
Creazione di un servizio Pub/Sub internamente utilizzando Node.js e Redis
Pubblicato: 2022-03-10Il mondo di oggi funziona in tempo reale. Che si tratti di negoziare azioni o ordinare cibo, oggi i consumatori si aspettano risultati immediati. Allo stesso modo, ci aspettiamo tutti di sapere immediatamente le cose, che si tratti di notizie o sport. Zero, in altre parole, è il nuovo eroe.
Questo vale anche per gli sviluppatori di software, probabilmente alcune delle persone più impazienti! Prima di immergermi nella storia di BrowserStack, sarebbe negligente da parte mia non fornire alcune informazioni su Pub/Sub. Per quelli di voi che hanno familiarità con le basi, sentitevi liberi di saltare i prossimi due paragrafi.
Molte applicazioni oggi si basano sul trasferimento di dati in tempo reale. Diamo un'occhiata più da vicino a un esempio: i social network. Mi piace di Facebook e Twitter generano feed pertinenti e tu (tramite la loro app) li consumi e spii i tuoi amici. Lo fanno con una funzione di messaggistica, in cui se un utente genera dati, questi verranno pubblicati affinché altri li consumino in un batter d'occhio. Eventuali ritardi significativi e gli utenti si lamenteranno, l'utilizzo diminuirà e, se persiste, sfornerà. La posta in gioco è alta, così come le aspettative degli utenti. Quindi in che modo servizi come WhatsApp, Facebook, TD Ameritrade, Wall Street Journal e GrubHub supportano elevati volumi di trasferimenti di dati in tempo reale?
Tutti utilizzano un'architettura software simile ad alto livello chiamata modello "Publish-Subscribe", comunemente indicato come Pub/Sub.
"Nell'architettura del software, pubblica-sottoscrivi è un modello di messaggistica in cui i mittenti di messaggi, chiamati editori, non programmano i messaggi da inviare direttamente a destinatari specifici, chiamati abbonati, ma classificano invece i messaggi pubblicati in classi senza sapere quali abbonati, se qualsiasi, ci può essere. Allo stesso modo, gli abbonati esprimono interesse per una o più classi e ricevono solo messaggi di interesse, senza sapere quali editori, se ce ne sono.“
— Wikipedia
Annoiato dalla definizione? Torniamo alla nostra storia.
In BrowserStack, tutti i nostri prodotti supportano (in un modo o nell'altro) software con un componente sostanziale di dipendenza in tempo reale, che si tratti di automatizzare i registri dei test, schermate del browser appena sfornate o streaming mobile a 15 fps.
In questi casi, se un singolo messaggio cade, un cliente può perdere informazioni vitali per prevenire un bug . Pertanto, dovevamo scalare per diversi requisiti di dimensione dei dati. Ad esempio, con i servizi di registrazione del dispositivo in un determinato momento, potrebbero esserci 50 MB di dati generati in un singolo messaggio. Dimensioni come questa potrebbero causare il crash del browser. Per non parlare del fatto che il sistema di BrowserStack dovrebbe essere ridimensionato per prodotti aggiuntivi in futuro.
Poiché la dimensione dei dati per ogni messaggio varia da pochi byte fino a 100 MB, avevamo bisogno di una soluzione scalabile in grado di supportare una moltitudine di scenari. In altre parole, abbiamo cercato una spada che potesse tagliare tutte le torte. In questo articolo, discuterò il perché, come e i risultati della creazione interna del nostro servizio Pub/Sub.
Attraverso la lente del problema del mondo reale di BrowserStack, otterrai una comprensione più profonda dei requisiti e del processo per creare il tuo Pub/Sub personale .
La nostra esigenza di un servizio Pub/Sub
BrowserStack ha circa 100 milioni di messaggi, ognuno dei quali è compreso tra circa 2 byte e oltre 100 MB. Questi vengono trasmessi in tutto il mondo in qualsiasi momento, tutti a velocità Internet diverse.
I più grandi generatori di questi messaggi, in base alla dimensione del messaggio, sono i nostri prodotti BrowserStack Automate. Entrambi hanno dashboard in tempo reale che mostrano tutte le richieste e le risposte per ogni comando di un test utente. Quindi, se qualcuno esegue un test con 100 richieste in cui la dimensione media richiesta-risposta è 10 byte, questo trasmette 1×100×10 = 1000 byte.
Ora consideriamo il quadro più ampio poiché, ovviamente, non eseguiamo un solo test al giorno. Più di circa 850.000 test BrowserStack Automate e App Automate vengono eseguiti con BrowserStack ogni giorno. E sì, abbiamo una media di circa 235 richieste-risposte per test. Poiché gli utenti possono acquisire schermate o chiedere fonti di pagina in Selenium, la nostra dimensione media richiesta-risposta è di circa 220 byte.
Quindi, tornando al nostro calcolatore:
850.000 × 235 × 220 = 43.945.000.000 di byte (circa) o solo 43,945 GB al giorno
Ora parliamo di BrowserStack Live e App Live. Sicuramente abbiamo Automate come nostro vincitore in termini di dimensioni dei dati. Tuttavia, i prodotti Live prendono il comando quando si tratta del numero di messaggi passati. Per ogni test dal vivo, vengono superati circa 20 messaggi ogni minuto che gira. Eseguiamo circa 100.000 test dal vivo, ognuno dei quali con una media di circa 12 minuti significa:
100.000×12×20 = 24.000.000 di messaggi al giorno
Ora per la parte fantastica e straordinaria: costruiamo, eseguiamo e manteniamo l'applicazione per questo pusher chiamato con 6 istanze t1.micro di ec2. Il costo di gestione del servizio? Circa $70 al mese .
Scegliere di costruire e acquistare
Per prima cosa: come startup, come la maggior parte delle altre, siamo sempre stati entusiasti di costruire le cose internamente. Ma abbiamo ancora valutato alcuni servizi là fuori. I requisiti primari che avevamo erano:
- Affidabilità e stabilità,
- Alte prestazioni e
- Efficacia dei costi.
Lasciamo perdere i criteri di costo-efficacia, poiché non riesco a pensare a servizi esterni che costano meno di $ 70 al mese (twittami se ne conosci uno che lo fa!). Quindi la nostra risposta è ovvia.
In termini di affidabilità e stabilità, abbiamo trovato aziende che fornivano Pub/Sub come servizio con un tempo di attività SLA superiore al 99,9%, ma c'erano molti T&C allegati. Il problema non è così semplice come si pensa, soprattutto se si considerano le vaste terre dell'Internet aperta che si trovano tra il sistema e il client. Chiunque abbia familiarità con l'infrastruttura Internet sa che la connettività stabile è la sfida più grande. Inoltre, la quantità di dati inviati dipende dal traffico. Ad esempio, una pipe di dati che è a zero per un minuto potrebbe scoppiare durante il successivo. I servizi che forniscono un'adeguata affidabilità durante tali momenti di burst sono rari (Google e Amazon).
Prestazioni per il nostro progetto significa ottenere e inviare dati a tutti i nodi di ascolto con una latenza prossima allo zero . In BrowserStack, utilizziamo i servizi cloud (AWS) insieme all'hosting in co-location. Tuttavia, i nostri editori e/o abbonati potrebbero essere collocati ovunque. Ad esempio, potrebbe coinvolgere un server delle applicazioni AWS che genera i dati di registro tanto necessari o terminali (macchine a cui gli utenti possono connettersi in modo sicuro per i test). Tornando di nuovo al problema di Internet aperto, se dovessimo ridurre i nostri rischi dovremmo garantire che il nostro Pub/Sub sfrutti i migliori servizi host e AWS.
Un altro requisito essenziale era la capacità di trasmettere tutti i tipi di dati (Byte, testo, dati multimediali strani, ecc.). Tutto sommato, non aveva senso affidarsi a una soluzione di terze parti per supportare i nostri prodotti. A nostra volta, abbiamo deciso di far rivivere il nostro spirito di startup, rimboccandoci le maniche per programmare la nostra soluzione.

Costruire la nostra soluzione
Pub/Sub by design significa che ci sarà un editore, che genererà e invierà dati, e un Abbonato che li accetterà ed elaborerà. È simile a una radio: un canale radiofonico trasmette (pubblica) contenuti ovunque all'interno di un intervallo. Come abbonato, puoi decidere se sintonizzarti su quel canale e ascoltarlo (o spegnere del tutto la radio).
A differenza dell'analogia radiofonica in cui i dati sono gratuiti per tutti e chiunque può decidere di sintonizzarsi, nel nostro scenario digitale abbiamo bisogno dell'autenticazione, il che significa che i dati generati dall'editore potrebbero essere solo per un singolo cliente o abbonato particolare.
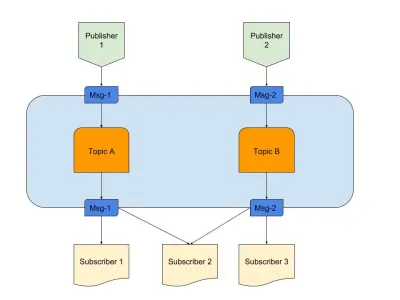
Sopra c'è un diagramma che fornisce un esempio di un buon Pub/Sub con:
- Editori
Qui abbiamo due editori che generano messaggi in base a una logica predefinita. Nella nostra analogia radiofonica, questi sono i nostri fantini radiofonici che creano il contenuto. - Temi
Ce ne sono due qui, il che significa che ci sono due tipi di dati. Possiamo dire che questi sono i nostri canali radio 1 e 2. - Iscritti
Ne abbiamo tre che leggono ciascuno i dati su un argomento particolare. Una cosa da notare è che Subscriber 2 sta leggendo da più argomenti. Nella nostra analogia radiofonica, queste sono le persone che sono sintonizzate su un canale radiofonico.
Iniziamo a capire i requisiti necessari per il servizio.
- Un componente con eventi
Questo si attiva solo quando c'è qualcosa da calciare. - Stoccaggio transitorio
Ciò mantiene i dati persistenti per un breve periodo, quindi se l'abbonato è lento, ha ancora una finestra per consumarli. - Ridurre la latenza
Collegamento di due entità su una rete con salti e distanza minimi.
Abbiamo scelto uno stack tecnologico che soddisfa i requisiti di cui sopra:
- Node.js
Perché perché no? Eventualmente, non avremmo bisogno di un'elaborazione pesante dei dati, inoltre è facile da integrare. - Redis
Supporta perfettamente dati di breve durata. Ha tutte le capacità per avviare, aggiornare e scadere automaticamente. Inoltre carica meno l'applicazione.
Node.js per la connettività della logica aziendale
Node.js è un linguaggio quasi perfetto quando si tratta di scrivere codice che incorpora IO ed eventi. Il nostro particolare problema dato aveva entrambi, rendendo questa opzione la più pratica per le nostre esigenze.
Sicuramente altri linguaggi come Java potrebbero essere più ottimizzati, oppure un linguaggio come Python offre scalabilità. Tuttavia, il costo per iniziare con questi linguaggi è così alto che uno sviluppatore potrebbe finire di scrivere codice in Node nella stessa durata.
Ad essere onesti, se il servizio avesse avuto la possibilità di aggiungere funzionalità più complicate, avremmo potuto esaminare altre lingue o uno stack completo. Ma ecco un matrimonio fatto in paradiso. Ecco il nostro package.json :
{ "name": "Pusher", "version": "1.0.0", "dependencies": { "bstack-analytics": "*****", // Hidden for BrowserStack reasons. :) "ioredis": "^2.5.0", "socket.io": "^1.4.4" }, "devDependencies": {}, "scripts": { "start": "node server.js" } }In parole povere, crediamo nel minimalismo soprattutto quando si tratta di scrivere codice. D'altra parte, avremmo potuto usare librerie come Express per scrivere codice estensibile per questo progetto. Tuttavia, il nostro istinto di startup ha deciso di trasmetterlo e di salvarlo per il prossimo progetto. Strumenti aggiuntivi che abbiamo utilizzato:
- ioredis
Questa è una delle librerie più supportate per la connettività Redis con Node.js utilizzata da aziende tra cui Alibaba. - presa.io
La migliore libreria per connettività aggraziata e fallback con WebSocket e HTTP.
Redis per l'archiviazione transitoria
Redis come scala di servizio è altamente affidabile e configurabile. Inoltre, ci sono molti fornitori di servizi gestiti affidabili per Redis, incluso AWS. Anche se non desideri utilizzare un provider, Redis è facile da usare.
Analizziamo la parte configurabile. Abbiamo iniziato con la solita configurazione master-slave, ma Redis viene fornito anche con modalità cluster o sentinella. Ogni modalità ha i suoi vantaggi.
Se potessimo condividere i dati in qualche modo, un cluster Redis sarebbe la scelta migliore. Ma se condividiamo i dati con qualsiasi euristica, abbiamo meno flessibilità poiché l'euristica deve essere seguita attraverso . Meno regole, più controllo fa bene alla vita!
Redis Sentinel funziona meglio per noi poiché la ricerca dei dati viene eseguita in un solo nodo, collegandosi in un determinato momento mentre i dati non sono partizionati. Ciò significa anche che anche se vengono persi più nodi, i dati sono comunque distribuiti e presenti in altri nodi. Quindi hai più HA e meno possibilità di perdita. Ovviamente, questo ha rimosso i professionisti dall'avere un cluster, ma il nostro caso d'uso è diverso.
Architettura a 30000 piedi
Il diagramma seguente fornisce un'immagine di alto livello di come funzionano i nostri dashboard Automate e App Automate. Ricordi il sistema in tempo reale che avevamo nella sezione precedente?
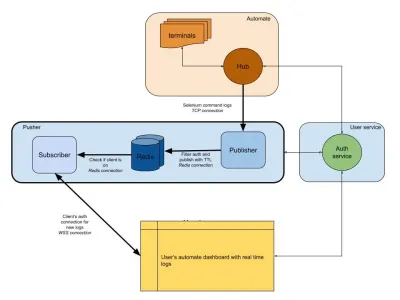
Nel nostro diagramma, il nostro flusso di lavoro principale è evidenziato con bordi più spessi. La sezione “automatizzazione” è composta da:
- Terminali
Comprende le versioni originali di Windows, OSX, Android o iOS che ottieni durante i test su BrowserStack. - Centro
Il punto di contatto per tutti i tuoi test Selenium e Appium con BrowserStack.
La sezione "servizio utente" qui è il nostro gatekeeper, garantendo che i dati vengano inviati e salvati per la persona giusta. È anche il nostro guardiano della sicurezza. La sezione "spingitori" incorpora il cuore di ciò di cui abbiamo discusso in questo articolo. È composto dai soliti sospetti tra cui:
- Redis
Il nostro archivio transitorio per i messaggi, dove nel nostro caso i registri automatici vengono temporaneamente archiviati. - Editore
Questa è fondamentalmente l'entità che ottiene i dati dall'hub. Tutte le risposte alle tue richieste vengono catturate da questo componente che scrive su Redis consession_idcome canale. - Abbonato
Questo legge i dati da Redis generati persession_id. È anche il server Web in cui i client possono connettersi tramite WebSocket (o HTTP) per ottenere dati e quindi inviarli ai client autenticati.
Infine, abbiamo la sezione del browser dell'utente, che rappresenta una connessione WebSocket autenticata per garantire che i log di session_id vengano inviati. Ciò consente al JS front-end di analizzarlo e abbellirlo per gli utenti.
Simile al servizio di log, qui abbiamo un pusher che viene utilizzato per altre integrazioni di prodotti. Invece di session_id , utilizziamo un'altra forma di ID per rappresentare quel canale. Tutto questo funziona da pusher!
Conclusione (TLDR)
Abbiamo avuto un notevole successo nella creazione di Pub/Sub. Per riassumere perché l'abbiamo costruito internamente:
- Si adatta meglio alle nostre esigenze;
- Più economico dei servizi esternalizzati;
- Pieno controllo sull'intera architettura.
Per non parlare del fatto che JS è la soluzione perfetta per questo tipo di scenario. Il ciclo di eventi e l'enorme quantità di IO sono ciò di cui il problema ha bisogno! JavaScript è la magia di un singolo pseudo thread.
Eventi e Redis come sistema semplificano le cose per gli sviluppatori, poiché puoi ottenere dati da una fonte e inviarli a un'altra tramite Redis. Quindi l'abbiamo costruito.
Se l'utilizzo si adatta al tuo sistema, ti consiglio di fare lo stesso!