
Strumenti di dati quantitativi per UX Designer
Pubblicato: 2022-03-10Molti designer di UX hanno un po' paura dei dati, ritenendo che richiedano una profonda conoscenza della statistica e della matematica. Sebbene ciò possa essere vero per la scienza dei dati avanzata, non è vero per l'analisi dei dati di ricerca di base richiesta dalla maggior parte dei designer di UX. Dal momento che viviamo in un mondo sempre più guidato dai dati, l'alfabetizzazione dei dati di base è utile per quasi tutti i professionisti, non solo per i designer di UX.
Aaron Gitlin, interaction designer di Google, sostiene che molti designer non sono ancora basati sui dati:
"Mentre molte aziende si promuovono come basate sui dati, la maggior parte dei designer è guidata dall'istinto, dalla collaborazione e dai metodi di ricerca qualitativa".
— Aaron Gitlin, "Diventare un designer consapevole dei dati"
Con questo articolo, vorrei fornire ai designer di UX le conoscenze e gli strumenti per incorporare i dati nelle loro routine quotidiane.
Ma prima, alcuni concetti di dati
In questo articolo parlerò di dati strutturati, ovvero dati che possono essere rappresentati in una tabella, con righe e colonne. I dati non strutturati, essendo un argomento in sé, sono più difficili da analizzare, come ha sottolineato Devin Pickell (specialista di content marketing presso G2 Crowd, che scrive di dati e analisi) nel suo articolo "Dati strutturati vs non strutturati: qual è la differenza?". Se i dati strutturati possono essere rappresentati in forma tabellare, i concetti principali sono:
Set di dati
L'intero insieme di dati che intendiamo analizzare. Potrebbe trattarsi, ad esempio, di una tabella di Excel. Un altro formato popolare per l'archiviazione dei set di dati è il file CSV (comma-separated value file). I file CSV sono semplici file di testo utilizzati per memorizzare informazioni simili a tabelle. Ogni riga CSV corrisponde a una riga nella tabella e ogni riga CSV ha valori separati (naturalmente) da virgole, che corrispondono alle celle della tabella.
Punto dati
Una singola riga di una tabella di set di dati è un punto dati. In questo modo, un set di dati è una raccolta di punti dati.
Dati variabili
Un singolo valore da una riga di punti dati rappresenta una variabile di dati, in parole povere, una cella di tabella. Possiamo avere due tipi di variabili di dati: variabili qualitative e variabili quantitative. Le variabili qualitative (note anche come variabili categoriali) hanno un insieme discreto di valori, ad esempio color = red/green/blue . Le variabili quantitative hanno valori numerici, ad esempio height = 167 . Una variabile quantitativa, a differenza di una qualitativa, può assumere qualsiasi valore.
Creazione del nostro progetto di dati
Ora che conosciamo le basi, è il momento di sporcarci le mani e creare il nostro primo progetto di dati. Lo scopo del progetto è analizzare un set di dati attraverso l'intero flusso di dati di importazione, elaborazione e tracciatura dei dati. Per prima cosa sceglieremo il nostro set di dati, quindi scaricheremo e installeremo gli strumenti per l'analisi dei dati.
Set di dati per auto
Ai fini di questo articolo, ho scelto un set di dati per auto, perché è semplice e intuitivo. L'analisi dei dati confermerà semplicemente ciò che già sappiamo sulle auto, il che va bene, poiché il nostro focus è sul flusso di dati e sugli strumenti.
Possiamo scaricare un set di dati di auto usate da Kaggle, una delle maggiori fonti di set di dati gratuiti. Dovrai prima registrarti.
Dopo aver scaricato il file, aprilo e dai un'occhiata. È un file CSV davvero grande, ma dovresti capire l'essenza. Una riga in questo file sarà simile a questa:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3Come puoi vedere, questo punto dati ha diverse variabili separate da virgole. Dato che ora abbiamo il set di dati, parliamo un po' degli strumenti.
Strumenti del mestiere
Useremo il linguaggio R e RStudio per analizzare il set di dati. R è una lingua molto popolare e facile da imparare, utilizzata non solo dai data scientist, ma anche da persone nei mercati finanziari, nella medicina e in molte altre aree. RStudio è l'ambiente in cui vengono sviluppati i progetti R e c'è una versione gratuita, che è più che sufficiente per le nostre esigenze di designer UX.
È probabile che alcuni designer UX utilizzino Excel per il flusso di lavoro dei dati. Se questo significa che sei tu, prova R: ci sono buone probabilità che ti piaccia, dal momento che è facile da imparare e più flessibile e potente di Excel. L'aggiunta di R al tuo kit di strumenti farà la differenza.
Installazione degli strumenti
Innanzitutto, dobbiamo scaricare e installare R e RStudio. Dovresti installare prima R, quindi RStudio. I processi di installazione sia per R che per RStudio sono semplici e diretti.
Configurazione del progetto
Una volta completata l'installazione, crea una cartella di progetto: l'ho chiamata used-cars-prj . In quella cartella, crea una sottocartella chiamata data , quindi copia il file del set di dati (scaricato da Kaggle) in quella cartella e rinominalo in used-cars.csv . Ora torna alla nostra cartella del progetto ( used-cars-prj ) e crea un file di testo semplice chiamato used-cars.r . Dovresti ritrovarti con la stessa struttura dello screenshot qui sotto.
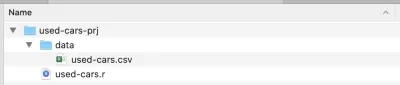
Ora abbiamo la struttura delle cartelle in atto, possiamo aprire RStudio e creare un nuovo progetto R. Scegli Nuovo progetto... dal menu File e seleziona la seconda opzione, Directory esistente . Quindi seleziona la directory del progetto ( used-cars-prj ). Infine, premi il pulsante Crea progetto e il gioco è fatto. Una volta creato il progetto, apri used-cars.r in RStudio: questo è il file in cui aggiungeremo tutto il nostro codice R.
Importazione di dati
Aggiungeremo la nostra prima riga in used-cars.r , per leggere i dati dal file used-cars.csv . Ricorda che i file CSV sono solo file di testo utilizzati per archiviare i dati. La nostra prima riga di codice R sarà simile a questa:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") Potrebbe sembrare un po' intimidatorio, ma in realtà non lo è — a proposito, questa è la linea più complessa dell'intero articolo. Quello che abbiamo qui è la funzione read.csv , che accetta tre parametri.
Il primo parametro è il file da leggere, nel nostro caso used-cars.csv , che si trova nella cartella dei dati . Il secondo parametro, stringsAsFactors=FALSE è impostato per assicurarsi che le stringhe come "BMW" o "Audi" non vengano convertite in fattori (il gergo R per i dati categoriali) — come ricorderete, le variabili qualitative o categoriali possono avere solo valori discreti come red/green/blue . Infine, il terzo parametro, sep="," specifica il tipo di separatore utilizzato per separare i valori nel file CSV: una virgola.
Dopo aver letto il file CSV, i dati vengono archiviati nell'oggetto frame dati cars . Un frame di dati è una struttura di dati bidimensionale (come una tabella di Excel), molto utile in R per manipolare i dati. Dopo aver introdotto la linea e averla eseguita, verrà creato per te un frame di dati delle cars . Se guardi nel quadrante in alto a destra in RStudio, noterai il frame dei dati delle cars , nella sezione Dati nella scheda Ambiente . Se fai doppio clic su auto , si aprirà una nuova scheda nel quadrante in alto a sinistra di RStudio e presenterà il frame dei dati delle cars . Come ci si potrebbe aspettare, sembra una tabella di Excel.
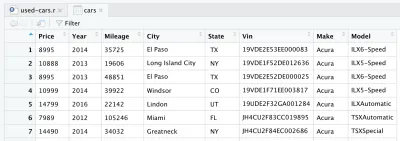
Questi sono in realtà i dati grezzi che abbiamo scaricato da Kaggle. Ma poiché vogliamo eseguire l'analisi dei dati, dobbiamo prima elaborare il nostro set di dati.
Elaborazione dati
Per elaborazione, intendiamo rimuovere, trasformare o aggiungere informazioni al nostro set di dati, al fine di prepararci al tipo di analisi che vogliamo eseguire. Abbiamo i dati in un oggetto data frame, quindi ora dobbiamo installare la libreria dplyr , una potente libreria per manipolare i dati. Per installare la libreria nel nostro ambiente R, dobbiamo scrivere la seguente riga nella parte superiore del nostro file R.
install.packages("dplyr")Quindi, per aggiungere la libreria al nostro progetto attuale, utilizzeremo la riga successiva:
library(dplyr) Una volta aggiunta la libreria dplyr al nostro progetto, possiamo iniziare a elaborare i dati. Abbiamo un set di dati davvero grande e abbiamo bisogno solo dei dati che rappresentano la stessa casa automobilistica e modello, per correlarlo con il prezzo. Utilizzeremo il seguente codice R per conservare solo i dati relativi alla BMW Serie 3 e rimuovere il resto. Naturalmente, puoi scegliere qualsiasi altro produttore e modello dal set di dati e aspettarti di avere le stesse caratteristiche dei dati.
cars <- cars %>% filter(Make == "BMW", Model == "3")Ora abbiamo un set di dati più gestibile, sebbene contenga ancora più di 11.000 punti dati, che si adatta allo scopo previsto: analizzare le distribuzioni di prezzo, età e chilometraggio delle auto, e anche le correlazioni tra di loro. Per questo, dobbiamo mantenere solo le colonne "Prezzo", "Anno" e "Chilometraggio" e rimuovere il resto: questo viene fatto con la riga seguente.
cars <- cars %>% select(Price, Year, Mileage)Dopo aver rimosso altre colonne, il nostro frame di dati sarà simile a questo:
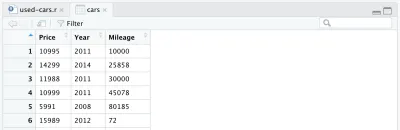
C'è un'altra modifica che vogliamo apportare al nostro set di dati: sostituire l'anno di produzione con l'età dell'auto. Possiamo aggiungere le due righe seguenti, la prima per calcolare l'età, la seconda per cambiare il nome della colonna.

cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Infine, il nostro frame di dati completamente elaborato si presenta così:
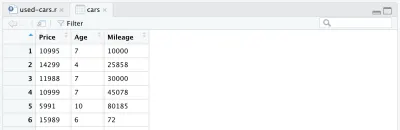
A questo punto, il nostro codice R sarà simile al seguente, e questo è tutto per l'elaborazione dei dati. Ora possiamo vedere quanto sia facile e potente il linguaggio R. Abbiamo elaborato il set di dati iniziale in modo abbastanza drammatico con solo poche righe di codice.
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Analisi dei dati
I nostri dati ora sono nella forma giusta, quindi possiamo andare a fare alcuni grafici. Come già accennato, ci concentreremo su due aspetti: la distribuzione delle singole variabili e le correlazioni tra di esse. La distribuzione variabile ci aiuta a capire cosa viene considerato un prezzo medio o alto per un'auto usata o la percentuale di auto al di sopra di un prezzo specifico. Lo stesso vale per l'età e il chilometraggio delle auto. Le correlazioni, d'altra parte, sono utili per capire come variabili come l'età e il chilometraggio sono correlate tra loro.
Detto questo, utilizzeremo due tipi di visualizzazione dei dati: istogrammi per la distribuzione delle variabili e grafici a dispersione per le correlazioni.
Distribuzione dei prezzi
Tracciare l'istogramma del prezzo dell'auto nel linguaggio R è facile come questo:
hist(cars$Price)Un piccolo consiglio: se sei in RStudio puoi eseguire il codice riga per riga; ad esempio, nel nostro caso, è necessario eseguire solo la riga sopra per visualizzare l'istogramma. Non è necessario eseguire nuovamente tutto il codice poiché l'hai già eseguito una volta. L'istogramma dovrebbe assomigliare a questo:
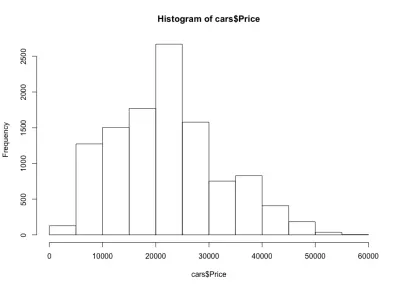
Se osserviamo l'istogramma, notiamo una distribuzione a campana dei prezzi delle auto, che è ciò che ci aspettavamo. La maggior parte delle auto si trova nella fascia media e ne abbiamo sempre meno man mano che ci spostiamo su ciascun lato. Quasi l'80% delle auto ha un prezzo compreso tra $ 10.000 e $ 30.000 USD e abbiamo un massimo di oltre 2.500 auto tra $ 20.000 e $ 25.000 USD. Sul lato sinistro abbiamo probabilmente circa 150 auto con meno di $ 5.000 USD e sul lato destro ancora meno. Possiamo facilmente vedere quanto siano utili tali grafici per ottenere informazioni dettagliate sui dati.
Distribuzione per età
Proprio come per i prezzi delle auto, useremo una linea simile per tracciare l'istogramma dell'età delle auto.
hist(cars$Age)Ed ecco l'istogramma:
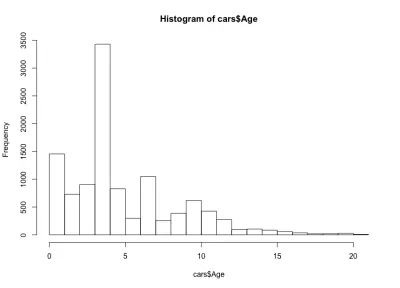
Questa volta l'istogramma sembra controintuitivo: invece di una semplice forma a campana, qui abbiamo quattro campane. Fondamentalmente, la distribuzione ha tre massimi locali e uno globale, il che è inaspettato. Sarebbe interessante vedere se questa strana distribuzione dell'età delle auto rimane vera per un altro produttore e modello di auto. Ai fini di questo articolo rimarremo con il set di dati della BMW Serie 3, ma puoi approfondire i dati se sei curioso. Per quanto riguarda la nostra distribuzione per età delle auto, notiamo che oltre il 90% delle auto ha meno di 10 anni e più dell'80% meno di 7 anni. Inoltre, notiamo che la maggior parte delle auto ha meno di 5 anni.
Distribuzione del chilometraggio
Ora, cosa possiamo dire del chilometraggio? Ovviamente, ci aspettiamo di avere la stessa forma a campana che avevamo per il prezzo. Ecco il codice R e l'istogramma:
hist(cars$Mileage) 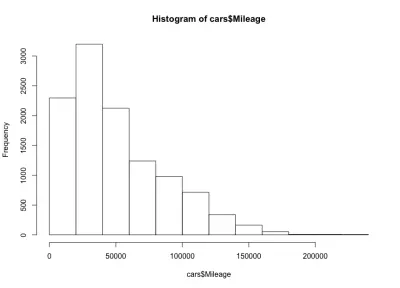
Qui abbiamo una forma a campana inclinata a sinistra, il che significa che ci sono più auto con meno chilometraggio sul mercato. Notiamo anche che la maggior parte delle auto ha meno di 60.000 miglia e abbiamo un massimo di circa 20.000 a 40.000 miglia.
Correlazione età-prezzo
Per quanto riguarda le correlazioni, diamo un'occhiata più da vicino alla correlazione età-prezzo delle auto. Potremmo aspettarci che il prezzo sia correlato negativamente con l'età: all'aumentare dell'età di un'auto, il suo prezzo diminuirà. Useremo la funzione R plot per visualizzare la correlazione prezzo-età come segue:
plot(cars$Age, cars$Price)E la trama si presenta così:
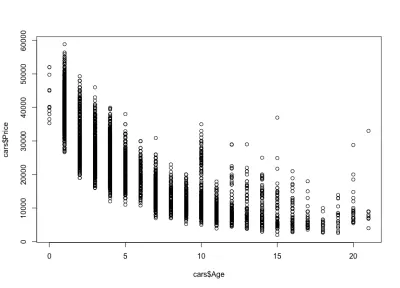
Notiamo come i prezzi delle auto scendono con l'età: ci sono auto nuove e costose e vecchie auto più economiche. Possiamo anche vedere l'intervallo di variazione del prezzo per qualsiasi età specifica, una variazione che diminuisce con l'età di un'auto. Questa variazione è in gran parte determinata dal chilometraggio, dalla configurazione e dallo stato generale dell'auto. Ad esempio, nel caso di un'auto di 4 anni, il prezzo varia tra $ 10.000 e $ 40.000 USD.
Correlazione chilometraggio-età
Considerando la correlazione chilometraggio-età, ci si aspetterebbe che il chilometraggio aumenti con l'età, il che significa una correlazione positiva. Ecco il codice:
plot(cars$Mileage, cars$Age)Ed ecco la trama:
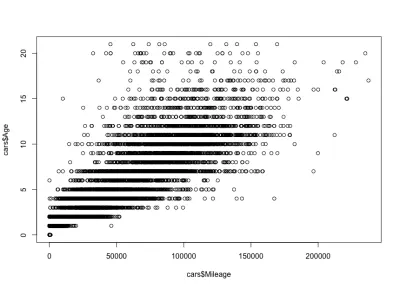
Come puoi vedere, l'età e il chilometraggio di un'auto sono correlati positivamente, a differenza del prezzo e dell'età di un'auto, che sono correlati negativamente. Abbiamo anche una variazione di chilometraggio prevista per un'età specifica; cioè, le auto della stessa età hanno chilometri diversi. Ad esempio, la maggior parte delle auto di 4 anni ha un chilometraggio compreso tra 10.000 e 80.000 miglia. Ma ci sono anche valori anomali, con un chilometraggio maggiore.
Correlazione chilometraggio-prezzo
Come previsto, ci sarà una correlazione negativa tra il chilometraggio delle auto e il prezzo, il che significa che aumentando il chilometraggio si riduce il prezzo.
plot(cars$Mileage, cars$Price)Ed ecco la trama:
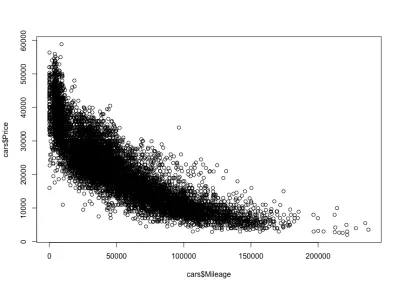
Come ci aspettavamo, una correlazione negativa. Possiamo anche notare l'intervallo di prezzo lordo tra $ 3.000 e $ 50.000 USD e il chilometraggio tra 0 e 150.000. Se osserviamo più da vicino la forma della distribuzione, vediamo che il prezzo scende molto più velocemente per le auto con meno chilometraggio rispetto alle auto con più chilometraggio. Ci sono auto con chilometraggio quasi zero, dove il prezzo scende drasticamente. Inoltre, al di sopra dell'intervallo di 200.000 miglia, poiché il chilometraggio è molto alto, il prezzo rimane costante.
Dai numeri alle visualizzazioni dei dati
In questo articolo sono stati utilizzati due tipi di visualizzazione: istogrammi per le distribuzioni dei dati e grafici a dispersione per le correlazioni dei dati. Gli istogrammi sono rappresentazioni visive che prendono i valori di una variabile di dati ( numeri effettivi) e mostrano come sono distribuiti in un intervallo. Abbiamo usato la funzione R hist() per tracciare un istogramma.
I grafici a dispersione, invece, prendono coppie di numeri e li rappresentano su due assi. I grafici a dispersione utilizzano la funzione plot() e forniscono due parametri: la prima e la seconda variabile di dati della correlazione che vogliamo indagare. Pertanto, le due funzioni R, hist() e plot() ci aiutano a tradurre insiemi di numeri in rappresentazioni visive significative.
Conclusione
Avendoci sporcato le mani durante l'intero flusso di dati di importazione, elaborazione e tracciatura dei dati, ora le cose sembrano molto più chiare. Puoi applicare lo stesso flusso di dati a qualsiasi nuovo brillante set di dati che incontrerai. Nella ricerca degli utenti, ad esempio, è possibile tracciare un grafico del tempo sulle distribuzioni di attività o errori e anche tracciare un tempo sulla correlazione tra attività e errori.
Per saperne di più sul linguaggio R Quick-R è un buon punto di partenza, ma potresti anche considerare R Bloggers. Per la documentazione sui pacchetti R, come dplyr , puoi visitare RDocumentation. Giocare con i dati può essere divertente, ma è anche estremamente utile per qualsiasi designer di UX in un mondo basato sui dati. Man mano che vengono raccolti e utilizzati più dati per prendere decisioni aziendali, aumenta la possibilità per i progettisti di lavorare sulla visualizzazione dei dati o sui prodotti di dati, dove è essenziale comprendere la natura dei dati.