
7 algoritmi di apprendimento automatico più utilizzati in Python che dovresti conoscere
Pubblicato: 2021-03-04Il Machine Learning è una branca dell'Intelligenza Artificiale (AI) che si occupa degli algoritmi informatici utilizzati su qualsiasi dato. Si concentra sull'apprendimento automatico dai dati inseriti e ci dà risultati migliorando ogni volta le previsioni precedenti.
Sommario
I migliori algoritmi di apprendimento automatico utilizzati in Python
Di seguito sono riportati alcuni dei principali algoritmi di apprendimento automatico utilizzati in Python, insieme ai frammenti di codice che mostrano la loro implementazione e visualizzazione dei limiti di classificazione.
1. Regressione lineare
La regressione lineare è una delle tecniche di apprendimento automatico supervisionato più comunemente utilizzate. Come suggerisce il nome, questa regressione tenta di modellare la relazione tra due variabili utilizzando un'equazione lineare e adattando quella linea ai dati osservati. Questa tecnica viene utilizzata per stimare valori reali continui come le vendite totali effettuate o il costo delle case.
La linea di miglior adattamento è anche chiamata retta di regressione. È data dalla seguente equazione:
Y = a*X + b
dove Y è la variabile dipendente, a è la pendenza, X è la variabile indipendente e b è il valore di intercetta. I coefficienti aeb sono derivati minimizzando il quadrato della differenza di quella distanza tra i vari punti dati e l'equazione della retta di regressione.

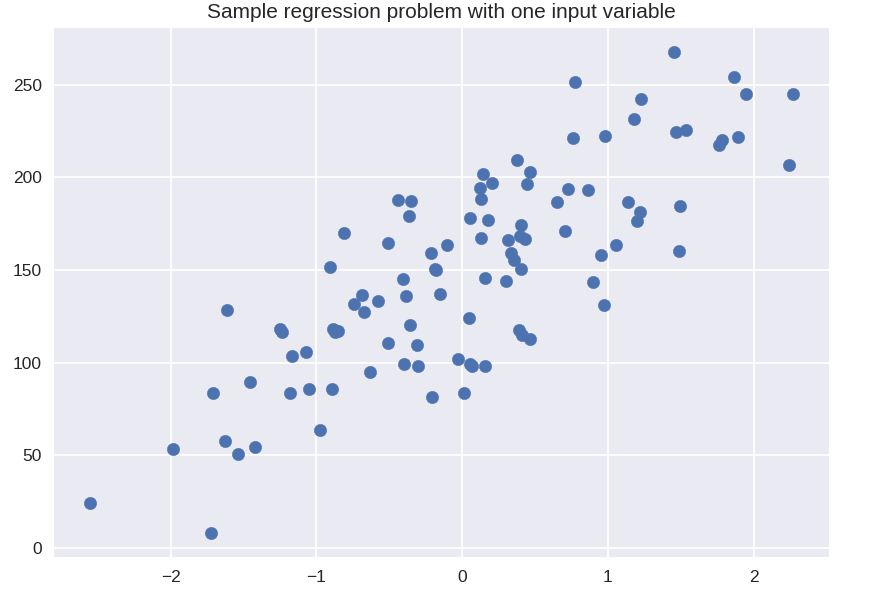
# set di dati sintetici per una semplice regressione
da sklearn.datasets import make_regression
plt.figura()
plt.title( 'Problema di regressione di esempio con una variabile di input' )
X_R1, y_R1 = make_regression( n_samples = 100, n_features = 1, n_informative = 1, bias = 150.0, noise = 30, random_state = 0 )
plt.scatter( X_R1, y_R1, marker = 'o', s = 50 )
plt.show()
da sklearn.linear_model import LinearRegression
X_train, X_test, y_train, y_test = train_test_split( X_R1, y_R1,
stato_casuale = 0 )
linreg = LinearRegression().fit( X_train, y_train )
print( 'coeff modello lineare (w): {}'.format( linreg.coef_ ) )
print( 'intercetta modello lineare (b): {:.3f}'z.format( linreg.intercept_ ) )
print( 'Punteggio R-quadrato (allenamento): {:.3f}'.format( linreg.score( X_train, y_train ) ) )
print( 'Punteggio R al quadrato (test): {:.3f}'.format( linreg.score( X_test, y_test ) ) )
Produzione
coeff del modello lineare (w): [ 45.71]
intercetta del modello lineare (b): 148.446
Punteggio R al quadrato (allenamento): 0,679
Punteggio R al quadrato (test): 0,492
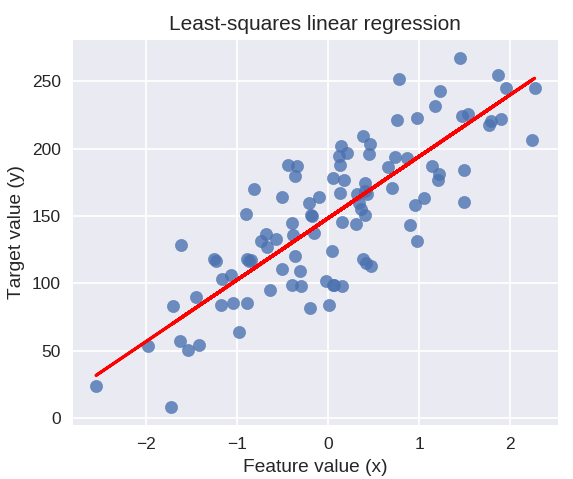
Il codice seguente disegnerà la retta di regressione adattata sul grafico dei nostri punti dati.
plt.figure(figsize = ( 5, 4 ) )
plt.scatter( X_R1, y_R1, marcatore = 'o', s = 50, alfa = 0,8)
plt.plot( X_R1, linreg.coef_ * X_R1 + linreg.intercept_, 'r-' )
plt.title( 'Regressione lineare dei minimi quadrati' )
plt.xlabel( 'Valore caratteristica (x)' )
plt.ylabel( 'Valore target (y)' )
plt.show()
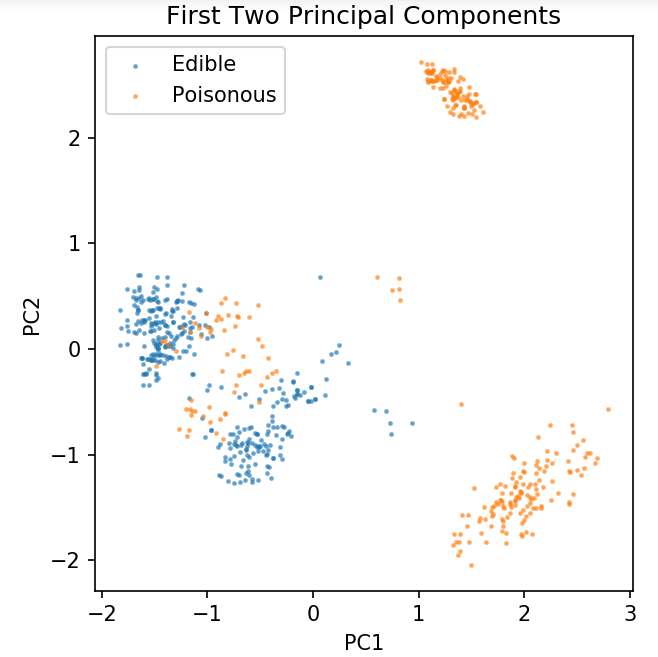
Preparazione di un set di dati comune per l'esplorazione delle tecniche di classificazione
I seguenti dati verranno utilizzati per mostrare i vari algoritmi di classificazione più comunemente utilizzati nell'apprendimento automatico in Python.
Il set di dati sui funghi UCI è archiviato in funghi.csv.
%taccuino matplotlib
importa panda come pd
importa numpy come np
importa matplotlib.pyplot come plt
da sklearn.decomposition import PCA
da sklearn.model_selection import train_test_split
df = pd.read_csv( 'sola lettura/funghi.csv' )
df2 = pd.get_dummies(df)
df3 = df2.campione( frac = 0,08 )
X = df3.iloc[:, 2:]
y = df3.iloc[:, 1]
pca = PCA( n_componenti = 2 ).fit_transform( X )
X_train, X_test, y_train, y_test = train_test_split( pca, y, random_state = 0 )
plt.figure(dpi = 120)
plt.scatter( pca[y.values == 0, 0], pca[y.values == 0, 1], alpha = 0,5, label = 'Commestibile', s = 2 )
plt.scatter( pca[y.values == 1, 0], pca[y.values == 1, 1], alpha = 0.5, label = 'Velenoso', s = 2 )
plt.leggenda()
plt.title( 'Set di dati sui funghi\nPrimi due componenti principali' )
plt.xlabel( 'PC1' )
plt.ylabel( 'PC2' )
plt.gca().set_aspect( 'uguale' )
Utilizzeremo la funzione definita di seguito per ottenere i limiti decisionali dei diversi classificatori che utilizzeremo sul set di dati dei funghi.
def plot_mushroom_boundary( X, y, fitting_model ):
plt.figure(figsize = (9.8, 5), dpi = 100)
per i, plot_type in enumerate( ['Decision Boundary', 'Decision Probabilities'] ):
plt.subplot( 1, 2, i + 1 )
mesh_step_size = 0,01 # dimensione del passo nella mesh
x_min, x_max = X[:, 0].min() – .1, X[:, 0].max() + .1
y_min, y_max = X[:, 1].min() – .1, X[:, 1].max() + .1
xx, yy = np.meshgrid( np.arange( x_min, x_max, mesh_step_size ), np.arange( y_min, y_max, mesh_step_size ) )
se io == 0:
Z = fitting_model.predict( np.c_[xx.ravel(), yy.ravel()] )
altro:
Tentativo:
Z = fitting_model.predict_proba( np.c_[xx.ravel(), yy.ravel()] )[:, 1]
tranne:
plt.text( 0.4, 0.5, 'Probabilità non disponibili', horizontalalignment = 'center', verticalalignment = 'center', transform = plt.gca().transAxes, fontsize = 12 )
plt.axis( 'off' )
rottura
Z = Z.reshape(xx.shape)
plt.scatter( X[y.values == 0, 0], X[y.values == 0, 1], alpha = 0.4, label = 'Commestibile', s = 5 )
plt.scatter( X[y.values == 1, 0], X[y.values == 1, 1], alpha = 0.4, label = 'Posionous', s = 5 )
plt.imshow( Z, interpolazione = 'più vicino', cmap = 'RdYlBu_r', alpha = 0.15, extent = ( x_min, x_max, y_min, y_max ), origin = 'inferiore')
plt.title( plot_type + '\n' + str( fitting_model ).split( '(' )[0] + ' Test Precisione: ' + str( np.round( fitting_model.score( X, y ), 5 ) ) )
plt.gca().set_aspect( 'uguale' );
plt.tight_layout()
plt.subplots_adjust(in alto = 0.9, in basso = 0.08, wspace = 0.02)
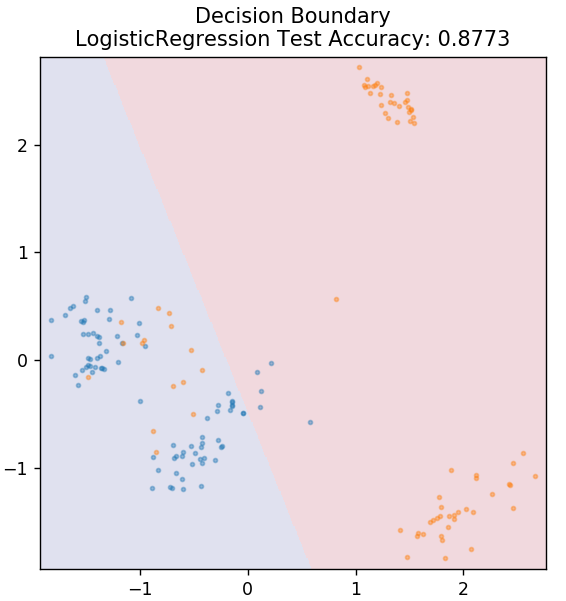
2. Regressione logistica
A differenza della regressione lineare, la regressione logistica si occupa della stima di valori discreti (0/1 valori binari, vero/falso, sì/no). Questa tecnica è anche chiamata regressione logit. Questo perché prevede la probabilità di un evento utilizzando una funzione logit per addestrare i dati forniti. Il suo valore è sempre compreso tra 0 e 1 (poiché calcola una probabilità).
Le quote log dei risultati sono costruite come una combinazione lineare della variabile predittore come segue:
odds = p / (1 – p) = probabilità che si verifichi un evento o probabilità che non si verifichi un evento
ln( quota ) = ln( p / (1 – p) )
logit( p ) = ln( p / (1 – p) ) = b0 + b1X1 + b2X2 + b3X3 + … + bkXk
dove p è la probabilità di presenza di una caratteristica.
da sklearn.linear_model import LogisticRegression
modello = Regressione Logistica()
model.fit( X_treno, y_treno )
plot_mushroom_boundary (X_test, y_test, modello)
Ottieni la certificazione di intelligenza artificiale online dalle migliori università del mondo: master, programmi post-laurea esecutivi e programma di certificazione avanzata in ML e AI per accelerare la tua carriera.
3. Albero decisionale
Questo è un algoritmo molto popolare che può essere utilizzato per classificare variabili di dati sia continue che discrete. Ad ogni passaggio, i dati vengono suddivisi in più insiemi omogenei in base ad alcuni attributi/condizioni di divisione.

da sklearn.tree import DecisionTreeClassifier
modello = DecisionTreeClassifier( max_depth = 3 )
model.fit( X_treno, y_treno )
plot_mushroom_boundary (X_test, y_test, modello)
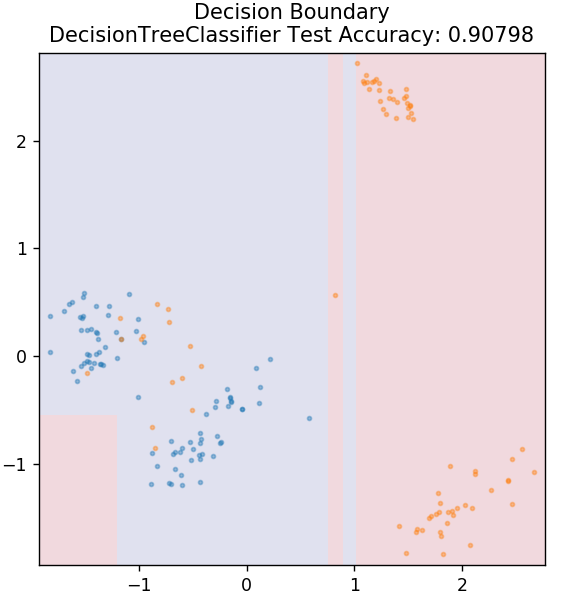
4. SVM
SVM è l'abbreviazione di Support Vector Machines. Qui l'idea di base è classificare i punti dati utilizzando gli iperpiani per la separazione. L'obiettivo è trovare un tale iperpiano che abbia la massima distanza (o margine) tra i punti dati di entrambe le classi o categorie.
Scegliamo l'aereo in modo tale da occuparci di classificare i punti sconosciuti in futuro con la massima sicurezza. Le SVM sono notoriamente utilizzate perché offrono un'elevata precisione pur occupando molto meno potenza di calcolo. Le SVM possono essere utilizzate anche per problemi di regressione.
da sklearn.svm importa SVC
modello = SVC( kernel = 'lineare')
model.fit( X_treno, y_treno )
plot_mushroom_boundary (X_test, y_test, modello)
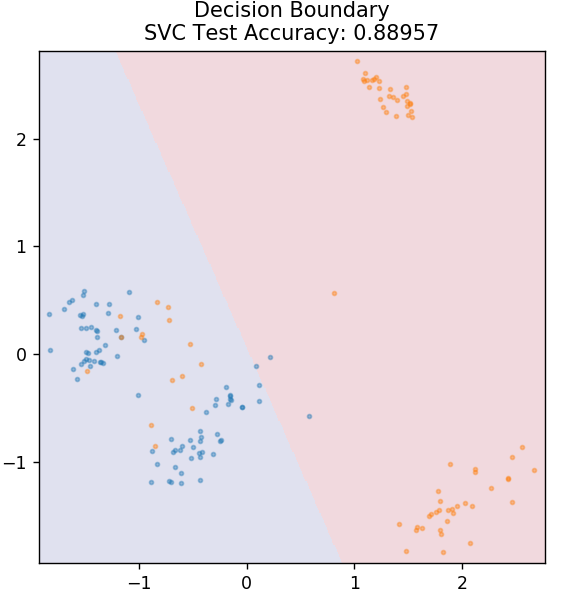
Checkout: Progetti Python su GitHub
5. Bayes ingenuo
Come suggerisce il nome, l'algoritmo di Naive Bayes è un algoritmo di apprendimento supervisionato basato sul teorema di Bayes . Il teorema di Bayes usa le probabilità condizionali per darti la probabilità di un evento sulla base di una data conoscenza.
Dove, 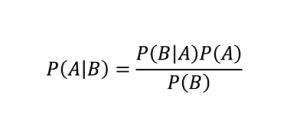
P (A | B): la probabilità condizionata che si verifichi l'evento A, dato che l'evento B si è già verificato. (Chiamata anche probabilità a posteriori)
P(A): Probabilità dell'evento A.
P(B): Probabilità dell'evento B.
P (B | A): la probabilità condizionata che si verifichi l'evento B, dato che l'evento A si è già verificato.
Perché questo algoritmo si chiama Naive, chiedi? Questo perché presuppone che tutte le occorrenze degli eventi siano indipendenti l'una dall'altra. Quindi ogni funzionalità definisce separatamente la classe a cui appartiene un punto dati, senza avere alcuna dipendenza tra di loro. Naive Bayes è la scelta migliore per la categorizzazione del testo. Funzionerà sufficientemente bene anche con piccole quantità di dati di addestramento.
da sklearn.naive_bayes importa GaussianNB
modello = GaussianNB()
model.fit( X_treno, y_treno )
plot_mushroom_boundary (X_test, y_test, modello)
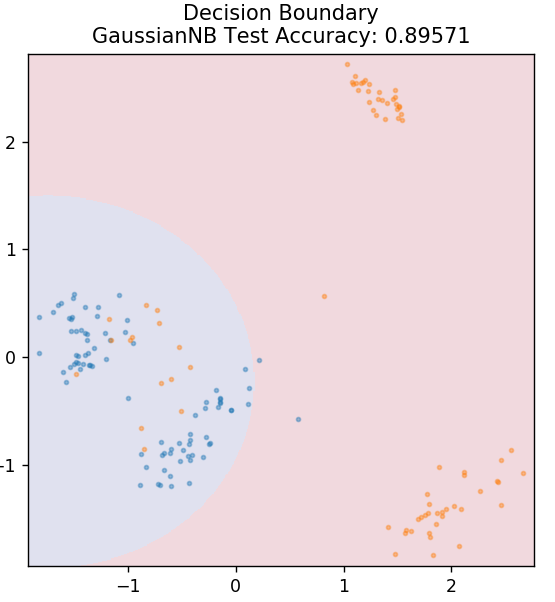
5. KNN
KNN sta per K-Nearest Neighbours. È un algoritmo di apprendimento supervisionato molto diffuso che classifica i dati del test in base alle sue somiglianze con i dati di allenamento precedentemente classificati. KNN non classifica tutti i punti dati durante l'allenamento. Invece, archivia semplicemente il set di dati e quando riceve nuovi dati, classifica quei punti dati in base alle loro somiglianze. Lo fa calcolando la distanza euclidea del numero K dei vicini più vicini (qui, n_neighbors ) di quel punto dati.
da sklearn.neighbors importa KNeighborsClassifier
modello = KNeighborsClassifier( n_neighbors = 20 )
model.fit( X_treno, y_treno )
plot_mushroom_boundary (X_test, y_test, modello)
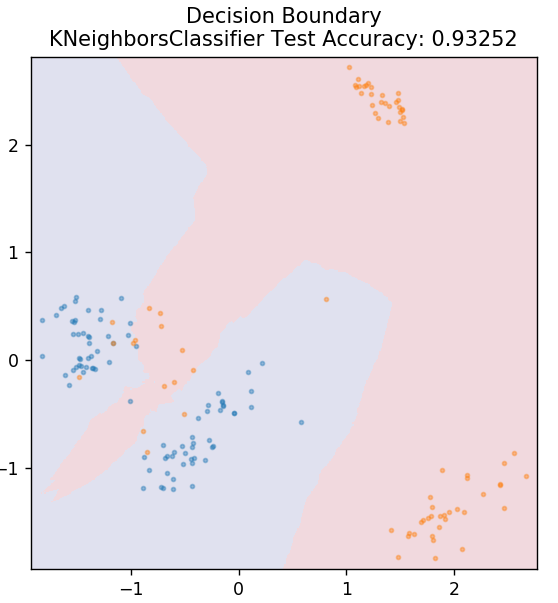
6. Foresta casuale
La foresta casuale è un algoritmo di apprendimento automatico molto semplice e diversificato che utilizza una tecnica di apprendimento supervisionato. Come puoi intuire dal nome, la foresta casuale è composta da un gran numero di alberi decisionali, che agiscono come un insieme. Ciascun albero decisionale individuerà la classe di output dei punti dati e la classe di maggioranza verrà scelta come output finale del modello. L'idea qui è che più alberi che lavorano sugli stessi dati tenderanno ad essere più accurati nei risultati rispetto ai singoli alberi.
da sklearn.ensemble importa RandomForestClassifier
modello = RandomForestClassifier()
model.fit( X_treno, y_treno )
plot_mushroom_boundary (X_test, y_test, modello)
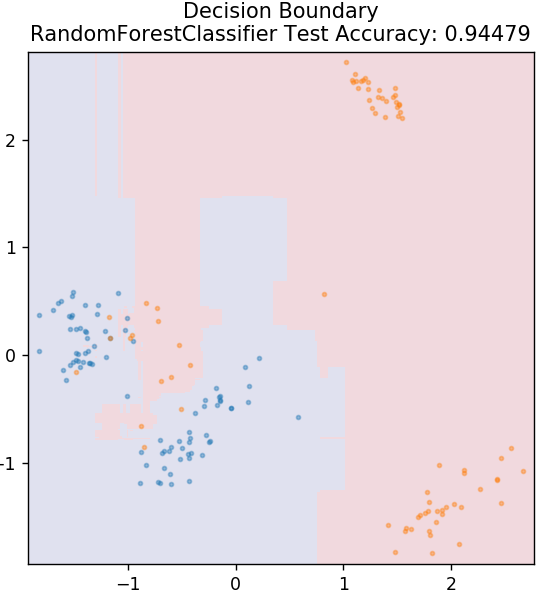
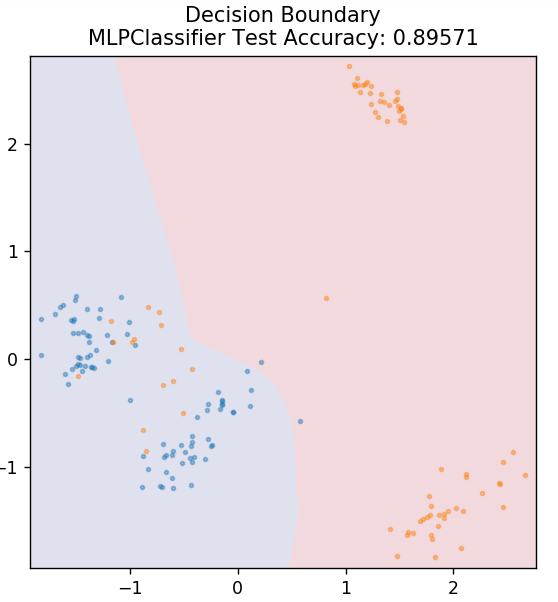
7. Perceptron multistrato
Multi-Layer Perceptron (o MLP) è un algoritmo molto affascinante che rientra nel ramo del deep learning. Più in particolare, appartiene alla classe delle reti neurali artificiali feed-forward (ANN). MLP forma una rete di più perceptron con almeno tre livelli: uno strato di input, uno strato di output e uno o più strati nascosti. Gli MLP sono in grado di distinguere tra dati che sono separabili in modo non lineare.
Ogni neurone negli strati nascosti usa una funzione di attivazione per passare allo strato successivo. Qui, l'algoritmo di backpropagation viene utilizzato per regolare effettivamente i parametri e quindi addestrare la rete neurale. Può essere utilizzato principalmente per semplici problemi di regressione.
da sklearn.neural_network importa MLPClassifier
modello = MLPClassificatore()
model.fit( X_treno, y_treno )
plot_mushroom_boundary (X_test, y_test, modello)
Leggi anche: Idee e argomenti per i progetti Python
Conclusione
Possiamo concludere che diversi algoritmi di apprendimento automatico producono confini decisionali diversi e quindi risultati di accuratezza diversi nella classificazione dello stesso set di dati.
Non c'è modo di dichiarare un algoritmo come il miglior algoritmo per tutti i tipi di dati in generale. L'apprendimento automatico richiede prove ed errori rigorosi per vari algoritmi per determinare cosa funziona meglio per ciascun set di dati separatamente. L'elenco degli algoritmi ML non finisce ovviamente qui. C'è un vasto mare di altre tecniche che aspettano di essere esplorate nella libreria Scikit-Learn di Python. Vai avanti e addestra i tuoi set di dati usando tutti quelli e divertiti!
Se sei interessato a saperne di più sugli alberi decisionali, sull'apprendimento automatico, dai un'occhiata al programma Executive PG di IIIT-B e upGrad in Machine Learning e AI , progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, stato di Alumni IIIT-B, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Quali sono le prime ipotesi di regressione lineare?
Esistono 4 presupposti essenziali per la regressione lineare: linearità, omoscedasticità, indipendenza e normalità. Linearità significa che la relazione tra la variabile indipendente (X) e la media della variabile dipendente (Y) è considerata lineare quando utilizziamo la regressione lineare. Per omoscedasticità si presume che la varianza negli errori dei punti residui del grafico sia costante. L'indipendenza si riferisce a tutte le osservazioni dei dati di input da considerare indipendenti l'una dall'altra. Normalità significa che la distribuzione dei dati di input può essere uniforme o non uniforme, ma si presume che sia distribuita uniformemente nel caso di regressione lineare.
Quali sono le differenze tra un albero decisionale e una foresta casuale?
L'albero decisionale attua il proprio processo decisionale, utilizzando una struttura ad albero che rappresenta i possibili esiti di azioni specifiche. La foresta casuale utilizza un insieme di tali alberi decisionali per analizzare i dati. Con questo processo, più dati verranno utilizzati dalla foresta casuale, ma aiuta a prevenire l'overfitting e fornisce risultati accurati. Esiste un ambito di overfitting in un algoritmo dell'albero decisionale e può fornire risultati meno accurati. Un albero decisionale è facile da interpretare in quanto richiede meno calcoli, mentre una foresta casuale è difficile da interpretare a causa delle sue complesse analisi.
Quali sono alcune librerie standard utilizzate per algoritmi di apprendimento automatico in Python?
Python ha sostituito quasi tutti gli altri linguaggi nell'apprendimento automatico grazie alla disponibilità di un vasto numero di librerie e di semplici regole di sintassi. Esistono molte librerie Python per l'apprendimento automatico come Numpy, Scipy, Scikit-learn, Theono, TensorFlow, PyTorch, Matplotlib, Keras, Pandas, ecc. L'utilizzo delle funzioni di queste librerie consente di risparmiare molto tempo nella scrittura di algoritmi per ogni attività; i processi richiedono meno tempo e forniscono risultati efficienti. Queste librerie hanno applicazioni come elaborazione di matrici, problemi di ottimizzazione, data mining, analisi statistica, calcoli che coinvolgono tensori, rilevamento di oggetti, reti neurali e molti altri.