
25 Domande e risposte sull'intervista sull'apprendimento automatico – Regressione lineare
Pubblicato: 2022-09-08È una pratica comune testare gli aspiranti alla scienza dei dati su algoritmi di apprendimento automatico comunemente usati nelle interviste. Questi algoritmi convenzionali sono regressione lineare, regressione logistica, clustering, alberi decisionali ecc. Ci si aspetta che i data scientist possiedano una conoscenza approfondita di questi algoritmi.
Abbiamo consultato responsabili delle assunzioni e data scientist di varie organizzazioni per conoscere le tipiche domande sul ML che pongono in un'intervista. Sulla base del loro ampio feedback, è stata preparata una serie di domande e risposte per aiutare gli aspiranti data scientist nelle loro conversazioni. Le domande del colloquio di regressione lineare sono le più comuni nelle interviste di Machine Learning. Domande e risposte su questi algoritmi verranno fornite in una serie di quattro post sul blog.
I migliori corsi di apprendimento automatico e corsi di intelligenza artificiale online
| Master of Science in Machine Learning e AI presso LJMU | Programma post-laurea esecutivo in Machine Learning e AI di IIITB | |
| Programma di certificazione avanzato in Machine Learning e NLP da IIITB | Programma di certificazione avanzato in Machine Learning e Deep Learning da IIITB | Programma post-laurea esecutivo in Data Science e Machine Learning presso l'Università del Maryland |
| Per esplorare tutti i nostri corsi, visita la nostra pagina qui sotto. | ||
| Corsi di apprendimento automatico | ||
Ogni post del blog tratterà il seguente argomento: -
- Regressione lineare
- Regressione logistica
- Raggruppamento
- Alberi decisionali e domande che riguardano tutti gli algoritmi
Iniziamo con la regressione lineare!
1. Che cos'è la regressione lineare?
In termini semplici, la regressione lineare è un metodo per trovare la migliore retta adatta ai dati forniti, cioè trovare la migliore relazione lineare tra le variabili indipendenti e dipendenti.
In termini tecnici, la regressione lineare è un algoritmo di apprendimento automatico che trova la migliore relazione di adattamento lineare su qualsiasi dato, tra variabili indipendenti e dipendenti. Viene eseguito principalmente con il metodo della somma dei residui quadrati.
Competenze di apprendimento automatico richieste
| Corsi di Intelligenza Artificiale | Corsi di Tableau |
| Corsi di PNL | Corsi di deep learning |

2. Enunciare le ipotesi in un modello di regressione lineare.
Ci sono tre ipotesi principali in un modello di regressione lineare:
- L'ipotesi sulla forma del modello:
Si presume che esista una relazione lineare tra le variabili dipendenti e indipendenti. È noto come "ipotesi di linearità". - Ipotesi sui residui:
- Assunzione di normalità: si assume che i termini di errore, ε (i) , siano normalmente distribuiti.
- Assunzione media zero: si presume che i residui abbiano un valore medio pari a zero.
- Assunzione di varianza costante: si presume che i termini residui abbiano la stessa (ma sconosciuta) varianza, σ 2 Questa ipotesi è anche nota come assunzione di omogeneità o omoscedasticità.
- Assunzione di errore indipendente: si presume che i termini residui siano indipendenti l'uno dall'altro, ovvero la loro covarianza a coppie sia zero.
- Ipotesi sugli stimatori:
- Le variabili indipendenti vengono misurate senza errori.
- Le variabili indipendenti sono linearmente indipendenti l'una dall'altra, cioè non c'è multicollinearità nei dati.
Spiegazione:
- Questo è autoesplicativo.
- Se i residui non sono distribuiti normalmente, la loro casualità viene persa, il che implica che il modello non è in grado di spiegare la relazione nei dati.
Inoltre, la media dei residui dovrebbe essere zero.
Y (i)i = β 0 + β 1 x (i) + ε (i)
Questo è il modello lineare assunto, dove ε è il termine residuo.
E(Y) = E( β 0 + β 1 x (i) + ε (i) )
= E( β 0 + β 1 x (i) + ε (i) )
Se l'aspettativa (media) dei residui, E(ε (i) ), è zero, le aspettative della variabile target e del modello diventano gli stessi, che è uno degli obiettivi del modello.
I residui (noti anche come termini di errore) dovrebbero essere indipendenti. Ciò significa che non c'è correlazione tra i residui ei valori previsti, o tra i residui stessi. Se è presente qualche correlazione, significa che c'è qualche relazione che il modello di regressione non è in grado di identificare. - Se le variabili indipendenti non sono linearmente indipendenti l'una dall'altra, si perde l'unicità della soluzione dei minimi quadrati (o della soluzione dell'equazione normale).
Partecipa al corso di intelligenza artificiale online dalle migliori università del mondo: master, programmi post-laurea esecutivi e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
3. Che cos'è l'ingegneria delle funzionalità? Come lo applichi nel processo di modellazione?
L'ingegneria delle caratteristiche è il processo di trasformazione dei dati grezzi in caratteristiche che rappresentano meglio il problema alla base dei modelli predittivi
, con conseguente miglioramento dell'accuratezza del modello su dati invisibili.
In parole povere, ingegneria delle funzionalità significa lo sviluppo di nuove funzionalità che possono aiutarti a comprendere e modellare il problema in un modo migliore. L'ingegneria delle funzionalità è di due tipi: guidata dal business e basata sui dati. L'ingegneria delle funzionalità orientata al business ruota attorno all'inclusione di funzionalità da un punto di vista aziendale. Il compito qui è trasformare le variabili aziendali in caratteristiche del problema. In caso di ingegneria delle funzionalità basata sui dati, le funzionalità aggiunte non hanno alcuna interpretazione fisica significativa, ma aiutano il modello nella previsione della variabile target.
Cordiali saluti: corso nlp gratuito!
Per applicare l'ingegneria delle funzionalità, è necessario conoscere completamente il set di dati. Ciò implica sapere quali sono i dati forniti, cosa significano, quali sono le caratteristiche grezze, ecc. È inoltre necessario avere un'idea chiara del problema, ad esempio quali fattori influenzano la variabile target, qual è l'interpretazione fisica della variabile , eccetera.
4. A cosa serve la regolarizzazione? Spiegare le regolarizzazioni L1 e L2.
La regolarizzazione è una tecnica che viene utilizzata per affrontare il problema dell'overfitting del modello. Quando un modello molto complesso viene implementato sui dati di addestramento, si sovrappone. A volte, il modello semplice potrebbe non essere in grado di generalizzare i dati e il modello complesso si adatta. Per affrontare questo problema, viene utilizzata la regolarizzazione.
La regolarizzazione non è altro che l'aggiunta dei termini del coefficiente (beta) alla funzione di costo in modo che i termini siano penalizzati e siano di piccola entità. Questo essenzialmente aiuta a catturare le tendenze nei dati e allo stesso tempo previene l'overfitting non lasciando che il modello diventi troppo complesso.
- Regolarizzazione L1 o LASSO: qui si sommano i valori assoluti dei coefficienti alla funzione di costo. Questo può essere visto nella seguente equazione; la parte evidenziata corrisponde alla regolarizzazione L1 o LASSO. Questa tecnica di regolarizzazione dà risultati scarsi, che portano anche alla selezione delle caratteristiche.
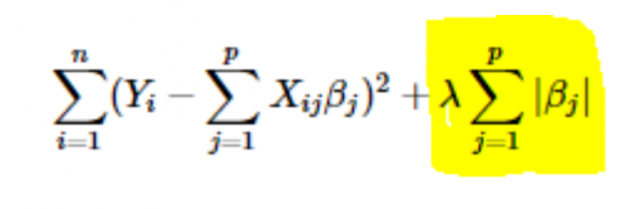
- Regolarizzazione L2 o Ridge: qui i quadrati dei coefficienti vengono sommati alla funzione di costo. Questo può essere visto nella seguente equazione, dove la parte evidenziata corrisponde alla regolarizzazione L2 o Ridge.
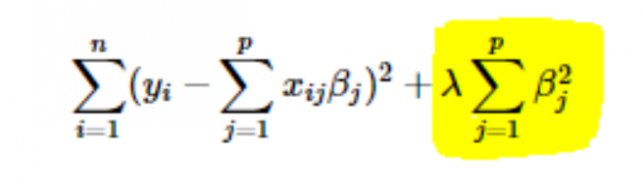
5. Come scegliere il valore della velocità di apprendimento del parametro (α)?
Selezionare il valore del tasso di apprendimento è un affare complicato. Se il valore è troppo piccolo, l'algoritmo di discesa del gradiente impiega secoli per convergere alla soluzione ottimale. D'altra parte, se il valore della velocità di apprendimento è elevato, la discesa del gradiente supererà la soluzione ottimale e molto probabilmente non convergerà mai alla soluzione ottimale.
Per superare questo problema, puoi provare diversi valori di alfa su un intervallo di valori e tracciare il costo rispetto al numero di iterazioni. Quindi, in base ai grafici, si può scegliere il valore corrispondente al grafico che mostra il rapido decremento. 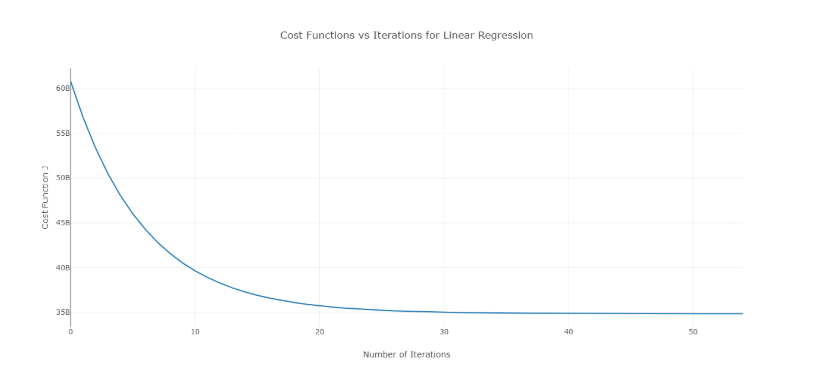
Il grafico di cui sopra è un costo ideale rispetto alla curva del numero di iterazioni. Si noti che il costo inizialmente diminuisce all'aumentare del numero di iterazioni, ma dopo alcune iterazioni la discesa del gradiente converge e il costo non diminuisce più.
Se vedi che il costo aumenta con il numero di iterazioni, il parametro del tasso di apprendimento è alto e deve essere ridotto.
6. Come scegliere il valore del parametro di regolarizzazione (λ)?
La selezione del parametro di regolarizzazione è un affare complicato. Se il valore di λ è troppo alto, porterà a valori estremamente piccoli del coefficiente di regressione β , che porterà all'underfitting del modello (alta distorsione – bassa varianza). D'altra parte, se il valore di λ è 0 (molto piccolo), il modello tenderà a sovraadattare i dati di addestramento (bassa distorsione – alta varianza).
Non esiste un modo corretto per selezionare il valore di λ . Quello che puoi fare è avere un sottocampione di dati ed eseguire l'algoritmo più volte su set diversi. Qui, la persona deve decidere quanta varianza può essere tollerata. Una volta che l'utente è soddisfatto della varianza, è possibile scegliere il valore di λ per l'intero set di dati.
Una cosa da notare è che il valore di λ qui selezionato era ottimale per quel sottoinsieme, non per l'intero addestramento dei dati.
7. Possiamo usare la regressione lineare per l'analisi delle serie temporali?
È possibile utilizzare la regressione lineare per l'analisi delle serie temporali, ma i risultati non sono promettenti. Quindi, generalmente non è consigliabile farlo. Le ragioni alla base di questo sono -
- I dati delle serie temporali vengono utilizzati principalmente per la previsione del futuro, ma la regressione lineare raramente fornisce buoni risultati per la previsione futura poiché non è pensata per l'estrapolazione.
- Per lo più, i dati delle serie temporali hanno uno schema, ad esempio durante le ore di punta, le festività natalizie, ecc., che molto probabilmente verrebbero trattati come valori anomali nell'analisi di regressione lineare.
8. A quale valore si avvicina la somma dei residui di una regressione lineare? Giustificare.
Ans La somma dei residui di una regressione lineare è 0. La regressione lineare lavora sul presupposto che gli errori (residui) siano normalmente distribuiti con una media di 0, cioè
Y = β T X + ε
Qui, Y è la variabile target o dipendente,
β è il vettore del coefficiente di regressione,
X è la matrice delle caratteristiche che contiene tutte le caratteristiche come le colonne,
ε è il termine residuo tale che ε ~ N(0,σ 2 ).
Quindi, la somma di tutti i residui è il valore atteso dei residui moltiplicato per il numero totale di punti dati. Poiché l'aspettativa dei residui è 0, la somma di tutti i termini residui è zero.
Nota : N(μ,σ 2 ) è la notazione standard per una distribuzione normale con media μ e deviazione standard σ 2 .
9. In che modo la multicollinearità influisce sulla regressione lineare?
Ans Multicollinearità si verifica quando alcune delle variabili indipendenti sono altamente correlate (positivamente o negativamente) tra loro. Questa multicollinearità causa un problema in quanto è contraria all'assunto di base della regressione lineare. La presenza di multicollinearità non pregiudica la capacità predittiva del modello. Quindi, se vuoi solo previsioni, la presenza di multicollinearità non influisce sul tuo output. Tuttavia, se si desidera trarre alcune informazioni dal modello e applicarle, ad esempio, in alcuni modelli di business, ciò potrebbe causare problemi.
Uno dei principali problemi causati dalla multicollinearità è che porta a interpretazioni errate e fornisce intuizioni errate. I coefficienti di regressione lineare suggeriscono la variazione media del valore target se una caratteristica viene modificata di un'unità. Quindi, se esiste la multicollinearità, ciò non è vero poiché la modifica di una caratteristica porterà a modifiche nella variabile correlata e conseguenti modifiche nella variabile target. Ciò porta a informazioni errate e può produrre risultati pericolosi per un'azienda.
Un modo molto efficace per affrontare la multicollinearità è l'uso del VIF (Variance Inflation Factor). Più alto è il valore di VIF per una caratteristica, più linearmente correlata è quella caratteristica. È sufficiente rimuovere la funzione con un valore VIF molto elevato e riqualificare il modello sul set di dati rimanente.
10. Qual è la forma normale (equazione) della regressione lineare? Quando dovrebbe essere preferito al metodo della discesa in pendenza?
L'equazione normale per la regressione lineare è —
β=(X T X) -1 . X T Y
Qui, Y=β T X è il modello per la regressione lineare,
Y è la variabile target o dipendente,
β è il vettore del coefficiente di regressione, che si ottiene usando l'equazione normale,
X è la matrice delle caratteristiche che contiene tutte le caratteristiche come le colonne.
Nota qui che la prima colonna nella matrice X è composta da tutti gli 1. Questo serve per incorporare il valore di offset per la retta di regressione.
Confronto tra la discesa del gradiente e l'equazione normale:
| Discesa graduale | Equazione normale |
| Richiede l'ottimizzazione degli iperparametri per alpha (parametro di apprendimento) | Nessun bisogno del genere |
| È un processo iterativo | È un processo non iterativo |
| O(kn 2 ) complessità temporale | O(n 3 ) complessità temporale dovuta alla valutazione di X T X |
| Preferito quando n è estremamente grande | Diventa abbastanza lento per valori elevati di n |
Qui, ' k ' è il numero massimo di iterazioni per la discesa del gradiente e ' n ' è il numero totale di punti dati nel set di addestramento.
Chiaramente, se disponiamo di dati di allenamento di grandi dimensioni, l'equazione normale non è preferita per l'uso. Per piccoli valori di ' n ', l'equazione normale è più veloce della discesa del gradiente.
Cos'è l'apprendimento automatico e perché è importante
11. Esegui la tua regressione su diversi sottoinsiemi di dati e in ogni sottoinsieme il valore beta per una determinata variabile varia notevolmente. Quale potrebbe essere il problema qui?
Questo caso implica che il set di dati è eterogeneo. Quindi, per superare questo problema, il set di dati dovrebbe essere raggruppato in diversi sottoinsiemi e quindi dovrebbero essere creati modelli separati per ciascun cluster. Un altro modo per affrontare questo problema è utilizzare modelli non parametrici, come alberi decisionali, che possono gestire dati eterogenei in modo abbastanza efficiente.

12. La tua regressione lineare non viene eseguita e comunica che esiste un numero infinito di migliori stime per i coefficienti di regressione. Cosa potrebbe esserci di sbagliato?
Questa condizione si verifica quando c'è una perfetta correlazione (positiva o negativa) tra alcune variabili. In questo caso, non esiste un valore univoco per i coefficienti e quindi si verifica la condizione data.
13. Cosa intendi per R 2 rettificato ? In che cosa differisce da R 2 ?
R 2 rettificato , proprio come R 2 , è un rappresentante del numero di punti che si trovano attorno alla linea di regressione. Cioè, mostra quanto bene il modello si adatta ai dati di addestramento. La formula per R 2 rettificata è -
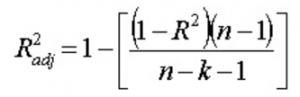
Qui, n è il numero di punti dati e k è il numero di caratteristiche.
Uno svantaggio di R 2 è che aumenterà sempre con l'aggiunta di una nuova funzionalità, indipendentemente dal fatto che la nuova funzionalità sia utile o meno. La rettificata R 2 supera questo inconveniente. Il valore della R 2 rettificata aumenta solo se la nuova caratteristica aggiunta gioca un ruolo significativo nel modello.
14. Come interpreti la curva del valore residuo rispetto a quello montato?
Il grafico del valore residuo rispetto a quello adattato viene utilizzato per vedere se i valori e i residui previsti hanno una correlazione o meno. Se i residui sono distribuiti normalmente, con una media attorno al valore adattato e una varianza costante, il nostro modello funziona bene; in caso contrario, c'è qualche problema con il modello.
Il problema più comune che può essere riscontrato durante l'addestramento del modello su un ampio intervallo di un set di dati è l' eteroscedasticità (questo è spiegato nella risposta di seguito). La presenza di eteroschedasticità può essere facilmente osservata tracciando la curva del valore residuo vs. fitto.
15. Che cos'è l'eteroscedasticità? Quali sono le conseguenze e come superarle?
Una variabile casuale si dice eteroscedastica quando sottopopolazioni diverse hanno variabilità diverse (deviazione standard).
L'esistenza dell'eteroscedasticità dà origine ad alcuni problemi nell'analisi di regressione poiché l'assunto afferma che i termini di errore non sono correlati e, quindi, la varianza è costante. La presenza di eteroschedasticità può essere spesso vista sotto forma di un diagramma di dispersione a forma di cono per i valori residui rispetto a quelli adattati.
Uno dei presupposti di base della regressione lineare è che l'eteroscedasticità non è presente nei dati. A causa della violazione delle ipotesi, gli stimatori dei minimi quadrati ordinari (OLS) non sono i migliori stimatori lineari imparziali (BLU). Quindi, non danno la minima varianza rispetto ad altri stimatori lineari imparziali (LUE).
Non esiste una procedura fissa per superare l'eteroscedasticità. Tuttavia, ci sono alcuni modi che possono portare a una riduzione dell'eteroscedasticità. Sono -
- Logaritmizzazione dei dati: una serie che aumenta in modo esponenziale spesso si traduce in una maggiore variabilità. Questo può essere superato utilizzando la trasformazione del registro.
- Utilizzo della regressione lineare ponderata: qui, il metodo OLS viene applicato ai valori ponderati di X e Y. Un modo consiste nell'associare pesi direttamente correlati all'entità della variabile dipendente.
16. Cos'è la VIF? Come lo calcoli?
Il fattore di inflazione della varianza (VIF) viene utilizzato per verificare la presenza di multicollinearità in un set di dati. È calcolato come—
Qui, VIF j è il valore di VIF per la j- esima variabile,
Rj 2 è il valore R 2 del modello quando quella variabile viene regredita rispetto a tutte le altre variabili indipendenti.
Se il valore di VIF è alto per una variabile, implica che R 2 il valore del modello corrispondente è alto, cioè altre variabili indipendenti sono in grado di spiegare quella variabile. In parole povere, la variabile dipende linearmente da alcune altre variabili.
17. Come fai a sapere che la regressione lineare è adatta per un dato dato?
Per vedere se la regressione lineare è adatta per un dato dato, è possibile utilizzare un grafico a dispersione. Se la relazione sembra lineare, possiamo optare per un modello lineare. Ma se non è il caso, dobbiamo applicare alcune trasformazioni per rendere lineare la relazione. Tracciare i grafici a dispersione è facile in caso di regressione lineare semplice o univariata. Ma in caso di regressione lineare multivariata, è possibile tracciare grafici a dispersione bidimensionali a coppie, grafici rotanti e grafici dinamici.
18. Come viene utilizzato il test di ipotesi nella regressione lineare?
Il test di ipotesi può essere effettuato in regressione lineare per i seguenti scopi:
- Per verificare se un predittore è significativo per la previsione della variabile target. Due metodi comuni per questo sono:
- Utilizzando i valori p:
Se il valore p di una variabile è maggiore di un certo limite (di solito 0,05), la variabile è insignificante nella previsione della variabile target. - Verificando i valori del coefficiente di regressione:
Se il valore del coefficiente di regressione corrispondente a un predittore è zero, quella variabile è insignificante nella previsione della variabile target e non ha alcuna relazione lineare con essa.
- Utilizzando i valori p:
- Per verificare se i coefficienti di regressione calcolati sono buoni stimatori dei coefficienti effettivi.
19. Spiegare la discesa del gradiente rispetto alla regressione lineare.
La discesa del gradiente è un algoritmo di ottimizzazione. Nella regressione lineare, viene utilizzato per ottimizzare la funzione di costo e trovare i valori dei βs (stimatori) corrispondenti al valore ottimizzato della funzione di costo.
La discesa del gradiente funziona come una pallina che rotola lungo un grafico (ignorando l'inerzia). La pallina si muove lungo la direzione della massima pendenza e si ferma sulla superficie piana (minima). 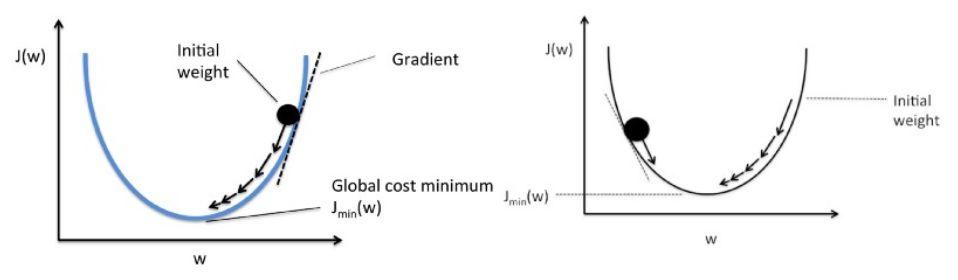
Matematicamente, lo scopo della discesa del gradiente per la regressione lineare è trovare la soluzione di
ArgMin J(Θ 0 ,Θ 1 ), dove J(Θ 0 ,Θ 1 ) è la funzione di costo della regressione lineare. È dato da - 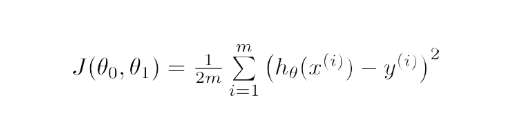
Qui h è il modello di ipotesi lineare, h=Θ 0 + Θ 1 x, y è il vero output e m è il numero di punti dati nell'insieme di addestramento.
La discesa del gradiente inizia con una soluzione casuale e quindi, in base alla direzione del gradiente, la soluzione viene aggiornata al nuovo valore in cui la funzione di costo ha un valore inferiore.
L'aggiornamento è:
Ripetere fino alla convergenza 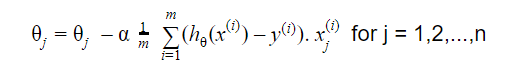
20. Come si interpreta un modello di regressione lineare?
Un modello di regressione lineare è abbastanza facile da interpretare. Il modello è della seguente forma: 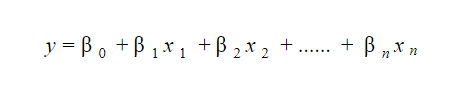
Il significato di questo modello sta nel fatto che si possono facilmente interpretare e comprendere i cambiamenti marginali e le loro conseguenze. Ad esempio, se il valore di x 0 aumenta di 1 unità, mantenendo costanti le altre variabili, l'aumento totale del valore di y sarà β i . Matematicamente, il termine di intercettazione ( β 0 ) è la risposta quando tutti i termini predittori sono impostati su zero o non vengono considerati.
Queste 6 tecniche di apprendimento automatico stanno migliorando l'assistenza sanitaria
21. Che cos'è la regressione robusta?
Un modello di regressione dovrebbe essere di natura robusta. Ciò significa che con modifiche in alcune osservazioni, il modello non dovrebbe cambiare drasticamente. Inoltre, non dovrebbe essere molto influenzato dai valori anomali.
Un modello di regressione con OLS (Ordinary Least Squares) è abbastanza sensibile agli outlier. Per superare questo problema, possiamo utilizzare il metodo WLS (Weighted Least Squares) per determinare gli stimatori dei coefficienti di regressione. Qui, vengono dati meno pesi ai valori anomali o ai punti di leva elevati nel raccordo, rendendo questi punti meno impattanti.
22. Quali grafici si consiglia di osservare prima del montaggio del modello?
Prima di adattare il modello, è necessario essere ben consapevoli dei dati, ad esempio quali sono le tendenze, la distribuzione, l'asimmetria, ecc. nelle variabili. Grafici come istogrammi, box plot e dot plot possono essere utilizzati per osservare la distribuzione delle variabili. Oltre a questo, bisogna anche analizzare quale sia la relazione tra variabili dipendenti e indipendenti. Questo può essere fatto mediante grafici a dispersione (in caso di problemi univariati), grafici rotanti, grafici dinamici, ecc.
23. Qual è il modello lineare generalizzato?
Il modello lineare generalizzato è la derivata del modello di regressione lineare ordinaria. GLM è più flessibile in termini di residui e può essere utilizzato laddove la regressione lineare non sembra appropriata. GLM consente alla distribuzione dei residui di essere diversa da una distribuzione normale. Generalizza la regressione lineare consentendo al modello lineare di collegarsi alla variabile target utilizzando la funzione di collegamento. La stima del modello viene eseguita utilizzando il metodo della stima di massima verosimiglianza.
24. Spiegare il trade-off bias-varianza.
Bias si riferisce alla differenza tra i valori previsti dal modello e i valori reali. È un errore. Uno degli obiettivi di un algoritmo ML è avere una bassa distorsione.
La varianza si riferisce alla sensibilità del modello a piccole fluttuazioni nel set di dati di addestramento. Un altro obiettivo di un algoritmo ML è avere una varianza bassa.
Per un set di dati che non è esattamente lineare, non è possibile avere contemporaneamente bias e varianza bassi. Un modello a linea retta avrà una bassa varianza ma un'elevata polarizzazione, mentre un polinomio di alto grado avrà una bassa deviazione ma una varianza elevata.
Non c'è modo di sfuggire alla relazione tra bias e varianza nell'apprendimento automatico.
- Diminuendo il bias aumenta la varianza.
- Diminuendo la varianza aumenta la distorsione.
Quindi, c'è un compromesso tra i due; lo specialista ML deve decidere, in base al problema assegnato, quanto bias e varianza possono essere tollerati. Sulla base di questo, viene costruito il modello finale.
25. In che modo le curve di apprendimento possono aiutare a creare un modello migliore?
Le curve di apprendimento danno l'indicazione della presenza di overfitting o underfitting.
In una curva di apprendimento, l'errore di addestramento e l'errore di convalida incrociata vengono tracciati rispetto al numero di punti dati di addestramento. Una tipica curva di apprendimento è simile a questa: 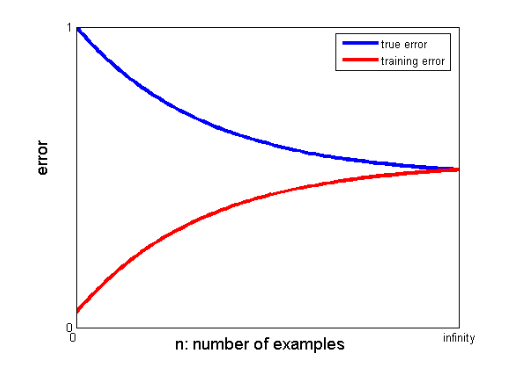
Se l'errore di addestramento e l'errore vero (errore di convalida incrociata) convergono allo stesso valore e il valore corrispondente dell'errore è alto, indica che il modello è underfitting e soffre di una distorsione elevata.
Interviste di apprendimento automatico e come ottenerle
Le interviste di apprendimento automatico possono variare in base ai tipi o alle categorie, ad esempio alcuni reclutatori pongono molte domande sui colloqui di regressione lineare . Quando si candidano per il ruolo di ingegnere dell'apprendimento automatico, possono specializzarsi in categorie come codifica, ricerca, case study, gestione dei progetti, presentazione, progettazione di sistemi e statistiche. Ci concentreremo sui tipi più comuni di categorie e su come prepararli.
- Codifica
La codifica e la programmazione sono componenti significative di un colloquio di apprendimento automatico e vengono spesso utilizzate per selezionare i candidati. Per fare bene in queste interviste, devi avere solide capacità di programmazione. Le interviste di codifica durano in genere dai 45 ai 60 minuti e sono composte da due sole domande. L'intervistatore pone l'argomento e prevede che il candidato lo affronterà nel minor tempo possibile.
Come prepararsi – Puoi prepararti per queste interviste avendo una buona comprensione delle strutture dei dati, delle complessità del tempo e dello spazio, delle capacità di gestione e della capacità di comprendere e risolvere un problema. upGrad ha un ottimo corso di ingegneria del software che può aiutarti a migliorare le tue capacità di programmazione e ad affrontare quel colloquio.
2. Apprendimento automatico
La tua comprensione dell'apprendimento automatico sarà valutata attraverso interviste. I livelli convoluzionali, le reti neurali ricorrenti, le reti generative dell'avversario, il riconoscimento vocale e altri argomenti possono essere trattati a seconda delle esigenze occupazionali.
Come prepararsi – Per essere in grado di superare questo colloquio, devi assicurarti di avere una conoscenza approfondita dei ruoli e delle responsabilità lavorative. Questo ti aiuterà a identificare le specifiche del ML che devi studiare. Tuttavia, se non ti imbatti in alcuna specifica, devi comprendere a fondo le basi. Un corso approfondito in ML fornito da upGrad può aiutarti in questo. Puoi anche studiare gli ultimi articoli su ML e AI per comprendere le loro ultime tendenze e incorporarli regolarmente.
3. Proiezione
Questa intervista è in qualche modo informale e tipicamente uno dei punti iniziali dell'intervista. Un potenziale datore di lavoro spesso lo gestisce. L'obiettivo principale di questo colloquio è fornire al candidato un'idea dell'attività, del ruolo e dei doveri. In un'atmosfera più informale, il candidato viene anche interrogato sul suo passato per determinare se la sua area di interesse corrisponde alla posizione.
Come prepararsi – Questa è una parte molto non tecnica dell'intervista. Tutto ciò che serve è la tua onestà e le basi della tua specializzazione in Machine Learning.
4. Progettazione del sistema
Tali interviste mettono alla prova la capacità di una persona di creare una soluzione completamente scalabile dall'inizio alla fine. La maggior parte degli ingegneri è così preoccupata per un problema che spesso trascura il quadro più ampio. Un colloquio di progettazione del sistema richiede la comprensione di numerosi elementi che si combinano per produrre una soluzione. Questi elementi includono il layout front-end, il sistema di bilanciamento del carico, la cache e altro ancora. Un sistema end-to-end efficace e scalabile è più facile da sviluppare quando questi problemi sono ben compresi.
Come prepararsi – Comprendere i concetti ei componenti del progetto di progettazione del sistema. Usa esempi di vita reale per spiegare la struttura al tuo intervistatore per una migliore comprensione del progetto.
Blog popolari di Machine Learning e Intelligenza Artificiale
| IoT: storia, presente e futuro | Esercitazione sull'apprendimento automatico: impara il ML | Cos'è l'algoritmo? Semplice e facile |
| Stipendio per ingegnere robotico in India: tutti i ruoli | Un giorno nella vita di un ingegnere di machine learning: cosa fanno? | Cos'è l'IoT (Internet delle cose) |
| Permutazione vs combinazione: differenza tra permutazione e combinazione | Le 7 tendenze principali nell'intelligenza artificiale e nell'apprendimento automatico | Machine Learning con R: tutto ciò che devi sapere |
Se c'è un divario significativo tra i valori convergenti dell'addestramento e gli errori di convalida incrociata, ovvero l'errore di convalida incrociata è significativamente maggiore dell'errore di addestramento, suggerisce che il modello sta sovraadattando i dati di addestramento e soffre di una varianza elevata .
Ingegneri dell'apprendimento automatico: miti e realtà
Questa è la fine della prima sezione di questa serie. Attenersi alla parte successiva della serie che consiste in domande basate sulla regressione logistica . Sentiti libero di postare i tuoi commenti.
Co-autore di – Ojas Agarwal
Puoi controllare il nostro programma Executive PG in Machine Learning e AI , che offre workshop pratici pratici, tutor del settore individuale, 12 casi di studio e incarichi, stato di Alumni IIIT-B e altro ancora.
Cosa intendi per regolarizzazione?
La regolarizzazione è una strategia per affrontare il problema dell'overfitting del modello. L'overfitting si verifica quando un modello complicato viene applicato ai dati di addestramento. Il modello di base potrebbe non essere in grado di generalizzare i dati a volte e il modello complicato potrebbe sovradimensionare i dati. La regolarizzazione viene utilizzata per alleviare questo problema. La regolarizzazione è il processo di aggiunta di termini di coefficienti (beta) al problema di minimizzazione in modo tale che i termini siano penalizzati e abbiano una modesta entità. Ciò aiuta essenzialmente a identificare i modelli di dati e allo stesso tempo a prevenire l'overfitting impedendo che il modello diventi troppo complesso.
Cosa capisci dell'ingegneria delle funzionalità?
Il processo di modifica dei dati originali in funzionalità che descrivono meglio il problema alla base dei modelli predittivi, con conseguente maggiore accuratezza del modello su dati invisibili, è noto come ingegneria delle funzionalità. In parole povere, l'ingegneria delle funzionalità si riferisce alla creazione di funzionalità aggiuntive che possono aiutare a comprendere e modellare meglio un problema. Esistono due tipi di ingegneria delle funzionalità: guidata dal business e basata sui dati. L'incorporazione di funzionalità da un punto di vista commerciale è al centro dell'ingegneria delle funzionalità orientata al business.
Qual è il compromesso bias-varianza?
Il divario tra il modello - valori previsti e valori effettivi è indicato come bias. È un errore. Una bassa distorsione è uno degli obiettivi di un algoritmo ML. La vulnerabilità del modello a piccoli cambiamenti nel set di dati di addestramento viene definita varianza. La bassa varianza è un altro obiettivo di un algoritmo ML. È impossibile avere sia una bassa distorsione che una bassa varianza in un set di dati che non è perfettamente lineare. La varianza di un modello a linea retta è bassa, ma la distorsione è ampia, mentre la varianza di un polinomio di alto grado è bassa, ma la distorsione è alta. Nell'apprendimento automatico, il legame tra distorsione e variazione è inevitabile.