/passo – perdita: 6.1709
Epoca 6/100
834/834 [================================] – 1s 2ms/passo – perdita: 1.8726
Epoca 7/100
834/834 [================================] – 1s 2ms/passo – perdita: 0,9380
Epoca 8/100
834/834 [================================] – 2s 2ms/passo – perdita: 0,6566
Epoca 9/100
834/834 [================================] – 1s 2ms/passo – perdita: 0,5369
Epoca 10/100
834/834 [================================] – 2s 2ms/passo – perdita: 0,4761
.
.
.
.
Epoca 95/100
834/834 [================================] – 1s 2ms/passo – perdita: 0,4542
Epoca 96/100
834/834 [================================] – 2s 2ms/passo – perdita: 0,4553
Epoca 97/100
834/834 [================================] – 1s 2ms/passo – perdita: 0,4565
Epoca 98/100
834/834 [================================] – 1s 2ms/passo – perdita: 0,4576
Epoca 99/100
834/834 [================================] – 1s 2ms/passo – perdita: 0,4588
Epoca 100/100
834/834 [================================] – 1s 2ms/passo – perdita: 0,4599
Infine, vediamo che il valore della perdita è diminuito esponenzialmente nel tempo durante il processo di addestramento di 100 epoche e ha raggiunto un valore di 0,4599
Passaggio 11 – Pronostico LSTM
Con il nostro modello pronto, è il momento di utilizzare il modello addestrato utilizzando la rete LSTM sul set di test e prevedere il valore di chiusura adiacente del titolo Microsoft. Questo viene eseguito utilizzando la semplice funzione di predict sul modello lstm costruito.
Pronostico #LSTM
y_pred= lstm.predict(X_test)
Passaggio 12 – Valore di chiusura dell'adj vero e previsto – LSTM
Infine, poiché abbiamo previsto i valori del set di test, possiamo tracciare il grafico per confrontare sia i valori veri di Adj Close che il valore previsto di Adj Close dal modello LSTM Machine Learning.
#True vs Predicted Adj Close Value – LSTM
plt.plot(y_test, label='Vero valore')
plt.plot(y_pred, label='Valore LSTM')
plt.title ("Pronostico di LSTM")
plt.xlabel('Scala temporale')
plt.ylabel('Scaled USD')
plt.leggenda()
plt.show()
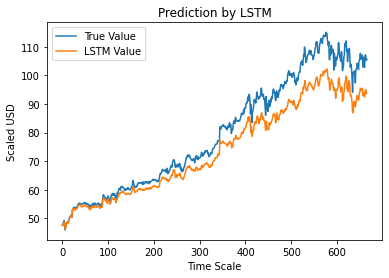
Il grafico sopra mostra che alcuni pattern vengono rilevati dal modello di rete LSTM singolo molto semplice costruito sopra. Mettendo a punto diversi parametri e aggiungendo più livelli LSTM al modello, possiamo ottenere una rappresentazione più accurata del valore delle azioni di una determinata società.
Conclusione
Se sei interessato a saperne di più su esempi di intelligenza artificiale e apprendimento automatico, dai un'occhiata al programma Executive PG di IIIT-B e upGrad in Machine Learning e AI , progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, stato di Alumni IIIT-B, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Puoi prevedere il mercato azionario usando l'apprendimento automatico?
Oggi abbiamo una serie di indicatori per aiutare a prevedere le tendenze del mercato. Tuttavia, non dobbiamo guardare oltre un computer ad alta potenza per trovare gli indicatori più accurati per il mercato azionario. Il mercato azionario è un sistema aperto e può essere visto come una rete complessa. La rete è costituita dalle relazioni tra azioni, società, investitori e volumi di scambio. Utilizzando un algoritmo di data mining come la macchina del vettore di supporto, puoi applicare una formula matematica per estrarre le relazioni tra queste variabili. Il mercato azionario è ormai al di là delle previsioni umane.
Quale algoritmo è il migliore per la previsione del mercato azionario?
Per ottenere i migliori risultati, dovresti usare la regressione lineare. La regressione lineare è un approccio statistico utilizzato per determinare la relazione tra due diverse variabili. In questo esempio, le variabili sono prezzo e tempo. Nella previsione del mercato azionario, il prezzo è la variabile indipendente e il tempo è la variabile dipendente. Se è possibile determinare una relazione lineare tra queste due variabili, è possibile prevedere con precisione il valore del titolo in qualsiasi momento futuro.
La previsione del mercato azionario è un problema di classificazione o regressione?
Prima di rispondere, dobbiamo capire cosa significano le previsioni del mercato azionario. È un problema di classificazione binaria o un problema di regressione? Supponiamo di voler prevedere il futuro di un'azione, dove futuro indica il giorno, la settimana, il mese o l'anno successivi. Se la performance passata del titolo in un determinato momento è l'input e il futuro è l'output, allora è un problema di regressione. Se la performance passata di un'azione e il futuro di un'azione sono indipendenti, allora è un problema di classificazione.