
Conversione da immagine a testo con React e Tesseract.js (OCR)
Pubblicato: 2022-03-10I dati sono la spina dorsale di ogni applicazione software perché lo scopo principale di un'applicazione è risolvere i problemi umani. Per risolvere i problemi umani, è necessario avere alcune informazioni su di essi.
Tali informazioni sono rappresentate come dati, soprattutto attraverso il calcolo. Sul web i dati vengono raccolti principalmente sotto forma di testi, immagini, video e molti altri. A volte, le immagini contengono testi essenziali che devono essere elaborati per raggiungere un determinato scopo. Queste immagini sono state per lo più elaborate manualmente perché non c'era modo di elaborarle a livello di codice.
L'impossibilità di estrarre testo dalle immagini era una limitazione nell'elaborazione dei dati che ho sperimentato in prima persona nella mia ultima azienda. Avevamo bisogno di elaborare le carte regalo scansionate e dovevamo farlo manualmente poiché non potevamo estrarre il testo dalle immagini.
C'era un dipartimento chiamato "Operazioni" all'interno dell'azienda che era responsabile della conferma manuale delle carte regalo e dell'accredito sugli account degli utenti. Sebbene avessimo un sito Web attraverso il quale gli utenti si collegavano a noi, l'elaborazione delle carte regalo veniva eseguita manualmente dietro le quinte.
All'epoca, il nostro sito web era costruito principalmente con PHP (Laravel) per il backend e JavaScript (jQuery e Vue) per il frontend. Il nostro stack tecnico era abbastanza buono per lavorare con Tesseract.js a condizione che il problema fosse considerato importante dal management.
Ero disposto a risolvere il problema ma non era necessario risolvere il problema a giudicare dal punto di vista dell'impresa o del management. Dopo aver lasciato l'azienda, ho deciso di fare delle ricerche e cercare di trovare possibili soluzioni. Alla fine, ho scoperto l'OCR.
Che cos'è l'OCR?
OCR sta per "Optical Character Recognition" o "Optical Character Reader". Viene utilizzato per estrarre testi dalle immagini.
L'evoluzione dell'OCR può essere ricondotta a diverse invenzioni, ma Optophone, "Gismo", scanner a superficie piana CCD, Newton MessagePad e Tesseract sono le principali invenzioni che portano il riconoscimento dei caratteri a un altro livello di utilità.
Allora, perché usare l'OCR? Bene, il riconoscimento ottico dei caratteri risolve molti problemi, uno dei quali mi ha spinto a scrivere questo articolo. Mi sono reso conto che la possibilità di estrarre testi da un'immagine garantisce molte possibilità come:
- Regolamento
Ogni organizzazione ha bisogno di regolamentare le attività degli utenti per alcuni motivi. Il regolamento potrebbe essere utilizzato per proteggere i diritti degli utenti e proteggerli da minacce o truffe.
L'estrazione di testi da un'immagine consente a un'organizzazione di elaborare le informazioni testuali su un'immagine per la regolamentazione, soprattutto quando le immagini sono fornite da alcuni utenti.
Ad esempio, con l'OCR è possibile ottenere una regolazione simile a Facebook del numero di testi sulle immagini utilizzate per gli annunci. Inoltre, l'OCR rende possibile anche nascondere i contenuti sensibili su Twitter. - Ricercabilità
La ricerca è una delle attività più comuni, soprattutto su Internet. Gli algoritmi di ricerca si basano principalmente sulla manipolazione di testi. Con il riconoscimento ottico dei caratteri, è possibile riconoscere i caratteri sulle immagini e utilizzarli per fornire agli utenti risultati di immagine rilevanti. In breve, immagini e video sono ora ricercabili con l'aiuto dell'OCR. - Accessibilità
Avere testi su immagini è sempre stata una sfida per l'accessibilità ed è regola pratica avere pochi testi su un'immagine. Con l'OCR, i lettori di schermo possono avere accesso ai testi sulle immagini per fornire l'esperienza necessaria ai propri utenti. - Automazione dell'elaborazione dei dati L'elaborazione dei dati è per lo più automatizzata su larga scala. Avere testi su immagini è una limitazione al trattamento dei dati perché i testi non possono essere elaborati se non manualmente. Il riconoscimento ottico dei caratteri (OCR) consente di estrarre testi su immagini in modo programmatico, garantendo così l'automazione dell'elaborazione dei dati soprattutto quando ha a che fare con l'elaborazione di testi su immagini.
- Digitalizzazione di materiali stampati
Tutto sta diventando digitale e ci sono ancora molti documenti da digitalizzare. Assegni, certificati e altri documenti fisici possono ora essere digitalizzati con l'uso del riconoscimento ottico dei caratteri.
Scoprire tutti gli usi di cui sopra ha approfondito i miei interessi, quindi ho deciso di andare oltre ponendo una domanda:
"Come posso utilizzare l'OCR sul Web, specialmente in un'applicazione React?"
Questa domanda mi ha portato a Tesseract.js.
Che cos'è Tesseract.js?
Tesseract.js è una libreria JavaScript che compila il Tesseract originale da C a JavaScript WebAssembly rendendo così l'OCR accessibile nel browser. Il motore Tesseract.js è stato originariamente scritto in ASM.js e successivamente è stato portato su WebAssembly, ma ASM.js funge ancora da backup in alcuni casi quando WebAssembly non è supportato.
Come affermato sul sito Web di Tesseract.js, supporta più di 100 lingue , orientamento automatico del testo e rilevamento degli script, una semplice interfaccia per la lettura di paragrafi, parole e riquadri di delimitazione dei caratteri.
Tesseract è un motore di riconoscimento ottico dei caratteri per vari sistemi operativi. È un software gratuito, rilasciato con licenza Apache. Hewlett-Packard ha sviluppato Tesseract come software proprietario negli anni '80. È stato rilasciato come open source nel 2005 e il suo sviluppo è stato sponsorizzato da Google dal 2006.
L'ultima versione, la versione 4, di Tesseract è stata rilasciata nell'ottobre 2018 e contiene un nuovo motore OCR che utilizza un sistema di rete neurale basato sulla memoria a lungo termine (LSTM) e ha lo scopo di produrre risultati più accurati.
Comprensione delle API Tesseract
Per capire davvero come funziona Tesseract, dobbiamo analizzare alcune delle sue API e dei loro componenti. Secondo la documentazione di Tesseract.js, ci sono due modi per utilizzarlo. Di seguito è riportato il primo approccio e la sua suddivisione:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } Il metodo di recognize prende image come primo argomento, language (che può essere multiplo) come secondo argomento e { logger: m => console.log(me) } come ultimo argomento. I formati immagine supportati da Tesseract sono jpg, png, bmp e pbm che possono essere forniti solo come elementi (img, video o canvas), oggetto file ( <input> ), oggetto blob, percorso o URL di un'immagine e immagine codificata in base64 . (Leggi qui per ulteriori informazioni su tutti i formati di immagine che Tesseract può gestire.)
La lingua viene fornita come una stringa come eng . Il segno + potrebbe essere usato per concatenare più lingue come in eng+chi_tra . L'argomento lingua viene utilizzato per determinare i dati della lingua addestrati da utilizzare nell'elaborazione delle immagini.
Nota : qui troverai tutte le lingue disponibili e i relativi codici.
{ logger: m => console.log(m) } è molto utile per ottenere informazioni sullo stato di avanzamento di un'immagine in elaborazione. La proprietà logger accetta una funzione che verrà chiamata più volte mentre Tesseract elabora un'immagine. Il parametro della funzione logger dovrebbe essere un oggetto con workerId , jobId , status e progress come proprietà:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress è un numero compreso tra 0 e 1 ed è in percentuale per mostrare l'avanzamento di un processo di riconoscimento dell'immagine.
Tesseract genera automaticamente l'oggetto come parametro per la funzione logger ma può anche essere fornito manualmente. Mentre è in corso un processo di riconoscimento, le proprietà dell'oggetto logger vengono aggiornate ogni volta che viene chiamata la funzione . Pertanto, può essere utilizzato per mostrare una barra di avanzamento della conversione, modificare alcune parti di un'applicazione o utilizzare per ottenere il risultato desiderato.
Il result nel codice sopra è il risultato del processo di riconoscimento dell'immagine. Ciascuna delle proprietà del result ha la proprietà bbox come coordinate x/y del loro riquadro di delimitazione.
Ecco le proprietà dell'oggetto result , i loro significati o usi:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: tutto il testo riconosciuto come stringa. -
lines: una matrice di ogni riga per riga di testo riconosciuta. -
words: un array di ogni parola riconosciuta. -
symbols: una matrice di ciascuno dei caratteri riconosciuti. -
paragraphs: un array di ogni paragrafo riconosciuto. Discuteremo la "fiducia" più avanti in questo articolo.
Tesseract può anche essere usato in modo più imperativo come in:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();Questo approccio è correlato al primo approccio ma con implementazioni diverse.
createWorker(options) crea un lavoratore Web o un processo figlio del nodo che crea un lavoratore Tesseract. L'operatore aiuta a configurare il motore OCR Tesseract. Il metodo load() carica gli script core di Tesseract, loadLanguage() carica qualsiasi lingua fornita come stringa, initialize() si assicura che Tesseract sia completamente pronto per l'uso e quindi il metodo di riconoscimento viene utilizzato per elaborare l'immagine fornita. Il metodo terminate() arresta il lavoratore e ripulisce tutto.
Nota : per ulteriori informazioni, consultare la documentazione delle API Tesseract.
Ora, dobbiamo creare qualcosa per vedere davvero quanto sia efficace Tesseract.js.
Cosa costruiremo?
Costruiremo un estrattore di PIN per carte regalo perché l'estrazione del PIN da una carta regalo è stato il problema che ha portato in primo luogo a questa avventura di scrittura.
Costruiremo una semplice applicazione che estrae il PIN da una carta regalo scansionata . Mentre ho deciso di costruire un semplice estrattore di spille per carte regalo, ti guiderò attraverso alcune delle sfide che ho affrontato lungo la linea, le soluzioni che ho fornito e la mia conclusione basata sulla mia esperienza.
- Vai al codice sorgente →
Di seguito è riportata l'immagine che useremo per i test perché ha alcune proprietà realistiche possibili nel mondo reale.

Estrarremo AQUX-QWMB6L-R6JAU dalla scheda. Quindi iniziamo.
Installazione di React e Tesseract
C'è una domanda a cui rispondere prima di installare React e Tesseract.js e la domanda è: perché usare React con Tesseract? In pratica, possiamo usare Tesseract con Vanilla JavaScript, qualsiasi libreria o framework JavaScript come React, Vue e Angular.
L'uso di React in questo caso è una preferenza personale. Inizialmente, volevo usare Vue, ma ho deciso di utilizzare React perché ho più familiarità con React rispetto a Vue.
Ora, continuiamo con le installazioni.
Per installare React con create-react-app, devi eseguire il codice seguente:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jso
npm install tesseract.jsHo deciso di utilizzare il filato per installare Tesseract.js perché non ero in grado di installare Tesseract con npm ma il filato ha svolto il lavoro senza stress. Puoi usare npm ma ti consiglio di installare Tesseract con il filato a giudicare dalla mia esperienza.
Ora, avviamo il nostro server di sviluppo eseguendo il codice seguente:
yarn starto
npm startDopo aver eseguito yarn start o npm start, il browser predefinito dovrebbe aprire una pagina Web simile a quella seguente:

Puoi anche accedere a localhost:3000 nel browser a condizione che la pagina non venga avviata automaticamente.
Dopo aver installato React e Tesseract.js, cosa succede dopo?
Configurazione di un modulo di caricamento
In questo caso, regoleremo la home page (App.js) che abbiamo appena visualizzato nel browser per contenere il modulo di cui abbiamo bisogno:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App La parte del codice sopra che richiede la nostra attenzione a questo punto è la funzione handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } Nella funzione, URL.createObjectURL prende un file selezionato tramite event.target.files[0] e crea un URL di riferimento che può essere utilizzato con tag HTML come img, audio e video. Abbiamo usato setImagePath per aggiungere l'URL allo stato. Ora è possibile accedere all'URL con imagePath .
<img src={imagePath} className="App-logo" alt="image"/> Impostiamo l'attributo src dell'immagine su {imagePath} per visualizzarne l'anteprima nel browser prima di elaborarla.
Conversione di immagini selezionate in testi
Dopo aver afferrato il percorso dell'immagine selezionata, possiamo passare il percorso dell'immagine a Tesseract.js per estrarne i testi.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default AppAggiungiamo la funzione "handleClick" a "App.js e contiene l'API Tesseract.js che prende il percorso dell'immagine selezionata. Tesseract.js prende "imagePath", "language", "un oggetto di impostazione".
Il pulsante sottostante viene aggiunto al modulo per chiamare "handClick" che attiva la conversione da immagine a testo ogni volta che si fa clic sul pulsante.
<button onClick={handleClick} style={{height:50}}> convert to text</button>Quando l'elaborazione ha esito positivo, accediamo sia alla "confidenza" che al "testo" dal risultato. Quindi, aggiungiamo "testo" allo stato con "setText(testo)".
Aggiungendo a <p> {text} </p> , visualizziamo il testo estratto.
È ovvio che dall'immagine si estrae “testo”, ma che cos'è la fiducia?
La fiducia mostra quanto sia accurata la conversione. Il livello di confidenza è compreso tra 1 e 100. 1 sta per il peggiore mentre 100 sta per il migliore in termini di precisione. Può anche essere utilizzato per determinare se un testo estratto deve essere accettato come accurato o meno.
Quindi la domanda è: quali fattori possono influenzare il punteggio di affidabilità o l'accuratezza dell'intera conversione? È principalmente influenzato da tre fattori principali: la qualità e la natura del documento utilizzato, la qualità della scansione creata dal documento e le capacità di elaborazione del motore Tesseract.
Ora aggiungiamo il codice di seguito a "App.css" per modellare un po' l'applicazione.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }Ecco il risultato del mio primo test :
Risultato in Firefox
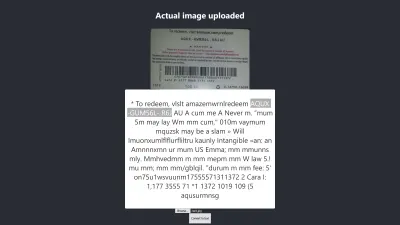
Il livello di confidenza del risultato sopra è 64. Vale la pena notare che l'immagine del buono regalo è di colore scuro e influisce sicuramente sul risultato che otteniamo.

Se dai un'occhiata più da vicino all'immagine sopra, vedrai che il pin della scheda è quasi preciso nel testo estratto. Non è preciso perché la carta regalo non è molto chiara.
Oh, aspetta! Come apparirà in Chrome?
Risultato in Chrome
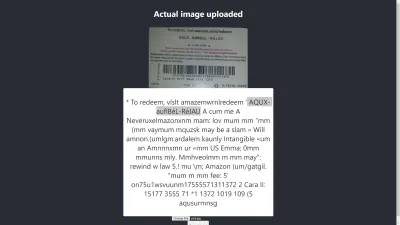
Ah! Il risultato è ancora peggiore in Chrome. Ma perché il risultato in Chrome è diverso da Mozilla Firefox? Browser diversi gestiscono le immagini e i loro profili colore in modo diverso. Ciò significa che un'immagine può essere renderizzata in modo diverso a seconda del browser . Fornendo image.data pre-renderizzato a Tesseract, è probabile che produca un risultato diverso in browser diversi perché a Tesseract viene fornito image.data diverso a seconda del browser in uso. La preelaborazione di un'immagine, come vedremo più avanti in questo articolo, aiuterà a ottenere un risultato coerente.
Dobbiamo essere più accurati in modo da poter essere sicuri di ricevere o fornire le informazioni giuste. Quindi dobbiamo spingerci un po' oltre.
Proviamo di più per vedere se riusciamo a raggiungere l'obiettivo alla fine.
Test di precisione
Ci sono molti fattori che influenzano una conversione da immagine a testo con Tesseract.js. La maggior parte di questi fattori ruota attorno alla natura dell'immagine che vogliamo elaborare e il resto dipende da come il motore Tesseract gestisce la conversione.
Internamente, Tesseract preelabora le immagini prima della conversione OCR effettiva, ma non sempre fornisce risultati accurati.
Come soluzione, possiamo preelaborare le immagini per ottenere conversioni accurate. Possiamo binarizzare, invertire, dilatare, raddrizzare o ridimensionare un'immagine per preelaborarla per Tesseract.js.
La pre-elaborazione delle immagini richiede molto lavoro o un campo vasto di per sé. Fortunatamente, P5.js ha fornito tutte le tecniche di preelaborazione delle immagini che vogliamo utilizzare. Invece di reinventare la ruota o usare l'intera libreria solo perché vogliamo usarne una piccola parte, ho copiato quelli che ci servivano. Tutte le tecniche di preelaborazione delle immagini sono incluse in preprocess.js.
Che cos'è la binarizzazione?
La binarizzazione è la conversione dei pixel di un'immagine in bianco o nero. Vogliamo binarizzare la carta regalo precedente per verificare se l'accuratezza sarà migliore o meno.
In precedenza, abbiamo estratto alcuni testi da una carta regalo, ma il PIN target non era preciso come volevamo. Quindi è necessario trovare un altro modo per ottenere un risultato accurato.
Ora, vogliamo binarizzare la carta regalo , cioè vogliamo convertire i suoi pixel in bianco e nero in modo da poter vedere se è possibile ottenere o meno un livello di precisione migliore.
Le funzioni seguenti verranno utilizzate per la binarizzazione ed è inclusa in un file separato chiamato preprocess.js.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageCosa fa il codice sopra?
Introduciamo canvas per contenere i dati di un'immagine per applicare alcuni filtri, per pre-elaborare l'immagine, prima di passarla a Tesseract per la conversione.
La prima funzione preprocessImage si trova in preprocess.js e prepara la tela per l'uso ottenendo i suoi pixel. La funzione thresholdFilter binarizza l'immagine convertendo i suoi pixel in bianco o nero .
Chiamiamo preprocessImage per vedere se il testo estratto dalla carta regalo precedente può essere più accurato.
Quando aggiorniamo App.js, ora dovrebbe assomigliare al codice questo:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default AppInnanzitutto, dobbiamo importare "preprocessImage" da "preprocess.js" con il codice seguente:
import preprocessImage from './preprocess'; Quindi, aggiungiamo un tag canvas al modulo. Impostiamo l'attributo ref di entrambi i tag canvas e img su { canvasRef } e { imageRef } rispettivamente. I riferimenti vengono utilizzati per accedere alla tela e all'immagine dal componente App. Prendiamo sia la tela che l'immagine con "useRef" come in:
const canvasRef = useRef(null); const imageRef = useRef(null);In questa parte del codice, uniamo l'immagine alla tela poiché possiamo solo preelaborare una tela in JavaScript. Quindi lo convertiamo in un URL di dati con "jpeg" come formato immagine.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");"dataUrl" viene passato a Tesseract come immagine da elaborare.
Ora, controlliamo se il testo estratto sarà più accurato.
Prova n. 2

L'immagine sopra mostra il risultato in Firefox. È ovvio che la parte scura dell'immagine è stata cambiata in bianca, ma la preelaborazione dell'immagine non porta a un risultato più accurato. È anche peggio.
La prima conversione ha solo due caratteri errati ma questa ha quattro caratteri errati. Ho anche provato a cambiare il livello di soglia ma senza successo. Non otteniamo un risultato migliore non perché la binarizzazione sia negativa, ma perché la binarizzazione dell'immagine non risolve la natura dell'immagine in un modo adatto al motore Tesseract.
Controlliamo come appare anche in Chrome:

Otteniamo lo stesso risultato.
Dopo aver ottenuto un risultato peggiore binarizzando l'immagine, è necessario controllare altre tecniche di preelaborazione dell'immagine per vedere se siamo in grado di risolvere il problema o meno. Quindi, proveremo successivamente la dilatazione, l'inversione e la sfocatura.
Prendiamo solo il codice per ciascuna delle tecniche da P5.js come utilizzato in questo articolo. Aggiungeremo le tecniche di elaborazione delle immagini a preprocess.js e le useremo una per una. È necessario comprendere ciascuna delle tecniche di preelaborazione delle immagini che vogliamo utilizzare prima di usarle, quindi le discuteremo prima.
Cos'è la dilatazione?
La dilatazione aggiunge pixel ai contorni degli oggetti in un'immagine per renderla più ampia, più grande o più aperta. La tecnica "dilata" viene utilizzata per preelaborare le nostre immagini per aumentare la luminosità degli oggetti sulle immagini. Abbiamo bisogno di una funzione per dilatare le immagini usando JavaScript, quindi lo snippet di codice per dilatare un'immagine viene aggiunto a preprocess.js.
Cos'è la sfocatura?
La sfocatura attenua i colori di un'immagine riducendone la nitidezza. A volte, le immagini hanno piccoli punti/macchie. Per rimuovere quelle patch, possiamo sfocare le immagini. Il frammento di codice per sfocare un'immagine è incluso in preprocess.js.
Cos'è l'inversione?
L'inversione cambia le aree chiare di un'immagine in un colore scuro e le aree scure in un colore chiaro. Ad esempio, se un'immagine ha uno sfondo nero e un primo piano bianco, possiamo invertirla in modo che il suo sfondo sia bianco e il suo primo piano sia nero. Abbiamo anche aggiunto lo snippet di codice per invertire un'immagine in preprocess.js.
Dopo aver aggiunto dilate , invertColors e blurARGB a "preprocess.js", ora possiamo usarli per preelaborare le immagini. Per usarli, dobbiamo aggiornare la funzione iniziale "preprocessImage" in preprocess.js:
preprocessImage(...) ora appare così:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } In preprocessImage sopra, applichiamo quattro tecniche di preelaborazione a un'immagine: blurARGB() per rimuovere i punti sull'immagine, dilate() per aumentare la luminosità dell'immagine, invertColors() per cambiare il colore di primo piano e di sfondo dell'immagine e thresholdFilter() per convertire l'immagine in bianco e nero, che è più adatta alla conversione di Tesseract.
Il thresholdFilter() prende image.data e level come parametri. level è usato per impostare quanto bianca o nera dovrebbe essere l'immagine. Abbiamo determinato il livello di thresholdFilter e il raggio di blurRGB per tentativi ed errori poiché non siamo sicuri di quanto bianca, scura o liscia debba essere l'immagine affinché Tesseract produca un ottimo risultato.
Prova n. 3
Ecco il nuovo risultato dopo aver applicato quattro tecniche:

L'immagine sopra rappresenta il risultato che otteniamo sia in Chrome che in Firefox.
Ops! Il risultato è terribile.
Invece di usare tutte e quattro le tecniche, perché non ne usiamo solo due alla volta?
Sì! Possiamo semplicemente usare le tecniche invertColors e thresholdFilter per convertire l'immagine in bianco e nero e cambiare il primo piano e lo sfondo dell'immagine. Ma come facciamo a sapere cosa e quali tecniche combinare? Sappiamo cosa combinare in base alla natura dell'immagine che vogliamo preelaborare.
Ad esempio, un'immagine digitale deve essere convertita in bianco e nero e un'immagine con patch deve essere sfocata per rimuovere i punti/macchie. Ciò che conta davvero è capire a cosa serve ciascuna delle tecniche.
Per utilizzare invertColors e thresholdFilter , dobbiamo commentare sia blurARGB che dilate in preprocessImage :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }Prova n. 4
Ora, ecco il nuovo risultato:

Il risultato è ancora peggiore di quello senza alcuna preelaborazione. Dopo aver adattato ciascuna delle tecniche per questa particolare immagine e per alcune altre immagini, sono giunto alla conclusione che immagini di natura diversa richiedono diverse tecniche di preelaborazione.
In breve, l'utilizzo di Tesseract.js senza la preelaborazione dell'immagine ha prodotto il miglior risultato per la carta regalo sopra. Tutti gli altri esperimenti con la preelaborazione delle immagini hanno prodotto risultati meno accurati.
Problema
Inizialmente, volevo estrarre il PIN da qualsiasi carta regalo Amazon, ma non ci sono riuscito perché non ha senso abbinare un PIN incoerente per ottenere un risultato coerente. Sebbene sia possibile elaborare un'immagine per ottenere un PIN accurato, tale preelaborazione sarà incoerente nel momento in cui verrà utilizzata un'altra immagine di natura diversa.
Il miglior risultato prodotto
L'immagine qui sotto mostra il miglior risultato prodotto dagli esperimenti.
Prova n. 5

I testi sull'immagine e quelli estratti sono totalmente gli stessi. La conversione ha una precisione del 100%. Ho provato a riprodurre il risultato ma sono riuscito a riprodurlo solo utilizzando immagini di natura simile.
Osservazione e lezioni
- Alcune immagini che non sono preelaborate possono dare risultati diversi in browser diversi . Questa affermazione è evidente nella prima prova. Il risultato in Firefox è diverso da quello in Chrome. Tuttavia, la preelaborazione delle immagini aiuta a ottenere un risultato coerente in altri test.
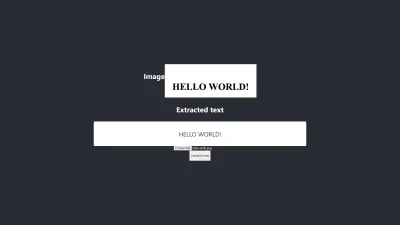
- Il colore nero su sfondo bianco tende a dare risultati gestibili. L'immagine seguente è un esempio di un risultato accurato senza alcuna preelaborazione . Sono stato anche in grado di ottenere lo stesso livello di accuratezza preelaborando l'immagine, ma sono stati necessari molti aggiustamenti che non erano necessari.
La conversione è accurata al 100%.
- Un testo con caratteri di grandi dimensioni tende ad essere più accurato.
- I caratteri con bordi curvi tendono a confondere Tesseract. Il miglior risultato che ho ottenuto è stato ottenuto utilizzando Arial (font).
- L'OCR attualmente non è abbastanza buono per automatizzare la conversione da immagine a testo, soprattutto quando è richiesto un livello di precisione superiore all'80%. Tuttavia, può essere utilizzato per rendere meno stressante l'elaborazione manuale dei testi sulle immagini estraendo testi per la correzione manuale.
- L'OCR non è attualmente sufficiente per trasmettere informazioni utili agli screen reader per l' accessibilità . Fornire informazioni imprecise a uno screen reader può facilmente fuorviare o distrarre gli utenti.
- L'OCR è molto promettente poiché le reti neurali consentono di apprendere e migliorare. Il deep learning renderà l'OCR un punto di svolta nel prossimo futuro .
- Prendere decisioni con fiducia. Un punteggio di affidabilità può essere utilizzato per prendere decisioni che possono avere un grande impatto sulle nostre applicazioni. Il punteggio di affidabilità può essere utilizzato per determinare se accettare o rifiutare un risultato. Dalla mia esperienza e dal mio esperimento, mi sono reso conto che qualsiasi punteggio di confidenza inferiore a 90 non è davvero utile. Se ho solo bisogno di estrarre alcuni pin da un testo, mi aspetto un punteggio di affidabilità compreso tra 75 e 100 e qualsiasi cosa inferiore a 75 verrà rifiutata .
Nel caso abbia a che fare con testi senza la necessità di estrarne alcuna parte, accetterò sicuramente un punteggio di confidenza compreso tra 90 e 100 ma rifiuterò qualsiasi punteggio inferiore a quello. Ad esempio, se voglio digitalizzare documenti come assegni, una cambiale storica o ogni volta che è necessaria una copia esatta, sarà richiesta una precisione di 90 e oltre. Ma un punteggio compreso tra 75 e 90 è accettabile quando una copia esatta non è importante come ottenere il PIN da una carta regalo. In breve, un punteggio di affidabilità aiuta a prendere decisioni che influiscono sulle nostre applicazioni.
Conclusione
Data la limitazione dell'elaborazione dei dati causata dai testi sulle immagini e gli svantaggi ad essa associati, il riconoscimento ottico dei caratteri (OCR) è una tecnologia utile da adottare. Sebbene l'OCR abbia i suoi limiti, è molto promettente grazie al suo utilizzo di reti neurali.
Nel tempo, l'OCR supererà la maggior parte dei suoi limiti con l'aiuto del deep learning, ma prima di allora, gli approcci evidenziati in questo articolo possono essere utilizzati per affrontare l'estrazione di testo dalle immagini, almeno, per ridurre le difficoltà e le perdite associate alla manualità elaborazione , soprattutto dal punto di vista commerciale.
Ora tocca a te provare l'OCR per estrarre testi dalle immagini. Buona fortuna!
Ulteriori letture
- P5.js
- Pre-elaborazione in OCR
- Migliorare la qualità dell'output
- Utilizzo di JavaScript per preelaborare le immagini per l'OCR
- OCR nel browser con Tesseract.js
- Una rapida storia del riconoscimento ottico dei caratteri
- Il futuro dell'OCR è il Deep Learning
- Cronologia del riconoscimento ottico dei caratteri