
Inizia con Node: Introduzione alle API, HTTP e JavaScript ES6+
Pubblicato: 2022-03-10Probabilmente hai sentito parlare di Node.js come di un "runtime JavaScript asincrono basato sul motore JavaScript V8 di Chrome" e che "utilizza un modello I/O non bloccante basato su eventi che lo rende leggero ed efficiente". Ma per alcuni, questa non è la migliore delle spiegazioni.
Che cos'è Node in primo luogo? Cosa significa esattamente per Node essere "asincrono" e in che cosa differisce da "sincrono"? Qual è il significato di "guidato da eventi" e "non bloccante" in ogni caso, e come si inserisce Node nel quadro più ampio di applicazioni, reti Internet e server?
Cercheremo di rispondere a tutte queste domande e altre ancora durante questa serie mentre esamineremo in modo approfondito il funzionamento interno di Node, impareremo il protocollo di trasferimento HyperText, le API e JSON e creeremo la nostra API Bookshelf utilizzando MongoDB, Express, Lodash, Mocha e Manubri.
Che cos'è Node.js
Node è solo un ambiente, o runtime, all'interno del quale eseguire il normale JavaScript (con piccole differenze) al di fuori del browser. Possiamo usarlo per creare applicazioni desktop (con framework come Electron), scrivere server Web o app e altro ancora.
Bloccante/non bloccante e sincrono/asincrono
Supponiamo di effettuare una chiamata al database per recuperare le proprietà di un utente. Quella chiamata richiederà tempo e, se la richiesta è "bloccante", significa che bloccherà l'esecuzione del nostro programma fino al completamento della chiamata. In questo caso, abbiamo fatto una richiesta "sincrona" poiché ha finito per bloccare il thread.
Pertanto, un'operazione sincrona blocca un processo o un thread fino al completamento dell'operazione, lasciando il thread in uno "stato di attesa". Un'operazione asincrona , invece, non è bloccante . Consente l'esecuzione del thread indipendentemente dal tempo necessario per il completamento dell'operazione o dal risultato con cui viene completata e nessuna parte del thread entra in uno stato di attesa in nessun momento.
Diamo un'occhiata a un altro esempio di chiamata sincrona che blocca un thread. Supponiamo di creare un'applicazione che confronti i risultati di due API meteo per trovare la loro differenza percentuale di temperatura. In modo bloccante, chiamiamo Weather API One e attendiamo il risultato. Una volta ottenuto un risultato, chiamiamo Weather API Two e attendiamo il suo risultato. Non preoccuparti a questo punto se non hai familiarità con le API. Li tratteremo in una prossima sezione. Per ora, pensa a un'API come al mezzo attraverso il quale due computer possono comunicare tra loro.
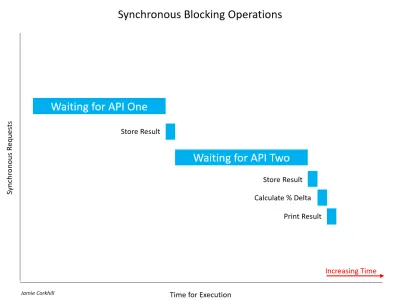
Consentitemi di notare, è importante riconoscere che non tutte le chiamate sincrone stanno necessariamente bloccando. Se un'operazione sincrona riesce a completare senza bloccare il thread o causare uno stato di attesa, non era bloccante. Nella maggior parte dei casi, le chiamate sincrone si bloccheranno e il tempo necessario per il completamento dipenderà da una varietà di fattori, come la velocità dei server dell'API, la velocità di download della connessione Internet dell'utente finale, ecc.
Nel caso dell'immagine sopra, abbiamo dovuto aspettare un bel po' per recuperare i primi risultati da API One. Successivamente, abbiamo dovuto aspettare altrettanto a lungo per ottenere una risposta da API Two. Durante l'attesa di entrambe le risposte, l'utente noterebbe che la nostra applicazione si blocca - l'interfaccia utente si bloccherebbe letteralmente - e ciò sarebbe negativo per l'esperienza utente.
Nel caso di una chiamata non bloccante, avremmo qualcosa del genere:

Puoi vedere chiaramente quanto più velocemente abbiamo concluso l'esecuzione. Piuttosto che attendere su API One e poi attendere su API Two, potremmo aspettare che entrambi si completino contemporaneamente e raggiungano i nostri risultati quasi il 50% più velocemente. Nota, una volta che abbiamo chiamato API One e abbiamo iniziato ad aspettare la sua risposta, abbiamo chiamato anche API Two e abbiamo iniziato ad aspettare la sua risposta contemporaneamente a One.
A questo punto, prima di passare ad esempi più concreti e tangibili, è importante ricordare che, per comodità, il termine “sincrono” è generalmente abbreviato in “sincrono”, e il termine “asincrono” è generalmente abbreviato in “asincrono”. Vedrai questa notazione usata nei nomi di metodi/funzioni.
Funzioni di richiamata
Ti starai chiedendo: "se siamo in grado di gestire una chiamata in modo asincrono, come facciamo a sapere quando quella chiamata è terminata e abbiamo una risposta?" In genere, passiamo come argomento al nostro metodo asincrono una funzione di callback e quel metodo "richiama" quella funzione in un secondo momento con una risposta. Sto usando le funzioni ES5 qui, ma aggiorneremo gli standard ES6 in seguito.
function asyncAddFunction(a, b, callback) { callback(a + b); //This callback is the one passed in to the function call below. } asyncAddFunction(2, 4, function(sum) { //Here we have the sum, 2 + 4 = 6. }); Tale funzione è chiamata "Funzione di ordine superiore" poiché accetta una funzione (il nostro callback) come argomento. In alternativa, una funzione di callback potrebbe accettare un oggetto di errore e un oggetto di risposta come argomenti e presentarli quando la funzione asincrona è completa. Lo vedremo più avanti con Express. Quando abbiamo chiamato asyncAddFunction(...) , noterai che abbiamo fornito una funzione di callback per il parametro di callback dalla definizione del metodo. Questa funzione è una funzione anonima (non ha un nome) e viene scritta utilizzando la sintassi dell'espressione . La definizione del metodo, d'altra parte, è un'istruzione di funzione. Non è anonimo perché in realtà ha un nome (che è "asyncAddFunction").
Alcuni potrebbero notare confusione poiché, nella definizione del metodo, forniamo un nome, ovvero "richiamata". Tuttavia, la funzione anonima passata come terzo parametro ad asyncAddFunction(...) non conosce il nome e quindi rimane anonima. Inoltre, non possiamo eseguire quella funzione in un secondo momento per nome, dovremmo ripetere la funzione di chiamata asincrona per attivarla.
Come esempio di chiamata sincrona, possiamo utilizzare il metodo readFileSync(...) di Node.js. Ancora una volta, ci sposteremo a ES6+ in seguito.
var fs = require('fs'); var data = fs.readFileSync('/example.txt'); // The thread will be blocked here until complete.Se lo facessimo in modo asincrono, passeremmo una funzione di callback che si attiverebbe al termine dell'operazione asincrona.
var fs = require('fs'); var data = fs.readFile('/example.txt', function(err, data) { //Move on, this will fire when ready. if(err) return console.log('Error: ', err); console.log('Data: ', data); // Assume var data is defined above. }); // Keep executing below, don't wait on the data. Se non hai mai visto return usato in quel modo prima, stiamo solo dicendo di interrompere l'esecuzione della funzione in modo da non stampare l'oggetto dati se l'oggetto errore è definito. Avremmo anche potuto semplicemente racchiudere l'istruzione log in una clausola else .
Come il nostro asyncAddFunction(...) , il codice dietro la fs.readFile(...) sarebbe qualcosa sulla falsariga di:
function readFile(path, callback) { // Behind the scenes code to read a file stream. // The data variable is defined up here. callback(undefined, data); //Or, callback(err, undefined); }Consentici di esaminare un'ultima implementazione di una chiamata di funzione asincrona. Questo aiuterà a consolidare l'idea che le funzioni di callback vengano attivate in un secondo momento e ci aiuterà a comprendere l'esecuzione di un tipico programma Node.js.
setTimeout(function() { // ... }, 1000); Il metodo setTimeout(...) accetta una funzione di callback per il primo parametro che verrà attivato dopo che si è verificato il numero di millisecondi specificato come secondo argomento.
Vediamo un esempio più complesso:
console.log('Initiated program.'); setTimeout(function() { console.log('3000 ms (3 sec) have passed.'); }, 3000); setTimeout(function() { console.log('0 ms (0 sec) have passed.'); }, 0); setTimeout(function() { console.log('1000 ms (1 sec) has passed.'); }, 1000); console.log('Terminated program');L'output che riceviamo è:
Initiated program. Terminated program. 0 ms (0 sec) have passed. 1000 ms (1 sec) has passed. 3000 ms (3 sec) have passed. Puoi vedere che la prima istruzione di log viene eseguita come previsto. Immediatamente, l'ultima istruzione di registro viene stampata sullo schermo, poiché ciò accade prima che 0 secondi siano superati dopo il secondo setTimeout(...) . Subito dopo, vengono eseguiti il secondo, il terzo e il primo metodo setTimeout(...) .
Se Node.js non fosse non bloccante, vedremmo la prima istruzione di log, attenderemo 3 secondi per vedere la successiva, vedremmo istantaneamente la terza (il 0-second setTimeout(...) , quindi dovremo attendere un altro secondo per vedere le ultime due istruzioni di registro. La natura non bloccante di Node fa sì che tutti i timer inizino il conto alla rovescia dal momento in cui il programma viene eseguito, piuttosto che dall'ordine in cui sono digitati. Potresti voler esaminare le API di Node, il Callstack e Event Loop per ulteriori informazioni su come funziona Node sotto il cofano.
È importante notare che solo perché viene visualizzata una funzione di callback non significa necessariamente che sia presente una chiamata asincrona nel codice. Abbiamo chiamato il asyncAddFunction(…) sopra "async" perché presupponiamo che l'operazione richieda tempo per essere completata, ad esempio effettuare una chiamata a un server. In realtà, il processo di aggiunta di due numeri non è asincrono, quindi sarebbe effettivamente un esempio di utilizzo di una funzione di callback in un modo che non blocca effettivamente il thread.
Promesse sulle richiamate
I callback possono diventare rapidamente disordinati in JavaScript, in particolare i callback multipli nidificati. Abbiamo familiarità con il passaggio di un callback come argomento a una funzione, ma Promises ci consente di aggiungere o allegare un callback a un oggetto restituito da una funzione. Ciò ci consentirebbe di gestire più chiamate asincrone in un modo più elegante.
Ad esempio, supponiamo di fare una chiamata API e la nostra funzione, non denominata in modo univoco ' makeAPICall(...) ', accetta un URL e un callback.
La nostra funzione, makeAPICall(...) , sarebbe definita come
function makeAPICall(path, callback) { // Attempt to make API call to path argument. // ... callback(undefined, res); // Or, callback(err, undefined); depending upon the API's response. }e lo chiameremmo con:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); // ... }); Se volessimo effettuare un'altra chiamata API utilizzando la risposta della prima, dovremmo annidare entrambi i callback. Supponiamo di dover inserire la proprietà userName dall'oggetto res1 nel percorso della seconda chiamata API. Noi avremmo:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); makeAPICall('/newExample/' + res1.userName, function(err2, res2) { if(err2) return console.log('Error: ', err2); console.log(res2); }); }); Nota : il metodo ES6+ per inserire la proprietà res1.userName anziché la concatenazione di stringhe consiste nell'usare "Template Strings". In questo modo, invece di incapsulare la nostra stringa tra virgolette ( ' , o " ), useremmo i backtick ( ` ). che si trovano sotto il tasto Esc sulla tastiera. Quindi, useremmo la notazione ${} per incorporare qualsiasi espressione JS all'interno le parentesi. Alla fine, il nostro percorso precedente sarebbe: /newExample/${res.UserName} , racchiuso in backtick.
È chiaro che questo metodo di annidamento dei callback può diventare rapidamente abbastanza inelegante, la cosiddetta "Piramide del destino di JavaScript". Saltando, se stessimo usando le promesse piuttosto che i callback, potremmo rifattorizzare il nostro codice dal primo esempio in quanto tale:
makeAPICall('/example').then(function(res) { // Success callback. // ... }, function(err) { // Failure callback. console.log('Error:', err); }); Il primo argomento della funzione then() è il nostro callback di successo e il secondo argomento è il nostro callback di errore. In alternativa, potremmo perdere il secondo argomento in .then() e chiamare invece .catch() . Gli argomenti per .then() sono facoltativi e chiamare .catch() sarebbe equivalente a .then(successCallback, null) .
Usando .catch() , abbiamo:
makeAPICall('/example').then(function(res) { // Success callback. // ... }).catch(function(err) { // Failure Callback console.log('Error: ', err); });Possiamo anche ristrutturare questo per la leggibilità:
makeAPICall('/example') .then(function(res) { // ... }) .catch(function(err) { console.log('Error: ', err); }); È importante notare che non possiamo semplicemente aggiungere una chiamata .then() a qualsiasi funzione e aspettarci che funzioni. La funzione che stiamo chiamando deve effettivamente restituire una promessa, una promessa che attiverà .then() al termine dell'operazione asincrona. In questo caso, makeAPICall(...) farà il suo dovere, attivando il blocco then() o il blocco catch() una volta completato.
Per fare in modo che makeAPICall(...) restituisca una Promise, assegniamo una funzione a una variabile, dove quella funzione è il costruttore Promise. Le promesse possono essere mantenute o rifiutate , dove adempiute significa che l'azione relativa alla promessa è stata completata con successo, e rifiutate significa il contrario. Una volta che la promessa è stata rispettata o rifiutata, diciamo che è stata saldata , e nell'attesa che si stabilisca, magari durante una chiamata asincrona, diciamo che la promessa è in sospeso .
Il costruttore Promise accetta una funzione di callback come argomento, che riceve due parametri: resolve e reject , che chiameremo in un secondo momento per attivare il callback di successo in .then() o l' .then() callback o .catch() , se fornito.
Ecco un esempio di come appare:
var examplePromise = new Promise(function(resolve, reject) { // Do whatever we are going to do and then make the appropiate call below: resolve('Happy!'); // — Everything worked. reject('Sad!'); // — We noticed that something went wrong. }):Quindi, possiamo usare:
examplePromise.then(/* Both callback functions in here */); // Or, the success callback in .then() and the failure callback in .catch(). Si noti, tuttavia, che examplePromise non può accettare argomenti. Questo tipo di vanifica lo scopo, quindi possiamo invece restituire una promessa.
function makeAPICall(path) { return new Promise(function(resolve, reject) { // Make our async API call here. if (/* All is good */) return resolve(res); //res is the response, would be defined above. else return reject(err); //err is error, would be defined above. }); } Le promesse brillano davvero per migliorare la struttura, e successivamente, l'eleganza, del nostro codice con il concetto di “Promise Chaining”. Ciò ci consentirebbe di restituire una nuova Promise all'interno di una clausola .then() , quindi potremmo allegare un secondo .then() seguito, che attiverebbe il callback appropriato dalla seconda promessa.
Refactoring della nostra chiamata URL multi API sopra con Promise, otteniamo:
makeAPICall('/example').then(function(res) { // First response callback. Fires on success to '/example' call. return makeAPICall(`/newExample/${res.UserName}`); // Returning new call allows for Promise Chaining. }, function(err) { // First failure callback. Fires if there is a failure calling with '/example'. console.log('Error:', err); }).then(function(res) { // Second response callback. Fires on success to returned '/newExample/...' call. console.log(res); }, function(err) { // Second failure callback. Fire if there is a failure calling with '/newExample/...' console.log('Error:', err); }); Si noti che prima chiamiamo makeAPICall('/example') . Ciò restituisce una promessa, quindi alleghiamo un .then() . All'interno di quello then() , restituiamo una nuova chiamata a makeAPICall(...) , che, di per sé, come visto in precedenza, restituisce una promessa, permettendoci di concatenare un nuovo .then() dopo il primo.
Come sopra, possiamo ristrutturarlo per renderlo leggibile e rimuovere i callback di errore per una generica clausola catch() all. Quindi, possiamo seguire il principio DRY (non ripetere te stesso) e implementare la gestione degli errori solo una volta.
makeAPICall('/example') .then(function(res) { // Like earlier, fires with success and response from '/example'. return makeAPICall(`/newExample/${res.UserName}`); // Returning here lets us chain on a new .then(). }) .then(function(res) { // Like earlier, fires with success and response from '/newExample'. console.log(res); }) .catch(function(err) { // Generic catch all method. Fires if there is an err with either earlier call. console.log('Error: ', err); }); Si noti che i callback di successo e fallimento in .then() si attivano solo per lo stato della singola Promise a cui corrisponde .then() . Il blocco catch , tuttavia, rileverà tutti gli errori che si attivano in uno qualsiasi dei .then() .
ES6 Cost vs Let
In tutti i nostri esempi, abbiamo utilizzato le funzioni ES5 e la vecchia parola chiave var . Sebbene milioni di righe di codice vengano ancora eseguite oggi utilizzando quei metodi ES5, è utile aggiornare agli attuali standard ES6+ e faremo il refactoring di parte del nostro codice sopra. Iniziamo con const e let .
Potresti essere abituato a dichiarare una variabile con la parola chiave var :
var pi = 3.14;Con gli standard ES6+, potremmo farlo anche noi
let pi = 3.14;o
const pi = 3.14; dove const significa "costante", un valore che non può essere riassegnato in seguito. (Ad eccezione delle proprietà degli oggetti, ne parleremo presto. Inoltre, le variabili dichiarate const non sono immutabili, lo è solo il riferimento alla variabile.)
Nel vecchio JavaScript, blocca gli ambiti, come quelli in if , while , {} . for , ecc. non ha influenzato in alcun modo var , e questo è abbastanza diverso da linguaggi tipizzati più staticamente come Java o C++. Cioè, l'ambito di var è l'intera funzione di inclusione — e potrebbe essere globale (se posizionato all'esterno di una funzione) o locale (se posizionato all'interno di una funzione). Per dimostrarlo, vedere il seguente esempio:
function myFunction() { var num = 5; console.log(num); // 5 console.log('--'); for(var i = 0; i < 10; i++) { var num = i; console.log(num); //num becomes 0 — 9 } console.log('--'); console.log(num); // 9 console.log(i); // 10 } myFunction();Produzione:
5 --- 0 1 2 3 ... 7 8 9 --- 9 10 La cosa importante da notare qui è che la definizione di una nuova var num all'interno dell'ambito for ha influenzato direttamente la var num all'esterno e al di sopra di for . Questo perché l'ambito di var è sempre quello della funzione di inclusione e non un blocco.
Ancora una volta, per impostazione predefinita, var i inside for() ha come valore predefinito l'ambito di myFunction , quindi possiamo accedere a i fuori dal ciclo e ottenere 10.
In termini di assegnazione di valori alle variabili, let è equivalente a var , è solo che let ha lo scope block e quindi le anomalie che si sono verificate con var sopra non si verificheranno.
function myFunction() { let num = 5; console.log(num); // 5 for(let i = 0; i < 10; i++) { let num = i; console.log('--'); console.log(num); // num becomes 0 — 9 } console.log('--'); console.log(num); // 5 console.log(i); // undefined, ReferenceError } Osservando la parola chiave const , puoi vedere che otteniamo un errore se proviamo a riassegnarla:
const c = 299792458; // Fact: The constant "c" is the speed of light in a vacuum in meters per second. c = 10; // TypeError: Assignment to constant variable. Le cose diventano interessanti quando assegniamo una variabile const a un oggetto:
const myObject = { name: 'Jane Doe' }; // This is illegal: TypeError: Assignment to constant variable. myObject = { name: 'John Doe' }; // This is legal. console.log(myObject.name) -> John Doe myObject.name = 'John Doe'; Come puoi vedere, solo il riferimento in memoria all'oggetto assegnato a un oggetto const è immutabile, non il valore stesso.
Funzioni della freccia ES6
Potresti essere abituato a creare una funzione come questa:
function printHelloWorld() { console.log('Hello, World!'); }Con le funzioni freccia, ciò diventerebbe:
const printHelloWorld = () => { console.log('Hello, World!'); };Supponiamo di avere una semplice funzione che restituisce il quadrato di un numero:
const squareNumber = (x) => { return x * x; } squareNumber(5); // We can call an arrow function like an ES5 functions. Returns 25.Puoi vedere che, proprio come con le funzioni ES5, possiamo accettare argomenti con parentesi, possiamo usare normali istruzioni di ritorno e possiamo chiamare la funzione come qualsiasi altra.
È importante notare che, mentre le parentesi sono richieste se la nostra funzione non accetta argomenti (come con printHelloWorld() sopra), possiamo eliminare le parentesi se ne richiede solo uno, quindi la nostra precedente definizione del metodo squareNumber() può essere riscritta come:
const squareNumber = x => { // Notice we have dropped the parentheses for we only take in one argument. return x * x; }Il fatto che tu scelga di racchiudere un singolo argomento tra parentesi o meno è una questione di gusti personali e probabilmente vedrai gli sviluppatori utilizzare entrambi i metodi.
Infine, se vogliamo restituire implicitamente solo un'espressione, come con squareNumber(...) sopra, possiamo mettere l'istruzione return in linea con la firma del metodo:
const squareNumber = x => x * x;Questo è,
const test = (a, b, c) => expressionequivale a
const test = (a, b, c) => { return expression }Nota, quando usi la scorciatoia sopra per restituire implicitamente un oggetto, le cose diventano oscure. Cosa impedisce a JavaScript di credere che le parentesi all'interno delle quali ci viene richiesto di incapsulare il nostro oggetto non siano il nostro corpo di funzione? Per aggirare questo problema, avvolgiamo le parentesi dell'oggetto tra parentesi. Ciò consente esplicitamente a JavaScript di sapere che stiamo effettivamente restituendo un oggetto e non stiamo solo definendo un corpo.
const test = () => ({ pi: 3.14 }); // Spaces between brackets are a formality to make the code look cleaner.Per aiutare a consolidare il concetto di funzioni ES6, faremo il refactoring di parte del nostro codice precedente consentendoci di confrontare le differenze tra entrambe le notazioni.
asyncAddFunction(...) , dall'alto, potrebbe essere rifattorizzato da:
function asyncAddFunction(a, b, callback){ callback(a + b); }a:
const aysncAddFunction = (a, b, callback) => { callback(a + b); };o anche a:
const aysncAddFunction = (a, b, callback) => callback(a + b); // This will return callback(a + b).Quando si chiama la funzione, è possibile passare una funzione freccia per la richiamata:
asyncAddFunction(10, 12, sum => { // No parentheses because we only take one argument. console.log(sum); }È chiaro come questo metodo migliori la leggibilità del codice. Per mostrarti solo un caso, possiamo prendere il nostro vecchio esempio basato su ES5 Promise sopra e rifattorizzarlo per utilizzare le funzioni delle frecce.
makeAPICall('/example') .then(res => makeAPICall(`/newExample/${res.UserName}`)) .then(res => console.log(res)) .catch(err => console.log('Error: ', err)); Ora, ci sono alcuni avvertimenti con le funzioni delle frecce. Per uno, non si legano a this parola chiave. Supponiamo di avere il seguente oggetto:
const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Potresti aspettarti che una chiamata a Person.greeting() restituirà "Ciao. Mi chiamo John Doe". Invece, otteniamo: “Ciao. Il mio nome è indefinito". Questo perché le funzioni freccia non hanno this , e quindi il tentativo di utilizzarlo all'interno di una funzione freccia ha per impostazione predefinita this dell'ambito di inclusione e this ambito di inclusione dell'oggetto Person è window , nel browser o module.exports in Nodo.
Per dimostrarlo, se usiamo di nuovo lo stesso oggetto, ma impostiamo la proprietà name del globale this su qualcosa come 'Jane Doe', allora this.name nella funzione freccia restituisce 'Jane Doe', perché il globale this è all'interno del che racchiude l'ambito o è il padre dell'oggetto Person .
this.name = 'Jane Doe'; const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting(); // Hi. My name is Jane DoeQuesto è noto come "scoping lessicale" e possiamo aggirarlo usando la cosiddetta "sintassi breve", che è dove perdiamo i due punti e la freccia per rifattorizzare il nostro oggetto in quanto tale:
const Person = { name: 'John Doe', greeting() { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting() //Hi. My name is John Doe.Classi ES6
Sebbene JavaScript non abbia mai supportato le classi, puoi sempre emularle con oggetti come quelli sopra. EcmaScript 6 fornisce il supporto per le classi che utilizzano la class e le new parole chiave:
class Person { constructor(name) { this.name = name; } greeting() { console.log(`Hi. My name is ${this.name}.`); } } const person = new Person('John'); person.greeting(); // Hi. My name is John. La funzione di costruzione viene chiamata automaticamente quando si utilizza la new parola chiave, in cui possiamo passare argomenti per impostare inizialmente l'oggetto. Questo dovrebbe essere familiare a qualsiasi lettore che abbia esperienza con linguaggi di programmazione orientati agli oggetti tipizzati più staticamente come Java, C++ e C#.
Senza entrare troppo nel dettaglio dei concetti OOP, un altro paradigma di questo tipo è "ereditarietà", che consiste nel consentire a una classe di ereditare da un'altra. Una classe chiamata Car , ad esempio, sarà molto generale, conterrà metodi come "stop", "start", ecc., di cui hanno bisogno tutte le auto. Un sottoinsieme della classe chiamato SportsCar , quindi, potrebbe ereditare le operazioni fondamentali da Car e ignorare tutto ciò di cui ha bisogno personalizzato. Potremmo denotare una tale classe come segue:
class Car { constructor(licensePlateNumber) { this.licensePlateNumber = licensePlateNumber; } start() {} stop() {} getLicensePlate() { return this.licensePlateNumber; } // … } class SportsCar extends Car { constructor(engineRevCount, licensePlateNumber) { super(licensePlateNumber); // Pass licensePlateNumber up to the parent class. this.engineRevCount = engineRevCount; } start() { super.start(); } stop() { super.stop(); } getLicensePlate() { return super.getLicensePlate(); } getEngineRevCount() { return this.engineRevCount; } }fermare() {}class Car { constructor(licensePlateNumber) { this.licensePlateNumber = licensePlateNumber; } start() {} stop() {} getLicensePlate() { return this.licensePlateNumber; } // … } class SportsCar extends Car { constructor(engineRevCount, licensePlateNumber) { super(licensePlateNumber); // Pass licensePlateNumber up to the parent class. this.engineRevCount = engineRevCount; } start() { super.start(); } stop() { super.stop(); } getLicensePlate() { return super.getLicensePlate(); } getEngineRevCount() { return this.engineRevCount; } }fermare() {class Car { constructor(licensePlateNumber) { this.licensePlateNumber = licensePlateNumber; } start() {} stop() {} getLicensePlate() { return this.licensePlateNumber; } // … } class SportsCar extends Car { constructor(engineRevCount, licensePlateNumber) { super(licensePlateNumber); // Pass licensePlateNumber up to the parent class. this.engineRevCount = engineRevCount; } start() { super.start(); } stop() { super.stop(); } getLicensePlate() { return super.getLicensePlate(); } getEngineRevCount() { return this.engineRevCount; } }
Puoi vedere chiaramente che la parola chiave super ci consente di accedere a proprietà e metodi dalla classe genitore o super.
Eventi JavaScript
Un Evento è un'azione che si verifica a cui hai la possibilità di rispondere. Supponiamo che tu stia creando un modulo di accesso per la tua applicazione. Quando l'utente preme il pulsante "invia", puoi reagire a quell'evento tramite un "gestore di eventi" nel tuo codice, in genere una funzione. Quando questa funzione è definita come gestore di eventi, diciamo che stiamo "registrando un gestore di eventi". Il gestore dell'evento per il clic del pulsante di invio probabilmente controllerà la formattazione dell'input fornito dall'utente, lo sanificherà per prevenire attacchi come SQL Injection o Cross Site Scripting (tieni presente che nessun codice sul lato client può mai essere preso in considerazione Pulisci sempre i dati sul server, non fidarti mai di nulla dal browser), quindi controlla se la combinazione di nome utente e password esce all'interno di un database per autenticare un utente e fornire loro un token.
Poiché questo è un articolo su Node, ci concentreremo sul modello di eventi Node.
Possiamo utilizzare il modulo events di Node per emettere e reagire a eventi specifici. Qualsiasi oggetto che emette un evento è un'istanza della classe EventEmitter .
Possiamo emettere un evento chiamando il metodo emit() e ascoltiamo quell'evento tramite il metodo on() , entrambi esposti tramite la classe EventEmitter .
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); Con myEmitter ora un'istanza della classe EventEmitter , possiamo accedere a emit() e on() :
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', () => { console.log('The "someEvent" event was fired (emitted)'); }); myEmitter.emit('someEvent'); // This will call the callback function above. Il secondo parametro di myEmitter.on() è la funzione di callback che si attiverà quando viene emesso l'evento: questo è il gestore dell'evento. Il primo parametro è il nome dell'evento, che può essere qualsiasi cosa desideriamo, sebbene sia consigliata la convenzione di denominazione camelCase.
Inoltre, il gestore dell'evento può accettare un numero qualsiasi di argomenti, che vengono passati quando viene emesso l'evento:
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', (data) => { console.log(`The "someEvent" event was fired (emitted) with data: ${data}`); }); myEmitter.emit('someEvent', 'This is the data payload'); Usando l'ereditarietà, possiamo esporre i metodi emit() e on() da 'EventEmitter' a qualsiasi classe. Questo viene fatto creando una classe Node.js e utilizzando la parola chiave riservata extends per ereditare le proprietà disponibili su EventEmitter :

const EventEmitter = require('events'); class MyEmitter extends EventEmitter { // This is my class. I can emit events from a MyEmitter object. } Supponiamo di costruire un programma di notifica di collisione del veicolo che riceve dati da giroscopi, accelerometri e manometri sullo scafo dell'auto. Quando un veicolo entra in collisione con un oggetto, quei sensori esterni rileveranno l'incidente, eseguendo la funzione di collide(...) e trasmettendogli i dati aggregati del sensore come un bell'oggetto JavaScript. Questa funzione emetterà un evento di collision , informando il fornitore dell'arresto anomalo.
const EventEmitter = require('events'); class Vehicle extends EventEmitter { collide(collisionStatistics) { this.emit('collision', collisionStatistics) } } const myVehicle = new Vehicle(); myVehicle.on('collision', collisionStatistics => { console.log('WARNING! Vehicle Impact Detected: ', collisionStatistics); notifyVendor(collisionStatistics); }); myVehicle.collide({ ... }); Questo è un esempio contorto perché potremmo semplicemente inserire il codice all'interno del gestore di eventi all'interno della funzione di collisione della classe, ma dimostra comunque come funziona il modello di eventi del nodo. Nota che alcuni tutorial mostreranno il metodo util.inherits() per consentire a un oggetto di emettere eventi. Questo è stato deprecato a favore delle classi ES6 e extends .
Il Nodo Package Manager
Quando si programma con Node e JavaScript, sarà abbastanza comune sentire parlare di npm . Npm è un gestore di pacchetti che fa proprio questo: consente il download di pacchetti di terze parti che risolvono problemi comuni in JavaScript. Esistono anche altre soluzioni, come Yarn, Npx, Grunt e Bower, ma in questa sezione ci concentreremo solo su npm e su come installare le dipendenze per la tua applicazione tramite una semplice Command Line Interface (CLI) che la utilizza.
Iniziamo in modo semplice, con solo npm . Visita la homepage di NpmJS per visualizzare tutti i pacchetti disponibili da NPM. Quando avvii un nuovo progetto che dipenderà dai pacchetti NPM, dovrai eseguire npm init tramite il terminale nella directory principale del tuo progetto. Ti verranno poste una serie di domande che verranno utilizzate per creare un file package.json . Questo file memorizza tutte le tue dipendenze — moduli da cui la tua applicazione dipende per funzionare, script — comandi del terminale predefiniti per eseguire test, costruire il progetto, avviare il server di sviluppo, ecc. e altro ancora.
Per installare un pacchetto, esegui semplicemente npm install [package-name] --save . Il flag di save assicurerà che il pacchetto e la sua versione siano registrati nel file package.json . A partire da npm versione 5, le dipendenze vengono salvate per impostazione predefinita, quindi --save può essere omesso. Noterai anche una nuova cartella node_modules , contenente il codice per quel pacchetto che hai appena installato. Questo può anche essere abbreviato a solo npm i [package-name] . Come nota utile, la cartella node_modules non dovrebbe mai essere inclusa in un repository GitHub a causa delle sue dimensioni. Ogni volta che cloni un repository da GitHub (o qualsiasi altro sistema di gestione delle versioni), assicurati di eseguire il comando npm install per uscire e recuperare tutti i pacchetti definiti nel file package.json , creando automaticamente la directory node_modules . Puoi anche installare un pacchetto in una versione specifica: npm i [package-name]@1.10.1 --save , per esempio.
La rimozione di un pacchetto è simile all'installazione di uno: npm remove [package-name] .
Puoi anche installare un pacchetto a livello globale. Questo pacchetto sarà disponibile per tutti i progetti, non solo per quello su cui stai lavorando. Lo fai con il flag -g dopo npm i [package-name] . Questo è comunemente usato per le CLI, come Google Firebase e Heroku. Nonostante la facilità offerta da questo metodo, è generalmente considerata una cattiva pratica installare i pacchetti a livello globale, poiché non vengono salvati nel file package.json e se un altro sviluppatore tenta di utilizzare il tuo progetto, non raggiungerà tutte le dipendenze richieste da npm install .
API e JSON
Le API sono un paradigma molto comune nella programmazione e, anche se hai appena iniziato la tua carriera come sviluppatore, le API e il loro utilizzo, in particolare nello sviluppo web e mobile, probabilmente si presenteranno il più delle volte.
Un'API è un'interfaccia di programmazione dell'applicazione ed è fondamentalmente un metodo mediante il quale due sistemi disaccoppiati possono comunicare tra loro. In termini più tecnici, un'API consente a un sistema o a un programma per computer (di solito un server) di ricevere richieste e inviare risposte appropriate (a un client, noto anche come host).
Si supponga di creare un'applicazione meteo. Hai bisogno di un modo per geocodificare l'indirizzo di un utente in una latitudine e longitudine, e quindi un modo per ottenere il tempo attuale o previsto in quella particolare posizione.
As a developer, you want to focus on building your app and monetizing it, not putting the infrastructure in place to geocode addresses or placing weather stations in every city.
Luckily for you, companies like Google and OpenWeatherMap have already put that infrastructure in place, you just need a way to talk to it — that is where the API comes in. While, as of now, we have developed a very abstract and ambiguous definition of the API, bear with me. We'll be getting to tangible examples soon.
Now, it costs money for companies to develop, maintain, and secure that aforementioned infrastructure, and so it is common for corporations to sell you access to their API. This is done with that is known as an API key, a unique alphanumeric identifier associating you, the developer, with the API. Every time you ask the API to send you data, you pass along your API key. The server can then authenticate you and keep track of how many API calls you are making, and you will be charged appropriately. The API key also permits Rate-Limiting or API Call Throttling (a method of throttling the number of API calls in a certain timeframe as to not overwhelm the server, preventing DOS attacks — Denial of Service). Most companies, however, will provide a free quota, giving you, as an example, 25,000 free API calls a day before charging you.
Up to this point, we have established that an API is a method by which two computer programs can communicate with each other. If a server is storing data, such as a website, and your browser makes a request to download the code for that site, that was the API in action.
Let us look at a more tangible example, and then we'll look at a more real-world, technical one. Suppose you are eating out at a restaurant for dinner. You are equivalent to the client, sitting at the table, and the chef in the back is equivalent to the server.
Since you will never directly talk to the chef, there is no way for him/her to receive your request (for what order you would like to make) or for him/her to provide you with your meal once you order it. We need someone in the middle. In this case, it's the waiter, analogous to the API. The API provides a medium with which you (the client) may talk to the server (the chef), as well as a set of rules for how that communication should be made (the menu — one meal is allowed two sides, etc.)
Now, how do you actually talk to the API (the waiter)? You might speak English, but the chef might speak Spanish. Is the waiter expected to know both languages to translate? What if a third person comes in who only speaks Mandarin? What then? Well, all clients and servers have to agree to speak a common language, and in computer programming, that language is JSON, pronounced JAY-sun, and it stands for JavaScript Object Notation.
At this point, we don't quite know what JSON looks like. It's not a computer programming language, it's just, well, a language, like English or Spanish, that everyone (everyone being computers) understands on a guaranteed basis. It's guaranteed because it's a standard, notably RFC 8259 , the JavaScript Object Notation (JSON) Data Interchange Format by the Internet Engineering Task Force (IETF).
Even without formal knowledge of what JSON actually is and what it looks like (we'll see in an upcoming article in this series), we can go ahead introduce a technical example operating on the Internet today that employs APIs and JSON. APIs and JSON are not just something you can choose to use, it's not equivalent to one out of a thousand JavaScript frameworks you can pick to do the same thing. It is THE standard for data exchange on the web.
Suppose you are building a travel website that compares prices for aircraft, rental car, and hotel ticket prices. Let us walk through, step-by-step, on a high level, how we would build such an application. Of course, we need our User Interface, the front-end, but that is out of scope for this article.
We want to provide our users with the lowest price booking method. Well, that means we need to somehow attain all possible booking prices, and then compare all of the elements in that set (perhaps we store them in an array) to find the smallest element (known as the infimum in mathematics.)
How will we get this data? Well, suppose all of the booking sites have a database full of prices. Those sites will provide an API, which exposes the data in those databases for use by you. You will call each API for each site to attain all possible booking prices, store them in your own array, find the lowest or minimum element of that array, and then provide the price and booking link to your user. We'll ask the API to query its database for the price in JSON, and it will respond with said price in JSON to us. We can then use, or parse, that accordingly. We have to parse it because APIs will return JSON as a string, not the actual JavaScript data type of JSON. This might not make sense now, and that's okay. We'll be covering it more in a future article.
Also, note that just because something is called an API does not necessarily mean it operates on the web and sends and receives JSON. The Java API, for example, is just the list of classes, packages, and interfaces that are part of the Java Development Kit (JDK), providing programming functionality to the programmer.
Bene. We know we can talk to a program running on a server by way of an Application Programming Interface, and we know that the common language with which we do this is known as JSON. But in the web development and networking world, everything has a protocol. What do we actually do to make an API call, and what does that look like code-wise? That's where HTTP Requests enter the picture, the HyperText Transfer Protocol, defining how messages are formatted and transmitted across the Internet. Once we have an understanding of HTTP (and HTTP verbs, you'll see that in the next section), we can look into actual JavaScript frameworks and methods (like fetch() ) offered by the JavaScript API (similar to the Java API), that actually allow us to make API calls.
HTTP And HTTP Requests
HTTP is the HyperText Transfer Protocol. It is the underlying protocol that determines how messages are formatted as they are transmitted and received across the web. Let's think about what happens when, for example, you attempt to load the home page of Smashing Magazine in your web browser.
You type the website URL (Uniform Resource Locator) in the URL bar, where the DNS server (Domain Name Server, out of scope for this article) resolves the URL into the appropriate IP Address. The browser makes a request, called a GET Request, to the Web Server to, well, GET the underlying HTML behind the site. The Web Server will respond with a message such as “OK”, and then will go ahead and send the HTML down to the browser where it will be parsed and rendered accordingly.
There are a few things to note here. First, the GET Request, and then the “OK” response. Suppose you have a specific database, and you want to write an API to expose that database to your users. Suppose the database contains books the user wants to read (as it will in a future article in this series). Then there are four fundamental operations your user may want to perform on this database, that is, Create a record, Read a record, Update a record, or Delete a record, known collectively as CRUD operations.
Let's look at the Read operation for a moment. Without incorrectly assimilating or conflating the notion of a web server and a database, that Read operation is very similar to your web browser attempting to get the site from the server, just as to read a record is to get the record from the database.
Questa è nota come richiesta HTTP. Stai facendo una richiesta a un server da qualche parte per ottenere alcuni dati e, in quanto tale, la richiesta è appropriatamente denominata "GET", la maiuscola è un modo standard per denotare tali richieste.
Che dire della parte Crea di CRUD? Bene, quando si parla di richieste HTTP, è noto come richiesta POST. Proprio come potresti pubblicare un messaggio su una piattaforma di social media, potresti anche pubblicare un nuovo record in un database.
L'aggiornamento di CRUD ci consente di utilizzare una richiesta PUT o PATCH per aggiornare una risorsa. Il PUT di HTTP creerà un nuovo record o aggiornerà/sostituirà quello vecchio.
Diamo un'occhiata a questo un po' più in dettaglio, e poi arriveremo a PATCH.
Un'API generalmente funziona effettuando richieste HTTP a percorsi specifici in un URL. Supponiamo di creare un'API per comunicare con un DB contenente la lista dei libri di un utente. Quindi potremmo essere in grado di visualizzare quei libri all'URL .../books . Un POST richiede a .../books creerà un nuovo libro con qualsiasi proprietà tu definisca (think id, titolo, ISBN, autore, dati di pubblicazione, ecc.) nel percorso .../books . Non importa quale sia la struttura dei dati sottostante che memorizza tutti i libri in .../books in questo momento. Ci interessa solo che l'API esponga quell'endpoint (a cui si accede tramite il percorso) per manipolare i dati. La frase precedente era fondamentale: una richiesta POST crea un nuovo libro sul percorso ...books/ . La differenza tra PUT e POST, quindi, è che PUT creerà un nuovo libro (come con POST) se tale libro non esiste, oppure sostituirà un libro esistente se il libro esiste già all'interno della suddetta struttura di dati.
Supponiamo che ogni libro abbia le seguenti proprietà: id, titolo, ISBN, autore, hasRead (booleano).
Quindi per aggiungere un nuovo libro, come visto in precedenza, faremmo una richiesta POST a .../books . Se volessimo aggiornare o sostituire completamente un libro, faremmo una richiesta PUT a .../books/id dove id è l'ID del libro che vogliamo sostituire.
Mentre PUT sostituisce completamente un libro esistente, PATCH aggiorna qualcosa che ha a che fare con un libro specifico, forse modificando la proprietà booleana hasRead che abbiamo definito sopra, quindi faremmo una richiesta PATCH a …/books/id inviando insieme i nuovi dati.
Può essere difficile vedere il significato di questo in questo momento, perché finora abbiamo stabilito tutto in teoria ma non abbiamo visto alcun codice tangibile che faccia effettivamente una richiesta HTTP. Tuttavia, ci arriveremo presto, trattando GET in questo articolo, e il resto in un articolo futuro.
C'è un'ultima operazione fondamentale CRUD e si chiama Elimina. Come ci si aspetterebbe, il nome di tale richiesta HTTP è "DELETE" e funziona più o meno come PATCH, richiedendo che l'ID del libro sia fornito in un percorso.
Abbiamo imparato finora, quindi, che le rotte sono URL specifici a cui si effettua una richiesta HTTP e che gli endpoint sono funzioni fornite dall'API, che fanno qualcosa ai dati che espone. Cioè, l'endpoint è una funzione del linguaggio di programmazione situata all'altra estremità del percorso ed esegue qualsiasi richiesta HTTP specificata. Abbiamo anche appreso che esistono termini come POST, GET, PUT, PATCH, DELETE e altro (noti come verbi HTTP) che specificano effettivamente quali richieste stai facendo all'API. Come JSON, questi metodi di richiesta HTTP sono standard Internet definiti dall'Internet Engineering Task Force (IETF), in particolare RFC 7231, sezione quattro: metodi di richiesta e RFC 5789, sezione due: metodo patch, dove RFC è l'acronimo di Richiesta di commenti.
Quindi, potremmo fare una richiesta GET all'URL .../books/id in cui l'ID passato è noto come parametro. Potremmo fare una richiesta POST, PUT o PATCH a .../books per creare una risorsa o a .../books/id per modificare/sostituire/aggiornare una risorsa. E possiamo anche fare una richiesta DELETE a .../books/id per eliminare un libro specifico.
Un elenco completo dei metodi di richiesta HTTP può essere trovato qui.
È anche importante notare che dopo aver effettuato una richiesta HTTP, riceveremo una risposta. La risposta specifica è determinata da come costruiamo l'API, ma dovresti sempre ricevere un codice di stato. In precedenza, abbiamo detto che quando il tuo browser web richiede l'HTML dal server web, risponderà con "OK". Questo è noto come codice di stato HTTP, più specificamente HTTP 200 OK. Il codice di stato specifica semplicemente come l'operazione o l'azione specificata nell'endpoint (ricorda, è la nostra funzione che fa tutto il lavoro) è stata completata. I codici di stato HTTP vengono restituiti dal server e probabilmente ce ne sono molti con cui hai familiarità, come 404 Not Found (non è stato possibile trovare la risorsa o il file, sarebbe come fare una richiesta GET a .../books/id dove non esiste tale ID.)
Un elenco completo dei codici di stato HTTP può essere trovato qui.
MongoDB
MongoDB è un database NoSQL non relazionale simile al database in tempo reale di Firebase. Parlerai con il database tramite un pacchetto Node come MongoDB Native Driver o Mongoose.
In MongoDB, i dati vengono archiviati in JSON, che è molto diverso dai database relazionali come MySQL, PostgreSQL o SQLite. Entrambi sono chiamati database, con tabelle SQL denominate Raccolte, Righe di tabelle SQL denominate Documenti e Colonne di tabelle SQL denominate Campi.
Useremo il database MongoDB in un prossimo articolo di questa serie quando creeremo la nostra prima API Bookshelf. Le operazioni CRUD fondamentali sopra elencate possono essere eseguite su un database MongoDB.
Si consiglia di leggere i documenti MongoDB per imparare come creare un database live su un cluster Atlas e fare operazioni CRUD su di esso con il driver nativo MongoDB. Nel prossimo articolo di questa serie, impareremo come configurare un database locale e un database di produzione cloud.
Creazione di un'applicazione del nodo della riga di comando
Durante la creazione di un'applicazione, vedrai molti autori scaricare l'intera base di codice all'inizio dell'articolo e quindi tentare di spiegare ogni riga in seguito. In questo testo adotterò un approccio diverso. Spiegherò il mio codice riga per riga, costruendo l'app mentre procediamo. Non mi preoccuperò della modularità o delle prestazioni, non dividerò la codebase in file separati e non seguirò il principio DRY né tenterò di rendere il codice riutilizzabile. Quando si impara semplicemente, è utile rendere le cose il più semplici possibile, e quindi questo è l'approccio che adotterò qui.
Cerchiamo di essere chiari su ciò che stiamo costruendo. Non ci preoccuperemo dell'input dell'utente, quindi non utilizzeremo pacchetti come Yargs. Inoltre, non creeremo la nostra API. Ciò arriverà in un articolo successivo di questa serie quando utilizzeremo Express Web Application Framework. Prendo questo approccio per non confondere Node.js con la potenza di Express e API poiché la maggior parte dei tutorial lo fa. Piuttosto, fornirò un metodo (di molti) con cui chiamare e ricevere dati da un'API esterna che utilizza una libreria JavaScript di terze parti. L'API che chiameremo è un'API Weather, a cui accederemo da Node e ne scaricheremo l'output sul terminale, forse con una formattazione, nota come "pretty-printing". Tratterò l'intero processo, incluso come impostare l'API e ottenere la chiave API, i cui passaggi forniscono i risultati corretti a partire da gennaio 2019.
Utilizzeremo l'API OpenWeatherMap per questo progetto, quindi per iniziare, vai alla pagina di registrazione di OpenWeatherMap e crea un account con il modulo. Una volta effettuato l'accesso, trova la voce di menu Chiavi API nella pagina del dashboard (che si trova qui). Se hai appena creato un account, dovrai scegliere un nome per la tua chiave API e premere "Genera". Potrebbero essere necessarie almeno 2 ore prima che la tua nuova chiave API sia funzionante e associata al tuo account.
Prima di iniziare a creare l'applicazione, visiteremo la documentazione API per scoprire come formattare la nostra chiave API. In questo progetto, specificheremo un codice postale e un prefisso internazionale per ottenere le informazioni meteorologiche in quella località.
Dai documenti, possiamo vedere che il metodo con cui lo facciamo è fornire il seguente URL:
api.openweathermap.org/data/2.5/weather?zip={zip code},{country code}In cui potremmo inserire i dati:
api.openweathermap.org/data/2.5/weather?zip=94040,usOra, prima di poter effettivamente ottenere dati rilevanti da questa API, dovremo fornire la nostra nuova chiave API come parametro di query:
api.openweathermap.org/data/2.5/weather?zip=94040,us&appid={YOUR_API_KEY} Per ora, copia quell'URL in una nuova scheda nel tuo browser web, sostituendo il segnaposto {YOUR_API_KEY} con la chiave API che hai ottenuto in precedenza quando ti sei registrato per un account.
Il testo che puoi vedere è in realtà JSON, la lingua concordata del Web come discusso in precedenza.
Per ispezionarlo ulteriormente, premi Ctrl + Maiusc + I in Google Chrome per aprire gli strumenti per sviluppatori di Chrome, quindi vai alla scheda Rete. Al momento, non dovrebbero esserci dati qui.
Per monitorare effettivamente i dati di rete, ricaricare la pagina e guardare la scheda riempirsi di informazioni utili. Fare clic sul primo collegamento come illustrato nell'immagine sottostante.
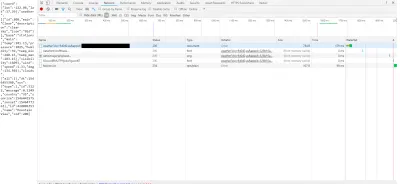
Dopo aver fatto clic su quel collegamento, possiamo effettivamente visualizzare informazioni specifiche HTTP, come le intestazioni. Le intestazioni vengono inviate nella risposta dall'API (puoi anche, in alcuni casi, inviare le tue intestazioni all'API, oppure puoi persino creare le tue intestazioni personalizzate (spesso precedute da x- ) da inviare indietro quando crei la tua API ) e contengono solo informazioni aggiuntive che potrebbero essere necessarie al client o al server.
In questo caso, puoi vedere che abbiamo effettuato una richiesta HTTP GET all'API e ha risposto con uno stato HTTP 200 OK. Puoi anche vedere che i dati inviati erano in JSON, come elencato nella sezione "Intestazioni di risposta".
Se premi la scheda di anteprima, puoi effettivamente visualizzare il JSON come un oggetto JavaScript. La versione di testo che puoi vedere nel tuo browser è una stringa, poiché JSON viene sempre trasmessa e ricevuta sul Web come una stringa. Ecco perché dobbiamo analizzare il JSON nel nostro codice, per inserirlo in un formato più leggibile - in questo caso (e praticamente in tutti i casi) - un oggetto JavaScript.
Puoi anche utilizzare l'estensione di Google Chrome "JSON View" per farlo automaticamente.
Per iniziare a creare la nostra applicazione, aprirò un terminale e creerò una nuova directory radice e poi cd in essa. Una volta dentro, creerò un nuovo file app.js , npm init per generare un file package.json con le impostazioni predefinite, quindi aprirò Visual Studio Code.
mkdir command-line-weather-app && cd command-line-weather-app touch app.js npm init code . Successivamente, scaricherò Axios, verificherò che sia stato aggiunto al mio file package.json e noterò che la cartella node_modules è stata creata correttamente.
Nel browser puoi vedere che abbiamo fatto una richiesta GET manualmente digitando manualmente l'URL corretto nella barra degli URL. Axios è ciò che mi permetterà di farlo all'interno di Node.
A partire da ora, tutto il codice seguente si troverà all'interno del file app.js , ogni snippet posizionato uno dopo l'altro.
La prima cosa che farò è richiedere il pacchetto Axios che abbiamo installato in precedenza
const axios = require('axios'); Ora abbiamo accesso ad Axios e possiamo effettuare richieste HTTP pertinenti, tramite la costante axios .
In genere, le nostre chiamate API saranno dinamiche: in questo caso, potremmo voler inserire codici postali e codici paese diversi nel nostro URL. Quindi, creerò variabili costanti per ciascuna parte dell'URL, quindi le unirò alle stringhe di modelli ES6. Innanzitutto, abbiamo la parte del nostro URL che non cambierà mai così come la nostra chiave API:
const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; Assegnerò anche il nostro codice postale e il codice del paese. Dal momento che non ci aspettiamo l'input dell'utente e stiamo codificando i dati in modo piuttosto difficile, li renderò costanti anche se, in molti casi, sarà più utile usare let .
const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us';Ora dobbiamo mettere insieme queste variabili in un URL a cui possiamo usare Axios per fare richieste GET per:
const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Ecco il contenuto del nostro file app.js fino a questo punto:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Tutto ciò che resta da fare è utilizzare effettivamente axios per effettuare una richiesta GET a quell'URL. Per questo, useremo il metodo get(url) fornito da axios .
axios.get(ENTIRE_API_URL) axios.get(...) restituisce effettivamente una promessa e la funzione di callback di successo riceverà un argomento di risposta che ci consentirà di accedere alla risposta dall'API, la stessa cosa che hai visto nel browser. Aggiungerò anche una clausola .catch() per rilevare eventuali errori.
axios.get(ENTIRE_API_URL) .then(response => console.log(response)) .catch(error => console.log('Error', error)); Se ora eseguiamo questo codice con node app.js nel terminale, sarai in grado di vedere la risposta completa che riceviamo. Tuttavia, supponiamo che tu voglia solo vedere la temperatura per quel codice postale, quindi la maggior parte di quei dati nella risposta non ti sono utili. Axios restituisce effettivamente la risposta dall'API nell'oggetto dati, che è una proprietà della risposta. Ciò significa che la risposta dal server si trova effettivamente in response.data , quindi stampiamola invece nella funzione di callback: console.log(response.data) .
Ora, abbiamo detto che i server Web gestiscono sempre JSON come una stringa, ed è vero. Potresti notare, tuttavia, che response.data è già un oggetto (evidente eseguendo console.log(typeof response.data) ) — non abbiamo dovuto analizzarlo con JSON.parse() . Questo perché Axios si occupa già di questo per noi dietro le quinte.
L'output nel terminale dall'esecuzione di console.log(response.data) può essere formattato — "pretty-printed" — eseguendo console.log(JSON.stringify(response.data, undefined, 2)) . JSON.stringify() converte un oggetto JSON in una stringa e accetta l'oggetto, un filtro e il numero di caratteri di cui rientrare durante la stampa. Puoi vedere la risposta che questo fornisce:
{ "coord": { "lon": -118.24, "lat": 33.97 }, "weather": [ { "id": 800, "main": "Clear", "description": "clear sky", "icon": "01d" } ], "base": "stations", "main": { "temp": 288.21, "pressure": 1022, "humidity": 15, "temp_min": 286.15, "temp_max": 289.75 }, "visibility": 16093, "wind": { "speed": 2.1, "deg": 110 }, "clouds": { "all": 1 }, "dt": 1546459080, "sys": { "type": 1, "id": 4361, "message": 0.0072, "country": "US", "sunrise": 1546441120, "sunset": 1546476978 }, "id": 420003677, "name": "Lynwood", "cod": 200 } Ora, è chiaro che la temperatura che stiamo cercando si trova sulla proprietà main dell'oggetto response.data , quindi possiamo accedervi chiamando response.data.main.temp . Diamo un'occhiata al codice dell'applicazione fino ad ora:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => console.log(response.data.main.temp)) .catch(error => console.log('Error', error));La temperatura che otteniamo è in realtà in Kelvin, che è una scala di temperatura generalmente utilizzata in Fisica, Chimica e Termodinamica poiché fornisce un punto "zero assoluto", che è la temperatura alla quale tutti i movimenti termici di tutti gli interni le particelle cessano. Dobbiamo solo convertirlo in Fahrenheit o Celcius con le formule seguenti:
F = K * 9/5 - 459,67
C = K - 273,15
Aggiorniamo il nostro callback di successo per stampare i nuovi dati con questa conversione. Aggiungeremo anche una frase adeguata ai fini dell'esperienza utente:
axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error)); Le parentesi attorno alla variabile del message non sono richieste, sono semplicemente belle, simili a quando si lavora con JSX in React. Le barre inverse impediscono alla stringa del modello di formattare una nuova riga e il metodo del prototipo di stringa replace() elimina lo spazio vuoto utilizzando le espressioni regolari (RegEx). I metodi del prototipo toFixed() Number arrotondano un float a un numero specifico di cifre decimali, in questo caso due.
Con ciò, il nostro app.js finale appare come segue:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error));Conclusione
Abbiamo imparato molto sul funzionamento di Node in questo articolo, dalle differenze tra richieste sincrone e asincrone, alle funzioni di callback, alle nuove funzionalità di ES6, eventi, gestori di pacchetti, API, JSON e HyperText Transfer Protocol, database non relazionali e abbiamo persino creato la nostra applicazione a riga di comando utilizzando la maggior parte delle nuove conoscenze acquisite.
Nei futuri articoli di questa serie, daremo uno sguardo approfondito alle API Call Stack, Event Loop e Node, parleremo di Cross-Origin Resource Sharing (CORS) e creeremo un Full Stack Bookshelf API utilizzando database, endpoint, autenticazione utente, token, rendering di modelli lato server e altro ancora.
Da qui, inizia a creare le tue applicazioni Node, leggi la documentazione Node, esci e trova API o moduli Node interessanti e implementali tu stesso. Il mondo è la tua ostrica e hai a portata di mano l'accesso alla più grande rete di conoscenza del pianeta: Internet. Usalo a tuo vantaggio.
Ulteriori letture su SmashingMag:
- Comprensione e utilizzo delle API REST
- Nuove funzionalità JavaScript che cambieranno il modo in cui scrivi Regex
- Mantenere Node.js veloce: strumenti, tecniche e suggerimenti per creare server Node.js ad alte prestazioni
- Costruire un semplice chatbot AI con l'API Web Speech e Node.js