
Mescolare tangibile e immateriale: progettare interfacce multimodali utilizzando Adobe XD
Pubblicato: 2022-03-10(Questo articolo è gentilmente sponsorizzato da Adobe.) Le interfacce utente si stanno evolvendo. Le interfacce abilitate alla voce stanno sfidando il lungo predominio delle interfacce utente grafiche e stanno rapidamente diventando una parte comune della nostra vita quotidiana. I progressi significativi nel riconoscimento vocale automatico (APS) e nell'elaborazione del linguaggio naturale (NLP), insieme a un'impressionante base di consumatori (milioni di dispositivi mobili con assistenti vocali integrati), hanno influenzato il rapido sviluppo e l'adozione dell'interfaccia basata sulla voce.
I prodotti che utilizzano la voce come interfaccia principale stanno diventando sempre più popolari. Solo negli Stati Uniti, 47,3 milioni di adulti hanno accesso a un altoparlante intelligente (ovvero un quinto della popolazione adulta statunitense) e il numero è in crescita. Ma le interfacce vocali hanno un futuro brillante non solo nell'uso personale e domestico. Man mano che le persone si abitueranno alle interfacce vocali, arriveranno ad aspettarsele anche in un contesto aziendale. Immagina solo che presto sarai in grado di attivare un proiettore per sale conferenze dicendo qualcosa come "Mostra la mia presentazione".
È evidente che la comunicazione uomo-macchina si sta espandendo rapidamente per comprendere sia l'interazione scritta che quella orale. Ma significa che le future interfacce saranno solo vocali? Nonostante alcune rappresentazioni di fantascienza, la voce non sostituirà completamente le interfacce utente grafiche. Avremo invece una sinergia di voce, visuale e gesti in un nuovo formato di interfaccia: un'interfaccia multimodale abilitata alla voce.
In questo articolo, faremo:
- esplorare il concetto di un'interfaccia abilitata alla voce e rivedere diversi tipi di interfacce abilitate alla voce;
- scoprire perché le interfacce utente multimodali abilitate alla voce saranno l'esperienza utente preferita;
- scopri come creare un'interfaccia utente multimodale utilizzando Adobe XD.
Lo stato delle interfacce utente (VUI)
Prima di addentrarci nei dettagli delle interfacce utente vocali, dobbiamo definire cos'è l'input vocale. L'input vocale è un'interazione uomo-computer in cui un utente pronuncia i comandi invece di scriverli. Il bello dell'input vocale è che è un'interazione più naturale per le persone: gli utenti non sono limitati a una sintassi specifica quando interagiscono con un sistema; possono strutturare il loro input in molti modi diversi, proprio come farebbero nella conversazione umana.
Le interfacce utente vocali offrono i seguenti vantaggi ai propri utenti:
- Meno costo di interazione
Sebbene l'utilizzo di un'interfaccia abilitata alla voce comporti un costo di interazione, questo costo è inferiore (in teoria) a quello dell'apprendimento di una nuova GUI. - Controllo a mani libere
Le VUI sono ottime per quando le mani degli utenti sono occupate, ad esempio mentre guidano, cucinano o fanno esercizio. - Velocità
La voce è eccellente quando porre una domanda è più veloce che digitarla e leggere i risultati. Ad esempio, quando si utilizza la voce in un'auto, è più veloce dire il luogo a un sistema di navigazione, piuttosto che digitare la posizione su un touchscreen. - Emozione e personalità
Anche quando sentiamo una voce ma non vediamo l'immagine di un oratore, possiamo immaginare l'oratore nella nostra testa. Questo ha l'opportunità di migliorare il coinvolgimento degli utenti. - Accessibilità
Gli utenti ipovedenti e gli utenti con difficoltà motorie possono utilizzare la voce per interagire con un sistema.
Tre tipi di interfacce abilitate alla voce
A seconda di come viene utilizzata la voce, potrebbe essere uno dei seguenti tipi di interfacce.
Agenti vocali nei dispositivi Screen-First
Apple Siri e Google Assistant sono ottimi esempi di agenti vocali. Per tali sistemi, la voce agisce più come un miglioramento per la GUI esistente. In molti casi, l'agente funge da primo passo nel percorso dell'utente: l'utente attiva l'agente vocale e fornisce un comando tramite voce, mentre tutte le altre interazioni vengono eseguite tramite il touchscreen. Ad esempio, quando fai una domanda a Siri, fornirà le risposte nel formato di un elenco e dovrai interagire con quell'elenco. Di conseguenza, l'esperienza dell'utente diventa frammentata: utilizziamo la voce per avviare l'interazione e quindi passiamo al tocco per continuarla.
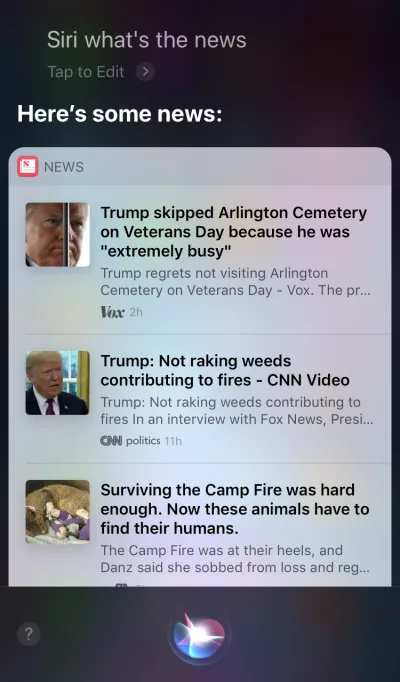
Dispositivi solo voce
Questi dispositivi non hanno display visivi; gli utenti fanno affidamento sull'audio sia per l'input che per l'output. Gli altoparlanti intelligenti Amazon Echo e Google Home sono ottimi esempi di prodotti in questa categoria. La mancanza di un display visivo è un vincolo significativo alla capacità del dispositivo di comunicare informazioni e opzioni all'utente. Di conseguenza, la maggior parte delle persone utilizza questi dispositivi per completare attività semplici, come riprodurre musica e ottenere risposte a semplici domande.

Dispositivi Voice-First
Con i sistemi voice-first, il dispositivo accetta l'input dell'utente principalmente tramite comandi vocali, ma ha anche un display integrato. Significa che la voce è l'interfaccia utente principale, ma non l'unica. Il vecchio detto "Un'immagine vale più di mille parole" si applica ancora ai moderni sistemi abilitati alla voce. Il cervello umano ha incredibili capacità di elaborazione dell'immagine: possiamo capire informazioni complesse più velocemente quando le vediamo visivamente. Rispetto ai dispositivi solo voce, i dispositivi voice-first consentono agli utenti di accedere a una maggiore quantità di informazioni e semplificano molte attività.
Amazon Echo Show è un ottimo esempio di dispositivo che utilizza un sistema vocale. Le informazioni visive vengono gradualmente incorporate come parte di un sistema olistico: lo schermo non viene caricato con le icone delle app; piuttosto, il sistema incoraggia gli utenti a provare diversi comandi vocali (suggerendo comandi verbali come "Prova 'Alexa, mostrami il tempo alle 17:00'"). Lo schermo rende anche molto più semplici attività comuni come controllare una ricetta durante la cottura: gli utenti non devono ascoltare attentamente e mantenere tutte le informazioni nella loro testa; quando hanno bisogno delle informazioni, guardano semplicemente lo schermo.

Presentazione delle interfacce multimodali
Quando si tratta di utilizzare la voce nella progettazione dell'interfaccia utente, non pensare alla voce come a qualcosa che puoi usare da solo. Dispositivi come Amazon Echo Show includono uno schermo ma utilizzano la voce come metodo di input principale, offrendo un'esperienza utente più olistica. Questo è il primo passo verso una nuova generazione di interfacce utente: le interfacce multimodali.
Un'interfaccia multimodale è un'interfaccia che unisce voce, tocco, audio e diversi tipi di elementi visivi in un'unica interfaccia utente senza interruzioni. Amazon Echo Show è un eccellente esempio di dispositivo che sfrutta appieno un'interfaccia multimodale abilitata alla voce. Quando gli utenti interagiscono con Show, effettuano richieste proprio come farebbero con un dispositivo solo vocale; tuttavia, la risposta che riceveranno sarà probabilmente multimodale, contenente sia risposte vocali che visive.
I prodotti multimodali sono più complessi dei prodotti che si basano solo sulla grafica o solo sulla voce. Perché qualcuno dovrebbe creare un'interfaccia multimodale in primo luogo? Per rispondere a questa domanda, dobbiamo fare un passo indietro e vedere come le persone percepiscono l'ambiente che li circonda. Le persone hanno cinque sensi e la combinazione dei nostri sensi che lavorano insieme è il modo in cui percepiamo le cose. Ad esempio, i nostri sensi lavorano insieme quando ascoltiamo la musica in un concerto dal vivo. Rimuovi un senso (ad esempio, l'udito) e l'esperienza assume un contesto completamente diverso.

Per troppo tempo abbiamo pensato all'esperienza dell'utente come un design esclusivamente visivo o gestuale. È tempo di cambiare questo modo di pensare. Il design multimodale è un modo per pensare e progettare esperienze che collegano insieme le nostre capacità sensoriali.
Le interfacce multimodali si sentono come un modo più umano per comunicare tra utente e macchina. Apre nuove opportunità per interazioni più profonde. E oggi è molto più facile progettare interfacce multimodali perché i limiti tecnici che in passato vincolavano le interazioni con i prodotti vengono cancellati.
La differenza tra una GUI e un'interfaccia multimodale
La differenza fondamentale qui è che le interfacce multimodali come Amazon Echo Show sincronizzano le interfacce vocali e visive. Di conseguenza, quando progettiamo l'esperienza, la voce e le immagini non sono più parti indipendenti; sono parte integrante dell'esperienza che il sistema fornisce.
Canale visivo e vocale: quando utilizzarli
È importante pensare alla voce e alle immagini come canali di input e output. Ogni canale ha i suoi punti di forza e di debolezza.
Cominciamo con le immagini. È chiaro che alcune informazioni sono semplicemente più facili da capire quando le vediamo, piuttosto che quando le sentiamo. Gli elementi visivi funzionano meglio quando è necessario fornire:
- un lungo elenco di opzioni (leggere un lungo elenco richiederà molto tempo e sarà difficile da seguire);
- informazioni pesanti (come diagrammi e grafici);
- informazioni sui prodotti (ad esempio, prodotti nei negozi online; molto probabilmente, vorresti vedere un prodotto prima di acquistare) e confronto tra prodotti (come con la lunga lista di opzioni, sarebbe difficile fornire tutte le informazioni usando solo la voce) .
Per alcune informazioni, tuttavia, possiamo tranquillamente fare affidamento sulla comunicazione verbale. La voce potrebbe essere la soluzione giusta per i seguenti casi:
- comandi dell'utente (la voce è una modalità di input efficiente, che consente agli utenti di impartire comandi al sistema in modo rapido e aggirando complessi menu di navigazione);
- semplici istruzioni per l'utente (ad esempio, un controllo di routine su una prescrizione);
- avvisi e notifiche (ad esempio, un avviso acustico associato a notifiche vocali durante la guida).
Sebbene questi siano alcuni casi tipici di visuale e voce combinate, è importante sapere che non possiamo separare i due l'uno dall'altro. Possiamo creare un'esperienza utente migliore solo quando sia la voce che le immagini funzionano insieme. Ad esempio, supponiamo di voler acquistare un nuovo paio di scarpe. Potremmo usare la voce per richiedere dal sistema "Mostrami le scarpe New Balance". Il sistema elaborerà la tua richiesta e fornirà visivamente le informazioni sul prodotto (un modo più semplice per confrontare le scarpe).
Cosa devi sapere per progettare interfacce multimodali abilitate alla voce
La voce è una delle sfide più emozionanti per i designer di UX. Nonostante la sua novità, le regole fondamentali per la progettazione di un'interfaccia multimodale abilitata alla voce sono le stesse che utilizziamo per creare progetti visivi. I designer dovrebbero preoccuparsi dei propri utenti. Dovrebbero mirare a ridurre l'attrito per l'utente risolvendo i suoi problemi in modi efficienti e dare la priorità alla chiarezza per rendere chiare le scelte dell'utente.
Ma ci sono anche alcuni principi di progettazione unici per le interfacce multimodali.
Assicurati di risolvere il problema giusto
Il design dovrebbe risolvere i problemi. Ma è fondamentale risolvere i problemi giusti; in caso contrario, potresti dedicare molto tempo alla creazione di un'esperienza che non apporta molto valore agli utenti. Quindi, assicurati di concentrarti sulla risoluzione del problema giusto. Le interazioni vocali dovrebbero avere senso per l'utente; gli utenti dovrebbero avere un motivo convincente per utilizzare la voce sopra altri metodi di interazione (come fare clic o toccare). Ecco perché, quando crei un nuovo prodotto, anche prima di iniziare la progettazione, è essenziale condurre ricerche sugli utenti e determinare se la voce migliorerebbe l'UX.
Inizia con la creazione di una mappa del percorso dell'utente. Analizza la mappa del viaggio e trova i luoghi in cui l'inclusione della voce come canale gioverebbe all'UX.
- Trova i luoghi del viaggio in cui gli utenti potrebbero incontrare attrito e frustrazione. Usare la voce ridurrebbe l'attrito?
- Pensa al contesto dell'utente. La voce funzionerebbe per un contesto particolare?
- Pensa a ciò che è abilitato in modo univoco dalla voce. Ricorda i vantaggi esclusivi dell'uso della voce, come l'interazione a mani libere e senza occhi. La voce può aggiungere valore all'esperienza?
Crea flussi di conversazione
Idealmente, le interfacce progettate dovrebbero richiedere un costo di interazione pari a zero: gli utenti dovrebbero essere in grado di soddisfare le loro esigenze senza dedicare tempo aggiuntivo all'apprendimento di come interagire con il sistema. Ciò accade solo quando l'interazione vocale assomiglia a una conversazione reale, non a una finestra di dialogo di sistema racchiusa nel formato dei comandi vocali. La regola fondamentale di una buona interfaccia utente è semplice: i computer devono adattarsi agli esseri umani, non il contrario.
Le persone raramente hanno conversazioni piatte e lineari (conversazioni che durano solo un turno). Ecco perché, per rendere l'interazione con un sistema come una conversazione dal vivo, i progettisti dovrebbero concentrarsi sulla creazione di flussi di conversazione. Ogni flusso di conversazione è costituito da dialoghi, i percorsi che si verificano tra il sistema e l'utente. Ciascuna finestra di dialogo includerebbe i prompt del sistema e le possibili risposte dell'utente.
Un flusso conversazionale può essere presentato sotto forma di diagramma di flusso. Ciascun flusso dovrebbe concentrarsi su un caso d'uso particolare (ad esempio, impostare una sveglia utilizzando un sistema). Per la maggior parte delle finestre di dialogo in un flusso, è fondamentale considerare i percorsi di errore, quando le cose vanno fuori dai binari.
Ogni comando vocale dell'utente è costituito da tre elementi chiave: intento, enunciato e slot.
- L'intento è l'obiettivo dell'interazione dell'utente con un sistema abilitato alla voce.
Un intento è solo un modo elegante per definire lo scopo dietro un insieme di parole. Ogni interazione con un sistema porta all'utente qualche utilità. Che si tratti di informazioni o di un'azione, l'utilità è nell'intento. Comprendere l'intento dell'utente è una parte cruciale delle interfacce abilitate alla voce. Quando progettiamo una VUI, non sempre sappiamo con certezza quale sia l'intento di un utente, ma possiamo indovinarlo con elevata precisione. - L'espressione è il modo in cui l'utente formula la sua richiesta.
Di solito, gli utenti hanno più di un modo per formulare un comando vocale. Ad esempio, possiamo impostare una sveglia dicendo "Imposta sveglia alle 8:00" o "Sveglia alle 8:00 domani" o anche "Devo svegliarmi alle 8:00". I progettisti devono considerare ogni possibile variazione dell'enunciato. - Gli slot sono variabili che gli utenti utilizzano in un comando. A volte gli utenti devono fornire informazioni aggiuntive nella richiesta. Nel nostro esempio della sveglia, "8 am" è uno slot.
Non mettere le parole in bocca all'utente
La gente sa parlare. Non cercare di insegnare loro i comandi. Evita frasi come "Per inviare un appuntamento per una riunione, devi dire 'Calendario, riunioni, crea una nuova riunione'". Se devi spiegare i comandi, devi riconsiderare il modo in cui stai progettando il sistema. Punta sempre a una conversazione in linguaggio naturale e cerca di adattarti a stili di conversazione diversi).
Sforzati per la coerenza
È necessario ottenere coerenza nel linguaggio e nella voce in tutti i contesti. La coerenza aiuterà a costruire familiarità nelle interazioni.
Fornisci sempre feedback
La visibilità dello stato del sistema è uno dei principi fondamentali di una buona progettazione della GUI. Il sistema dovrebbe sempre tenere gli utenti informati di ciò che sta accadendo attraverso un feedback appropriato entro un tempo ragionevole. La stessa regola si applica al design VUI.
- Rendere l'utente consapevole che il sistema è in ascolto.
Mostra indicatori visivi quando il dispositivo sta ascoltando o elaborando la richiesta dell'utente. Senza feedback, l'utente può solo indovinare se il sistema sta facendo qualcosa. Ecco perché anche i dispositivi solo vocali come Amazon Echo e Google Home ci danno un bel feedback visivo (luci lampeggianti) quando ascoltano o cercano una risposta. - Fornire marcatori di conversazione.
Gli indicatori di conversazione indicano all'utente dove si trova nella conversazione. - Conferma quando un'attività è stata completata.
Ad esempio, quando gli utenti chiedono al sistema di casa intelligente abilitato alla voce "Spegni le luci in garage", il sistema dovrebbe informare l'utente che il comando è stato eseguito correttamente. Senza conferma, gli utenti dovranno entrare nel garage e controllare le luci. Sconfigge lo scopo del sistema di casa intelligente, che è quello di semplificare la vita dell'utente.
Evita le frasi lunghe
Quando si progetta un sistema abilitato alla voce, considerare il modo in cui si forniscono informazioni agli utenti. È relativamente facile sovraccaricare gli utenti con troppe informazioni quando usi frasi lunghe. Innanzitutto, gli utenti non possono conservare molte informazioni nella memoria a breve termine, quindi possono facilmente dimenticare alcune informazioni importanti. Inoltre, l'audio è un mezzo lento: la maggior parte delle persone può leggere molto più velocemente di quanto possa ascoltare.
Sii rispettoso del tempo del tuo utente; non leggere lunghi monologhi audio. Quando stai progettando una risposta, meno parole usi, meglio è. Ma ricorda che devi comunque fornire informazioni sufficienti per consentire all'utente di completare la propria attività. Pertanto, se non riesci a riassumere una risposta in poche parole, mostrala invece sullo schermo.

Fornisci i passaggi successivi in sequenza
Gli utenti possono essere sopraffatti non solo da frasi lunghe, ma anche dal numero di opzioni contemporaneamente. È fondamentale scomporre il processo di interazione con un sistema abilitato alla voce in piccoli frammenti. Limita il numero di scelte che l'utente ha in qualsiasi momento e assicurati che sappia cosa fare in ogni momento.
Quando si progetta un sistema vocale complesso con molte funzionalità, è possibile utilizzare la tecnica della divulgazione progressiva: presentare solo le opzioni o le informazioni necessarie per completare l'attività.
Avere una forte strategia di gestione degli errori
Naturalmente, il sistema dovrebbe innanzitutto evitare che si verifichino errori. Ma non importa quanto sia buono il tuo sistema abilitato alla voce, dovresti sempre progettare per lo scenario in cui il sistema non capisce l'utente. La tua responsabilità è progettare per questi casi.
Ecco alcuni consigli pratici per creare una strategia:
- Non incolpare l'utente.
Nella conversazione, non ci sono errori. Cerca di evitare risposte come "La tua risposta non è corretta". - Fornire flussi di ripristino degli errori.
Fornisci un'opzione per andare avanti e indietro in una conversazione o anche per uscire dal sistema, senza perdere informazioni importanti. Salva lo stato dell'utente durante il viaggio, in modo che possa riattivare il sistema da dove si era interrotto. - Consenti agli utenti di riprodurre le informazioni.
Fornire un'opzione per fare in modo che il sistema ripeta la domanda o la risposta. Questo potrebbe essere utile per domande o risposte complesse in cui sarebbe difficile per l'utente impegnare tutte le informazioni nella propria memoria di lavoro. - Fornire una dicitura di arresto.
In alcuni casi, l'utente non sarà interessato ad ascoltare un'opzione e vorrà che il sistema smetta di parlarne. Smettere di formulare dovrebbe aiutarli a fare proprio questo. - Gestisci le espressioni inaspettate con grazia.
Non importa quanto investi nella progettazione di un sistema, ci saranno situazioni in cui il sistema non comprende l'utente. È fondamentale gestire questi casi con grazia. Non abbiate paura di lasciare che il sistema ammetta una mancanza di comprensione. Il sistema dovrebbe comunicare ciò che ha compreso e fornire utili suggerimenti. - Usa l'analisi per migliorare la tua strategia di errore.
L'analisi può aiutarti a identificare le svolte sbagliate e le interpretazioni errate.
Tieni traccia del contesto
Assicurati che il sistema comprenda il contesto dell'input dell'utente. Ad esempio, quando qualcuno dice di voler prenotare un volo per San Francisco la prossima settimana, potrebbe fare riferimento a "esso" o "città" durante il flusso della conversazione. Il sistema dovrebbe ricordare ciò che è stato detto ed essere in grado di abbinarlo alle informazioni appena ricevute.
Scopri i tuoi utenti per creare interazioni più potenti
Un sistema abilitato alla voce diventa più sofisticato quando utilizza informazioni aggiuntive (come il contesto dell'utente o il comportamento passato) per comprendere ciò che l'utente desidera. Questa tecnica è chiamata interpretazione intelligente e richiede che il sistema impari attivamente sull'utente e sia in grado di adattare il suo comportamento di conseguenza. Questa conoscenza aiuterà il sistema a fornire risposte anche a domande complesse, come "Quale regalo dovrei comprare per il compleanno di mia moglie?"
Dai una personalità alla tua VUI
Ogni sistema abilitato alla voce ha un impatto emotivo sull'utente, indipendentemente dal fatto che tu lo pianifichi o meno. Le persone associano la voce agli umani piuttosto che alle macchine. Secondo la ricerca Speak Easy Global Edition, il 74% degli utenti regolari della tecnologia vocale si aspetta che i marchi abbiano voci e personalità uniche per i loro prodotti abilitati alla voce. È possibile creare empatia attraverso la personalità e raggiungere un livello più elevato di coinvolgimento degli utenti.
Cerca di riflettere il tuo marchio e la tua identità unici nella voce e nel tono che presenti. Costruisci una persona del tuo agente abilitato alla voce e affidati a questa persona quando crei i dialoghi.
Costruisci fiducia
Quando gli utenti non si fidano di un sistema, non hanno la motivazione per usarlo. Ecco perché costruire fiducia è un requisito della progettazione del prodotto. Due fattori hanno un impatto significativo sul livello di fiducia costruito: capacità del sistema e risultato valido.
La creazione di fiducia inizia con l'impostazione delle aspettative degli utenti. Le GUI tradizionali hanno molti dettagli visivi per aiutare l'utente a capire di cosa è capace il sistema. Con un sistema abilitato alla voce, i progettisti hanno meno strumenti su cui fare affidamento. Tuttavia, è fondamentale rendere il sistema naturalmente rilevabile; l'utente dovrebbe capire cosa è e cosa non è possibile con il sistema. Ecco perché un sistema abilitato alla voce potrebbe richiedere l'onboarding dell'utente, in cui si parla di ciò che il sistema può fare o di ciò che sa. Quando progetti l'onboarding, cerca di offrire esempi significativi per far sapere alle persone cosa può fare (gli esempi funzionano meglio delle istruzioni).
Quando si tratta di risultati validi, le persone sanno che i sistemi abilitati alla voce sono imperfetti. Quando un sistema fornisce una risposta, alcuni utenti potrebbero dubitare che la risposta sia corretta. ciò accade perché gli utenti non hanno alcuna informazione sul fatto che la loro richiesta sia stata compresa correttamente o quale algoritmo sia stato utilizzato per trovare la risposta. Per prevenire problemi di fiducia, utilizza lo schermo per supportare le prove, visualizza la query originale sullo schermo e fornisci alcune informazioni chiave sull'algoritmo. Ad esempio, quando un utente chiede "Mostrami i primi cinque film del 2018", il sistema può dire: "Ecco i primi cinque film del 2018 in base al botteghino negli Stati Uniti".
Non ignorare la sicurezza e la privacy dei dati
A differenza dei dispositivi mobili, che appartengono all'individuo, i dispositivi vocali tendono ad appartenere a un luogo, come una cucina. E di solito ci sono più persone nella stessa posizione. Immagina che qualcun altro possa interagire con un sistema che ha accesso a tutti i tuoi dati personali. Alcuni sistemi VUI come Amazon Alexa, Google Assistant e Apple Siri possono riconoscere singole voci, il che aggiunge un livello di sicurezza al sistema. Tuttavia, non garantisce che il sistema sarà in grado di riconoscere gli utenti in base alla loro firma vocale univoca nel 100% dei casi.
Il riconoscimento vocale è in continuo miglioramento e sarà difficile o quasi impossibile imitare una voce nel prossimo futuro. Tuttavia, nella realtà attuale, è fondamentale fornire un livello di autenticazione aggiuntivo per rassicurare l'utente che i suoi dati sono al sicuro. Se progetti un'app che funziona con dati sensibili, come informazioni sanitarie o dati bancari, potresti voler includere un passaggio di autenticazione aggiuntivo, come una password o un'impronta digitale o il riconoscimento facciale.
Condurre test di usabilità
Il test di usabilità è un requisito obbligatorio per qualsiasi sistema. Testare in anticipo, testare spesso dovrebbe essere una regola fondamentale del processo di progettazione. Raccogli i dati di ricerca degli utenti all'inizio e ripeti i tuoi progetti. Ma testare le interfacce multimodali ha le sue specifiche. Ecco due fasi che dovrebbero essere prese in considerazione:
- Fase di ideazione
Prova le tue finestre di dialogo di esempio. Esercitati a leggere ad alta voce dialoghi di esempio. Una volta che hai alcuni flussi di conversazione, registra entrambi i lati della conversazione (espressioni dell'utente e risposte del sistema) e ascolta la registrazione per capire se suonano naturali. - Prime fasi di sviluppo del prodotto (test con prototipi lo-fi)
Il test del Mago di Oz è adatto per testare le interfacce conversazionali. Il test del Mago di Oz è un tipo di test in cui un partecipante interagisce con un sistema che crede sia gestito da un computer ma in realtà sia gestito da un essere umano. Il partecipante al test formula una domanda e una persona reale risponde dall'altra parte. Questo metodo prende il nome dal libro Il meraviglioso mago di Oz di Frank Baum. Nel libro, un uomo normale si nasconde dietro una tenda, fingendo di essere un potente mago. Questo test consente di tracciare ogni possibile scenario di interazione e, di conseguenza, creare interazioni più naturali. Say Wizard è un ottimo strumento per aiutarti a eseguire un test dell'interfaccia vocale del Mago di Oz su macOS. - Fasi successive di sviluppo del prodotto (test con prototipi hi-fi)
Nei test di usabilità delle interfacce utente grafiche, spesso chiediamo agli utenti di parlare ad alta voce quando interagiscono con un sistema. Per un sistema abilitato alla voce, ciò non è sempre possibile perché il sistema ascolterebbe quella narrazione. Quindi, potrebbe essere meglio osservare le interazioni dell'utente con il sistema, piuttosto che chiedere loro di parlare ad alta voce.
Come creare un'interfaccia multimodale utilizzando Adobe XD
Ora che hai una solida comprensione di cos'è un'interfaccia multimodale e quali regole ricordare durante la progettazione, possiamo discutere come realizzare un prototipo di un'interfaccia multimodale.
La prototipazione è una parte fondamentale del processo di progettazione. Essere in grado di dare vita a un'idea e condividerla con gli altri è estremamente importante. Finora, i designer che volevano incorporare la voce nella prototipazione avevano pochi strumenti su cui fare affidamento, il più potente dei quali era un diagramma di flusso. Immaginare come un utente avrebbe interagito con un sistema ha richiesto molta immaginazione da parte di qualcuno che guardava il diagramma di flusso. Con Adobe XD, i designer ora hanno accesso al mezzo vocale e possono usarlo nei loro prototipi. XD collega perfettamente lo schermo e la prototipazione vocale in un'unica app.
Nuove esperienze, stesso processo
Anche se la voce è un mezzo completamente diverso da quello visivo, il processo di prototipazione per la voce in Adobe XD è praticamente lo stesso della prototipazione per una GUI. Il team di Adobe XD integra la voce in un modo che risulterà naturale e intuitivo per qualsiasi designer. I progettisti possono utilizzare i trigger vocali e la riproduzione vocale per interagire con i prototipi:
- I trigger vocali avviano un'interazione quando un utente pronuncia una particolare parola o frase (espressione).
- La riproduzione vocale offre ai progettisti l'accesso a un motore di sintesi vocale. XD pronuncerà parole e frasi definite da un designer. La riproduzione vocale può essere utilizzata per molti scopi diversi. Ad esempio, può fungere da riconoscimento (per rassicurare gli utenti) o da guida (in modo che gli utenti sappiano cosa fare dopo).
La cosa grandiosa di XD è che non ti obbliga a imparare le complessità di ogni piattaforma vocale.
Basta parole: vediamo come funziona in azione. Per tutti gli esempi che vedrai di seguito, ho utilizzato tavole da disegno create utilizzando il kit Adobe XD UI per Amazon Alexa (questo è un link per scaricare il kit). Il kit contiene tutti gli stili e i componenti necessari per creare esperienze per Amazon Alexa.
Supponiamo di avere le seguenti tavole da disegno:
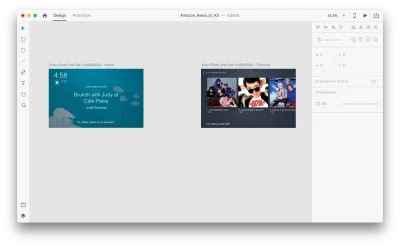
Entriamo nella modalità di prototipazione per aggiungere alcune interazioni vocali. Inizieremo con i trigger vocali. Insieme a trigger come tocca e trascina, ora siamo in grado di utilizzare la voce come trigger. Possiamo usare qualsiasi livello per i trigger vocali purché abbiano una maniglia che conduce a un'altra tavola da disegno. Colleghiamo insieme le tavole da disegno.
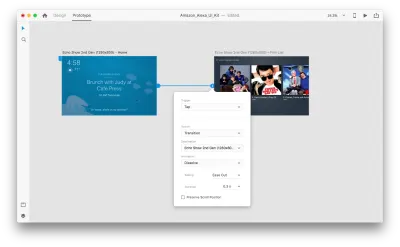
Una volta fatto, troveremo una nuova opzione "Voce" sotto "Trigger". Quando selezioniamo questa opzione, vedremo un campo "Comando" che possiamo usare per inserire un'espressione: questo è ciò che XD ascolterà effettivamente. Gli utenti dovranno pronunciare questo comando per attivare il trigger.
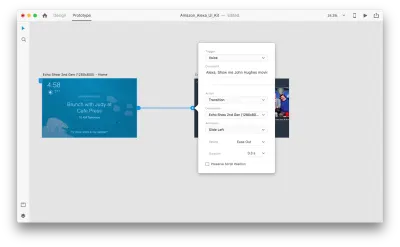
È tutto! Abbiamo definito la nostra prima interazione vocale. Ora, gli utenti possono dire qualcosa e un prototipo risponderà. Ma possiamo rendere questa interazione molto più potente aggiungendo la riproduzione vocale. Come accennato in precedenza, la riproduzione vocale consente a un sistema di pronunciare alcune parole.
Seleziona un'intera seconda tavola da disegno e fai clic sulla maniglia blu. Scegli un trigger "Time" con un ritardo e impostalo su 0,2 s. Sotto l'azione, troverai "Riproduzione vocale". Annoteremo ciò che l'assistente virtuale ci risponde.
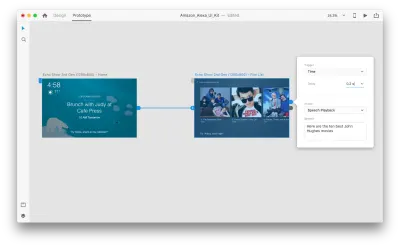
Siamo pronti per testare il nostro prototipo. Seleziona la prima tavola da disegno e facendo clic sul pulsante di riproduzione in alto a destra verrà avviata una finestra di anteprima. Quando interagisci con la prototipazione vocale, assicurati che il microfono sia acceso. Quindi, tieni premuta la barra spaziatrice per pronunciare il comando vocale. Questo input attiva l'azione successiva nel prototipo.
Usa l'animazione automatica per rendere l'esperienza più dinamica
L'animazione offre molti vantaggi alla progettazione dell'interfaccia utente. Ha chiari scopi funzionali, come ad esempio:
- comunicare le relazioni spaziali tra gli oggetti (da dove viene l'oggetto? Questi oggetti sono correlati?);
- comunicare l'affordance (cosa posso fare dopo?)
Ma gli scopi funzionali non sono gli unici vantaggi dell'animazione; l'animazione rende anche l'esperienza più viva e dinamica. Ecco perché le animazioni dell'interfaccia utente dovrebbero essere una parte naturale delle interfacce multimodali.
Con "Auto-Animate" disponibile in Adobe XD, diventa molto più semplice creare prototipi con transizioni animate coinvolgenti. Adobe XD fa tutto il duro lavoro per te, quindi non devi preoccuparti di questo. Tutto ciò che devi fare per creare una transizione animata tra due tavole da disegno è semplicemente duplicare una tavola da disegno, modificare le proprietà dell'oggetto nel clone (proprietà come dimensioni, posizione e rotazione) e applicare un'azione di animazione automatica. XD animerà automaticamente le differenze nelle proprietà tra ciascuna tavola da disegno.
Vediamo come funziona nel nostro design. Supponiamo di avere una lista della spesa esistente in Amazon Echo Show e di voler aggiungere un nuovo oggetto alla lista usando la voce. Duplica la seguente tavola da disegno:
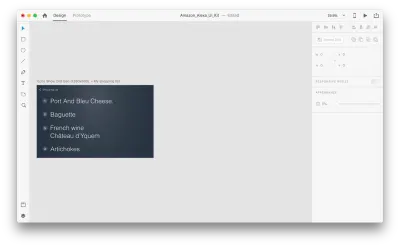
Introduciamo alcune modifiche nel layout: Aggiungi un nuovo oggetto. Non siamo limitati qui, quindi possiamo facilmente modificare qualsiasi proprietà come attributi del testo, colore, opacità, posizione dell'oggetto - in pratica, qualsiasi modifica apportiamo, XD si animerà tra di loro.
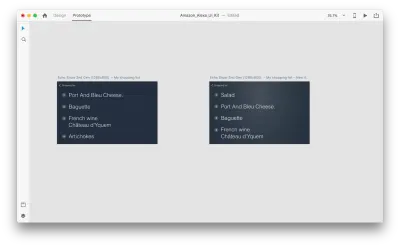
Quando colleghi due tavole da disegno insieme in modalità prototipo utilizzando Animazione automatica in "Azione", XD animerà automaticamente le differenze nelle proprietà tra ciascuna tavola da disegno.
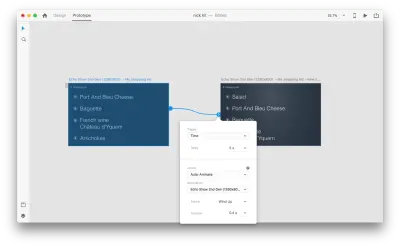
Ed ecco come apparirà l'interazione agli utenti:

Una cosa cruciale che deve essere menzionata: mantieni gli stessi nomi di tutti i livelli; in caso contrario, Adobe XD non sarà in grado di applicare l'animazione automatica.
Conclusione
Siamo agli albori di una rivoluzione dell'interfaccia utente. Una nuova generazione di interfacce — interfacce multimodali — non solo darà agli utenti più potenza, ma cambierà anche il modo in cui gli utenti interagiscono con i sistemi. We will probably still have displays, but we won't need keyboards to interact with the systems.
At the same time, the fundamental requirements for designing multimodal interfaces won't be much different from those of designing modern interfaces. Designers will need to keep the interaction simple; focus on the user and their needs; design, prototype, test and iterate.
And the great thing is that you don't need to wait to start designing for this new generation of interfaces. You can start today.
Questo articolo fa parte della serie di design UX sponsorizzata da Adobe. Lo strumento Adobe XD è realizzato per un processo di progettazione UX veloce e fluido, poiché ti consente di passare dall'idea al prototipo più velocemente. Progetta, prototipa e condividi: tutto in un'unica app. Puoi dare un'occhiata a progetti più stimolanti creati con Adobe XD su Behance e anche iscriverti alla newsletter di Adobe Experience Design per rimanere aggiornato e informato sulle ultime tendenze e approfondimenti per la progettazione UX/UI.