
Esercitazione sull'apprendimento automatico: impara il ML da zero
Pubblicato: 2022-02-17L'implementazione di soluzioni di intelligenza artificiale (AI) e machine learning (ML) continua a far progredire vari processi aziendali , con il miglioramento dell'esperienza del cliente come caso d'uso principale.
Oggi, l'apprendimento automatico ha una vasta gamma di applicazioni e la maggior parte di esse sono tecnologie che incontriamo quotidianamente. Ad esempio, Netflix o piattaforme OTT simili utilizzano l'apprendimento automatico per personalizzare i suggerimenti per ciascun utente. Quindi, se un utente guarda spesso thriller polizieschi o cerca gli stessi, il sistema di raccomandazione basato su ML della piattaforma inizierà a suggerire più film di un genere simile. Allo stesso modo, Facebook e Instagram personalizzano il feed di un utente in base ai post con cui interagiscono frequentemente.
In questo tutorial sull'apprendimento automatico di Python l , ci addentreremo nelle basi dell'apprendimento automatico. Abbiamo anche incluso un breve tutorial di deep learning per introdurre il concetto ai principianti.
Sommario
Che cos'è l'apprendimento automatico?
Il termine "apprendimento automatico" è stato coniato nel 1959 da Arthur Samuel, un pioniere nei giochi per computer e nell'intelligenza artificiale.
L'apprendimento automatico è un sottoinsieme dell'intelligenza artificiale. Si basa sul concetto che i software (programmi) possono imparare dai dati, decifrare schemi e prendere decisioni con la minima interferenza umana. In altre parole, ML è un'area della scienza computazionale che consente a un utente di fornire un'enorme quantità di dati a un algoritmo e fare in modo che il sistema analizzi e prenda decisioni basate sui dati in base ai dati di input. Pertanto, gli algoritmi ML non si basano su un modello predeterminato e invece "apprendono" direttamente le informazioni dai dati alimentati.
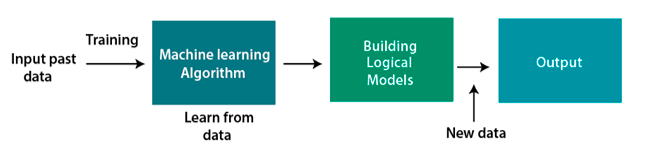
Fonte

Ecco un esempio semplificato:
Come si scrive un programma che identifichi i fiori in base al colore, alla forma del petalo o ad altre proprietà? Mentre il modo più ovvio sarebbe quello di stabilire regole di identificazione fondamentali, un tale approccio non renderà le regole ideali applicabili in tutti i casi. Tuttavia, l'apprendimento automatico richiede una strategia più pratica e solida e, invece di stabilire regole predeterminate, addestra il sistema alimentandolo con dati (immagini) di fiori diversi. Quindi, la prossima volta che al sistema vengono mostrati una rosa e un girasole, può classificare i due in base all'esperienza precedente.
Leggi Come apprendere l'apprendimento automatico - Passo dopo passo
Tipi di apprendimento automatico
La classificazione dell'apprendimento automatico si basa su come un algoritmo impara a diventare più accurato nel prevedere i risultati. Pertanto, esistono tre approcci di base all'apprendimento automatico: apprendimento supervisionato, apprendimento non supervisionato e apprendimento per rinforzo.
Apprendimento supervisionato
Nell'apprendimento automatico supervisionato, gli algoritmi vengono forniti con dati di addestramento etichettati. Inoltre, l'utente definisce le variabili che desidera che l'algoritmo valuti; le variabili target sono le variabili che vogliamo prevedere e le caratteristiche sono le variabili che ci aiutano a prevedere il target. Quindi, è più come se mostriamo all'algoritmo l'immagine di un pesce e diciamo "è un pesce", e poi mostriamo una rana e la indichiamo come una rana. Quindi, quando l'algoritmo è stato addestrato su un numero sufficiente di dati su pesci e rane, imparerà a differenziarli.
Apprendimento senza supervisione
L'apprendimento automatico non supervisionato coinvolge algoritmi che apprendono da dati di addestramento senza etichetta. Quindi, ci sono solo le funzionalità (variabili di input) e nessuna variabile di destinazione. I problemi di apprendimento senza supervisione includono il clustering, in cui le variabili di input con le stesse caratteristiche sono raggruppate e associate per decifrare relazioni significative all'interno del set di dati. Un esempio di raggruppamento è raggruppare le persone in fumatori e non fumatori. Al contrario, scoprire che i clienti che utilizzano smartphone acquisteranno anche cover telefoniche è associazione.
Insegnamento rafforzativo
L'apprendimento per rinforzo è una tecnica basata sui feed in cui i modelli di apprendimento automatico imparano a prendere una serie di decisioni in base al feedback che ricevono per le loro azioni. Per ogni azione buona, la macchina riceve un feedback positivo e per ogni azione negativa riceve una penalità o un feedback negativo. Pertanto, a differenza dell'apprendimento automatico supervisionato, un modello rinforzato apprende automaticamente utilizzando il feedback anziché i dati etichettati.
Leggi anche Cos'è l'apprendimento automatico e perché è importante
Perché usare Python per Machine Learning?
I progetti di apprendimento automatico differiscono dai progetti software tradizionali in quanto i primi coinvolgono competenze, stack tecnologici e ricerche approfondite distinti. Pertanto, l'implementazione di un progetto di apprendimento automatico di successo richiede un linguaggio di programmazione stabile, flessibile e che offra strumenti robusti. Python offre tutto, quindi vediamo principalmente progetti di machine learning basati su Python.
Indipendenza dalla piattaforma

La popolarità di Python è in gran parte dovuta al fatto che è un linguaggio indipendente dalla piattaforma ed è supportato dalla maggior parte delle piattaforme, inclusi Windows, macOS e Linux. Pertanto, gli sviluppatori possono creare programmi eseguibili autonomi su una piattaforma e distribuirli ad altri sistemi operativi senza richiedere un interprete Python. Pertanto, i modelli di apprendimento automatico di formazione diventano più gestibili ed economici.
Semplicità e Flessibilità
Dietro ogni modello di machine learning ci sono algoritmi e flussi di lavoro complessi che possono intimidire e opprimere gli utenti. Ma il codice conciso e leggibile di Python consente agli sviluppatori di concentrarsi sul modello di apprendimento automatico invece di preoccuparsi degli aspetti tecnici del linguaggio. Inoltre, Python è facile da imparare e può gestire complicate attività di machine learning, con conseguente creazione e test rapidi di prototipi.
Un'ampia selezione di framework e librerie
Python offre un'ampia selezione di framework e librerie che riducono notevolmente i tempi di sviluppo. Tali librerie hanno codici prescritti che gli sviluppatori utilizzano per eseguire attività di programmazione generali. Il repertorio di strumenti software di Python include Scikit-learn, TensorFlow e Keras per l'apprendimento automatico, Panda per l'analisi dei dati generici, NumPy e SciPy per l'analisi dei dati e il calcolo scientifico, Seaborn per la visualizzazione dei dati e altro ancora.
Impara anche la preelaborazione dei dati nell'apprendimento automatico: 7 semplici passaggi da seguire
Passaggi per implementare un progetto di apprendimento automatico Python
Se non conosci l'apprendimento automatico, il modo migliore per venire a patti con un progetto è elencare i passaggi chiave che devi coprire. Una volta che hai i passaggi, puoi usarli come modello per i set di dati successivi, colmare le lacune e modificare il tuo flusso di lavoro mentre procedi nelle fasi avanzate.
Ecco una panoramica di come implementare un progetto di machine learning con Python:
- Definisci il problema.
- Installa Python e SciPy.
- Carica il set di dati.
- Riassumi il set di dati.
- Visualizza il set di dati.
- Valuta gli algoritmi.
- Fare previsioni.
- Presenta i risultati.
Che cos'è una rete di apprendimento profondo?
Le reti di apprendimento profondo o reti neurali profonde (DNN) sono una branca dell'apprendimento automatico basato sull'imitazione del cervello umano. I DNN comprendono unità che combinano più input per produrre un unico output. Sono analoghi ai neuroni biologici che ricevono più segnali attraverso le sinapsi e inviano un singolo flusso di un potenziale d'azione lungo il suo neurone.
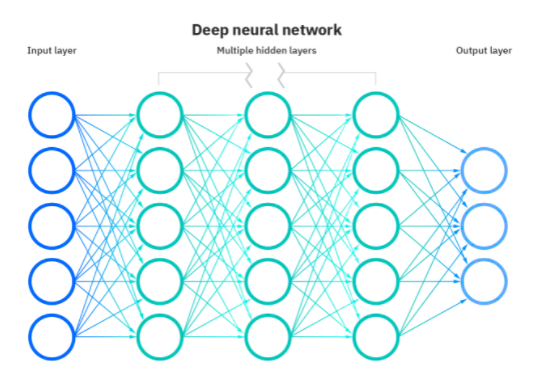
Fonte
In una rete neurale, la funzionalità simile al cervello si ottiene attraverso livelli di nodi costituiti da uno strato di input, uno o più strati nascosti e uno strato di output. Ogni neurone o nodo artificiale ha una soglia e un peso associati e si connette a un altro. Quando l'uscita di un nodo è al di sopra del valore di soglia definito, viene attivato e invia i dati al livello successivo della rete.
I DNN dipendono dai dati di addestramento per apprendere e perfezionare la loro accuratezza nel tempo. Costituiscono robusti strumenti di intelligenza artificiale, che consentono la classificazione dei dati e il raggruppamento ad alta velocità. Due dei domini di applicazione più comuni delle reti neurali profonde sono il riconoscimento delle immagini e il riconoscimento vocale.
Via avanti
Che si tratti di sbloccare uno smartphone con Face ID, di sfogliare film o di cercare un argomento casuale su Google, i consumatori moderni e orientati al digitale richiedono consigli più piccoli e una migliore personalizzazione. Indipendentemente dal settore o dal dominio, l'IA ha e continua a svolgere un ruolo significativo nel migliorare l'esperienza dell'utente. Inoltre, la semplicità e la versatilità di Python hanno reso lo sviluppo, l'implementazione e la manutenzione di progetti di intelligenza artificiale convenienti ed efficienti su tutte le piattaforme.
Impara il corso ML dalle migliori università del mondo. Guadagna master, Executive PGP o programmi di certificazione avanzati per accelerare la tua carriera.
Se hai trovato interessante questo tutorial sull'apprendimento automatico di Python per principianti, approfondisci l'argomento con il Master of Science in Machine Learning e AI di upGrad . Il programma online è progettato per i professionisti che desiderano apprendere competenze di intelligenza artificiale avanzate come la PNL, l'apprendimento profondo, l'apprendimento per rinforzo e altro ancora.
Punti salienti del corso:
- Master presso LJMU
- PGP esecutivo da IIIT Bangalore
- Oltre 750 ore di contenuti
- Oltre 40 sessioni dal vivo
- 12+ casi di studio e progetti
- 11 assegnazioni di codifica
- Copertura approfondita di 20 strumenti, lingue e librerie
- Assistenza professionale a 360 gradi
1. Python è buono per l'apprendimento automatico?
Python è uno dei migliori linguaggi di programmazione per l'implementazione di modelli di machine learning. Python fa appello sia agli sviluppatori che ai principianti grazie alla sua semplicità, flessibilità e curva di apprendimento delicata. Inoltre, Python è indipendente dalla piattaforma e ha accesso a librerie e framework che rendono più semplice e veloce la creazione e il test di modelli di machine learning.
2. L'apprendimento automatico con Python è difficile?
A causa della popolarità diffusa di Python come linguaggio di programmazione generico e della sua adozione nell'apprendimento automatico e nell'informatica scientifica, trovare un tutorial di apprendimento automatico Python è abbastanza facile. Inoltre, la curva di apprendimento delicata, il codice leggibile e preciso di Python lo rendono un linguaggio di programmazione adatto ai principianti.
3. L'intelligenza artificiale e l'apprendimento automatico sono la stessa cosa?
Sebbene i termini AI e machine learning siano spesso usati in modo intercambiabile, non sono la stessa cosa. Intelligenza artificiale (AI) è il termine generico per la branca dell'informatica che si occupa di macchine in grado di svolgere compiti solitamente svolti dagli esseri umani. Ma l'apprendimento automatico è un sottoinsieme dell'IA in cui le macchine vengono alimentate con dati e addestrate a prendere decisioni in base ai dati di input.