
Condivisione dei dati tra più server tramite AWS S3
Pubblicato: 2022-03-10Quando si forniscono alcune funzionalità per l'elaborazione di un file caricato dall'utente, il file deve essere disponibile per il processo durante l'esecuzione. Una semplice operazione di caricamento e salvataggio non presenta problemi. Tuttavia, se inoltre il file deve essere manipolato prima di essere salvato e l'applicazione è in esecuzione su più server dietro un sistema di bilanciamento del carico, è necessario assicurarsi che il file sia disponibile per qualsiasi server che esegue il processo in ogni momento.
Ad esempio, una funzionalità "Carica il tuo avatar utente" in più passaggi potrebbe richiedere all'utente di caricare un avatar al passaggio 1, ritagliarlo nel passaggio 2 e infine salvarlo nel passaggio 3. Dopo che il file è stato caricato su un server nel passaggio 1, il file deve essere disponibile a qualunque server gestisce la richiesta per i passaggi 2 e 3, che può essere o meno lo stesso per il passaggio 1.
Un approccio ingenuo sarebbe copiare il file caricato nel passaggio 1 su tutti gli altri server, in modo che il file sia disponibile su tutti loro. Tuttavia, questo approccio non è solo estremamente complesso, ma anche irrealizzabile: ad esempio, se il sito funziona su centinaia di server, da diverse regioni, non può essere realizzato.
Una possibile soluzione è abilitare le "sessioni permanenti" sul sistema di bilanciamento del carico, che assegnerà sempre lo stesso server per una determinata sessione. Quindi, i passaggi 1, 2 e 3 verranno gestiti dallo stesso server e il file caricato su questo server al passaggio 1 sarà ancora lì per i passaggi 2 e 3. Tuttavia, le sessioni permanenti non sono completamente affidabili: se tra i passaggi 1 e 2 quel server si è arrestato in modo anomalo, quindi il sistema di bilanciamento del carico dovrà assegnare un server diverso, interrompendo la funzionalità e l'esperienza dell'utente. Allo stesso modo, assegnare sempre lo stesso server per una sessione può, in circostanze speciali, portare a tempi di risposta più lenti da un server sovraccaricato.
Una soluzione più adeguata è conservare una copia del file su un repository accessibile a tutti i server. Quindi, dopo che il file è stato caricato sul server al punto 1, questo server lo caricherà nel repository (o, in alternativa, il file potrebbe essere caricato nel repository direttamente dal client, bypassando il server); il passaggio 2 della gestione del server scaricherà il file dal repository, lo manipolerà e lo caricherà nuovamente; e infine il passaggio 3 di gestione del server lo scaricherà dal repository e lo salverà.
In questo articolo descriverò quest'ultima soluzione, basata su un'applicazione WordPress che archivia i file su Amazon Web Services (AWS) Simple Storage Service (S3) (una soluzione di cloud object storage per archiviare e recuperare dati), che opera tramite l'SDK AWS.
Nota 1: per una funzionalità semplice come il ritaglio degli avatar, un'altra soluzione sarebbe bypassare completamente il server e implementarlo direttamente nel cloud tramite le funzioni Lambda. Ma poiché questo articolo riguarda la connessione di un'applicazione in esecuzione sul server con AWS S3, non prendiamo in considerazione questa soluzione.
Nota 2: per utilizzare AWS S3 (o qualsiasi altro servizio AWS) dovremo disporre di un account utente. Amazon offre un piano gratuito qui per 1 anno, che è abbastanza buono per sperimentare i loro servizi.
Nota 3: sono disponibili plug-in di terze parti per il caricamento di file da WordPress a S3. Uno di questi plug-in è WP Media Offload (la versione lite è disponibile qui), che fornisce un'ottima funzionalità: trasferisce senza problemi i file caricati nella Libreria multimediale a un bucket S3, che consente di disaccoppiare i contenuti del sito (come tutto in /wp-content/uploads) dal codice dell'applicazione. Disaccoppiando contenuto e codice, siamo in grado di distribuire la nostra applicazione WordPress utilizzando Git (altrimenti non possiamo poiché il contenuto caricato dall'utente non è ospitato nel repository Git) e ospitare l'applicazione su più server (altrimenti, ogni server dovrebbe mantenere una copia di tutto il contenuto caricato dall'utente.)
Creazione del secchio
Quando creiamo il bucket, dobbiamo tenere in considerazione il nome del bucket: ogni nome del bucket deve essere univoco a livello globale sulla rete AWS, quindi anche se vorremmo chiamare il nostro bucket qualcosa di semplice come "avatar", quel nome potrebbe essere già stato preso , quindi possiamo scegliere qualcosa di più distintivo come "avatar-nome-della-mia-azienda".
Dovremo anche selezionare la regione in cui si trova il bucket (la regione è la posizione fisica in cui si trova il data center, con sedi in tutto il mondo).
La regione deve essere la stessa in cui viene distribuita la nostra applicazione, in modo che l'accesso a S3 durante l'esecuzione del processo sia rapido. In caso contrario, l'utente potrebbe dover attendere ulteriori secondi prima di caricare/scaricare un'immagine in/da una posizione distante.
Nota: ha senso utilizzare S3 come soluzione di archiviazione di oggetti cloud solo se utilizziamo anche il servizio Amazon per i server virtuali sul cloud, EC2, per l'esecuzione dell'applicazione. Se invece ci affidiamo a qualche altra società per l'hosting dell'applicazione, come Microsoft Azure o DigitalOcean, allora dovremmo utilizzare anche i loro servizi di archiviazione di oggetti cloud. In caso contrario, il nostro sito subirà un sovraccarico dovuto al trasferimento di dati tra le reti di diverse società.
Negli screenshot seguenti vedremo come creare il bucket dove caricare gli avatar degli utenti per il ritaglio. Per prima cosa andiamo alla dashboard di S3 e facciamo clic su "Crea bucket":
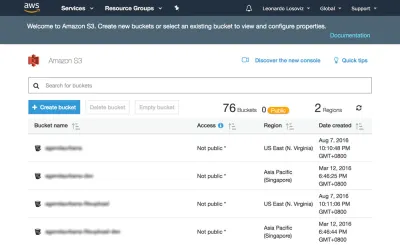
Quindi digitiamo il nome del bucket (in questo caso, "avatars-smashing") e scegliamo la regione ("EU (Francoforte)"):
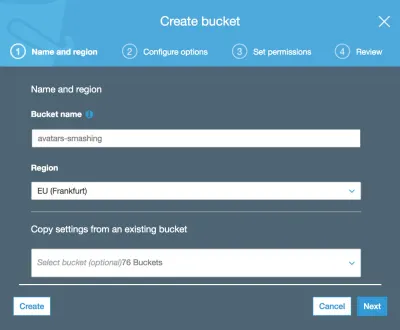
Solo il nome del bucket e la regione sono obbligatori. Per i seguenti passaggi possiamo mantenere le opzioni predefinite, quindi facciamo clic su "Avanti" fino a fare clic su "Crea bucket" e con ciò creeremo il bucket.
Impostazione delle autorizzazioni utente
Quando ci connettiamo ad AWS tramite l'SDK, ci verrà richiesto di inserire le nostre credenziali utente (una coppia di ID chiave di accesso e chiave di accesso segreta), per convalidare di avere accesso ai servizi e agli oggetti richiesti. I permessi dell'utente possono essere molto generali (un ruolo di "amministratore" può fare tutto) o molto granulari, semplicemente concedendo il permesso per le operazioni specifiche necessarie e nient'altro.
Come regola generale, più specifiche sono le autorizzazioni concesse, meglio è per evitare problemi di sicurezza . Quando creiamo il nuovo utente, dovremo creare una policy, che è un semplice documento JSON che elenca le autorizzazioni da concedere all'utente. Nel nostro caso, le nostre autorizzazioni utente garantiranno l'accesso a S3, per il bucket "avatars-smashing", per le operazioni di "Put" (per caricare un oggetto), "Get" (per scaricare un oggetto) e "List" ( per elencare tutti gli oggetti nel bucket), risultando nella seguente politica:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:Put*", "s3:Get*", "s3:List*" ], "Resource": [ "arn:aws:s3:::avatars-smashing", "arn:aws:s3:::avatars-smashing/*" ] } ] }Negli screenshot seguenti, possiamo vedere come aggiungere i permessi utente. Dobbiamo andare alla dashboard di Identity and Access Management (IAM):
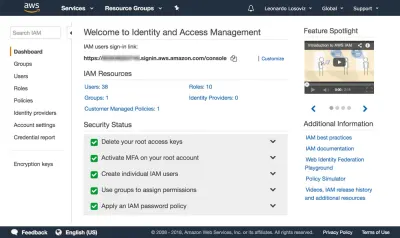
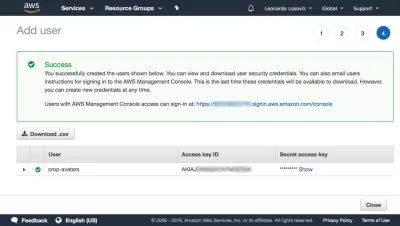
Nella dashboard clicchiamo su “Utenti” e subito dopo su “Aggiungi Utente”. Nella pagina Aggiungi utente, scegliamo un nome utente ("crop-avatars") e selezioniamo "Accesso programmatico" come Tipo di accesso, che fornirà l'ID della chiave di accesso e la chiave di accesso segreta per la connessione tramite l'SDK:
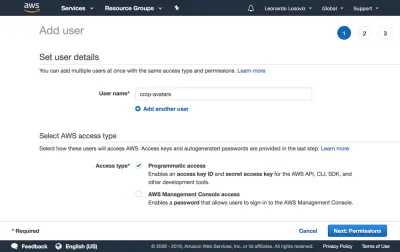
Quindi fare clic sul pulsante "Avanti: Autorizzazioni", fare clic su "Allega direttamente le politiche esistenti" e fare clic su "Crea politica". Si aprirà una nuova scheda nel browser, con la pagina Crea criterio. Facciamo clic sulla scheda JSON e inseriamo il codice JSON per la politica sopra definita:
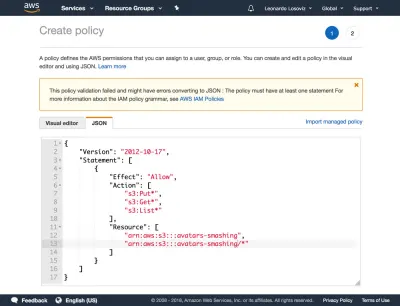
Quindi facciamo clic su Revisiona politica, diamogli un nome ("CropAvatars") e infine clicchiamo su Crea politica. Dopo aver creato la policy, torniamo alla scheda precedente, selezioniamo la policy CropAvatars (potrebbe essere necessario aggiornare l'elenco delle policy per vederla), clicchiamo su Next: Review e infine su Create user. Fatto ciò, possiamo finalmente scaricare l'ID chiave di accesso e la chiave di accesso segreta (si noti che queste credenziali sono disponibili per questo momento unico; se non le copiamo o scarichiamo ora, dovremo creare una nuova coppia ):

Connessione ad AWS tramite l'SDK
L'SDK è disponibile in una miriade di lingue. Per un'applicazione WordPress, abbiamo bisogno dell'SDK per PHP che può essere scaricato da qui e le istruzioni su come installarlo sono qui.
Una volta creato il bucket, pronte le credenziali utente e installato l'SDK, possiamo iniziare a caricare i file su S3.
Caricamento e download di file
Per comodità, definiamo le credenziali dell'utente e la regione come costanti nel file wp-config.php:
define ('AWS_ACCESS_KEY_ID', '...'); // Your access key id define ('AWS_SECRET_ACCESS_KEY', '...'); // Your secret access key define ('AWS_REGION', 'eu-central-1'); // Region where the bucket is located. This is the region id for "EU (Frankfurt)" Nel nostro caso, stiamo implementando la funzionalità di ritaglio avatar, per la quale gli avatar verranno archiviati nel bucket "distruggi avatar". Tuttavia, nella nostra applicazione potremmo avere molti altri bucket per altre funzionalità, che richiedono di eseguire le stesse operazioni di caricamento, scaricamento ed elenco dei file. Quindi, implementiamo i metodi comuni su una classe astratta AWS_S3 e otteniamo gli input, come il nome del bucket definito tramite la funzione get_bucket , nelle classi figlio di implementazione.
// Load the SDK and import the AWS objects require 'vendor/autoload.php'; use Aws\S3\S3Client; use Aws\Exception\AwsException; // Definition of an abstract class abstract class AWS_S3 { protected function get_bucket() { // The bucket name will be implemented by the child class return ''; } } La classe S3Client espone l'API per l'interazione con S3. Lo istanziamo solo quando necessario (attraverso l'inizializzazione lazy) e salviamo un riferimento ad esso in $this->s3Client per continuare a utilizzare la stessa istanza:
abstract class AWS_S3 { // Continued from above... protected $s3Client; protected function get_s3_client() { // Lazy initialization if (!$this->s3Client) { // Create an S3Client. Provide the credentials and region as defined through constants in wp-config.php $this->s3Client = new S3Client([ 'version' => '2006-03-01', 'region' => AWS_REGION, 'credentials' => [ 'key' => AWS_ACCESS_KEY_ID, 'secret' => AWS_SECRET_ACCESS_KEY, ], ]); } return $this->s3Client; } } Quando abbiamo a che fare con $file nella nostra applicazione, questa variabile contiene il percorso assoluto del file nel disco (es. /var/app/current/wp-content/uploads/users/654/leo.jpg ), ma quando carichiamo il file su S3 non dovremmo memorizzare l'oggetto nello stesso percorso. In particolare, per motivi di sicurezza, dobbiamo rimuovere il bit iniziale relativo alle informazioni di sistema ( /var/app/current ) e opzionalmente possiamo rimuovere il bit /wp-content (poiché tutti i file sono archiviati in questa cartella, si tratta di informazioni ridondanti ), mantenendo solo il percorso relativo al file ( /uploads/users/654/leo.jpg ). Convenientemente, questo può essere ottenuto rimuovendo tutto dopo WP_CONTENT_DIR dal percorso assoluto. Le funzioni get_file e get_file_relative_path sottostanti alternano tra i percorsi dei file assoluti e relativi:
abstract class AWS_S3 { // Continued from above... function get_file_relative_path($file) { return substr($file, strlen(WP_CONTENT_DIR)); } function get_file($file_relative_path) { return WP_CONTENT_DIR.$file_relative_path; } }Quando carichiamo un oggetto su S3, possiamo stabilire a chi è concesso l'accesso all'oggetto e il tipo di accesso, effettuato tramite le autorizzazioni dell'elenco di controllo di accesso (ACL). Le opzioni più comuni sono mantenere il file privato (ACL => "privato") e renderlo accessibile per la lettura su Internet (ACL => "lettura pubblica"). Poiché dovremo richiedere il file direttamente da S3 per mostrarlo all'utente, abbiamo bisogno di ACL => "lettura pubblica":
abstract class AWS_S3 { // Continued from above... protected function get_acl() { return 'public-read'; } }Infine, implementiamo i metodi per caricare un oggetto e scaricare un oggetto dal bucket S3:
abstract class AWS_S3 { // Continued from above... function upload($file) { $s3Client = $this->get_s3_client(); // Upload a file object to S3 $s3Client->putObject([ 'ACL' => $this->get_acl(), 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SourceFile' => $file, ]); } function download($file) { $s3Client = $this->get_s3_client(); // Download a file object from S3 $s3Client->getObject([ 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SaveAs' => $file, ]); } }Quindi, nella classe figlio di implementazione definiamo il nome del bucket:
class AvatarCropper_AWS_S3 extends AWS_S3 { protected function get_bucket() { return 'avatars-smashing'; } } Infine, istanziamo semplicemente la classe per caricare gli avatar o scaricarli da S3. Inoltre, quando si passa dai passaggi da 1 a 2 e da 2 a 3, è necessario comunicare il valore di $file . Possiamo farlo inviando un campo “file_relative_path” con il valore del percorso relativo di $file tramite un'operazione POST (non passiamo il percorso assoluto per motivi di sicurezza: non c'è bisogno di includere “/var/www/current ” informazioni che gli estranei possono vedere):
// Step 1: after the file was uploaded to the server, upload it to S3. Here, $file is known $avatarcropper = new AvatarCropper_AWS_S3(); $avatarcropper->upload($file); // Get the file path, and send it to the next step in the POST $file_relative_path = $avatarcropper->get_file_relative_path($file); // ... // -------------------------------------------------- // Step 2: get the $file from the request and download it, manipulate it, and upload it again $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_POST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Do manipulation of the file // ... // Upload the file again to S3 $avatarcropper->upload($file); // -------------------------------------------------- // Step 3: get the $file from the request and download it, and then save it $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_REQUEST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Save it, whatever that means // ...Visualizzazione del file direttamente da S3
Se vogliamo visualizzare lo stato intermedio del file dopo la manipolazione al punto 2 (es. l'avatar dell'utente dopo essere stato ritagliato), allora dobbiamo fare riferimento al file direttamente da S3; l'URL non può puntare al file sul server poiché, ancora una volta, non sappiamo quale server gestirà quella richiesta.
Di seguito, aggiungiamo la funzione get_file_url($file) che ottiene l'URL per quel file in S3. Se si utilizza questa funzione, assicurarsi che l'ACL dei file caricati sia di "lettura pubblica", altrimenti non sarà accessibile all'utente.
abstract class AWS_S3 { // Continue from above... protected function get_bucket_url() { $region = $this->get_region(); // North Virginia region is simply "s3", the others require the region explicitly $prefix = $region == 'us-east-1' ? 's3' : 's3-'.$region; // Use the same scheme as the current request $scheme = is_ssl() ? 'https' : 'http'; // Using the bucket name in path scheme return $scheme.'://'.$prefix.'.amazonaws.com/'.$this->get_bucket(); } function get_file_url($file) { return $this->get_bucket_url().$this->get_file_relative_path($file); } }Quindi, possiamo semplicemente ottenere l'URL del file su S3 e stampare l'immagine:
printf( "<img src='%s'>", $avatarcropper->get_file_url($file) );Elenco dei file
Se nella nostra applicazione vogliamo consentire all'utente di visualizzare tutti gli avatar caricati in precedenza, possiamo farlo. Per questo, introduciamo la funzione get_file_urls che elenca l'URL per tutti i file archiviati in un determinato percorso (in termini S3, si chiama prefisso):
abstract class AWS_S3 { // Continue from above... function get_file_urls($prefix) { $s3Client = $this->get_s3_client(); $result = $s3Client->listObjects(array( 'Bucket' => $this->get_bucket(), 'Prefix' => $prefix )); $file_urls = array(); if(isset($result['Contents']) && count($result['Contents']) > 0 ) { foreach ($result['Contents'] as $obj) { // Check that Key is a full file path and not just a "directory" if ($obj['Key'] != $prefix) { $file_urls[] = $this->get_bucket_url().$obj['Key']; } } } return $file_urls; } }Quindi, se stiamo memorizzando ogni avatar nel percorso "/users/${user_id}/", passando questo prefisso otterremo l'elenco di tutti i file:
$user_id = get_current_user_id(); $prefix = "/users/${user_id}/"; foreach ($avatarcropper->get_file_urls($prefix) as $file_url) { printf( "<img src='%s'>", $file_url ); }Conclusione
In questo articolo, abbiamo esplorato come utilizzare una soluzione di archiviazione di oggetti cloud che funga da repository comune per archiviare i file per un'applicazione distribuita su più server. Per la soluzione, ci siamo concentrati su AWS S3 e abbiamo provveduto a mostrare i passaggi necessari per essere integrati nell'applicazione: creazione del bucket, configurazione delle autorizzazioni utente e download e installazione dell'SDK. Infine, abbiamo spiegato come evitare insidie di sicurezza nell'applicazione e abbiamo visto esempi di codice che dimostrano come eseguire le operazioni più basilari su S3: caricare, scaricare ed elencare i file, che richiedevano a malapena poche righe di codice ciascuno. La semplicità della soluzione mostra che l'integrazione dei servizi cloud nell'applicazione non è difficile e può essere realizzata anche da sviluppatori che non hanno molta esperienza con il cloud.