
Presentazione dell'API basata sui componenti
Pubblicato: 2022-03-10Questo articolo è stato aggiornato il 31 gennaio 2019 per rispondere al feedback dei lettori. L'autore ha aggiunto funzionalità di query personalizzate all'API basata sui componenti e ne descrive il funzionamento .
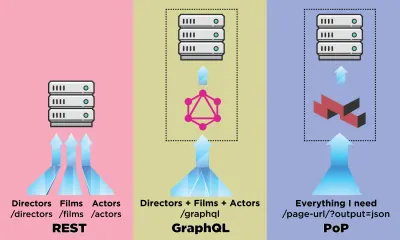
Un'API è il canale di comunicazione di un'applicazione per caricare i dati dal server. Nel mondo delle API, REST è stata la metodologia più consolidata, ma ultimamente è stata messa in ombra da GraphQL, che offre importanti vantaggi rispetto a REST. Mentre REST richiede più richieste HTTP per recuperare un set di dati per eseguire il rendering di un componente, GraphQL può interrogare e recuperare tali dati in un'unica richiesta e la risposta sarà esattamente quella richiesta, senza sovra o sotto-recupero dei dati come accade tipicamente in RIPOSO.
In questo articolo, descriverò un altro modo di recuperare i dati che ho progettato e chiamato "PoP" (e qui open source), che espande l'idea di recuperare i dati per diverse entità in un'unica richiesta introdotta da GraphQL e prende un fare un ulteriore passo avanti, ovvero mentre REST recupera i dati per una risorsa e GraphQL recupera i dati per tutte le risorse in un componente, l'API basata sui componenti può recuperare i dati per tutte le risorse da tutti i componenti in una pagina.
L'utilizzo di un'API basata su componenti ha più senso quando il sito Web stesso è costruito utilizzando componenti, ovvero quando la pagina Web è composta in modo iterativo da componenti che avvolgono altri componenti fino a quando, nella parte superiore, otteniamo un singolo componente che rappresenta la pagina. Ad esempio, la pagina Web mostrata nell'immagine seguente è costruita con componenti, che sono delineati da quadrati:
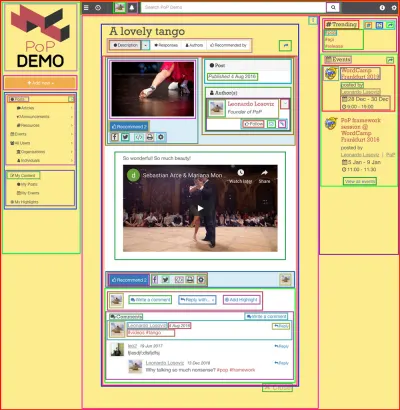
Un'API basata su componenti è in grado di effettuare una singola richiesta al server richiedendo i dati per tutte le risorse in ogni componente (così come per tutti i componenti nella pagina) che si ottiene mantenendo le relazioni tra i componenti in la struttura dell'API stessa.
Tra gli altri, questa struttura offre i seguenti numerosi vantaggi:
- Una pagina con molti componenti attiverà solo una richiesta invece di molte;
- I dati condivisi tra i componenti possono essere recuperati solo una volta dal DB e stampati solo una volta nella risposta;
- Può ridurre notevolmente, persino rimuovere completamente, la necessità di un archivio dati.
Le esploreremo in dettaglio nel corso dell'articolo, ma prima esploriamo quali sono effettivamente i componenti e come possiamo creare un sito basato su tali componenti e, infine, esploriamo come funziona un'API basata su componenti.
Letture consigliate : A GraphQL Primer: Perché abbiamo bisogno di un nuovo tipo di API
Costruire un sito attraverso i componenti
Un componente è semplicemente un insieme di pezzi di codice HTML, JavaScript e CSS messi insieme per creare un'entità autonoma. Questo può quindi avvolgere altri componenti per creare strutture più complesse ed essere esso stesso avvolto da altri componenti. Un componente ha uno scopo, che può variare da qualcosa di molto semplice (come un collegamento o un pulsante) a qualcosa di molto elaborato (come un carosello o un caricatore di immagini drag-and-drop). I componenti sono più utili quando sono generici e consentono la personalizzazione tramite proprietà iniettate (o "propri"), in modo che possano servire un'ampia gamma di casi d'uso. Nella maggior parte dei casi, il sito stesso diventa un componente.
Il termine "componente" è spesso usato per riferirsi sia alla funzionalità che al design. Ad esempio, per quanto riguarda la funzionalità, i framework JavaScript come React o Vue consentono di creare componenti lato client, che sono in grado di eseguire il rendering automatico (ad esempio, dopo che l'API ha recuperato i dati richiesti) e di utilizzare prop per impostare i valori di configurazione sui loro componenti avvolti, consentendo il riutilizzo del codice. Per quanto riguarda il design, Bootstrap ha standardizzato l'aspetto e l'aspetto dei siti Web attraverso la sua libreria di componenti front-end ed è diventata una tendenza salutare per i team creare sistemi di progettazione per mantenere i propri siti Web, il che consente ai diversi membri del team (designer e sviluppatori, ma anche marketer e venditori) per parlare un linguaggio unificato ed esprimere un'identità coerente.
La componentizzazione di un sito è quindi un modo molto sensato per rendere il sito Web più manutenibile. I siti che utilizzano framework JavaScript come React e Vue sono già basati su componenti (almeno sul lato client). L'uso di una libreria di componenti come Bootstrap non rende necessariamente il sito basato su componenti (potrebbe essere un grosso blob di HTML), tuttavia, incorpora il concetto di elementi riutilizzabili per l'interfaccia utente.
Se il sito è un grosso blob di HTML, per poterlo componentizzare dobbiamo suddividere il layout in una serie di schemi ricorrenti, per i quali dobbiamo identificare e catalogare le sezioni sulla pagina in base alla loro somiglianza di funzionalità e stili, e romperli sezioni in livelli, il più granulari possibile, cercando di concentrare ogni livello su un singolo obiettivo o azione e cercando anche di abbinare livelli comuni tra sezioni diverse.
Nota : "Atomic Design" di Brad Frost è un'ottima metodologia per identificare questi modelli comuni e costruire un sistema di progettazione riutilizzabile.
Quindi, costruire un sito attraverso i componenti è come giocare con i LEGO. Ogni componente è una funzionalità atomica, una composizione di altri componenti o una combinazione dei due.
Come mostrato di seguito, un componente di base (un avatar) è composto iterativamente da altri componenti fino ad ottenere la pagina web in alto:

La specifica dell'API basata sui componenti
Per l'API basata su componenti che ho progettato, un componente è chiamato "modulo", quindi d'ora in poi i termini "componente" e "modulo" sono usati in modo intercambiabile.
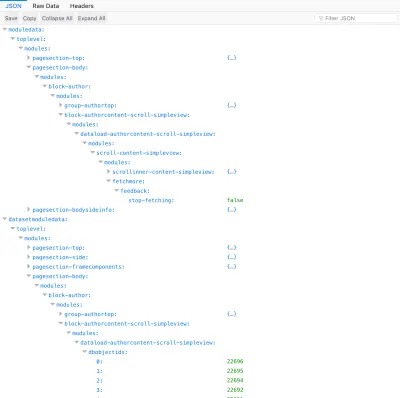
La relazione di tutti i moduli che si avvolgono a vicenda, dal modulo più in alto fino all'ultimo livello, è chiamata "gerarchia dei componenti". Questa relazione può essere espressa attraverso un array associativo (un array di key => proprietà) sul lato server, in cui ogni modulo dichiara il proprio nome come attributo chiave e i suoi moduli interni sotto la proprietà modules . L'API quindi codifica semplicemente questo array come un oggetto JSON per il consumo:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }La relazione tra i moduli è definita rigorosamente dall'alto verso il basso: un modulo avvolge altri moduli e sa chi sono, ma non sa – e non gli importa – quali moduli lo stanno avvolgendo.
Ad esempio, nel codice JSON sopra, module module-level1 sa che esegue il wrapping dei moduli module-level11 e module-level12 e, transitivamente, sa anche che esegue il wrapping module-level121 ; ma module module-level11 non si preoccupa di chi lo sta avvolgendo, di conseguenza non è a conoscenza di module-level1 .
Avendo la struttura basata sui componenti, ora possiamo aggiungere le informazioni effettive richieste da ciascun modulo, che è classificato in impostazioni (come valori di configurazione e altre proprietà) e dati (come gli ID degli oggetti del database interrogati e altre proprietà) , e posizionati di conseguenza nelle voci modulesettings e moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } Successivamente, l'API aggiungerà i dati dell'oggetto del database. Queste informazioni non vengono inserite in ciascun modulo, ma in una sezione condivisa denominata databases , per evitare la duplicazione delle informazioni quando due o più moduli diversi recuperano gli stessi oggetti dal database.
Inoltre, l'API rappresenta i dati dell'oggetto del database in modo relazionale, per evitare la duplicazione delle informazioni quando due o più oggetti del database diversi sono correlati a un oggetto comune (come due post con lo stesso autore). In altre parole, i dati dell'oggetto del database vengono normalizzati.
Letture consigliate : Costruire un modulo di contatto serverless per il tuo sito statico
La struttura è un dizionario, organizzato per ogni tipo di oggetto prima e ID oggetto poi, da cui possiamo ottenere le proprietà dell'oggetto:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }Questo oggetto JSON è già la risposta dell'API basata sui componenti. Il suo formato è una specifica di per sé: finché il server restituisce la risposta JSON nel formato richiesto, il client può utilizzare l'API indipendentemente da come viene implementata. Quindi, l'API può essere implementata su qualsiasi linguaggio (che è una delle bellezze di GraphQL: essere una specifica e non un'implementazione vera e propria le ha permesso di diventare disponibile in una miriade di lingue).
Nota : in un prossimo articolo, descriverò la mia implementazione dell'API basata su componenti in PHP (che è quella disponibile nel repository).
Esempio di risposta API
Ad esempio, la risposta API di seguito contiene una gerarchia di componenti con due moduli, page => post-feed , dove il modulo post-feed recupera i post del blog. Si prega di notare quanto segue:
- Ogni modulo sa quali sono i suoi oggetti interrogati dalla proprietà
dbobjectids(ID4e9per i post del blog) - Ogni modulo conosce il tipo di oggetto per i suoi oggetti interrogati dalla proprietà
dbkeys(i dati di ogni post si trovano sottopostse i dati dell'autore del post, corrispondenti all'autore con l'ID fornito sotto la proprietà del postauthor, si trovano sottousers) - Poiché i dati dell'oggetto del database sono relazionali, l'
authordella proprietà contiene l'ID dell'oggetto dell'autore invece di stampare direttamente i dati dell'autore.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }Differenze nel recupero dei dati da API basate su risorse, schema e componenti
Vediamo come un'API basata su componenti come PoP si confronta, durante il recupero dei dati, con un'API basata su risorse come REST e con un'API basata su schema come GraphQL.
Diciamo che IMDB ha una pagina con due componenti che devono recuperare i dati: "Regista in primo piano" (che mostra una descrizione di George Lucas e un elenco dei suoi film) e "Film consigliati per te" (che mostra film come Star Wars: Episodio I — La minaccia fantasma e Terminator ). Potrebbe assomigliare a questo:
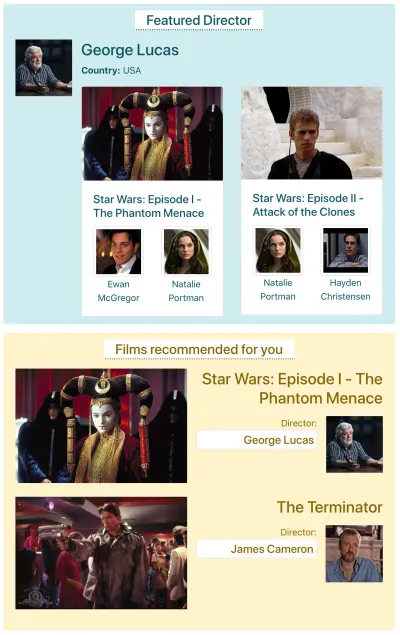
Vediamo quante richieste sono necessarie per recuperare i dati tramite ciascun metodo API. Per questo esempio, il componente "Regista in primo piano" porta un risultato ("George Lucas"), dal quale recupera due film ( Star Wars: Episodio I — La minaccia fantasma e Star Wars: Episodio II — L'attacco dei cloni ), e per ogni film due attori (“Ewan McGregor” e “Natalie Portman” per il primo film, e “Natalie Portman” e “Hayden Christensen” per il secondo film). Il componente "Film consigliati per te" porta due risultati ( Star Wars: Episodio I — La minaccia fantasma e Terminator ), e poi recupera i loro registi ("George Lucas" e "James Cameron" rispettivamente).
Utilizzando REST per eseguire il rendering del componente featured-director , potrebbero essere necessarie le seguenti 7 richieste (questo numero può variare a seconda della quantità di dati forniti da ciascun endpoint, ovvero della quantità di overfetching implementata):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL consente, attraverso schemi fortemente tipizzati, di recuperare tutti i dati richiesti in un'unica richiesta per componente. La query per recuperare i dati tramite GraphQL per il componente featuredDirector è simile alla seguente (dopo aver implementato lo schema corrispondente):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }E produce la seguente risposta:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }E la query per il componente "Film consigliati per te" produce la seguente risposta:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP emetterà solo una richiesta per recuperare tutti i dati per tutti i componenti nella pagina e normalizzare i risultati. L'endpoint da chiamare è semplicemente lo stesso dell'URL per il quale dobbiamo ottenere i dati, semplicemente aggiungendo un parametro aggiuntivo output=json per indicare di portare i dati in formato JSON invece di stamparli come HTML:
GET - /url-of-the-page/?output=json Supponendo che la struttura del modulo abbia un modulo superiore chiamato page contenente i moduli featured-director e films-recommended-for-you , e anche questi hanno dei sottomoduli, come questo:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"La singola risposta JSON restituita sarà simile a questa:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }Analizziamo come questi tre metodi si confrontano tra loro, in termini di velocità e quantità di dati recuperati.
Velocità
Attraverso REST, dover recuperare 7 richieste solo per eseguire il rendering di un componente può essere molto lento, principalmente su connessioni dati mobili e traballanti. Quindi, il salto da REST a GraphQL rappresenta un ottimo affare per la velocità, perché siamo in grado di eseguire il rendering di un componente con una sola richiesta.
PoP, poiché può recuperare tutti i dati per molti componenti in una richiesta, sarà più veloce per il rendering di molti componenti contemporaneamente; tuttavia, molto probabilmente non ce n'è bisogno. Avere i componenti da renderizzare in ordine (come appaiono nella pagina), è già una buona pratica, e per quei componenti che appaiono sotto la piega non c'è certo fretta nel renderli. Pertanto, sia le API basate su schema che quelle basate su componenti sono già abbastanza buone e chiaramente superiori a un'API basata su risorse.
Quantità di dati
Ad ogni richiesta, i dati nella risposta di GraphQL possono essere duplicati: l'attrice "Natalie Portman" viene recuperata due volte nella risposta dal primo componente e, quando si considera l'output congiunto per i due componenti, possiamo anche trovare dati condivisi, come il film Star Wars: Episodio I - La minaccia fantasma .
PoP, d'altra parte, normalizza i dati del database e li stampa una sola volta, tuttavia, comporta il sovraccarico della stampa della struttura del modulo. Quindi, a seconda della richiesta particolare con dati duplicati o meno, l'API basata su schema o l'API basata su componenti avrà una dimensione inferiore.
In conclusione, un'API basata su schema come GraphQL e un'API basata su componenti come PoP sono ugualmente buone per quanto riguarda le prestazioni e superiori a un'API basata su risorse come REST.
Letture consigliate : Capire e utilizzare le API REST
Proprietà particolari di un'API basata su componenti
Se un'API basata su componenti non è necessariamente migliore in termini di prestazioni rispetto a un'API basata su schema, ti starai chiedendo, cosa sto cercando di ottenere con questo articolo?
In questa sezione, cercherò di convincerti che una tale API ha un potenziale incredibile, fornendo diverse funzionalità che sono molto desiderabili, rendendola un serio concorrente nel mondo delle API. Di seguito descrivo e dimostro ciascuna delle sue straordinarie caratteristiche uniche.
I dati da recuperare dal database possono essere dedotti dalla gerarchia dei componenti
Quando un modulo visualizza una proprietà da un oggetto DB, il modulo potrebbe non sapere, o non preoccuparsi, di quale oggetto si tratta; tutto ciò che interessa è definire quali proprietà dell'oggetto caricato sono richieste.
Ad esempio, considera l'immagine qui sotto. Un modulo carica un oggetto dal database (in questo caso, un singolo post), quindi i suoi moduli discendenti mostreranno determinate proprietà dell'oggetto, come title e content :
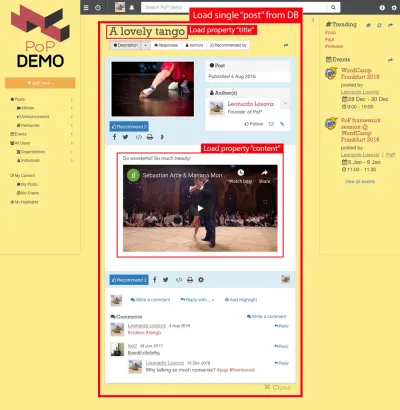
Quindi, lungo la gerarchia dei componenti, i moduli di “caricamento dati” si occuperanno di caricare gli oggetti interrogati (il modulo che carica il singolo post, in questo caso), e i suoi moduli discendenti definiranno quali proprietà dell'oggetto DB sono richieste ( title e content , in questo caso).
Il recupero di tutte le proprietà richieste per l'oggetto DB può essere eseguito automaticamente attraversando la gerarchia dei componenti: partendo dal modulo di caricamento dati, iteriamo tutti i suoi moduli discendenti fino a raggiungere un nuovo modulo di caricamento dati, o fino alla fine dell'albero; a ogni livello otteniamo tutte le proprietà richieste, quindi uniamo tutte le proprietà insieme e le interroghiamo dal database, tutte una sola volta.
Nella struttura sottostante, il modulo single-post recupera i risultati dal DB (il post con ID 37) ei sottomoduli post-title e post-content definiscono le proprietà da caricare per l'oggetto DB interrogato ( title e content rispettivamente); i sottomoduli post-layout e fetch-next-post-button non richiedono alcun campo dati.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"La query da eseguire viene calcolata automaticamente dalla gerarchia dei componenti e dai relativi campi dati obbligatori, contenenti tutte le proprietà necessarie a tutti i moduli e ai loro sottomoduli:
SELECT title, content FROM posts WHERE id = 37 Recuperando le proprietà da recuperare direttamente dai moduli, la query verrà aggiornata automaticamente ogni volta che la gerarchia dei componenti cambia. Se, ad esempio, aggiungiamo il sottomodulo post-thumbnail , che richiede la thumbnail del campo dati:
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"Quindi la query viene aggiornata automaticamente per recuperare la proprietà aggiuntiva:
SELECT title, content, thumbnail FROM posts WHERE id = 37Poiché abbiamo stabilito i dati dell'oggetto del database da recuperare in modo relazionale, possiamo anche applicare questa strategia tra le relazioni tra gli oggetti del database stessi.
Considera l'immagine seguente: partendo dal tipo di oggetto post e scendendo nella gerarchia dei componenti, dovremo spostare il tipo di oggetto DB in user e comment , corrispondenti rispettivamente all'autore del post e a ciascuno dei commenti del post, quindi, per ogni commento, deve cambiare ancora una volta il tipo di oggetto in user corrispondente all'autore del commento.
Passare da un oggetto di database a un oggetto relazionale (possibilmente cambiando il tipo di oggetto, come in post => author che passa da post a user , oppure no, come in author => follower che passano da user a user ) è ciò che chiamo "cambio di dominio ”.
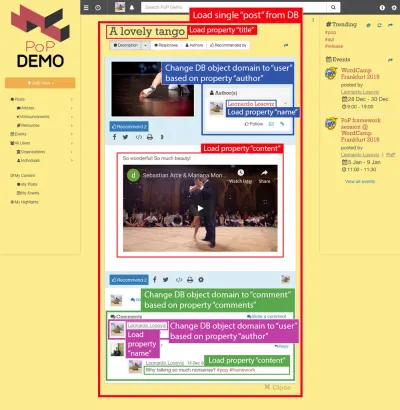
Dopo il passaggio a un nuovo dominio, da quel livello nella gerarchia dei componenti in giù, tutte le proprietà richieste saranno soggette al nuovo dominio:
- il
nameviene recuperato dall'oggettouser(che rappresenta l'autore del post), - il
contentviene recuperato dall'oggettocomment(che rappresenta ciascuno dei commenti del post), - il
nameviene prelevato dall'oggettouser(che rappresenta l'autore di ogni commento).
Attraversando la gerarchia dei componenti, l'API sa quando sta passando a un nuovo dominio e, in modo appropriato, aggiorna la query per recuperare l'oggetto relazionale.
Ad esempio, se abbiamo bisogno di mostrare i dati dell'autore del post, lo stacking del sottomodulo post-author cambierà il dominio a quel livello da post user corrispondente e da questo livello in giù l'oggetto DB caricato nel contesto passato al modulo è l'utente. Quindi, i sottomoduli user-name utente e user-avatar in post-author caricheranno il name delle proprietà e l' avatar sotto l'oggetto user :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"Risultato nella seguente query:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idIn sintesi, configurando ogni modulo in modo appropriato, non è necessario scrivere la query per recuperare i dati per un'API basata su componenti. La query viene prodotta automaticamente dalla struttura della gerarchia dei componenti stessa, ottenendo quali oggetti devono essere caricati dai moduli di caricamento dati, i campi da recuperare per ogni oggetto caricato definiti in ogni modulo discendente e il cambio di dominio definito in ogni modulo discendente.
L'aggiunta, la rimozione, la sostituzione o la modifica di qualsiasi modulo aggiornerà automaticamente la query. Dopo aver eseguito la query, i dati recuperati saranno esattamente ciò che è richiesto, né più né meno.
Osservare i dati e calcolare le proprietà aggiuntive
A partire dal modulo di caricamento dei dati lungo la gerarchia dei componenti, qualsiasi modulo può osservare i risultati restituiti e calcolare elementi di dati aggiuntivi basati su di essi, o valori di feedback , che vengono inseriti nella voce moduledata .
Ad esempio, il modulo fetch-next-post-button può aggiungere una proprietà che indica se ci sono più risultati da recuperare o meno (in base a questo valore di feedback, se non ci sono più risultati, il pulsante sarà disabilitato o nascosto):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }La conoscenza implicita dei dati richiesti diminuisce la complessità e rende obsoleto il concetto di "endpoint"
Come mostrato sopra, l'API basata sui componenti può recuperare esattamente i dati richiesti, perché ha il modello di tutti i componenti sul server e quali campi di dati sono richiesti da ciascun componente. Quindi, può rendere implicita la conoscenza dei campi dati richiesti.

Il vantaggio è che la definizione dei dati richiesti dal componente può essere aggiornata solo sul lato server, senza dover ridistribuire i file JavaScript, e il client può diventare stupido, chiedendo semplicemente al server di fornire tutti i dati di cui ha bisogno , diminuendo così la complessità dell'applicazione lato client.
Inoltre, la chiamata all'API per recuperare i dati per tutti i componenti per un URL specifico può essere eseguita semplicemente interrogando quell'URL e aggiungendo il parametro extra output=json per indicare la restituzione dei dati API invece di stampare la pagina. Quindi, l'URL diventa il proprio endpoint o, considerato in modo diverso, il concetto di "endpoint" diventa obsoleto.
Recupero di sottoinsiemi di dati: i dati possono essere recuperati per moduli specifici, trovati a qualsiasi livello della gerarchia dei componenti
Cosa succede se non abbiamo bisogno di recuperare i dati per tutti i moduli in una pagina, ma semplicemente i dati per un modulo specifico a partire da qualsiasi livello della gerarchia dei componenti? Ad esempio, se un modulo implementa uno scorrimento infinito, durante lo scorrimento verso il basso dobbiamo recuperare solo i nuovi dati per questo modulo e non per gli altri moduli nella pagina.
Ciò può essere ottenuto filtrando i rami della gerarchia dei componenti che verranno inclusi nella risposta, per includere le proprietà solo a partire dal modulo specificato e ignorare tutto al di sopra di questo livello. Nella mia implementazione (che descriverò in un prossimo articolo), il filtraggio viene abilitato aggiungendo il parametro modulefilter=modulepaths all'URL e il modulo (o moduli) selezionato viene indicato tramite un parametro modulepaths[] , dove un "percorso del modulo ” è l'elenco dei moduli a partire dal modulo più in alto fino al modulo specifico (es. module1 => module2 => module3 ha il percorso del modulo [ module1 , module2 , module3 ] e viene passato come parametro URL come module1.module2.module3 ) .
Ad esempio, nella gerarchia dei componenti sotto ogni modulo ha una voce dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Quindi, richiedendo l'URL della pagina web aggiungendo i parametri modulefilter=modulepaths e modulepaths[]=module1.module2.module5 si otterrà la seguente risposta:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] In sostanza, l'API inizia a caricare i dati a partire da module1 => module2 => module5 . Ecco perché module6 , che rientra in module5 , porta anche i suoi dati mentre module3 e module4 no.
Inoltre, possiamo creare filtri di moduli personalizzati per includere un set prestabilito di moduli. Ad esempio, chiamando una pagina con modulefilter=userstate può stampare solo quei moduli che richiedono lo stato utente per renderli nel client, come moduli module3 e module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] Le informazioni relative ai moduli iniziali si trovano nella sezione requestmeta , sotto voce filteredmodules , come un array di percorsi di modulo:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }Questa funzionalità consente di implementare una semplice Applicazione a Pagina Singola, in cui il frame del sito viene caricato sulla richiesta iniziale:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] Ma, da loro in poi, possiamo aggiungere il parametro modulefilter=page a tutti gli URL richiesti, filtrando il frame e portando solo il contenuto della pagina:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] Simile ai filtri modulo userstate e page descritti sopra, possiamo implementare qualsiasi filtro modulo personalizzato e creare esperienze utente avanzate.
Il modulo è la sua stessa API
Come mostrato sopra, possiamo filtrare la risposta dell'API per recuperare i dati a partire da qualsiasi modulo. Di conseguenza, ogni modulo può interagire con se stesso dal client al server semplicemente aggiungendo il proprio percorso del modulo all'URL della pagina web in cui è stato incluso.
Spero che scuserete la mia eccessiva eccitazione, ma non posso davvero sottolineare abbastanza quanto sia meravigliosa questa funzione. Durante la creazione di un componente, non è necessario creare un'API da affiancare ad essa per recuperare i dati (REST, GraphQL o qualsiasi altra cosa), perché il componente è già in grado di parlare con se stesso nel server e caricare i propri dati — è completamente autonomo e self-service .
Ogni modulo di caricamento dati esporta l'URL per interagire con esso nella voce dataloadsource dalla sezione datasetmodulemeta :
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }Il recupero dei dati è disaccoppiato tra i moduli e DRY
Per sottolineare che il recupero dei dati in un'API basata su componenti è altamente disaccoppiato e ASCIUTTO (non ripetere te stesso), dovrò prima mostrare come in un'API basata su schema come GraphQL sia meno disaccoppiato e non ASCIUTTO.
In GraphQL, la query per recuperare i dati deve indicare i campi di dati per il componente, che possono includere sottocomponenti, e questi possono anche includere sottocomponenti e così via. Quindi, il componente più in alto deve sapere quali dati sono richiesti anche da ciascuno dei suoi sottocomponenti, in modo da recuperare quei dati.
Ad esempio, il rendering del componente <FeaturedDirector> potrebbe richiedere i seguenti sottocomponenti:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> In questo scenario, la query GraphQL viene implementata a livello <FeaturedDirector> . Quindi, se il sottocomponente <Film> viene aggiornato, richiedendo il titolo tramite la proprietà filmTitle invece di title , anche la query dal componente <FeaturedDirector> dovrà essere aggiornata per rispecchiare queste nuove informazioni (GraphQL ha un meccanismo di controllo delle versioni che può gestire con questo problema, ma prima o poi dovremmo comunque aggiornare le informazioni). Ciò produce complessità di manutenzione, che potrebbe essere difficile da gestire quando i componenti interni cambiano spesso o sono prodotti da sviluppatori di terze parti. Pertanto, i componenti non sono completamente disaccoppiati l'uno dall'altro.
Allo stesso modo, potremmo voler rendere direttamente il componente <Film> per qualche film specifico, per il quale poi dobbiamo anche implementare una query GraphQL a questo livello, per recuperare i dati per il film e i suoi attori, che aggiunge codice ridondante: porzioni di la stessa query vivrà a diversi livelli della struttura del componente. Quindi GraphQL non è DRY .
Poiché un'API basata su componenti sa già come i suoi componenti si avvolgono a vicenda nella propria struttura, questi problemi vengono completamente evitati. Per uno, il cliente è in grado di richiedere semplicemente i dati richiesti di cui ha bisogno, qualunque siano questi dati; if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
Nell'API basata su componenti, tuttavia, possiamo facilmente utilizzare le relazioni tra i moduli già descritti nell'API per accoppiare i moduli insieme. Mentre originariamente avremo questa risposta:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }Dopo aver aggiunto Instagram avremo la risposta aggiornata:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } E semplicemente ripetendo tutti i valori in modulesettings["share-on-social-media"].modules , il componente <ShareOnSocialMedia> può essere aggiornato per mostrare il componente <InstagramShare> senza la necessità di ridistribuire alcun file JavaScript. Pertanto, l'API supporta l'aggiunta e la rimozione di moduli senza compromettere il codice di altri moduli, raggiungendo un grado di modularità più elevato.
Cache lato client nativa/archivio dati
I dati del database recuperati sono normalizzati in una struttura a dizionario, e standardizzati in modo che, partendo dal valore su dbobjectids , qualsiasi dato presente nei databases sia raggiungibile semplicemente seguendo il percorso ad esso indicato tramite le voci dbkeys , in qualunque modo fosse strutturato . Pertanto, la logica per l'organizzazione dei dati è già nativa dell'API stessa.
Possiamo trarre vantaggio da questa situazione in diversi modi. Ad esempio, i dati restituiti per ciascuna richiesta possono essere aggiunti in una cache lato client contenente tutti i dati richiesti dall'utente durante la sessione. Quindi, è possibile evitare di aggiungere all'applicazione un datastore esterno come Redux (intendo per quanto riguarda la gestione dei dati, non per quanto riguarda altre funzionalità come l'Undo/Redo, l'ambiente collaborativo o il debug del viaggio nel tempo).
Inoltre, la struttura basata sui componenti promuove la memorizzazione nella cache: la gerarchia dei componenti non dipende dall'URL, ma da quali componenti sono necessari in quell'URL. In questo modo, due eventi in /events/1/ e /events/2/ condivideranno la stessa gerarchia di componenti e le informazioni su quali moduli sono richiesti possono essere riutilizzate su di essi. Di conseguenza, tutte le proprietà (diverse dai dati del database) possono essere memorizzate nella cache sul client dopo aver recuperato il primo evento e riutilizzate da quel momento in poi, in modo che solo i dati del database per ogni evento successivo debbano essere recuperati e nient'altro.
Estendibilità e riutilizzo
La sezione dei databases dell'API può essere estesa, consentendo di classificare le sue informazioni in sottosezioni personalizzate. Per impostazione predefinita, tutti i dati dell'oggetto database vengono inseriti nella voce primary , tuttavia, possiamo anche creare voci personalizzate in cui posizionare proprietà dell'oggetto DB specifiche.
Ad esempio, se il componente "Film consigliati per te" descritto in precedenza mostra un elenco degli amici dell'utente che ha effettuato l'accesso che hanno visto questo film nella proprietà friendsWhoWatchedFilm sull'oggetto DB film , perché questo valore cambierà a seconda dell'accesso user, quindi salviamo questa proprietà in una voce userstate , quindi quando l'utente si disconnette, eliminiamo solo questo ramo dal database memorizzato nella cache sul client, ma rimangono ancora tutti i dati primary :
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }Inoltre, fino a un certo punto, la struttura della risposta API può essere riproposta. In particolare, i risultati del database possono essere stampati in una struttura dati diversa, come un array invece del dizionario predefinito.
Ad esempio, se il tipo di oggetto è solo uno (es. films ), può essere formattato come un array da inserire direttamente in un componente typeahead:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]Supporto per la programmazione orientata agli aspetti
Oltre a recuperare i dati, l'API basata sui componenti può anche pubblicare dati, ad esempio per creare un post o aggiungere un commento, ed eseguire qualsiasi tipo di operazione, come l'accesso o la disconnessione dell'utente, l'invio di e-mail, la registrazione, l'analisi, e così via. Non ci sono restrizioni: qualsiasi funzionalità fornita dal CMS sottostante può essere invocata tramite un modulo, a qualsiasi livello.
Lungo la gerarchia dei componenti, possiamo aggiungere un numero qualsiasi di moduli e ogni modulo può eseguire la propria operazione. Quindi, non tutte le operazioni devono essere necessariamente correlate all'azione prevista della richiesta, come quando si esegue un'operazione POST, PUT o DELETE in REST o si invia una mutazione in GraphQL, ma possono essere aggiunte per fornire funzionalità extra, come l'invio di un'e-mail all'amministratore quando un utente crea un nuovo post.
Quindi, definendo la gerarchia dei componenti tramite file di configurazione o iniezione di dipendenze, si può dire che l'API supporta la programmazione orientata agli aspetti, "un paradigma di programmazione che mira ad aumentare la modularità consentendo la separazione delle preoccupazioni trasversali".
Lettura consigliata : Protezione del sito con la politica delle funzionalità
Sicurezza avanzata
I nomi dei moduli non sono necessariamente fissi quando stampati nell'output, ma possono essere abbreviati, alterati, modificati casualmente o (in breve) resi variabili in qualsiasi modo. Sebbene originariamente pensato per abbreviare l'output dell'API (in modo che i nomi dei moduli carousel-featured-posts o drag-and-drop-user-images possano essere abbreviati in una notazione di base 64, come a1 , a2 e così via, per l'ambiente di produzione ), questa funzione consente di modificare frequentemente i nomi dei moduli nella risposta dall'API per motivi di sicurezza.
Ad esempio, i nomi di input sono nominati per impostazione predefinita come il modulo corrispondente; quindi, moduli chiamati username e password , che devono essere visualizzati nel client rispettivamente come <input type="text" name="{input_name}"> e <input type="password" name="{input_name}"> , possono essere impostati valori casuali variabili per i nomi di input (come zwH8DSeG e QBG7m6EF oggi e c3oMLBjo e c46oVgN6 domani), rendendo più difficile per spammer e bot prendere di mira il sito.
Versatilità grazie a modelli alternativi
L'annidamento dei moduli consente di passare a un altro modulo per aggiungere compatibilità per un supporto o una tecnologia specifici, o modificare uno stile o funzionalità, e quindi tornare al ramo originale.
Ad esempio, supponiamo che la pagina web abbia la seguente struttura:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" In questo caso, vorremmo che il sito Web funzionasse anche per AMP, tuttavia i moduli module2 , module4 e module5 non sono compatibili con AMP. Possiamo diramare questi moduli in moduli simili, compatibili con AMP module2AMP , module4AMP e module5AMP , dopodiché continuiamo a caricare la gerarchia dei componenti originale, quindi solo questi tre moduli vengono sostituiti (e nient'altro):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"Ciò rende abbastanza facile generare output diversi da una singola base di codice, aggiungendo fork solo qua e là secondo necessità e sempre con ambito e limitato ai singoli moduli.
Tempo di dimostrazione
Il codice che implementa l'API come spiegato in questo articolo è disponibile in questo repository open source.
Ho distribuito l'API PoP in https://nextapi.getpop.org a scopo dimostrativo. Il sito Web funziona su WordPress, quindi i permalink URL sono quelli tipici di WordPress. Come notato in precedenza, aggiungendo loro il parametro output=json , questi URL diventano i propri endpoint API.
Il sito è supportato dallo stesso database del sito Web PoP Demo, quindi è possibile visualizzare la gerarchia dei componenti e i dati recuperati interrogando lo stesso URL in questo altro sito Web (ad esempio visitando https://demo.getpop.org/u/leo/ spiega i dati da https://nextapi.getpop.org/u/leo/?output=json ).
I collegamenti seguenti mostrano l'API per i casi descritti in precedenza:
- La homepage, un singolo post, un autore, un elenco di post e un elenco di utenti.
- Un evento, filtraggio da un modulo specifico.
- Un tag, moduli di filtraggio che richiedono lo stato utente e filtri per portare solo una pagina da un'applicazione a pagina singola.
- Una serie di posizioni, per alimentare un typeahead.
- Modelli alternativi per la pagina "Chi siamo": Normale, Stampabile, Incorporabile.
- Modifica dei nomi dei moduli: originale vs maciullato.
- Filtraggio delle informazioni: solo le impostazioni del modulo, i dati del modulo più i dati del database.
Conclusione
Una buona API è un trampolino di lancio per la creazione di applicazioni affidabili, facilmente gestibili e potenti. In questo articolo, ho descritto i concetti alla base di un'API basata su componenti che, credo, sia un'API piuttosto buona e spero di aver convinto anche te.
Finora, la progettazione e l'implementazione dell'API ha richiesto diverse iterazioni e ha richiesto più di cinque anni, e non è ancora completamente pronta. Tuttavia, è in uno stato abbastanza decente, non pronto per la produzione ma come alfa stabile. In questi giorni ci sto ancora lavorando; lavorando sulla definizione della specifica aperta, implementando i livelli aggiuntivi (come il rendering) e scrivendo la documentazione.
In un prossimo articolo, descriverò come funziona la mia implementazione dell'API. Fino ad allora, se hai qualche idea al riguardo, indipendentemente dal fatto che sia positiva o negativa, mi piacerebbe leggere i tuoi commenti qui sotto.
Aggiornamento (31 gennaio): funzionalità di query personalizzate
Alain Schlesser ha commentato che un'API che non può essere interrogata in modo personalizzato dal client non ha valore, riportandoci a SOAP, in quanto tale non può competere né con REST né con GraphQL. Dopo aver espresso il suo commento per alcuni giorni di riflessione, ho dovuto ammettere che aveva ragione. Tuttavia, invece di respingere l'API basata su componenti come un'impresa ben intenzionata ma non del tutto ancora presente, ho fatto qualcosa di molto meglio: ho avuto modo di implementare la funzionalità di query personalizzate per essa. E funziona come un incantesimo!
Nei collegamenti seguenti, i dati per una risorsa o una raccolta di risorse vengono recuperati come in genere avviene tramite REST. Tuttavia, tramite i fields dei parametri possiamo anche specificare quali dati specifici recuperare per ciascuna risorsa, evitando l'over o underfetching dei dati:
- Un singolo post e una raccolta di post con l'aggiunta di
fields=title,content,datetime - Un utente e una raccolta di utenti che aggiungono
fields=name,username,description
I collegamenti sopra mostrano il recupero dei dati solo per le risorse richieste. E le loro relazioni? Ad esempio, supponiamo di voler recuperare un elenco di post con i campi "title" e "content" , i commenti di ogni post con i campi "content" e "date" e l'autore di ogni commento con i campi "name" e "url" . Per raggiungere questo obiettivo in GraphQL implementeremo la seguente query:
query { post { title content comments { content date author { name url } } } } Per l'implementazione dell'API basata su componenti, ho tradotto la query nella sua corrispondente espressione di "sintassi punto", che può quindi essere fornita tramite i fields dei parametri. Interrogando su una risorsa "post", questo valore è:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url Oppure può essere semplificato, utilizzando | per raggruppare tutti i campi applicati alla stessa risorsa:
fields=title|content,comments.content|date,comments.author.name|urlQuando eseguiamo questa query su un singolo post, otteniamo esattamente i dati richiesti per tutte le risorse coinvolte:
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } Quindi possiamo interrogare le risorse in modo REST e specificare query basate su schema in modo GraphQL e otterremo esattamente ciò che è richiesto, senza sovrascrivere o sottocaricare i dati e normalizzare i dati nel database in modo che nessun dato venga duplicato. Preferibilmente, la query può includere un numero qualsiasi di relazioni, annidate in profondità, e queste vengono risolte con un tempo di complessità lineare: caso peggiore di O(n+m), dove n è il numero di nodi che cambiano dominio (in questo caso 2: comments e comments.author ) e m è il numero di risultati recuperati (in questo caso 5: 1 post + 2 commenti + 2 utenti) e il caso medio di O(n). (Questo è più efficiente di GraphQL, che ha un tempo di complessità polinomiale O(n^c) e soffre di un aumento del tempo di esecuzione all'aumentare della profondità del livello).
Infine, questa API può anche applicare modificatori durante la query dei dati, ad esempio per filtrare quali risorse vengono recuperate, come può essere fatto tramite GraphQL. Per raggiungere questo obiettivo, l'API si trova semplicemente sopra l'applicazione e può utilizzare comodamente la sua funzionalità, quindi non è necessario reinventare la ruota. Ad esempio, l'aggiunta di parametri filter=posts&searchfor=internet filtrerà tutti i post contenenti "internet" da una raccolta di post.
L'implementazione di questa nuova funzionalità sarà descritta in un prossimo articolo.