
Classificatore KNN per l'apprendimento automatico: tutto ciò che devi sapere
Pubblicato: 2021-09-28Ricordi il tempo in cui l'intelligenza artificiale (AI) era solo un concetto limitato ai romanzi e ai film di fantascienza? Bene, grazie al progresso tecnologico, l'IA è qualcosa con cui ora conviviamo ogni giorno. Dato che Alexa e Siri sono presenti a nostra completa disposizione alle piattaforme OTT che "raccolgono manualmente" i film che vorremmo guardare, l'IA è quasi diventata all'ordine del giorno ed è qui per dirlo nel prossimo futuro.
Tutto questo è possibile grazie ad algoritmi ML avanzati. Oggi parleremo di uno di questi utili algoritmi ML, il classificatore K-NN.
Una branca dell'intelligenza artificiale e dell'informatica, l'apprendimento automatico utilizza dati e algoritmi per imitare la comprensione umana migliorando gradualmente l'accuratezza degli algoritmi. L'apprendimento automatico implica l'addestramento di algoritmi per fare previsioni o classificazioni e scoprire informazioni chiave che guidano il processo decisionale strategico all'interno di aziende e applicazioni.
L'algoritmo KNN (k-neighbor più vicino) è un algoritmo di apprendimento automatico supervisionato fondamentale utilizzato per risolvere affermazioni di problemi di regressione e classificazione. Quindi, tuffiamoci per saperne di più sul classificatore K-NN.
Sommario
Apprendimento automatico supervisionato e non supervisionato
L'apprendimento supervisionato e non supervisionato sono due approcci di base della scienza dei dati ed è pertinente conoscere la differenza prima di entrare nei dettagli di KNN.
L'apprendimento supervisionato è un approccio di apprendimento automatico che utilizza set di dati etichettati per aiutare a prevedere i risultati. Tali set di dati sono progettati per "supervisionare" o addestrare algoritmi per prevedere i risultati o classificare i dati in modo accurato. Pertanto, input e output etichettati consentono al modello di apprendere nel tempo migliorandone la precisione.

L'apprendimento supervisionato coinvolge due tipi di problemi: classificazione e regressione. Nei problemi di classificazione , gli algoritmi allocano i dati dei test in categorie discrete, come separare i gatti dai cani.
Un esempio significativo nella vita reale potrebbe essere la classificazione delle e-mail di spam in una cartella separata dalla tua casella di posta. D'altra parte, il metodo di regressione dell'apprendimento supervisionato allena gli algoritmi per comprendere la relazione tra variabili indipendenti e dipendenti. Utilizza diversi punti dati per prevedere valori numerici, ad esempio proiettare i ricavi delle vendite per un'azienda.
L'apprendimento non supervisionato , al contrario, utilizza algoritmi di apprendimento automatico per l'analisi e il raggruppamento di set di dati non etichettati. Pertanto, non è necessario l'intervento umano ("senza supervisione") affinché gli algoritmi identifichino schemi nascosti nei dati.
I modelli di apprendimento non supervisionato hanno tre applicazioni principali: associazione, raggruppamento e riduzione della dimensionalità. Tuttavia, non entreremo nei dettagli poiché esula dal nostro ambito di discussione.
K-vicino più vicino (KNN)
L'algoritmo K-Nearest Neighbor o KNN è un algoritmo di apprendimento automatico basato sul modello di apprendimento supervisionato. L'algoritmo K-NN funziona assumendo che cose simili esistano vicine l'una all'altra. Pertanto, l'algoritmo K-NN utilizza la somiglianza delle caratteristiche tra i nuovi punti dati e i punti nel set di addestramento (casi disponibili) per prevedere i valori dei nuovi punti dati. In sostanza, l'algoritmo K-NN assegna un valore al punto dati più recente in base a quanto assomiglia ai punti nel set di addestramento. L'algoritmo K-NN trova applicazione sia nei problemi di classificazione che di regressione, ma viene utilizzato principalmente per problemi di classificazione.
Ecco un esempio per comprendere il classificatore K-NN.

Fonte
Nell'immagine sopra, il valore di input è una creatura con somiglianze sia con un gatto che con un cane. Tuttavia, vogliamo classificarlo in un gatto o in un cane. Quindi, possiamo usare l'algoritmo K-NN per questa classificazione. Il modello K-NN troverà somiglianze tra il nuovo set di dati (input) e le immagini di cani e gatti disponibili (set di dati di addestramento). Successivamente, il modello inserirà il nuovo punto dati nella categoria del gatto o del cane in base alle caratteristiche più simili.
Allo stesso modo, la categoria A (punti verdi) e la categoria B (punti arancioni) hanno l'esempio grafico sopra. Abbiamo anche un nuovo punto dati (punto blu) che rientrerà in una delle categorie. Possiamo risolvere questo problema di classificazione utilizzando un algoritmo K-NN e identificare la nuova categoria di punti dati.
Definizione delle proprietà dell'algoritmo K-NN
Le due proprietà seguenti definiscono al meglio l'algoritmo K-NN:
- È un algoritmo di apprendimento pigro perché invece di apprendere immediatamente dal set di addestramento, l'algoritmo K-NN memorizza il set di dati e si allena dal set di dati al momento della classificazione.
- K-NN è anche un algoritmo non parametrico , il che significa che non fa ipotesi sui dati sottostanti.
Funzionamento dell'algoritmo K-NN
Ora, diamo un'occhiata ai seguenti passaggi per capire come funziona l'algoritmo K-NN.
Passaggio 1: caricare i dati di addestramento e test.
Passaggio 2: scegli i punti dati più vicini, ovvero il valore di K.
Passaggio 3: calcola la distanza di K numero di vicini (la distanza tra ciascuna riga di dati di addestramento e dati di test). Il metodo euclideo è più comunemente usato per calcolare la distanza.
Passaggio 4: prendi i K vicini più vicini in base alla distanza euclidea calcolata.
Passaggio 5: tra i vicini K più vicini, contare il numero di punti dati in ciascuna categoria.
Passaggio 6: assegna i nuovi punti dati alla categoria per la quale il numero di vicini è massimo.
Passaggio 7: fine. Il modello è ora pronto.
Partecipa ai corsi di intelligenza artificiale online delle migliori università del mondo: master, programmi post-laurea esecutivi e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
Scegliere il valore di K
K è un parametro critico nell'algoritmo K-NN. Quindi, dobbiamo tenere a mente alcuni punti prima di decidere un valore di K.
L'uso delle curve di errore è un metodo comune per determinare il valore di K. L'immagine seguente mostra le curve di errore per diversi valori di K per i dati di test e di addestramento.


Fonte
Nell'esempio grafico sopra, l'errore del treno è zero a K=1 nei dati di addestramento perché il vicino più vicino al punto è quel punto stesso. Tuttavia, l'errore del test è elevato anche a valori bassi di K. Questo è chiamato varianza elevata o overfitting dei dati. L'errore del test si riduce all'aumentare del valore di K., ma dopo un certo valore di K, vediamo che l'errore del test aumenta di nuovo, chiamato bias o underfitting. Pertanto, l'errore dei dati di test è inizialmente elevato a causa della varianza, successivamente si riduce e si stabilizza e, con un ulteriore aumento del valore di K, l'errore di test aumenta nuovamente a causa della distorsione.
Pertanto, il valore di K al quale l'errore di test si stabilizza ed è basso viene preso come valore ottimale di K. Considerando la curva di errore sopra, K=8 è il valore ottimale.
Un esempio per comprendere il funzionamento dell'algoritmo K-NN
Considera un set di dati che è stato tracciato come segue:

Fonte
Supponiamo che ci sia un nuovo punto dati (punto nero) in (60,60) che dobbiamo classificare nella classe viola o rossa. Useremo K=3, il che significa che il nuovo punto dati troverà tre punti dati più vicini, due nella classe rossa e uno nella classe viola.
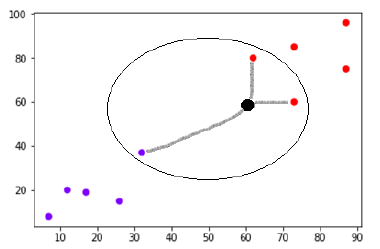
Fonte
I vicini più vicini sono determinati calcolando la distanza euclidea tra due punti. Ecco un'illustrazione per mostrare come viene eseguito il calcolo.

Fonte
Ora, poiché due (su tre) dei vicini più vicini del nuovo punto dati (punto nero) si trovano nella classe rossa, anche il nuovo punto dati verrà assegnato alla classe rossa.
Partecipa al corso di Machine Learning online dalle migliori università del mondo: master, programmi post-laurea per dirigenti e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
K-NN come classificatore (implementazione in Python)
Ora che abbiamo avuto una spiegazione semplificata dell'algoritmo K-NN, passiamo all'implementazione dell'algoritmo K-NN in Python. Ci concentreremo solo sul classificatore K-NN.
Passaggio 1: importa i pacchetti Python necessari.

Fonte
Passaggio 2: scarica il set di dati dell'iris dall'UCI Machine Learning Repository. Il suo collegamento web è "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
Passaggio 3: assegna i nomi delle colonne al set di dati.

Fonte
Passaggio 4: leggi il set di dati su Pandas DataFrame.

Fonte
Passaggio 5: la preelaborazione dei dati viene eseguita utilizzando le seguenti righe di script.

Fonte
Passaggio 6: dividere il set di dati in test e dividere il treno. Il codice seguente dividerà il set di dati in 40% di dati di test e 60% di dati di addestramento.

Fonte
Passaggio 7: il ridimensionamento dei dati viene eseguito come segue:

Fonte
Passaggio 8: addestra il modello utilizzando la classe KNeighborsClassifier di sklearn.

Fonte
Passaggio 9: fai una previsione utilizzando il seguente script:

Fonte
Passaggio 10: stampa i risultati.

Fonte
Produzione:

Fonte
Cosa succede dopo? Iscriviti al programma Advanced Certificate in Machine Learning da IIT Madras e upGrad
Supponiamo che tu stia aspirando a diventare un esperto di data scientist o un professionista dell'apprendimento automatico. Allora il Corso di Certificazione Avanzata in Machine Learning e Cloud di IIT Madras e upGrad fa proprio al caso tuo!
Il programma online di 12 mesi è appositamente progettato per i professionisti che desiderano padroneggiare concetti di Machine Learning, Big Data Processing, Data Management, Data Warehousing, Cloud e distribuzione di modelli di Machine Learning.
Ecco alcuni punti salienti del corso per darti un'idea migliore di ciò che offre il programma:
- Certificazione prestigiosa accettata a livello mondiale da IIT Madras
- Oltre 500 ore di apprendimento, oltre 20 casi di studio e progetti, oltre 25 sessioni di tutoraggio del settore, oltre 8 incarichi di codifica
- Copertura completa di 7 linguaggi e strumenti di programmazione
- 4 settimane di progetto capstone del settore
- Laboratori pratici pratici
- Rete peer-to-peer offline
Iscriviti oggi per saperne di più sul programma!
Conclusione
Con il tempo, i Big Data continuano a crescere e l'intelligenza artificiale diventa sempre più intrecciata con le nostre vite. Di conseguenza, c'è un forte aumento della domanda di professionisti della scienza dei dati che possono sfruttare la potenza dei modelli di machine learning per raccogliere informazioni dettagliate sui dati e migliorare i processi aziendali critici e, in generale, il nostro mondo. Senza dubbio, il campo dell'intelligenza artificiale e dell'apprendimento automatico sembra davvero promettente. Con upGrad puoi essere certo che la tua carriera nell'apprendimento automatico e nel cloud sarà gratificante!
Perché K-NN è un buon classificatore?
Il vantaggio principale di K-NN rispetto ad altri algoritmi di apprendimento automatico è che possiamo utilizzare convenientemente K-NN per la classificazione multiclasse. Pertanto, K-NN è il miglior algoritmo se abbiamo bisogno di classificare i dati in più di due categorie o se i dati comprendono più di due etichette. Inoltre, è ideale per dati non lineari e ha una precisione relativamente elevata.
Qual è il limite dell'algoritmo K-NN?
L'algoritmo K-NN funziona calcolando la distanza tra i punti dati. Quindi, è abbastanza ovvio che si tratta di un algoritmo relativamente più dispendioso in termini di tempo e richiederà più tempo per la classificazione in alcuni casi. Pertanto, è meglio non utilizzare troppi punti dati durante l'utilizzo di K-NN per la classificazione multiclasse. Altre limitazioni includono memoria elevata e sensibilità a funzioni irrilevanti.
Quali sono le applicazioni reali di K-NN?
K-NN ha diversi casi d'uso reali nell'apprendimento automatico, come il rilevamento della grafia, il riconoscimento vocale, il riconoscimento video e il riconoscimento delle immagini. Nel settore bancario, K-NN viene utilizzato per prevedere se un individuo ha diritto a un prestito in base al fatto che abbia caratteristiche simili agli inadempienti. In politica, K-NN può essere utilizzato per classificare i potenziali elettori in classi diverse come "voteranno per il partito X" o "voteranno per il partito Y", ecc.