
Come creare un editor di sintesi vocale
Pubblicato: 2022-03-10Quando Steve Jobs ha presentato il Macintosh nel 1984, ci ha detto "Ciao" dal palco. Anche a quel punto, la sintesi vocale non era davvero una nuova tecnologia: Bell Labs ha sviluppato il vocoder già alla fine degli anni '30 e il concetto di un computer con assistente vocale è diventato consapevole della gente quando Stanley Kubrick ha reso il vocoder la voce di HAL9000 nel 2001: Odissea nello spazio (1968).
Non è stato prima dell'introduzione di Siri, Amazon Echo e Google Assistant di Apple a metà degli anni 2015 che le interfacce vocali hanno effettivamente trovato la loro strada nelle case, nei polsi e nelle tasche di un pubblico più ampio. Siamo ancora in una fase di adozione, ma sembra che questi assistenti vocali siano qui per restare.
In altre parole, il web non è più solo testo passivo su uno schermo . Gli editor Web e i designer UX devono abituarsi a creare contenuti e servizi che dovrebbero essere pronunciati ad alta voce.
Ci stiamo già muovendo rapidamente verso l'utilizzo di sistemi di gestione dei contenuti che ci consentono di lavorare con i nostri contenuti senza testa e tramite API. L'ultimo pezzo è creare interfacce editoriali che semplifichino la personalizzazione dei contenuti per la voce. Quindi facciamo proprio questo!
Cos'è SSML
Mentre i browser Web utilizzano le specifiche del W3C per HyperText Markup Language (HTML) per eseguire il rendering visivo dei documenti, la maggior parte degli assistenti vocali utilizza Speech Synthesis Markup Language (SSML) durante la generazione del parlato.
Un esempio minimo che utilizza l'elemento radice <speak> e i tag paragrafo ( <p> ) e frase ( <s> ):
<speak> <p> <s>This is the first sentence of the paragraph.</s> <s>Here's another sentence.</s> </p> </speak> Il punto in cui SSML diventa esistente è quando introduciamo i tag per <emphasis> e <prosody> (pitch):
<speak> <p> <s>Put some <emphasis strength="strong">extra weight on these words</emphasis></s> <s>And say <prosody pitch="high" rate="fast">this a bit higher and faster</prosody>!</s> </p> </speak>SSML ha più funzionalità, ma questo è sufficiente per avere un'idea delle basi. Ora, diamo un'occhiata più da vicino all'editor che useremo per creare l'interfaccia di modifica della sintesi vocale.
L'editor per il testo portatile
Per creare questo editor, utilizzeremo l'editor per Portable Text presente in Sanity.io. Portable Text è una specifica JSON per la modifica del testo RTF, che può essere serializzata in qualsiasi linguaggio di markup, come SSML. Ciò significa che puoi facilmente utilizzare lo stesso snippet di testo in più posizioni utilizzando linguaggi di markup diversi.

Installazione della sanità mentale
Sanity.io è una piattaforma per contenuti strutturati fornita con un ambiente di editing open source creato con React.js. Ci vogliono due minuti per far funzionare tutto.
Digita npm i -g @sanity/cli && sanity init nel tuo terminale e segui le istruzioni. Scegli "vuoto", quando ti viene richiesto un modello di progetto.
Se non vuoi seguire questo tutorial e creare questo editor da zero, puoi anche clonare il codice di questo tutorial e seguire le istruzioni in README.md .
Quando l'editor viene scaricato, esegui sanity start nella cartella del progetto per avviarlo. Avvierà un server di sviluppo che utilizza il ricaricamento dei moduli a caldo per aggiornare le modifiche mentre modifichi i suoi file.
Come configurare gli schemi in Sanity Studio
Creazione dei file dell'editor
Inizieremo creando una cartella chiamata ssml-editor nella cartella /schemas . In quella cartella, metteremo alcuni file vuoti:
/ssml-tutorial/schemas/ssml-editor ├── alias.js ├── emphasis.js ├── annotations.js ├── preview.js ├── prosody.js ├── sayAs.js ├── blocksToSSML.js ├── speech.js ├── SSMLeditor.css └── SSMLeditor.js Ora possiamo aggiungere schemi di contenuto in questi file. Gli schemi di contenuto sono ciò che definisce la struttura dei dati per il rich text e ciò che Sanity Studio utilizza per generare l'interfaccia editoriale. Sono semplici oggetti JavaScript che richiedono principalmente solo un name e un type .
Possiamo anche aggiungere un title e una description per rendere un po' più piacevoli gli editori. Ad esempio, questo è uno schema per un semplice campo di testo per un title :
export default { name: 'title', type: 'string', title: 'Title', description: 'Titles should be short and descriptive' } 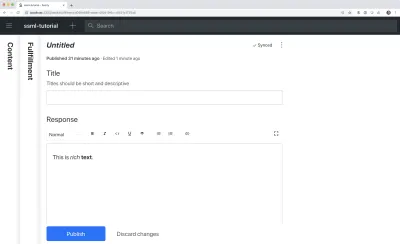
Portable Text si basa sull'idea di rich text come dati. Questo è potente perché ti consente di interrogare il tuo testo RTF e di convertirlo praticamente in qualsiasi markup tu voglia.
È una serie di oggetti chiamati "blocchi" che puoi considerare come "paragrafi". In un blocco c'è una serie di intervalli figli. Ciascun blocco può avere uno stile e un insieme di definizioni di contrassegno, che descrivono le strutture dati distribuite sugli intervalli figli.
Sanity.io viene fornito con un editor in grado di leggere e scrivere su Portable Text e si attiva inserendo il tipo di block all'interno di un campo array , come questo:
// speech.js export default { name: 'speech', type: 'array', title: 'SSML Editor', of: [ { type: 'block' } ] }Un array può essere di più tipi. Per un editor SSML, quelli potrebbero essere blocchi per file audio, ma ciò non rientra nell'ambito di questo tutorial.
L'ultima cosa che vogliamo fare è aggiungere un tipo di contenuto in cui è possibile utilizzare questo editor. La maggior parte degli assistenti utilizza un semplice modello di contenuto di "intenti" e "realizzazioni":
- Intenzioni
Di solito un elenco di stringhe utilizzate dal modello AI per delineare ciò che l'utente vuole fare. - Adempimenti
Questo accade quando viene identificato un "intento". Un appagamento spesso è, o almeno, arriva con una sorta di risposta.
Quindi creiamo un semplice tipo di contenuto chiamato fulfillment che utilizza l'editor di sintesi vocale. Crea un nuovo file chiamato adempimento.js e salvalo nella cartella /schema :
// fulfillment.js export default { name: 'fulfillment', type: 'document', title: 'Fulfillment', of: [ { name: 'title', type: 'string', title: 'Title', description: 'Titles should be short and descriptive' }, { name: 'response', type: 'speech' } ] }Salva il file e apri schema.js . Aggiungilo al tuo studio in questo modo:
// schema.js import createSchema from 'part:@sanity/base/schema-creator' import schemaTypes from 'all:part:@sanity/base/schema-type' import fullfillment from './fullfillment' import speech from './speech' export default createSchema({ name: 'default', types: schemaTypes.concat([ fullfillment, speech, ]) }) Se ora esegui sanity start nella tua interfaccia della riga di comando all'interno della cartella principale del progetto, lo studio si avvierà localmente e sarai in grado di aggiungere voci per gli adempimenti. Puoi mantenere lo studio in funzione mentre andiamo avanti, poiché si ricaricherà automaticamente con nuove modifiche quando salvi i file.
Aggiunta di SSML all'editor
Per impostazione predefinita, il tipo di block ti fornirà un editor standard per il testo RTF con orientamento visivo con stili di intestazione, stili decoratore per enfasi e forte, annotazioni per collegamenti ed elenchi. Ora vogliamo sovrascrivere quelli con i concetti auditivi trovati in SSML.
Iniziamo con la definizione delle diverse strutture di contenuto, con descrizioni utili per gli editor, che aggiungeremo al block in SSMLeditorSchema.js come configurazioni per le annotations . Quelli sono "enfasi", "alias", "prosodia" e "dire come".
Enfasi
Iniziamo con "enfasi", che controlla quanto peso viene attribuito al testo contrassegnato. La definiamo come una stringa con un elenco di valori predefiniti tra cui l'utente può scegliere:
// emphasis.js export default { name: 'emphasis', type: 'object', title: 'Emphasis', description: 'The strength of the emphasis put on the contained text', fields: [ { name: 'level', type: 'string', options: { list: [ { value: 'strong', title: 'Strong' }, { value: 'moderate', title: 'Moderate' }, { value: 'none', title: 'None' }, { value: 'reduced', title: 'Reduced' } ] } } ] }Alias
A volte il termine scritto e quello parlato differiscono. Ad esempio, si desidera utilizzare l'abbreviazione di una frase in un testo scritto, ma far leggere l'intera frase ad alta voce. Per esempio:
<s>This is a <sub alias="Speech Synthesis Markup Language">SSML</sub> tutorial</s>Il campo di input per l'alias è una semplice stringa:
// alias.js export default { name: 'alias', type: 'object', title: 'Alias (sub)', description: 'Replaces the contained text for pronunciation. This allows a document to contain both a spoken and written form.', fields: [ { name: 'text', type: 'string', title: 'Replacement text', } ] }Prosodia
Con la proprietà della prosodia possiamo controllare diversi aspetti di come deve essere pronunciato il testo, come tono, frequenza e volume. Il markup per questo può assomigliare a questo:
<s>Say this with an <prosody pitch="x-low">extra low pitch</prosody>, and this <prosody rate="fast" volume="loud">loudly with a fast rate</prosody></s>Questo input avrà tre campi con opzioni di stringa predefinite:
// prosody.js export default { name: 'prosody', type: 'object', title: 'Prosody', description: 'Control of the pitch, speaking rate, and volume', fields: [ { name: 'pitch', type: 'string', title: 'Pitch', description: 'The baseline pitch for the contained text', options: { list: [ { value: 'x-low', title: 'Extra low' }, { value: 'low', title: 'Low' }, { value: 'medium', title: 'Medium' }, { value: 'high', title: 'High' }, { value: 'x-high', title: 'Extra high' }, { value: 'default', title: 'Default' } ] } }, { name: 'rate', type: 'string', title: 'Rate', description: 'A change in the speaking rate for the contained text', options: { list: [ { value: 'x-slow', title: 'Extra slow' }, { value: 'slow', title: 'Slow' }, { value: 'medium', title: 'Medium' }, { value: 'fast', title: 'Fast' }, { value: 'x-fast', title: 'Extra fast' }, { value: 'default', title: 'Default' } ] } }, { name: 'volume', type: 'string', title: 'Volume', description: 'The volume for the contained text.', options: { list: [ { value: 'silent', title: 'Silent' }, { value: 'x-soft', title: 'Extra soft' }, { value: 'medium', title: 'Medium' }, { value: 'loud', title: 'Loud' }, { value: 'x-loud', title: 'Extra loud' }, { value: 'default', title: 'Default' } ] } } ] }Dì come
L'ultimo che vogliamo includere è <say-as> . Questo tag ci consente di esercitare un po' più di controllo su come vengono pronunciate determinate informazioni. Possiamo anche usarlo per cancellare le parole se hai bisogno di redigere qualcosa nelle interfacce vocali. Questo è @!%& utile!
<s>Do I have to <say-as interpret-as="expletive">frakking</say-as> <say-as interpret-as="verbatim">spell</say-as> it out for you!?</s> // sayAs.js export default { name: 'sayAs', type: 'object', title: 'Say as...', description: 'Lets you indicate information about the type of text construct that is contained within the element. It also helps specify the level of detail for rendering the contained text.', fields: [ { name: 'interpretAs', type: 'string', title: 'Interpret as...', options: { list: [ { value: 'cardinal', title: 'Cardinal numbers' }, { value: 'ordinal', title: 'Ordinal numbers (1st, 2nd, 3th...)' }, { value: 'characters', title: 'Spell out characters' }, { value: 'fraction', title: 'Say numbers as fractions' }, { value: 'expletive', title: 'Blip out this word' }, { value: 'unit', title: 'Adapt unit to singular or plural' }, { value: 'verbatim', title: 'Spell out letter by letter (verbatim)' }, { value: 'date', title: 'Say as a date' }, { value: 'telephone', title: 'Say as a telephone number' } ] } }, { name: 'date', type: 'object', title: 'Date', fields: [ { name: 'format', type: 'string', description: 'The format attribute is a sequence of date field character codes. Supported field character codes in format are {y, m, d} for year, month, and day (of the month) respectively. If the field code appears once for year, month, or day then the number of digits expected are 4, 2, and 2 respectively. If the field code is repeated then the number of expected digits is the number of times the code is repeated. Fields in the date text may be separated by punctuation and/or spaces.' }, { name: 'detail', type: 'number', validation: Rule => Rule.required() .min(0) .max(2), description: 'The detail attribute controls the spoken form of the date. For detail='1' only the day fields and one of month or year fields are required, although both may be supplied' } ] } ] }Ora possiamo importarli in un file annotations.js , il che rende le cose un po' più ordinate.

// annotations.js export {default as alias} from './alias' export {default as emphasis} from './emphasis' export {default as prosody} from './prosody' export {default as sayAs} from './sayAs'Ora possiamo importare questi tipi di annotazioni nei nostri schemi principali:
// schema.js import createSchema from "part:@sanity/base/schema-creator" import schemaTypes from "all:part:@sanity/base/schema-type" import fulfillment from './fulfillment' import speech from './ssml-editor/speech' import { alias, emphasis, prosody, sayAs } from './annotations' export default createSchema({ name: "default", types: schemaTypes.concat([ fulfillment, speech, alias, emphasis, prosody, sayAs ]) })Infine, ora possiamo aggiungerli all'editor in questo modo:
// speech.js export default { name: 'speech', type: 'array', title: 'SSML Editor', of: [ { type: 'block', styles: [], lists: [], marks: { decorators: [], annotations: [ {type: 'alias'}, {type: 'emphasis'}, {type: 'prosody'}, {type: 'sayAs'} ] } } ] } Si noti che abbiamo anche aggiunto array vuoti a styles e decorators . Ciò disabilita gli stili e i decoratori predefiniti (come grassetto ed enfasi) poiché non hanno molto senso in questo caso specifico.
Personalizzazione dell'aspetto e della sensazione
Ora abbiamo la funzionalità in atto, ma poiché non abbiamo specificato alcuna icona, ogni annotazione utilizzerà l'icona predefinita, il che rende difficile l'utilizzo dell'editor per gli autori. Quindi sistemiamolo!
Con l'editor per Portable Text è possibile iniettare componenti React sia per le icone che per come deve essere renderizzato il testo contrassegnato. Qui, lasceremo che alcune emoji facciano il lavoro per noi, ma ovviamente potresti andare lontano con questo, rendendole dinamiche e così via. Per la prosody faremo anche cambiare l'icona a seconda del volume selezionato. Nota che ho omesso i campi in questi frammenti per brevità, non dovresti rimuoverli nei tuoi file locali.
// alias.js import React from 'react' export default { name: 'alias', type: 'object', title: 'Alias (sub)', description: 'Replaces the contained text for pronunciation. This allows a document to contain both a spoken and written form.', fields: [ /* all the fields */ ], blockEditor: { icon: () => '', render: ({ children }) => <span>{children} </span>, }, }; // emphasis.js import React from 'react' export default { name: 'emphasis', type: 'object', title: 'Emphasis', description: 'The strength of the emphasis put on the contained text', fields: [ /* all the fields */ ], blockEditor: { icon: () => '', render: ({ children }) => <span>{children} </span>, }, }; // prosody.js import React from 'react' export default { name: 'prosody', type: 'object', title: 'Prosody', description: 'Control of the pitch, speaking rate, and volume', fields: [ /* all the fields */ ], blockEditor: { icon: () => '', render: ({ children, volume }) => ( <span> {children} {['x-loud', 'loud'].includes(volume) ? '' : ''} </span> ), }, }; // sayAs.js import React from 'react' export default { name: 'sayAs', type: 'object', title: 'Say as...', description: 'Lets you indicate information about the type of text construct that is contained within the element. It also helps specify the level of detail for rendering the contained text.', fields: [ /* all the fields */ ], blockEditor: { icon: () => '', render: props => <span>{props.children} </span>, }, }; 
Ora hai un editor per la modifica del testo che può essere utilizzato dagli assistenti vocali. Ma non sarebbe utile se anche gli editor potessero visualizzare in anteprima come suonerà effettivamente il testo?
Aggiunta di un pulsante di anteprima utilizzando la sintesi vocale di Google
Il supporto per la sintesi vocale nativa è attualmente in arrivo per i browser. Ma in questo tutorial utilizzeremo l'API di sintesi vocale di Google che supporta SSML. La creazione di questa funzionalità di anteprima sarà anche una dimostrazione di come serializzi Portable Text in SSML in qualsiasi servizio tu voglia utilizzarlo.
Avvolgimento dell'editor in un componente React
Iniziamo con l'apertura del file SSMLeditor.js e aggiungiamo il seguente codice:
// SSMLeditor.js import React, { Fragment } from 'react'; import { BlockEditor } from 'part:@sanity/form-builder'; export default function SSMLeditor(props) { return ( <Fragment> <BlockEditor {...props} /> </Fragment> ); } Ora abbiamo avvolto l'editor nel nostro componente React. Tutti gli oggetti di scena di cui ha bisogno, compresi i dati che contiene, vengono trasmessi in tempo reale. Per utilizzare effettivamente questo componente, devi importarlo nel tuo file speech.js :
// speech.js import React from 'react' import SSMLeditor from './SSMLeditor.js' export default { name: 'speech', type: 'array', title: 'SSML Editor', inputComponent: SSMLeditor, of: [ { type: 'block', styles: [], lists: [], marks: { decorators: [], annotations: [ { type: 'alias' }, { type: 'emphasis' }, { type: 'prosody' }, { type: 'sayAs' }, ], }, }, ], }Quando lo salvi e lo studio si ricarica, dovrebbe sembrare più o meno esattamente lo stesso, ma è perché non abbiamo ancora iniziato a modificare l'editor.
Converti testo portatile in SSML
L'editor salverà il contenuto come Portable Text, una matrice di oggetti in JSON che semplifica la conversione di rich text in qualsiasi formato tu voglia. Quando converti Portable Text in un'altra sintassi o formato, la chiamiamo "serializzazione". Quindi, i "serializzatori" sono le ricette su come convertire il rich text. In questa sezione verranno aggiunti serializzatori per la sintesi vocale.
Hai già creato il file blocksToSSML.js . Ora dovremo aggiungere la nostra prima dipendenza. Inizia eseguendo il comando del terminale npm init -y all'interno della cartella ssml-editor . Questo aggiungerà un package.json in cui verranno elencate le dipendenze dell'editor.
Una volta fatto, puoi eseguire npm install @sanity/block-content-to-html per ottenere una libreria che semplifichi la serializzazione di Portable Text. Stiamo usando la libreria HTML perché SSML ha la stessa sintassi XML con tag e attributi.
Questo è un mucchio di codice, quindi sentiti libero di copiarlo e incollarlo. Spiegherò lo schema proprio sotto lo snippet:
// blocksToSSML.js import blocksToHTML, { h } from '@sanity/block-content-to-html' const serializers = { marks: { prosody: ({ children, mark: { rate, pitch, volume } }) => h('prosody', { attrs: { rate, pitch, volume } }, children), alias: ({ children, mark: { text } }) => h('sub', { attrs: { alias: text } }, children), sayAs: ({ children, mark: { interpretAs } }) => h('say-as', { attrs: { 'interpret-as': interpretAs } }, children), break: ({ children, mark: { time, strength } }) => h('break', { attrs: { time: '${time}ms', strength } }, children), emphasis: ({ children, mark: { level } }) => h('emphasis', { attrs: { level } }, children) } } export const blocksToSSML = blocks => blocksToHTML({ blocks, serializers }) Questo codice esporterà una funzione che prende l'array di blocchi e li scorre. Ogni volta che un blocco contiene un mark , cercherà un serializzatore per il tipo. Se hai contrassegnato del testo per avere emphasis , questa funzione dall'oggetto serializzatori:
emphasis: ({ children, mark: { level } }) => h('emphasis', { attrs: { level } }, children) Forse riconosci il parametro da cui abbiamo definito lo schema? La funzione h() ci permette di definire un elemento HTML, cioè qui "imbrogliamo" e gli fa restituire un elemento SSML chiamato <emphasis> . Gli diamo anche il level di attributo, se definito, e collochiamo gli elementi children al suo interno, che nella maggior parte dei casi sarà il testo che hai contrassegnato con emphasis .
{ "_type": "block", "_key": "f2c4cf1ab4e0", "style": "normal", "markDefs": [ { "_type": "emphasis", "_key": "99b28ed3fa58", "level": "strong" } ], "children": [ { "_type": "span", "_key": "f2c4cf1ab4e01", "text": "Say this strongly!", "marks": [ "99b28ed3fa58" ] } ] }Ecco come la struttura sopra in Portable Text viene serializzata su questo SSML:
<emphasis level="strong">Say this strongly</emphasis> Se desideri il supporto per più tag SSML, puoi aggiungere più annotazioni nello schema e aggiungere i tipi di annotazione alla sezione dei marks nei serializzatori.
Ora abbiamo una funzione che restituisce il markup SSML dal nostro testo RTF contrassegnato. L'ultima parte consiste nel creare un pulsante che ci consenta di inviare questo markup a un servizio di sintesi vocale.
Aggiunta di un pulsante di anteprima che ti risponde
Idealmente, avremmo dovuto utilizzare le capacità di sintesi vocale del browser nell'API Web. In questo modo, saremmo riusciti a farla franca con meno codice e dipendenze.
All'inizio del 2019, tuttavia, il supporto del browser nativo per la sintesi vocale è ancora nelle sue fasi iniziali. Sembra che il supporto per SSML sia in arrivo e ci sono prove di concetti di implementazioni JavaScript lato client per esso.
È probabile che utilizzerai comunque questo contenuto con un assistente vocale. Sia Google Assistant che Amazon Echo (Alexa) supportano SSML come risposte in un adempimento. In questo tutorial, utilizzeremo l'API di sintesi vocale di Google, che suona anche bene e supporta diverse lingue.
Inizia ottenendo una chiave API iscrivendoti a Google Cloud Platform (sarà gratuito per il primo milione di caratteri che elabori). Dopo esserti registrato, puoi creare una nuova chiave API in questa pagina.
Ora puoi aprire il tuo file PreviewButton.js e aggiungervi questo codice:
// PreviewButton.js import React from 'react' import Button from 'part:@sanity/components/buttons/default' import { blocksToSSML } from './blocksToSSML' // You should be careful with sharing this key // I put it here to keep the code simple const API_KEY = '<yourAPIkey>' const GOOGLE_TEXT_TO_SPEECH_URL = 'https://texttospeech.googleapis.com/v1beta1/text:synthesize?key=' + API_KEY const speak = async blocks => { // Serialize blocks to SSML const ssml = blocksToSSML(blocks) // Prepare the Google Text-to-Speech configuration const body = JSON.stringify({ input: { ssml }, // Select the language code and voice name (AF) voice: { languageCode: 'en-US', name: 'en-US-Wavenet-A' }, // Use MP3 in order to play in browser audioConfig: { audioEncoding: 'MP3' } }) // Send the SSML string to the API const res = await fetch(GOOGLE_TEXT_TO_SPEECH_URL, { method: 'POST', body }).then(res => res.json()) // Play the returned audio with the Browser's Audo API const audio = new Audio('data:audio/wav;base64,' + res.audioContent) audio.play() } export default function PreviewButton (props) { return <Button style={{ marginTop: '1em' }} onClick={() => speak(props.blocks)}>Speak text</Button> }Ho ridotto al minimo il codice del pulsante di anteprima per rendere più facile seguire questo tutorial. Ovviamente, puoi costruirlo aggiungendo lo stato per mostrare se l'anteprima è in elaborazione o rendere possibile l'anteprima con le diverse voci supportate dall'API di Google.
Aggiungi il pulsante a SSMLeditor.js :
// SSMLeditor.js import React, { Fragment } from 'react'; import { BlockEditor } from 'part:@sanity/form-builder'; import PreviewButton from './PreviewButton'; export default function SSMLeditor(props) { return ( <Fragment> <BlockEditor {...props} /> <PreviewButton blocks={props.value} /> </Fragment> ); }Ora dovresti essere in grado di contrassegnare il tuo testo con le diverse annotazioni e ascoltare il risultato quando premi "Pronuncia testo". Fantastico, vero?
Hai creato un editor di sintesi vocale e adesso?
Se hai seguito questo tutorial, hai spiegato come utilizzare l'editor per Portable Text in Sanity Studio per creare annotazioni personalizzate e personalizzare l'editor. Puoi usare queste abilità per ogni genere di cose, non solo per creare un editor di sintesi vocale. Hai anche spiegato come serializzare Portable Text nella sintassi di cui hai bisogno. Ovviamente, questo è utile anche se stai costruendo frontend in React o Vue. Puoi anche usare queste abilità per generare Markdown da Portable Text.
Non abbiamo spiegato come lo usi effettivamente insieme a un assistente vocale. Se vuoi provare, puoi utilizzare gran parte della stessa logica del pulsante di anteprima in una funzione serverless e impostarlo come endpoint API per un evasione utilizzando webhook, ad esempio con Dialogflow.
Se desideri che scriva un tutorial su come utilizzare l'editor di sintesi vocale con un assistente vocale, sentiti libero di darmi un suggerimento su Twitter o condividi nella sezione commenti qui sotto.
Ulteriori letture su SmashingMag:
- Sperimentazione con sintesi vocale
- Miglioramento dell'esperienza utente con l'API Web Speech
- API di accessibilità: una chiave per l'accessibilità al Web
- Costruire un semplice chatbot AI con l'API Web Speech e Node.js