
Utilizzo di SSE invece di WebSocket per il flusso di dati unidirezionale su HTTP/2
Pubblicato: 2022-03-10Quando si costruisce un'applicazione Web, è necessario considerare che tipo di meccanismo di consegna verrà utilizzato. Diciamo che abbiamo un'applicazione multipiattaforma che funziona con dati in tempo reale; un'applicazione del mercato azionario che offre la possibilità di acquistare o vendere azioni in tempo reale. Questa applicazione è composta da widget che apportano un valore diverso ai diversi utenti.
Quando si tratta di consegna dei dati dal server al client, siamo limitati a due approcci generali: client pull o server push . Come semplice esempio con qualsiasi applicazione web, il client è il browser web. Quando il sito Web nel tuo browser richiede dati al server, questo viene chiamato client pull . Al contrario, quando il server invia in modo proattivo gli aggiornamenti al tuo sito Web, viene chiamato server push .
Al giorno d'oggi, ci sono alcuni modi per implementarli:
- Sondaggio lungo/breve (client pull)
- WebSocket (push del server)
- Eventi inviati dal server (server push).
Analizzeremo in modo approfondito le tre alternative dopo aver impostato i requisiti per il nostro business case.
Il caso aziendale
Per poter fornire rapidamente nuovi widget per la nostra applicazione di borsa e collegarli senza ridistribuzione dell'intera piattaforma, abbiamo bisogno che questi siano autonomi e gestiscano i propri dati I/O. I widget non sono accoppiati tra loro in alcun modo. Nel caso ideale, tutti si iscriveranno a un endpoint API e inizieranno a ottenere dati da esso. Oltre a un time-to-market più rapido delle nuove funzionalità, questo approccio ci dà la possibilità di esportare contenuti su siti Web di terze parti mentre i nostri widget offrono tutto ciò di cui hanno bisogno da soli.
L'insidia principale qui è che il numero di connessioni aumenterà linearmente con il numero di widget che abbiamo e raggiungeremo il limite dei browser per il numero di richieste HTTP gestite contemporaneamente.
I dati che i nostri widget riceveranno sono principalmente costituiti da numeri e aggiornamenti ai loro numeri: la risposta iniziale contiene dieci titoli con alcuni valori di mercato per loro. Ciò include gli aggiornamenti dell'aggiunta/rimozione di azioni e gli aggiornamenti dei valori di mercato di quelli attualmente presentati. Trasferiamo piccole quantità di stringhe JSON per ogni aggiornamento il più velocemente possibile.
HTTP/2 fornisce il multiplexing delle richieste provenienti dallo stesso dominio, il che significa che possiamo ottenere solo una connessione per più risposte. Sembra che possa risolvere il nostro problema. Iniziamo esplorando le diverse opzioni per ottenere i dati e vedere cosa possiamo ricavarne.
- Utilizzeremo NGINX per il bilanciamento del carico e il proxy per nascondere tutti i nostri endpoint dietro lo stesso dominio. Questo ci consentirà di utilizzare il multiplexing HTTP/2 pronto all'uso.
- Vogliamo utilizzare la rete e la batteria dei dispositivi mobili in modo efficiente.
Le alternative
Sondaggio lungo

Client pull è l'equivalente dell'implementazione del software del bambino fastidioso seduto sul sedile posteriore della tua auto che chiede costantemente: "Siamo già arrivati?" In breve, il client chiede i dati al server. Il server non ha dati e attende un po' di tempo prima di inviare la risposta:
- Se compare qualcosa durante l'attesa, il server lo invia e chiude la richiesta;
- Se non c'è nulla da inviare e viene raggiunto il tempo di attesa massimo, il server invia una risposta che non ci sono dati;
- In entrambi i casi il cliente apre la successiva richiesta di dati;
- Schiuma, risciacqua, ripeti.
Le chiamate AJAX funzionano sul protocollo HTTP, il che significa che le richieste allo stesso dominio dovrebbero essere multiplexate per impostazione predefinita. Tuttavia, abbiamo riscontrato diversi problemi nel tentativo di farlo funzionare come richiesto. Alcune delle insidie che abbiamo identificato con i nostri widget si avvicinano:
Intestazioni generali
Ogni richiesta e risposta di sondaggio è un messaggio HTTP completo e contiene un set completo di intestazioni HTTP nel frame del messaggio. Nel nostro caso in cui abbiamo piccoli messaggi frequenti, le intestazioni rappresentano effettivamente la percentuale maggiore dei dati trasmessi. Il carico utile effettivo è molto inferiore al totale dei byte trasmessi (ad esempio, 15 KB di intestazioni per 5 KB di dati).Latenza massima
Dopo che il server ha risposto, non può più inviare dati al client finché il client non invia la richiesta successiva. Mentre la latenza media per il polling lungo è vicina a un transito di rete, la latenza massima è su tre transiti di rete: risposta, richiesta, risposta. Tuttavia, a causa della perdita e della ritrasmissione dei pacchetti, la latenza massima per qualsiasi protocollo TCP/IP sarà superiore a tre transiti di rete (evitabili con il pipelining HTTP). Mentre nella connessione LAN diretta questo non è un grosso problema, lo diventa mentre si è in movimento e si cambiano le celle di rete. In una certa misura, questo si osserva con SSE e WebSocket, ma l'effetto è maggiore con il polling.Stabilimento della connessione
Sebbene possa essere evitato utilizzando una connessione HTTP persistente riutilizzabile per molte richieste di polling, è difficile programmare di conseguenza tutti i componenti per eseguire il polling in tempi brevi per mantenere attiva la connessione. Alla fine, a seconda delle risposte del server, i tuoi sondaggi verranno desincronizzati.Degrado delle prestazioni
Un client (o server) di polling lungo sotto carico ha una naturale tendenza a peggiorare le prestazioni a scapito della latenza del messaggio. Quando ciò accade, gli eventi inviati al client verranno inseriti nella coda. Questo dipende davvero dall'implementazione; nel nostro caso, dobbiamo aggregare tutti i dati mentre stiamo inviando eventi di aggiunta/rimozione/aggiornamento ai nostri widget.Timeout
Le richieste di polling lunghe devono rimanere in sospeso finché il server non ha qualcosa da inviare al client. Ciò può comportare la chiusura della connessione da parte del server proxy se rimane inattivo per troppo tempo.Multiplexing
Ciò può accadere se le risposte si verificano contemporaneamente su una connessione HTTP/2 persistente. Questo può essere difficile da fare poiché le risposte ai sondaggi non possono essere davvero sincronizzate.
Ulteriori informazioni sui problemi del mondo reale che si potrebbero riscontrare con i sondaggi lunghi sono disponibili qui .
WebSocket

Come primo esempio del metodo push del server , esamineremo WebSocket.
Tramite MDN:
WebSockets è una tecnologia avanzata che consente di aprire una sessione di comunicazione interattiva tra il browser dell'utente e un server. Con questa API, puoi inviare messaggi a un server e ricevere risposte basate su eventi senza dover eseguire il polling del server per una risposta.
Questo è un protocollo di comunicazione che fornisce canali di comunicazione full-duplex su una singola connessione TCP.
Sia HTTP che WebSocket si trovano a livello dell'applicazione dal modello OSI e come tali dipendono da TCP a livello 4.
- Applicazione
- Presentazione
- Sessione
- Trasporto
- Rete
- Collegamento dati
- Fisico
RFC 6455 afferma che WebSocket "è progettato per funzionare sulle porte HTTP 80 e 443, nonché per supportare proxy e intermediari HTTP", rendendolo così compatibile con il protocollo HTTP. Per ottenere la compatibilità, l'handshake WebSocket utilizza l'intestazione HTTP Upgrade per passare dal protocollo HTTP al protocollo WebSocket.
C'è anche un ottimo articolo che spiega tutto ciò che devi sapere sui WebSocket su Wikipedia. Ti incoraggio a leggerlo.
Dopo aver stabilito che le prese potrebbero effettivamente funzionare per noi, abbiamo iniziato a esplorare le loro capacità nel nostro caso aziendale e abbiamo colpito muro dopo muro.
Server proxy : in generale, ci sono alcuni problemi diversi con WebSocket e proxy:
- Il primo riguarda i fornitori di servizi Internet e il modo in cui gestiscono le loro reti. I problemi con i proxy del raggio hanno bloccato le porte e così via.
- Il secondo tipo di problemi è correlato al modo in cui il proxy è configurato per gestire il traffico HTTP non protetto e le connessioni di lunga durata (l'impatto è ridotto con HTTPS).
- Il terzo problema "con WebSockets, sei costretto a eseguire proxy TCP anziché proxy HTTP. I proxy TCP non possono inserire intestazioni, riscrivere URL o svolgere molti dei ruoli di cui tradizionalmente ci occupiamo i nostri proxy HTTP".
Un certo numero di connessioni : il famoso limite di connessione per le richieste HTTP che ruota attorno al numero 6, non si applica ai WebSocket. 50 prese = 50 connessioni. Dieci schede del browser per 50 socket = 500 connessioni e così via. Poiché WebSocket è un protocollo diverso per la distribuzione dei dati, non viene automaticamente multiplexato su connessioni HTTP/2 (in realtà non funziona affatto su HTTP). L'implementazione del multiplexing personalizzato sia sul server che sul client è troppo complicata per rendere i socket utili nel business case specificato. Inoltre, questo accoppia i nostri widget alla nostra piattaforma poiché avranno bisogno di una sorta di API sul client a cui iscriversi e non siamo in grado di distribuirli senza di essa.
Bilanciamento del carico (senza multiplexing) : se ogni singolo utente apre un numero
ndi socket, il corretto bilanciamento del carico è molto complicato. Quando i tuoi server vengono sovraccaricati e devi creare nuove istanze e terminare quelle vecchie a seconda dell'implementazione del tuo software, le azioni intraprese alla "riconnessione" possono innescare una massiccia catena di aggiornamenti e nuove richieste di dati che sovraccaricheranno il tuo sistema . I WebSocket devono essere mantenuti sia sul server che sul client. Non è possibile spostare le connessioni socket su un server diverso se quello attuale subisce un carico elevato. Devono essere chiusi e riaperti.DoS : Questo è solitamente gestito da proxy HTTP front-end che non possono essere gestiti dai proxy TCP necessari per i WebSocket. Ci si può connettere al socket e iniziare a inondare i server di dati. I WebSocket ti lasciano vulnerabile a questo tipo di attacchi.
Reinventare la ruota : con WebSocket, è necessario gestire molti problemi che vengono risolti in HTTP da soli.
Ulteriori informazioni sui problemi del mondo reale con WebSocket possono essere letti qui.
Alcuni buoni casi d'uso per WebSocket sono chat e giochi multiplayer in cui i vantaggi superano i problemi di implementazione. Poiché il loro principale vantaggio è la comunicazione duplex e non ne abbiamo davvero bisogno, dobbiamo andare avanti.
Impatto
Otteniamo un aumento del sovraccarico operativo in termini di sviluppo, test e ridimensionamento; il software e la sua infrastruttura IT con entrambi: polling e WebSocket.
Abbiamo lo stesso problema su dispositivi mobili e reti con entrambi. Il design hardware di questi dispositivi mantiene una connessione aperta mantenendo in vita l'antenna e la connessione alla rete cellulare. Ciò comporta una riduzione della durata della batteria, del calore e, in alcuni casi, costi aggiuntivi per i dati.
Ma perché abbiamo ancora problemi con i dispositivi mobili?
Consideriamo come il dispositivo mobile predefinito si connette a Internet:
Una semplice spiegazione di come funziona la rete mobile: in genere i dispositivi mobili hanno un'antenna a bassa potenza che può ricevere dati da una cella. In questo modo, una volta che il dispositivo riceve i dati da una chiamata in arrivo, avvia l'antenna full-duplex per stabilire la chiamata. La stessa antenna viene utilizzata ogni volta che si desidera effettuare una chiamata o accedere a Internet (se non è disponibile il WiFi). L'antenna full-duplex deve stabilire una connessione alla rete cellulare ed eseguire un'autenticazione. Una volta stabilita la connessione, c'è una comunicazione tra il tuo dispositivo e il cellulare per eseguire la nostra richiesta di rete. Veniamo reindirizzati al proxy interno del provider di servizi mobili che gestisce le richieste Internet. Da quel momento in poi, la procedura è già nota: chiede a un DNS dove si trova effettivamente www.domainname.ext , riceve l'URI alla risorsa ed eventualmente viene reindirizzato ad essa.
Questo processo, come puoi immaginare, assorbe molta energia dalla batteria. Questo è il motivo per cui i fornitori di telefoni cellulari offrono un tempo di standby di pochi giorni e un tempo di conversazione in appena un paio d'ore.
Senza Wi-Fi, sia i WebSocket che il polling richiedono che l'antenna full-duplex funzioni quasi costantemente. Pertanto, dobbiamo affrontare un maggiore consumo di dati e un maggiore assorbimento di energia e, a seconda del dispositivo, anche il calore.

Quando le cose sembreranno desolate, sembra che dovremo riconsiderare i requisiti aziendali per la nostra applicazione. Ci sfugge qualcosa?
SSE
Tramite MDN:
“L'interfaccia EventSource viene utilizzata per ricevere gli eventi inviati dal server. Si connette a un server tramite HTTP e riceve eventi in formato testo/flusso di eventi senza chiudere la connessione".
La differenza principale rispetto al polling è che otteniamo solo una connessione e manteniamo un flusso di eventi che la attraversa. Il lungo polling crea una nuova connessione per ogni pull, ergo le intestazioni in testa e altri problemi che abbiamo affrontato lì.
Tramite html5doctor.com:
Gli eventi inviati dal server sono eventi in tempo reale emessi dal server e ricevuti dal browser. Sono simili ai WebSocket in quanto si verificano in tempo reale, ma sono un metodo di comunicazione unidirezionale dal server.
Sembra strano, ma dopo aver riflettuto: il nostro flusso di dati principale è dal server al client e in molte meno occasioni dal client al server.
Sembra che possiamo usarlo per il nostro caso aziendale principale di fornire dati. Possiamo risolvere gli acquisti dei clienti inviando una nuova richiesta in quanto il protocollo è unidirezionale e il client non può inviare messaggi al server tramite esso. Questo alla fine avrà il ritardo dell'antenna full-duplex per l'avvio sui dispositivi mobili. Tuttavia, possiamo convivere con ciò che accade di tanto in tanto: dopotutto questo ritardo è misurato in millisecondi.
Caratteristiche uniche
- Il flusso di connessione proviene dal server ed è di sola lettura.
- Usano richieste HTTP regolari per la connessione persistente, non un protocollo speciale. Ottenere multiplexing su HTTP/2 fuori dagli schemi.
- Se la connessione si interrompe, EventSource genera un evento di errore e tenta automaticamente di riconnettersi. Il server può anche controllare il timeout prima che il client tenti di riconnettersi (spiegato in maggiori dettagli più avanti).
- I clienti possono inviare un ID univoco con i messaggi. Quando un client tenta di riconnettersi dopo una connessione interrotta, invierà l'ultimo ID noto. Quindi il server può vedere che il client ha perso
nnumero di messaggi e inviare il backlog di messaggi persi alla riconnessione.
Esempio di implementazione client
Questi eventi sono simili ai normali eventi JavaScript che si verificano nel browser, come gli eventi di clic, tranne per il fatto che possiamo controllare il nome dell'evento e i dati ad esso associati.
Vediamo la semplice anteprima del codice lato client:
// subscribe for messages var source = new EventSource('URL'); // handle messages source.onmessage = function(event) { // Do something with the data: event.data; };Quello che vediamo dall'esempio è che il lato client è abbastanza semplice. Si collega alla nostra fonte e attende di ricevere messaggi.
Per consentire ai server di inviare dati alle pagine Web tramite HTTP o utilizzando protocolli server-push dedicati, la specifica introduce l'interfaccia `EventSource` sul client. L'uso di questa API consiste nella creazione di un oggetto `EventSource` e nella registrazione di un listener di eventi.
L'implementazione del client per WebSocket è molto simile a questa. La complessità con i socket risiede nell'infrastruttura IT e nell'implementazione del server.
EventSource
Ogni oggetto EventSource ha i seguenti membri:
- URL: impostato durante la costruzione.
- Richiesta: inizialmente è nulla.
- Tempo di riconnessione: valore in ms (valore definito dall'agente utente).
- ID ultimo evento: inizialmente una stringa vuota.
- Stato pronto: stato della connessione.
- CONNESSIONE (0)
- APERTO (1)
- CHIUSO (2)
A parte l'URL, tutti sono trattati come privati e non sono accessibili dall'esterno.
Eventi integrati:
- Aprire
- Messaggio
- Errore
Gestione delle interruzioni di connessione
La connessione viene ristabilita automaticamente dal browser in caso di caduta. Il server può inviare il timeout per riprovare o chiudere la connessione in modo permanente. In tal caso, il browser rispetterà il tentativo di riconnettersi dopo il timeout o non tenterà affatto se la connessione ha ricevuto un messaggio di interruzione. Sembra abbastanza semplice - e in realtà lo è.
Esempio di implementazione del server
Bene, se il client è così semplice, forse l'implementazione del server è complessa?
Bene, il gestore del server per SSE potrebbe assomigliare a questo:
function handler(response) { // setup headers for the response in order to get the persistent HTTP connection response.writeHead(200, { 'Content-Type': 'text/event-stream', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive' }); // compose the message response.write('id: UniqueID\n'); response.write("data: " + data + '\n\n'); // whenever you send two new line characters the message is sent automatically }Definiamo una funzione che gestirà la risposta:
- Imposta intestazioni
- Creare un messaggio
- Spedire
Nota che non vedi una chiamata al metodo send() o push() . Questo perché lo standard definisce che il messaggio verrà inviato non appena riceve due \n\n caratteri come nell'esempio: response.write("data: " + data + '\n\n'); . Questo invierà immediatamente il messaggio al client. Si noti che i data devono essere una stringa di escape e non hanno nuovi caratteri di riga alla fine.
Costruzione del messaggio
Come accennato in precedenza, il messaggio può contenere alcune proprietà:
- ID
Se il valore del campo non contiene U+0000 NULL, impostare l'ultimo buffer dell'ID evento sul valore del campo. In caso contrario, ignora il campo. - Dati
Aggiungere il valore del campo al buffer di dati, quindi aggiungere un singolo carattere U+000A LINE FEED (LF) al buffer di dati. - Evento
Impostare il buffer del tipo di evento sul valore del campo. Questo portaevent.typea ottenere il nome dell'evento personalizzato. - Riprova
Se il valore del campo è costituito solo da cifre ASCII, interpretare il valore del campo come un numero intero in base dieci e impostare il tempo di riconnessione del flusso di eventi su tale numero intero. In caso contrario, ignora il campo.
Qualsiasi altra cosa verrà ignorata. Non possiamo introdurre i nostri campi.
Esempio con event aggiunto:
response.write('id: UniqueID\n'); response.write('event: add\n'); response.write('retry: 10000\n'); response.write("data: " + data + '\n\n'); Quindi sul client, questo viene gestito con addEventListener in quanto tale:
source.addEventListener("add", function(event) { // do stuff with data event.data; });Puoi inviare più messaggi separati da una nuova riga purché fornisci ID diversi.
... id: 54 event: add data: "[{SOME JSON DATA}]" id: 55 event: remove data: JSON.stringify(some_data) id: 56 event: remove data: { data: "msg" : "JSON data"\n data: "field": "value"\n data: "field2": "value2"\n data: }\n\n ...Questo semplifica enormemente ciò che possiamo fare con i nostri dati.
Requisiti specifici del server
Durante il nostro POC per il back-end, abbiamo identificato che ha alcune specifiche che devono essere affrontate per avere un'implementazione funzionante di SSE. Nel migliore dei casi utilizzerai server basati su loop di eventi come NodeJS, Kestrel o Twisted. L'idea è che con la soluzione basata su thread avrai un thread per connessione → 1000 connessioni = 1000 thread. Con la soluzione del ciclo di eventi, avrai un thread per 1000 connessioni.
- Puoi accettare richieste EventSource solo se la richiesta HTTP dice che può accettare il tipo MIME del flusso di eventi;
- È necessario mantenere un elenco di tutti gli utenti collegati per poter emettere nuovi eventi;
- Dovresti ascoltare le connessioni interrotte e rimuoverle dall'elenco degli utenti connessi;
- Facoltativamente, dovresti mantenere una cronologia dei messaggi in modo che i client di riconnessione possano recuperare i messaggi persi.
Funziona come previsto e all'inizio sembra magico. Otteniamo tutto ciò che desideriamo affinché la nostra applicazione funzioni in modo efficiente. Come per tutte le cose che sembrano troppo belle per essere vere, a volte dobbiamo affrontare alcuni problemi che devono essere affrontati. Tuttavia, non sono complicati da implementare o aggirare:
È noto che i server proxy legacy, in alcuni casi, interrompono le connessioni HTTP dopo un breve timeout. Per proteggersi da tali server proxy, gli autori possono includere una riga di commento (una che inizia con un carattere ':') ogni 15 secondi circa.
Gli autori che desiderano mettere in relazione le connessioni dell'origine eventi tra loro o con documenti specifici precedentemente serviti potrebbero scoprire che fare affidamento sugli indirizzi IP non funziona, poiché i singoli client possono avere più indirizzi IP (a causa della presenza di più server proxy) e singoli indirizzi IP possono avere più client (a causa della condivisione di un server proxy). È meglio includere un identificatore univoco nel documento quando viene servito e quindi passare tale identificatore come parte dell'URL quando viene stabilita la connessione.
Gli autori sono inoltre avvertiti che il chunking HTTP può avere effetti negativi imprevisti sull'affidabilità di questo protocollo, in particolare, se il chunking viene eseguito da un livello diverso ignaro dei requisiti di temporizzazione. Se questo è un problema, il chunking può essere disabilitato per servire i flussi di eventi.
I client che supportano la limitazione della connessione per server di HTTP potrebbero avere problemi durante l'apertura di più pagine da un sito se ogni pagina ha un EventSource nello stesso dominio. Gli autori possono evitarlo utilizzando il meccanismo relativamente complesso dell'utilizzo di nomi di dominio univoci per connessione o consentendo all'utente di abilitare o disabilitare la funzionalità EventSource in base alla pagina o condividendo un singolo oggetto EventSource utilizzando un ruolo di lavoro condiviso.
Supporto del browser e Polyfill: Edge è in ritardo rispetto a questa implementazione, ma è disponibile un polyfill che può salvarti. Tuttavia, il caso più importante per SSE riguarda i dispositivi mobili in cui IE/Edge non hanno una quota di mercato praticabile.
Alcuni dei polyfill disponibili:
- Yaffle
- amvtek
- remy
Push senza connessione e altre funzionalità
Gli user agent in esecuzione in ambienti controllati, ad es. browser su telefoni cellulari legati a carrier specifici, possono alleggerire la gestione della connessione a un proxy sulla rete. In una tale situazione, si considera che l'agente utente ai fini della conformità includa sia il software del telefono che il proxy di rete.
Ad esempio, un browser su un dispositivo mobile, dopo aver stabilito una connessione, potrebbe rilevare che si trova su una rete di supporto e richiedere che un server proxy sulla rete si occupi della gestione della connessione. La tempistica per una situazione del genere potrebbe essere la seguente:
- Il browser si connette a un server HTTP remoto e richiede la risorsa specificata dall'autore nel costruttore EventSource.
- Il server invia messaggi occasionali.
- Tra due messaggi, il browser rileva che è inattivo ad eccezione dell'attività di rete coinvolta nel mantenere attiva la connessione TCP e decide di passare alla modalità di sospensione per risparmiare energia.
- Il browser si disconnette dal server.
- Il browser contatta un servizio sulla rete e richiede che il servizio, un "proxy push", mantenga invece la connessione.
- Il servizio "push proxy" contatta il server HTTP remoto e richiede la risorsa specificata dall'autore nel costruttore EventSource (eventualmente includendo un'intestazione HTTP
Last-Event-ID, ecc.). - Il browser consente al dispositivo mobile di andare a dormire.
- Il server invia un altro messaggio.
- Il servizio "push proxy" utilizza una tecnologia come OMA push per trasmettere l'evento al dispositivo mobile, che si sveglia solo quanto basta per elaborare l'evento e quindi torna in modalità di sospensione.
Ciò può ridurre l'utilizzo totale dei dati e, pertanto, può comportare un notevole risparmio energetico.
Oltre a implementare l'API esistente e il formato wire del flusso di testo/eventi come definito dalla specifica e in modi più distribuiti (come descritto sopra), possono essere supportati formati di frame di eventi definiti da altre specifiche applicabili.
Sommario
Dopo lunghi ed esaurienti POC che includono implementazioni di server e client, sembra che SSE sia la risposta ai nostri problemi con la consegna dei dati. Ci sono anche alcune insidie, ma si sono rivelate banali da risolvere.
Ecco come appare alla fine la nostra configurazione di produzione:
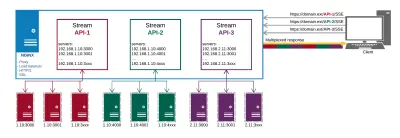
Otteniamo quanto segue da NGINX:
- Proxy agli endpoint API in luoghi diversi;
- HTTP/2 e tutti i suoi vantaggi come il multiplexing per le connessioni;
- Bilancio del carico;
- SSL.
In questo modo gestiamo la consegna dei dati e i certificati in un unico posto invece di farlo su ogni endpoint separatamente.
I principali vantaggi che otteniamo da questo approccio sono:
- Efficienza dei dati;
- Implementazione più semplice;
- Viene automaticamente multiplexato su HTTP/2;
- Limita a uno il numero di connessioni per i dati sul client;
- Fornisce un meccanismo per risparmiare la batteria scaricando la connessione a un proxy.
SSE non è solo una valida alternativa agli altri metodi per fornire aggiornamenti rapidi; sembra che sia in un campionato a sé stante quando si tratta di ottimizzazioni per dispositivi mobili. Non vi è alcun sovraccarico nella sua implementazione rispetto alle alternative. In termini di implementazione lato server, non è molto diverso dal polling. Sul client, è molto più semplice del polling in quanto richiede una sottoscrizione iniziale e l'assegnazione di gestori di eventi, in modo molto simile a come vengono gestiti i WebSocket.
Controlla la demo del codice se desideri ottenere una semplice implementazione client-server.
Risorse
- "Problemi noti e migliori pratiche per l'uso di polling lungo e streaming in HTTP bidirezionale", IETF (PDF)
- Raccomandazione W3C, W3C
- "WebSocket sopravviverà a HTTP/2?", Allan Denis, InfoQ
- "Aggiornamenti in streaming con eventi inviati dal server", Eric Bidelman, HTML5 Rocks
- "App Data Push con HTML5 SSE", Darren Cook, O'Reilly Media