
15 Domande e risposte per l'intervista sull'apprendimento automatico per il 2022
Pubblicato: 2021-01-08Sei una persona che desidera fare una carriera di successo nel Machine Learning? Se è così, ottimo per te!
Ma prima devi prepararti per il rompighiaccio: l'intervista a ML.
Poiché il processo di preparazione per un colloquio può essere impegnativo, abbiamo deciso di intervenire: ecco un elenco curato delle 15 domande più frequenti nelle interviste di Machine Learning!
- Qual è la differenza tra Deep Learning e Machine Learning?
Sebbene l'apprendimento automatico comporti l'applicazione e l'utilizzo di algoritmi avanzati per analizzare i dati, scoprire i modelli nascosti all'interno dei dati e imparare da essi e, infine, applicare le informazioni apprese per prendere decisioni aziendali informate. Per quanto riguarda il Deep Learning, è un sottoinsieme del Machine Learning che prevede l'uso di reti neurali artificiali che traggono ispirazione dalla struttura della rete neurale del cervello umano. Il deep learning è ampiamente utilizzato nel rilevamento delle funzionalità.
- Definisci: precisione e richiamo.
Precisione o Valore predittivo positivo misura o più precisamente prevede il numero di veri positivi dichiarati da un modello rispetto al numero di positivi effettivamente dichiarati.
Recall o True Positive Rate si riferisce al numero di positivi dichiarati da un modello rispetto al numero effettivo di positivi presenti nei dati.

Partecipa al corso di Machine Learning online dalle migliori università del mondo: master, programmi post-laurea per dirigenti e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
- Spiegare i termini "pregiudizio" e "varianza". '
Durante il processo di addestramento, l'errore atteso di un algoritmo di apprendimento viene generalmente classificato o scomposto in due parti: bias e varianza. Mentre "bias" è una situazione di errore causata dall'uso di semplici ipotesi nell'algoritmo di apprendimento, "varianza" indica un errore causato dalla complessità dell'algoritmo di apprendimento nell'analisi dei dati. Bias misura la vicinanza del classificatore medio creato dall'algoritmo di apprendimento alla funzione target e la varianza misura quanto varia la previsione dell'algoritmo di apprendimento per diversi set di dati di addestramento.
- Come funziona una curva ROC?
La curva ROC o la curva caratteristica operativa del ricevitore è una rappresentazione grafica della variazione tra tassi di veri positivi e tassi di falsi positivi a soglie variabili. È uno strumento fondamentale per la valutazione dei test diagnostici e viene spesso utilizzato come rappresentazione del trade-off tra la sensibilità del modello (veri positivi) e la probabilità di innescare falsi allarmi (falsi positivi).
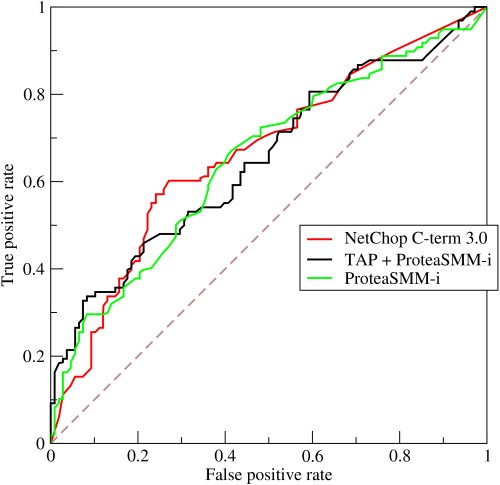
Fonte
- La curva rappresenta il compromesso tra sensibilità e specificità: se la sensibilità aumenta, la specificità diminuirà.
- Se la curva confina maggiormente verso l'asse sinistro e la parte superiore dello spazio ROC, il test è generalmente più accurato. Tuttavia, se la curva si avvicina alla diagonale di 45 gradi dello spazio ROC, il test è meno accurato o affidabile.
- La pendenza della linea tangente in corrispondenza di un punto di taglio indica il rapporto di verosimiglianza (LR) per quel particolare valore del test.
- L'area sotto la curva misura la precisione del test.
- Spiega la differenza tra gli errori di tipo 1 e di tipo 2?
L'errore di tipo 1 è un errore falso positivo che "afferma" che si è verificato un incidente quando, in realtà, non si è verificato nulla. Il miglior esempio di errore falso positivo è un falso allarme antincendio: l'allarme inizia a suonare quando non c'è incendio. Contrariamente a ciò, un errore di tipo 2 è un errore falso negativo che "afferma" che non si è verificato nulla quando è successo qualcosa. Sarebbe un errore di tipo 2 dire a una donna incinta che non sta portando un bambino.
- Perché Bayes viene chiamato "Naive Bayes?"
Naive Bayes viene definito "ingenuo" perché, sebbene abbia molte applicazioni pratiche, si basa sul presupposto che è impossibile da trovare nei dati della vita reale: tutte le caratteristiche di un set di dati sono cruciali, indipendenti e uguali. Nell'approccio di Naive Bayes, la probabilità condizionale è calcolata come il puro prodotto delle probabilità dei singoli componenti, implicando così la completa indipendenza delle caratteristiche. Sfortunatamente, questa ipotesi non può mai essere soddisfatta in uno scenario del mondo reale.
- Cosa si intende con il termine 'Overfitting'? Puoi evitarlo? Se é cosi, come?
Di solito, durante il processo di addestramento, un modello riceve grandi quantità di dati. Nel corso del processo, i dati iniziano ad apprendere anche dalle informazioni imprecise e dal rumore presenti nel set di dati campione. Ciò crea un'influenza negativa sulle prestazioni del modello sui nuovi dati, ovvero il modello non può classificare accuratamente nuove istanze/dati oltre a quelli del set di addestramento. Questo è noto come Overfitting.
Sì, è possibile evitare il Overfitting. Ecco come:
- Raccogli più dati (da fonti disparate) per addestrare il modello con campioni diversi.
- Applicare metodi di insieme (ad esempio, Random Forest) che utilizzano l'approccio bagging per ridurre al minimo la variazione nelle previsioni giustapponendo i risultati di più alberi decisionali su diverse unità del set di dati.
- Assicurati di utilizzare tecniche di convalida incrociata.
- Assegna un nome ai due metodi utilizzati per la calibrazione in Supervised Learning.
I due metodi di calibrazione nell'apprendimento supervisionato sono: calibrazione Platt e regressione isotonica. Entrambi questi metodi sono progettati specificamente per la classificazione binaria.
- Perché poti un albero decisionale?
Gli alberi decisionali devono essere potati per sbarazzarsi dei rami con deboli capacità predittive. Ciò aiuta a ridurre al minimo il quoziente di complessità del modello Decision Tree e ad ottimizzarne l'accuratezza predittiva. La potatura può essere eseguita dall'alto verso il basso o dal basso verso l'alto. La potatura degli errori ridotta, la potatura della complessità dei costi, la potatura della complessità degli errori e la potatura degli errori minimi sono alcuni dei metodi di potatura dell'albero decisionale più utilizzati.

- Cosa si intende per punteggio F1?
In parole povere, il punteggio F1 è una misura delle prestazioni di un modello: una media della Precisione e del Richiamo di un modello, con risultati vicini a 1 che sono i migliori e quelli che si avvicinano a 0 sono i peggiori. Il punteggio F1 può essere utilizzato nei test di classificazione che non danno importanza ai veri negativi.
- Distinguere tra un algoritmo generativo e discriminativo.
Mentre un algoritmo generativo apprende le categorie di dati, un algoritmo discriminativo apprende la distinzione tra diverse categorie di dati. Quando si tratta di attività di classificazione, i modelli discriminativi in genere superano i modelli generativi.
- Che cos'è l'apprendimento dell'insieme?
Ensemble Learning utilizza una combinazione di algoritmi di apprendimento per ottimizzare le prestazioni predittive dei modelli. In questo metodo, più modelli come classificatori o esperti vengono generati strategicamente e combinati per prevenire l'overfitting nei modelli. Viene utilizzato principalmente per migliorare la previsione, la classificazione, l'approssimazione di funzioni, le prestazioni, ecc., Di un modello.
- Definisci 'Trucco del kernel'.
Il metodo Kernel Trick prevede l'uso di funzioni del kernel che possono operare in uno spazio di funzionalità implicito e di dimensione superiore senza dover calcolare esplicitamente le coordinate dei punti all'interno di quella dimensione. Le funzioni del kernel calcolano i prodotti interni tra le immagini di tutte le coppie di dati presenti in uno spazio di funzionalità. Questa procedura è computazionalmente più economica rispetto al calcolo esplicito delle coordinate ed è nota come Kernel Trick.
- Come dovresti gestire i dati mancanti o danneggiati in un set di dati?
Per trovare i dati mancanti/corrotti in un set di dati, è necessario eliminare le righe e le colonne o sostituirle con altri valori. La libreria Pandas ha due ottimi metodi per trovare dati mancanti/corrotti: isnull() e dropna(). Entrambe queste funzioni sono progettate specificamente per aiutarti a trovare le righe/colonne di dati con dati mancanti/corrotti e a eliminare quei valori.
- Cos'è una tabella hash?
Una tabella hash è una struttura dati che crea un array associativo, in cui una chiave viene mappata su valori specifici utilizzando una funzione hash. Le tabelle hash sono utilizzate principalmente nell'indicizzazione del database.
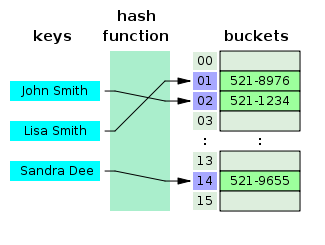
Fonte
Questo elenco di domande ha solo lo scopo di introdurti alle basi del Machine Learning e, francamente, queste venti domande sono solo una goccia nel mare. L'apprendimento automatico avanza mentre parliamo e quindi, con il tempo, emergeranno nuovi concetti. La chiave per inchiodare le tue interviste ML, quindi, sta nel nutrire un costante bisogno di imparare e migliorare le competenze. Quindi, inizia e flagella Internet, leggi giornali, unisciti a comunità online, partecipa a conferenze e seminari ML: ci sono tanti modi per imparare.
Per entrare in una grande organizzazione, è essenziale un certificato di un'istituzione rinomata. Dai un'occhiata al programma Executive PG di IIIT-B in Machine Learning e AI e ottieni assistenza sul lavoro dalle migliori aziende di ML e AI.
Quali sono i limiti dell'Ensemble Learning?
Gli approcci di insieme possono aiutare nella riduzione della varianza e nello sviluppo di modelli più robusti. Tuttavia, ci sono alcuni inconvenienti nell'uso di tecniche d'insieme, come la mancanza di spiegabilità e prestazioni. Inoltre, tieni presente che l'efficacia degli ensemble deriva dalla loro capacità di aggregare più modelli che si concentrano su diversi aspetti della questione. Tuttavia, hanno un periodo di previsione più lungo perché potresti aver bisogno di previsioni da centinaia di modelli. Anche se hanno proiezioni migliori, il guadagno in termini di precisione potrebbe non valerne la pena.
Quanto tempo è necessario per imparare il Machine Learning?
Quando si tratta di Machine Learning, le complesse tecnologie utilizzate per lo stesso potrebbero facilmente spaventare le persone. Tuttavia, capirlo poco a poco non è difficile. Una precedente esperienza in statistica, matematica avanzata e così via ti aiuterà senza dubbio a comprendere rapidamente tutti i concetti. Tuttavia, poiché il background educativo e le competenze variano da persona a persona, un individuo può imparare il ML in tre settimane mentre un altro potrebbe aver bisogno di un anno.
In che modo l'apprendimento automatico viene utilizzato nella nostra vita quotidiana?
Gmail classifica le email come essenziali classificandole come Principali, Promozioni, Social e Aggiorna utilizzando Machine Learning. Le aziende utilizzano le reti neurali per rilevare transazioni fraudolente in base a dati come l'ultima frequenza delle transazioni, l'importo della transazione e il tipo di commerciante. I rilevatori di plagio utilizzano anche l'apprendimento automatico. Quando si tratta di ingegneria ML, ci vogliono circa sei mesi per finire.