
Regressione polinomiale: importanza, implementazione passo passo
Pubblicato: 2021-01-29Sommario
introduzione
In questo vasto campo del Machine Learning, quale sarebbe il primo algoritmo che la maggior parte di noi avrebbe studiato? Sì, è la regressione lineare. Essendo principalmente il primo programma e algoritmo che si sarebbe appreso nei primi giorni di Machine Learning Programming, la regressione lineare ha la sua importanza e potenza con un tipo lineare di dati.
E se il set di dati che incontriamo non è separabile linearmente? Cosa succede se il modello di regressione lineare non è in grado di derivare alcun tipo di relazione tra le variabili indipendenti e dipendenti?
Viene un altro tipo di regressione noto come la regressione polinomiale. Fedele al suo nome, Polynomial Regression è un algoritmo di regressione che modella la relazione tra la variabile dipendente (y) e la variabile indipendente (x) come un polinomio di ennesimo grado. In questo articolo, comprenderemo l'algoritmo e la matematica alla base della regressione polinomiale insieme alla sua implementazione in Python.
Che cos'è la regressione polinomiale?
Come definito in precedenza, la regressione polinomiale è un caso speciale di regressione lineare in cui un'equazione polinomiale con un grado (n) specificato si adatta ai dati non lineari che formano una relazione curvilinea tra le variabili dipendenti e indipendenti.
y= b 0 +b 1 x 1 + b 2 x 1 2 + b 3 x 1 3 +…… b n x 1 n
Qui,

y è la variabile dipendente (variabile di output)
x1 è la variabile indipendente (predittori)
b 0 è la distorsione
b 1 , b 2 , ….b n sono i pesi nell'equazione di regressione.
Man mano che il grado dell'equazione polinomiale ( n ) diventa più alto, l'equazione polinomiale diventa più complicata e c'è la possibilità che il modello tenda a overfit che sarà discusso nella parte successiva.
Confronto di equazioni di regressione
Regressione lineare semplice ===> y= b0+b1x
Regressione lineare multipla ===> y= b0+b1x1+ b2x2+ b3x3+…… bnxn
Regressione polinomiale ===> y= b0+b1x1+ b2x12+ b3x13+…… bnx1n
Dalle tre equazioni precedenti, vediamo che ci sono diverse sottili differenze in esse. Le regressioni lineari semplici e multiple sono diverse dall'equazione di regressione polinomiale in quanto ha un grado di solo 1. La regressione lineare multipla è composta da diverse variabili x1, x2 e così via. Sebbene l'equazione della regressione polinomiale abbia una sola variabile x1, ha un grado n che la differenzia dalle altre due.
Necessità di regressione polinomiale
Dai diagrammi seguenti possiamo vedere che nel primo diagramma, si tenta di adattare una linea lineare al dato insieme di punti dati non lineari. Resta inteso che diventa molto difficile per una retta formare una relazione con questi dati non lineari. Per questo motivo, quando si addestra il modello, la funzione di perdita aumenta causando l'errore elevato.
D'altra parte, quando applichiamo la regressione polinomiale è chiaramente visibile che la linea si adatta bene ai punti dati. Ciò significa che l'equazione polinomiale che si adatta ai punti dati deriva una sorta di relazione tra le variabili nel set di dati. Pertanto, per quei casi in cui i punti dati sono disposti in modo non lineare, è necessario il modello di regressione polinomiale.
Implementazione della regressione polinomiale in Python
Da qui, costruiremo un modello di Machine Learning in Python implementando la regressione polinomiale. Confronteremo i risultati ottenuti con la regressione lineare e la regressione polinomiale. Cerchiamo prima di tutto di capire il problema che risolveremo con la regressione polinomiale.
Descrizione del problema
In questo caso, consideriamo il caso di una Start-up che cerca di assumere diversi candidati da un'azienda. Ci sono diverse aperture per diversi ruoli di lavoro in azienda. La start-up ha i dettagli dello stipendio per ogni ruolo nella società precedente. Pertanto, quando un candidato menziona il suo precedente stipendio, l'HR della start-up deve verificarlo con i dati esistenti. Quindi, abbiamo due variabili indipendenti che sono Posizione e Livello. La variabile dipendente (output) è lo stipendio che deve essere previsto utilizzando la regressione polinomiale.
Visualizzando la tabella sopra in un grafico, vediamo che i dati sono di natura non lineare. In altre parole, all'aumentare del livello, lo stipendio aumenta a un ritmo più alto dandoci così una curva come mostrato di seguito.
Passaggio 1: pre-elaborazione dei datiIl primo passaggio nella creazione di qualsiasi modello di Machine Learning è importare le librerie. Qui abbiamo solo tre librerie di base da importare. Successivamente, il set di dati viene importato dal mio repository GitHub e vengono assegnate le variabili dipendenti e le variabili indipendenti. Le variabili indipendenti sono memorizzate nella variabile X e la variabile dipendente è memorizzata nella variabile y.
importa numpy come np
importa matplotlib.pyplot come plt
importa panda come pd
set di dati = pd.read_csv('https://raw.githubusercontent.com/mk-gurucharan/Regression/master/PositionSalaries_Data.csv')
X = dataset.iloc[:, 1:-1].valori
y = dataset.iloc[:, -1].valori
Qui nel termine [:, 1:-1], i primi due punti rappresentano che tutte le righe devono essere prese e il termine 1:-1 indica che le colonne da includere sono dalla prima colonna alla penultima colonna che è data da -1.
Passaggio 2: modello di regressione lineareNella fase successiva, costruiremo un modello di regressione lineare multipla e lo utilizzeremo per prevedere i dati salariali dalle variabili indipendenti. Per questo, la classe LinearRegression viene importata dalla libreria sklearn. Viene quindi adattato alle variabili X e y per scopi di addestramento.

da sklearn.linear_model import LinearRegression
regressore = regressione lineare()
regressore.fit(X, y)
Una volta costruito il modello, visualizzando i risultati, otteniamo il grafico seguente.
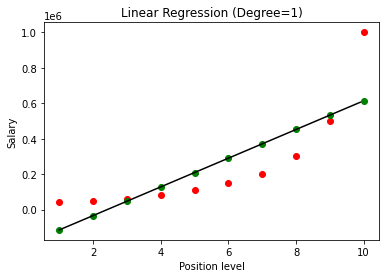
Come si vede chiaramente, cercando di adattare una linea retta su un set di dati non lineare, non esiste alcuna relazione derivata dal modello di Machine Learning. Pertanto, dobbiamo utilizzare la regressione polinomiale per ottenere una relazione tra le variabili.
Passaggio 3: modello di regressione polinomialeIn questo passaggio successivo, adatteremo un modello di regressione polinomiale su questo set di dati e visualizzeremo i risultati. Per questo, importiamo un'altra classe dal modulo sklearn chiamato PolynomialFeatures in cui diamo il grado dell'equazione polinomiale da costruire. Quindi la classe LinearRegression viene utilizzata per adattare l'equazione Polynomial al set di dati.
da sklearn.preprocessing import PolynomialFeatures
da sklearn.linear_model import LinearRegression
poly_reg = PolynomialFeatures(grado = 2)
X_poly = poly_reg.fit_transform(X)
lin_reg = regressione lineare()
lin_reg.fit(X_poly, y)
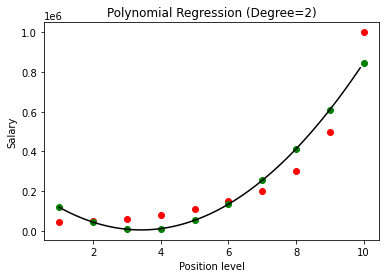
Nel caso precedente, abbiamo dato che il grado dell'equazione polinomiale sia uguale a 2. Nel tracciare il grafico, vediamo che c'è una sorta di curva che viene derivata ma c'è ancora molta deviazione dai dati reali (in rosso ) e i punti della curva previsti (in verde). Pertanto, nel passaggio successivo aumenteremo il grado del polinomio a numeri più alti come 3 e 4 e quindi lo confronteremo tra loro.
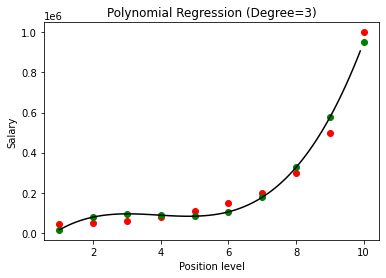
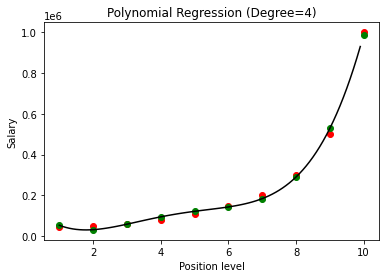
Confrontando i risultati della regressione polinomiale con i gradi 3 e 4, vediamo che all'aumentare del grado, il modello si allena bene con i dati. Pertanto, possiamo dedurre che un grado più alto consente all'equazione del polinomio di adattarsi in modo più accurato ai dati di addestramento. Tuttavia, questo è il caso perfetto di overfitting. Pertanto, diventa importante scegliere il valore di n con precisione per evitare l'overfitting.
Cos'è l'overfitting?
Come dice il nome, l'Overfitting è definito come una situazione nelle statistiche in cui una funzione (o un modello di Machine Learning in questo caso) si adatta troppo da vicino a un insieme di punti dati limitati. Ciò fa sì che la funzione funzioni male con i nuovi punti dati.
In Machine Learning, se si dice che un modello si adatta troppo a un determinato insieme di punti dati di addestramento, quando lo stesso modello viene introdotto in un insieme di punti completamente nuovo (ad esempio il set di dati di test), allora funziona molto male su di esso come il il modello di overfitting non si è generalizzato bene con i dati ed è solo overfitting sui punti dati di addestramento.
Nella regressione polinomiale, c'è una buona possibilità che il modello si adatti troppo ai dati di addestramento all'aumentare del grado del polinomio. Nell'esempio mostrato sopra, vediamo un tipico caso di overfitting nella regressione polinomiale che può essere corretto solo con una base per tentativi ed errori per la scelta del valore ottimale del grado.
Leggi anche: Idee per progetti di apprendimento automatico
Conclusione
Per concludere, la regressione polinomiale viene utilizzata in molte situazioni in cui esiste una relazione non lineare tra le variabili dipendenti e indipendenti. Sebbene questo algoritmo soffra di sensibilità verso i valori anomali, può essere corretto trattandoli prima di adattare la linea di regressione. Pertanto, in questo articolo, siamo stati introdotti al concetto di regressione polinomiale insieme a un esempio della sua implementazione nella programmazione Python su un semplice set di dati.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Stato di ex alunni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Impara il corso ML dalle migliori università del mondo. Guadagna master, Executive PGP o programmi di certificazione avanzati per accelerare la tua carriera.
Cosa intendi per regressione lineare?
La regressione lineare è un tipo di analisi numerica predittiva attraverso la quale possiamo trovare il valore di una variabile sconosciuta con l'aiuto di una variabile dipendente. Spiega anche la connessione tra una variabile dipendente e una o più variabili indipendenti. La regressione lineare è una tecnica statistica per dimostrare un legame tra due variabili. La regressione lineare traccia una linea di tendenza da un insieme di punti dati. La regressione lineare può essere utilizzata per generare un modello di previsione da dati apparentemente casuali, come diagnosi di cancro o prezzi delle azioni. Esistono diversi metodi per calcolare la regressione lineare. L'approccio ordinario dei minimi quadrati, che stima variabili incognite nei dati e si trasforma visivamente nella somma delle distanze verticali tra i punti dati e la linea di tendenza, è uno dei più diffusi.
Quali sono alcuni degli svantaggi della regressione lineare?
Nella maggior parte dei casi, l'analisi di regressione viene utilizzata nella ricerca per stabilire che esiste un collegamento tra le variabili. Tuttavia, la correlazione non implica una causalità poiché un collegamento tra due variabili non implica che una causi l'avvenimento dell'altra. Anche una linea in una regressione lineare di base che si adatta bene ai punti dati potrebbe non garantire una relazione tra circostanze e risultati logici. Utilizzando un modello di regressione lineare, è possibile determinare se esiste o meno una correlazione tra le variabili. Saranno necessarie ulteriori indagini e analisi statistiche per determinare l'esatta natura del collegamento e se una variabile causa l'altra.
Quali sono le ipotesi di base della regressione lineare?
Nella regressione lineare, ci sono tre ipotesi chiave. Le variabili dipendenti e indipendenti devono innanzitutto avere una connessione lineare. Per verificare questa relazione viene utilizzato un grafico a dispersione delle variabili dipendenti e indipendenti. In secondo luogo, dovrebbe esserci una multicollinearità minima o nulla tra le variabili indipendenti nel set di dati. Implica che le variabili indipendenti non sono correlate. Il valore deve essere limitato, che è determinato dal requisito del dominio. L'omoscedasticità è il terzo fattore. Il presupposto che gli errori siano distribuiti uniformemente è uno dei presupposti più essenziali.