
Mantenere Node.js veloce: strumenti, tecniche e suggerimenti per creare server Node.js ad alte prestazioni
Pubblicato: 2022-03-10Se hai creato qualcosa con Node.js abbastanza a lungo, senza dubbio hai sperimentato il dolore di problemi di velocità imprevisti. JavaScript è un linguaggio asincrono con eventi. Ciò può rendere complicato il ragionamento sulle prestazioni, come risulterà evidente. La crescente popolarità di Node.js ha messo in luce la necessità di strumenti, tecniche e pensiero adatti ai vincoli di JavaScript lato server.
Quando si tratta di prestazioni, ciò che funziona nel browser non è necessariamente adatto a Node.js. Quindi, come possiamo assicurarci che un'implementazione di Node.js sia veloce e adatta allo scopo? Esaminiamo un esempio pratico.
Utensili
Node è una piattaforma molto versatile, ma una delle applicazioni predominanti è la creazione di processi in rete. Ci concentreremo sulla profilazione del più comune di questi: i server Web HTTP.
Avremo bisogno di uno strumento in grado di far esplodere un server con molte richieste misurando le prestazioni. Ad esempio, possiamo usare AutoCannon:
npm install -g autocannonAltri buoni strumenti di benchmarking HTTP includono Apache Bench (ab) e wrk2, ma AutoCannon è scritto in Node, fornisce una pressione di carico simile (o talvolta maggiore) ed è molto facile da installare su Windows, Linux e Mac OS X.
Dopo aver stabilito una misurazione delle prestazioni di base, se decidiamo che il nostro processo potrebbe essere più veloce, avremo bisogno di un modo per diagnosticare i problemi con il processo. Un ottimo strumento per diagnosticare vari problemi di prestazioni è Node Clinic, che può essere installato anche con npm:
npm install -g clinicQuesto in realtà installa una suite di strumenti. Useremo Clinic Doctor e Clinic Flame (un wrapper intorno a 0x) mentre procediamo.
Nota : per questo esempio pratico avremo bisogno del nodo 8.11.2 o successivo.
Il codice
Il nostro caso di esempio è un semplice server REST con una singola risorsa: un grande payload JSON esposto come route GET su /seed/v1 . Il server è una cartella app che consiste in un file package.json (a seconda di restify 7.1.0 ), un file index.js e un file util.js.
Il file index.js per il nostro server si presenta così:
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) Questo server è rappresentativo del caso comune di servire contenuto dinamico memorizzato nella cache del client. Ciò si ottiene con il middleware etagger , che calcola un'intestazione ETag per lo stato più recente del contenuto.
Il file util.js fornisce parti di implementazione che verrebbero comunemente utilizzate in uno scenario del genere, una funzione per recuperare il contenuto pertinente da un back-end, il middleware etag e una funzione timestamp che fornisce timestamp minuto per minuto:
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }Non prendere assolutamente questo codice come un esempio di best practice! Ci sono più odori di codice in questo file, ma li individueremo mentre misuriamo e profiliamo l'applicazione.
Per ottenere la fonte completa per il nostro punto di partenza, il server lento può essere trovato qui.
Profilazione
Per profilare, abbiamo bisogno di due terminali, uno per avviare l'applicazione e l'altro per testare il carico.
In un terminale, all'interno della cartella app , possiamo eseguire:
node index.jsIn un altro terminale possiamo profilarlo in questo modo:
autocannon -c100 localhost:3000/seed/v1Questo aprirà 100 connessioni simultanee e bombarderà il server di richieste per dieci secondi.
I risultati dovrebbero essere qualcosa di simile ai seguenti (Esecuzione del test di 10 secondi @ https://localhost:3000/seed/v1 — 100 connessioni):
| statistica | media | Stdev | Massimo |
|---|---|---|---|
| Latenza (ms) | 3086.81 | 1725.2 | 5554 |
| Richiesto/Sec | 23.1 | 19.18 | 65 |
| Byte/Sec | 237,98 kB | 197,7 kB | 688.13 kB |
I risultati variano a seconda della macchina. Tuttavia, considerando che un server Node.js "Hello World" è facilmente in grado di ricevere trentamila richieste al secondo su quella macchina che ha prodotto questi risultati, 23 richieste al secondo con una latenza media superiore a 3 secondi sono tristi.
Diagnosi
Alla scoperta dell'area problematica
Possiamo diagnosticare l'applicazione con un solo comando, grazie al comando –on-port di Clinic Doctor. All'interno della cartella app eseguiamo:
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsQuesto creerà un file HTML che si aprirà automaticamente nel nostro browser al termine della profilazione.
I risultati dovrebbero essere simili ai seguenti:
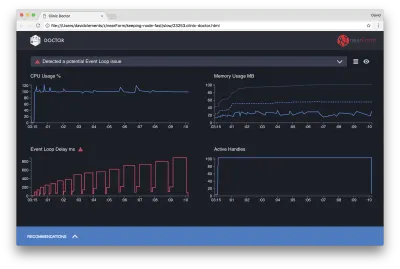
Il Dottore ci sta dicendo che probabilmente abbiamo avuto un problema con il ciclo degli eventi.
Insieme al messaggio nella parte superiore dell'interfaccia utente, possiamo anche vedere che il grafico Event Loop è rosso e mostra un ritardo in costante aumento. Prima di approfondire il significato di ciò, comprendiamo innanzitutto l'effetto che il problema diagnosticato sta avendo sulle altre metriche.
Possiamo vedere che la CPU è costantemente pari o superiore al 100% poiché il processo lavora duramente per elaborare le richieste in coda. Il motore JavaScript di Node (V8) utilizza effettivamente due core CPU in questo caso perché la macchina è multi-core e V8 utilizza due thread. Uno per Event Loop e l'altro per Garbage Collection. Quando in alcuni casi vediamo la CPU aumentare fino al 120%, il processo sta raccogliendo oggetti relativi alle richieste gestite.
Lo vediamo correlato nel grafico della memoria. La linea continua nel grafico Memoria è la metrica Heap Used. Ogni volta che c'è un picco nella CPU, vediamo una caduta nella riga Heap Used, che mostra che la memoria viene deallocata.
Gli handle attivi non sono influenzati dal ritardo del ciclo di eventi. Un handle attivo è un oggetto che rappresenta l'I/O (ad esempio un socket o un handle di file) o un timer (ad esempio un setInterval ). Abbiamo incaricato AutoCannon di aprire 100 connessioni ( -c100 ). Gli handle attivi rimangono un conteggio coerente di 103. Gli altri tre sono handle per STDOUT, STDERR e l'handle per il server stesso.
Se facciamo clic sul pannello Consigli nella parte inferiore dello schermo, dovremmo vedere qualcosa di simile al seguente:
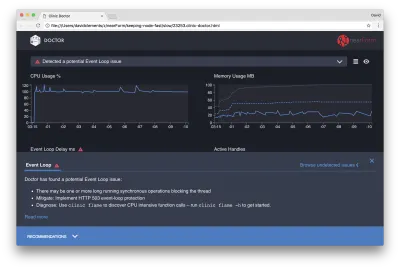
Mitigazione a breve termine
L'analisi della causa principale di gravi problemi di prestazioni può richiedere tempo. Nel caso di un progetto distribuito in tempo reale, vale la pena aggiungere la protezione da sovraccarico a server o servizi. L'idea della protezione da sovraccarico è monitorare il ritardo del loop di eventi (tra le altre cose) e rispondere con "503 Servizio non disponibile" se viene superata una soglia. Ciò consente a un sistema di bilanciamento del carico di eseguire il failover su altre istanze o, nel peggiore dei casi, significa che gli utenti dovranno aggiornare. Il modulo di protezione da sovraccarico può fornire questo con un sovraccarico minimo per Express, Koa e Restify. Il framework Hapi ha un'impostazione di configurazione del carico che fornisce la stessa protezione.
Comprendere l'area problematica
Come spiega la breve spiegazione in Clinic Doctor, se l'Event Loop è ritardato al livello che stiamo osservando è molto probabile che una o più funzioni stiano “bloccando” l'Event Loop.
È particolarmente importante con Node.js riconoscere questa caratteristica JavaScript primaria: gli eventi asincroni non possono verificarsi fino al completamento del codice in esecuzione.
Questo è il motivo per cui un setTimeout non può essere preciso.
Ad esempio, prova a eseguire quanto segue in DevTools di un browser o Node REPL:
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() La misurazione del tempo risultante non sarà mai 100 ms. Sarà probabilmente nell'intervallo da 150 ms a 250 ms. Il setTimeout ha pianificato un'operazione asincrona ( console.timeEnd ), ma il codice attualmente in esecuzione non è stato ancora completato; ci sono altre due righe. Il codice attualmente in esecuzione è noto come "tick" corrente. Per completare il segno di spunta, Math.random deve essere chiamato dieci milioni di volte. Se ciò richiede 100 ms, il tempo totale prima che il timeout si risolva sarà di 200 ms (più il tempo impiegato dalla funzione setTimeout per accodare effettivamente il timeout in anticipo, di solito un paio di millisecondi).
In un contesto lato server, se un'operazione nel tick corrente impiega molto tempo per completare le richieste non può essere gestita e il recupero dei dati non può avvenire perché il codice asincrono non verrà eseguito fino al completamento del tick corrente. Ciò significa che il codice computazionalmente costoso rallenterà tutte le interazioni con il server. Quindi si consiglia di suddividere il lavoro ad alta intensità di risorse in processi separati e chiamarli dal server principale, questo eviterà casi in cui su percorsi usati raramente ma costosi rallentano le prestazioni di altri percorsi usati frequentemente ma poco costosi.
Il server di esempio ha del codice che blocca il ciclo di eventi, quindi il passaggio successivo consiste nell'individuare quel codice.
Analizzando
Un modo per identificare rapidamente il codice con prestazioni scadenti consiste nel creare e analizzare un grafico di fiamma. Un grafico a fiamma rappresenta le chiamate di funzione come blocchi uno sopra l'altro, non nel tempo ma in modo aggregato. Il motivo per cui è chiamato "grafico a fiamma" è perché in genere utilizza uno schema di colori da arancione a rosso, dove più un blocco è rosso, più "calda" è una funzione, il che significa che più è probabile che blocchi il ciclo degli eventi. L'acquisizione dei dati per un grafico di fiamma viene eseguita tramite il campionamento della CPU, il che significa che viene acquisita un'istantanea della funzione attualmente in esecuzione e del suo stack. Il calore è determinato dalla percentuale di tempo durante il quale una determinata funzione si trova in cima allo stack (ad esempio la funzione attualmente in esecuzione) per ciascun campione. Se non è l'ultima funzione ad essere mai chiamata all'interno di quello stack, è probabile che stia bloccando il ciclo di eventi.
Usiamo la clinic flame per generare un grafico di fiamma dell'applicazione di esempio:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsIl risultato dovrebbe aprirsi nel nostro browser con qualcosa di simile al seguente:
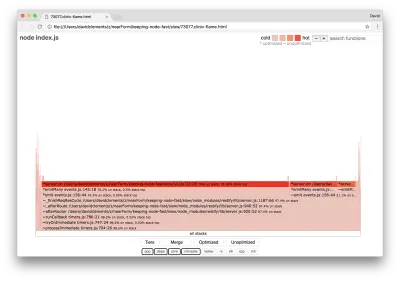
La larghezza di un blocco rappresenta quanto tempo ha speso complessivamente sulla CPU. Si possono osservare tre stack principali che occupano più tempo, tutti evidenziando server.on come la funzione più attiva. In verità, tutti e tre gli stack sono gli stessi. Divergono perché durante la profilazione le funzioni ottimizzate e non ottimizzate vengono trattate come frame di chiamata separati. Le funzioni con il prefisso * sono ottimizzate dal motore JavaScript e quelle con il prefisso ~ non sono ottimizzate. Se lo stato ottimizzato non è importante per noi, possiamo semplificare ulteriormente il grafico premendo il pulsante Unisci. Questo dovrebbe portare a una visualizzazione simile alla seguente:
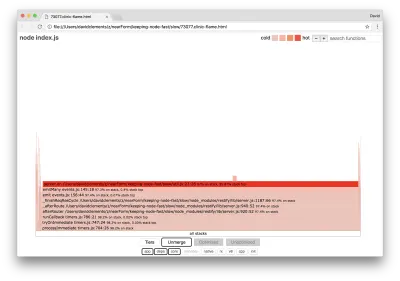
Fin dall'inizio, possiamo dedurre che il codice incriminato è nel file util.js del codice dell'applicazione.
La funzione slow è anche un gestore di eventi: le funzioni che portano alla funzione fanno parte del modulo events di base e server.on è un nome di fallback per una funzione anonima fornita come funzione di gestione degli eventi. Possiamo anche vedere che questo codice non è nello stesso segno di spunta del codice che gestisce effettivamente la richiesta. Se lo fosse, le funzioni dei moduli principali http , net e stream sarebbero nello stack.
Tali funzioni principali possono essere trovate espandendo altre parti, molto più piccole, del grafico della fiamma. Ad esempio, prova a utilizzare l'input di ricerca in alto a destra dell'interfaccia utente per cercare send (il nome di entrambi i metodi interni, restify e http ). Dovrebbe essere a destra del grafico (le funzioni sono ordinate alfabeticamente):
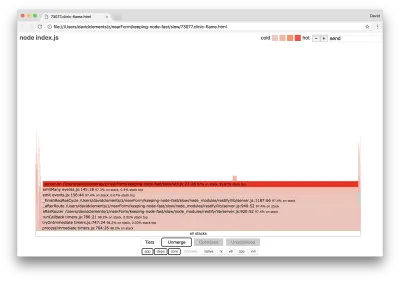
Si noti quanto siano relativamente piccoli tutti i blocchi di gestione HTTP effettivi.

Possiamo fare clic su uno dei blocchi evidenziati in ciano che si espanderà per mostrare funzioni come writeHead e write nel file http_outgoing.js (parte della libreria http di Node core):
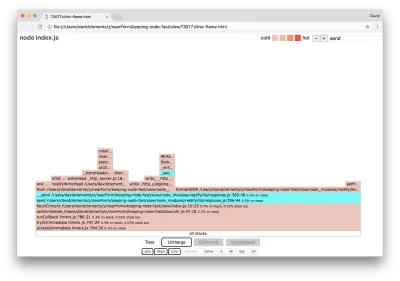
Possiamo fare clic su tutte le pile per tornare alla vista principale.
Il punto chiave qui è che anche se la funzione server.on non è nello stesso tick del codice di gestione delle richieste effettivo, sta comunque influenzando le prestazioni complessive del server ritardando l'esecuzione di codice altrimenti performante.
Debug
Sappiamo dal grafico della fiamma che la funzione problematica è il gestore di eventi passato a server.on nel file util.js.
Diamo un'occhiata:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) È risaputo che la crittografia tende ad essere costosa, così come la serializzazione ( JSON.stringify ) ma perché non compaiono nel grafico della fiamma? Queste operazioni sono nei campioni acquisiti, ma sono nascoste dietro il filtro cpp . Se premiamo il pulsante cpp dovremmo vedere qualcosa di simile al seguente:
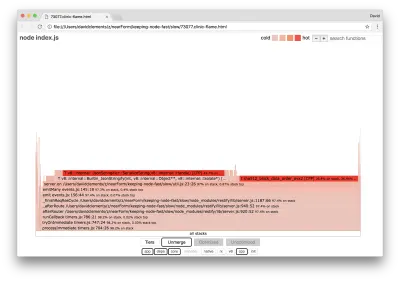
Le istruzioni V8 interne relative sia alla serializzazione che alla crittografia sono ora mostrate come gli stack più caldi e occupano la maggior parte del tempo. Il metodo JSON.stringify chiama direttamente il codice C++; questo è il motivo per cui non vediamo una funzione JavaScript. Nel caso della crittografia, funzioni come createHash e update sono nei dati, ma sono in linea (il che significa che scompaiono nella vista unita) o troppo piccole per essere renderizzate.
Una volta che iniziamo a ragionare sul codice nella funzione etagger , può rapidamente diventare evidente che è mal progettato. Perché stiamo prendendo l'istanza del server dal contesto della funzione? C'è un sacco di hashing in corso, è tutto necessario? Inoltre, nell'implementazione non è disponibile il supporto dell'intestazione If-None-Match che mitigherebbe parte del carico in alcuni scenari del mondo reale perché i client farebbero solo una richiesta principale per determinare l'aggiornamento.
Ignoriamo tutti questi punti per il momento e convalidiamo la scoperta che il lavoro effettivo svolto in server.on è davvero il collo di bottiglia. Ciò può essere ottenuto impostando il codice server.on su una funzione vuota e generando un nuovo flamegraph.
Modificare la funzione etagger come segue:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } La funzione del listener di eventi passata a server.on ora non è operativa.
Eseguiamo di nuovo la clinic flame :
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsQuesto dovrebbe produrre un grafico di fiamma simile al seguente:
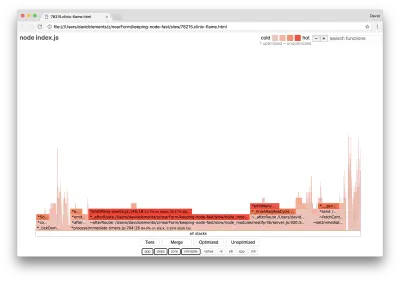
Sembra migliore e avremmo dovuto notare un aumento della richiesta al secondo. Ma perché il codice di emissione dell'evento è così caldo? Ci aspetteremmo a questo punto che il codice di elaborazione HTTP occupi la maggior parte del tempo della CPU, non c'è nulla in esecuzione nell'evento server.on .
Questo tipo di collo di bottiglia è causato da una funzione eseguita più di quanto dovrebbe essere.
Il seguente codice sospetto nella parte superiore di util.js potrebbe essere un indizio:
require('events').defaultMaxListeners = Infinity Rimuoviamo questa riga e iniziamo il nostro processo con il --trace-warnings :
node --trace-warnings index.jsSe eseguiamo il profilo con AutoCannon in un altro terminale, in questo modo:
autocannon -c100 localhost:3000/seed/v1Il nostro processo produrrà qualcosa di simile a:
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Node ci dice che molti eventi vengono collegati all'oggetto server . Questo è strano perché c'è un booleano che controlla se l'evento è stato allegato e quindi ritorna in anticipo, essenzialmente rendendo attachAfterEvent un no-op dopo che il primo evento è stato allegato.
Diamo un'occhiata alla funzione attachAfterEvent :
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } Il controllo condizionale è sbagliato! Verifica se attachAfterEvent è true invece di afterEventAttached . Ciò significa che un nuovo evento viene allegato all'istanza del server su ogni richiesta e quindi tutti gli eventi allegati precedenti vengono attivati dopo ogni richiesta. Ops!
Ottimizzazione
Ora che abbiamo scoperto le aree problematiche, vediamo se possiamo rendere il server più veloce.
Frutto basso
Reinseriamo il codice del listener server.on (invece di una funzione vuota) e utilizziamo il nome booleano corretto nel controllo condizionale. La nostra funzione etagger il seguente aspetto:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }Ora controlliamo la nostra correzione profilando di nuovo. Avvia il server in un terminale:
node index.jsQuindi profila con AutoCannon:
autocannon -c100 localhost:3000/seed/v1 Dovremmo vedere risultati da qualche parte nell'intervallo di un miglioramento di 200 volte (esecuzione del test di 10 secondi @ https://localhost:3000/seed/v1 — 100 connessioni):
| statistica | media | Stdev | Massimo |
|---|---|---|---|
| Latenza (ms) | 19.47 | 4.29 | 103 |
| Richiesto/Sec | 5011.11 | 506.2 | 5487 |
| Byte/Sec | 51,8 MB | 5,45 MB | 58,72 MB |
È importante bilanciare le potenziali riduzioni dei costi del server con i costi di sviluppo. Dobbiamo definire, nei nostri contesti situazionali, fino a che punto dobbiamo spingerci per ottimizzare un progetto. Altrimenti, può essere fin troppo facile dedicare l'80% dello sforzo al 20% dei miglioramenti della velocità. I vincoli del progetto lo giustificano?
In alcuni scenari, potrebbe essere appropriato ottenere un miglioramento di 200 volte con un frutto che pende basso e chiamarlo un giorno. In altri, potremmo voler rendere la nostra implementazione il più veloce possibile. Dipende molto dalle priorità del progetto.
Un modo per controllare la spesa delle risorse è fissare un obiettivo. Ad esempio, 10 volte il miglioramento o 4000 richieste al secondo. Basare questo sulle esigenze aziendali ha più senso. Ad esempio, se i costi del server superano il budget del 100%, possiamo fissare un obiettivo di miglioramento 2x.
Portarlo oltre
Se produciamo un nuovo grafico di fiamma del nostro server, dovremmo vedere qualcosa di simile al seguente:
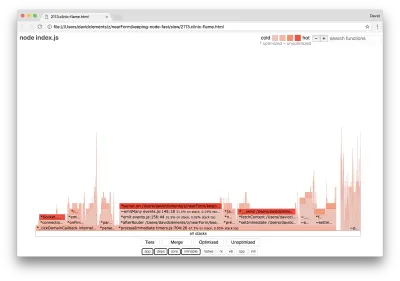
L'event listener è ancora il collo di bottiglia, occupa ancora un terzo del tempo della CPU durante la profilazione (la larghezza è di circa un terzo dell'intero grafico).
Quali vantaggi aggiuntivi si possono ottenere e vale la pena apportare le modifiche (insieme alle interruzioni associate)?
Con un'implementazione ottimizzata, che è comunque leggermente più vincolata, è possibile ottenere le seguenti caratteristiche prestazionali (esecuzione di 10s test @ https://localhost:3000/seed/v1 — 10 connessioni):
| statistica | media | Stdev | Massimo |
|---|---|---|---|
| Latenza (ms) | 0,64 | 0,86 | 17 |
| Richiesto/Sec | 8330.91 | 757.63 | 8991 |
| Byte/Sec | 84,17 MB | 7,64 MB | 92,27 MB |
Sebbene un miglioramento di 1,6 volte sia significativo, è discutibile se lo sforzo, le modifiche e l'interruzione del codice necessari per creare questo miglioramento dipendono dalla situazione. Soprattutto se confrontato con il miglioramento di 200 volte dell'implementazione originale con una singola correzione di bug.
Per ottenere questo miglioramento, è stata utilizzata la stessa tecnica iterativa di profilo, generazione flamegraph, analisi, debug e ottimizzazione per arrivare al server ottimizzato finale, il cui codice può essere trovato qui.
Le modifiche finali per raggiungere 8000 req/s sono state:
- Non creare oggetti e quindi serializzare, creare direttamente una stringa di JSON;
- Usa qualcosa di unico nel contenuto per definire il suo Etag, piuttosto che creare un hash;
- Non eseguire l'hashing dell'URL, utilizzalo direttamente come chiave.
Queste modifiche sono leggermente più coinvolte, un po' più dirompenti per la base di codice e lasciano il middleware etagger un po' meno flessibile perché grava sul percorso di fornire il valore Etag . Ma raggiunge 3000 richieste in più al secondo sulla macchina di profilatura.
Diamo un'occhiata a un grafico a fiamma per questi miglioramenti finali:
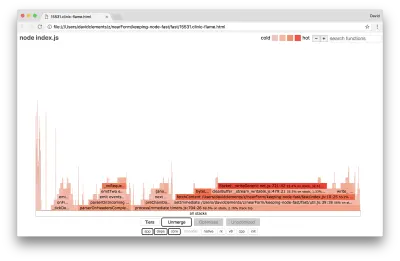
La parte più calda del grafico della fiamma fa parte del Node core, nel modulo net . Questo è l'ideale.
Prevenire i problemi di prestazioni
Per concludere, ecco alcuni suggerimenti su come prevenire problemi di prestazioni prima che vengano distribuiti.
L'utilizzo di strumenti per le prestazioni come punti di controllo informali durante lo sviluppo può filtrare i bug delle prestazioni prima che entrino in produzione. Si consiglia di rendere AutoCannon e Clinic (o equivalenti) parte degli strumenti di sviluppo quotidiano.
Quando acquisti in un framework, scopri qual è la sua politica sulle prestazioni. Se il framework non dà priorità alle prestazioni, è importante verificare se ciò è in linea con le pratiche infrastrutturali e gli obiettivi aziendali. Ad esempio, Restify ha chiaramente (dal rilascio della versione 7) investito nel miglioramento delle prestazioni della libreria. Tuttavia, se il basso costo e l'alta velocità sono una priorità assoluta, considera Fastify che è stato misurato come il 17% più veloce da un collaboratore di Restify.
Fai attenzione ad altre scelte di libreria di grande impatto, in particolare considera la registrazione. Man mano che gli sviluppatori risolvono i problemi, possono decidere di aggiungere output di log aggiuntivo per aiutare a eseguire il debug dei problemi correlati in futuro. Se viene utilizzato un taglialegna poco performante, questo può strangolare le prestazioni nel tempo alla moda della favola della rana bollente. Il pino logger è il logger JSON delimitato da una nuova riga più veloce disponibile per Node.js.
Infine, ricorda sempre che l'Event Loop è una risorsa condivisa. Un server Node.js è in definitiva vincolato dalla logica più lenta nel percorso più caldo.