
Classificazione delle immagini nella CNN: tutto ciò che devi sapere
Pubblicato: 2021-02-25Sommario
introduzione
Mentre sfogli il feed di Facebook, ti sei mai chiesto come le persone in una foto di gruppo vengano automaticamente etichettate dal software di Facebook? Dietro ogni interfaccia utente interattiva di Facebook che vedi, c'è un algoritmo complesso e potente che viene utilizzato per riconoscere ed etichettare ogni immagine che viene caricata da noi sulla piattaforma dei social media. Con ogni nostra immagine, aiutiamo solo a migliorare l'efficienza dell'algoritmo. Sì, la classificazione delle immagini è uno degli algoritmi più utilizzati in cui vediamo l'applicazione dell'intelligenza artificiale.
Negli ultimi tempi, le reti neurali convoluzionali (CNN) sono diventate uno dei più forti sostenitori del Deep Learning. Un'applicazione popolare di queste reti convoluzionali è la classificazione delle immagini. In questo tutorial, analizzeremo le basi delle reti neurali convoluzionali, vedremo i vari livelli coinvolti nella costruzione di un modello CNN e infine visualizzeremo un esempio dell'attività di classificazione delle immagini.
Classificazione delle immagini
Prima di entrare nei dettagli dell'apprendimento profondo e delle reti neurali convoluzionali, cerchiamo di comprendere le basi della classificazione delle immagini. In generale, la classificazione dell'immagine è definita come l'attività in cui diamo un'immagine come input a un modello costruito utilizzando un algoritmo specifico che restituisce la classe o la probabilità della classe a cui appartiene l'immagine. Questo processo in cui etichettiamo un'immagine per una classe particolare è chiamato apprendimento supervisionato.
C'è un'enorme differenza tra il modo in cui vediamo un'immagine e il modo in cui la macchina (computer) vede la stessa immagine. Per noi siamo in grado di visualizzare l'immagine e caratterizzarla in base al colore e alla dimensione. D'altra parte, alla macchina, tutto ciò che riesce a vedere sono i numeri. I numeri visualizzati sono chiamati pixel.
Ogni pixel ha un valore compreso tra 0 e 255. Quindi, con questi dati numerici, la macchina richiede alcuni passaggi di pre-elaborazione per ricavare alcuni modelli o caratteristiche specifiche che distinguono un'immagine dall'altra. Le reti neurali convoluzionali ci aiutano a costruire algoritmi in grado di derivare lo schema specifico dalle immagini.
Ciò che vediamo contro ciò che vede il computer
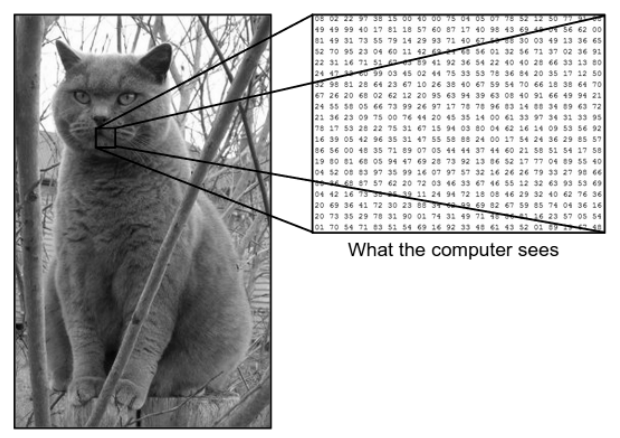 Fonte : differenza tra computer e occhio umano
Fonte : differenza tra computer e occhio umano

Deep Learning per la classificazione delle immagini
Ora che abbiamo capito cos'è la Classificazione delle immagini, vediamo ora come implementarla utilizzando l'Intelligenza Artificiale. Per questo, utilizziamo i popolari metodi di Deep Learning. Il deep learning è un sottoinsieme dell'intelligenza artificiale che utilizza set di dati di immagini di grandi dimensioni per riconoscere e derivare modelli da varie immagini per differenziare tra le varie classi presenti nel set di dati di immagini.
La sfida principale che il Deep Learning deve affrontare è che per un database enorme ci vuole molto tempo e ha un costo computazionale elevato. Tuttavia, il Convolutional Neural Networks, che è un tipo di algoritmo di Deep Learning, affronta bene questo problema.
Reti neurali convoluzionali
In Deep Learning, le reti neurali convoluzionali sono una classe di reti neurali profonde utilizzate principalmente nelle immagini visive. Sono un'architettura speciale delle reti neurali artificiali (ANN) proposta nel 1998 da Yann LeCunn. Le reti neurali convoluzionali sono composte da due parti.
La prima parte è costituita dai livelli Convoluzionali e dai livelli Pooling in cui avviene il processo di estrazione delle caratteristiche principali. Nella seconda parte, i layer Fully Connected e Dense eseguono diverse trasformazioni non lineari sulle feature estratte e fungono da parte del classificatore. Scopri la CNN per la classificazione delle immagini.
Considera l'esempio di immagine sopra mostrato di ciò che l'uomo e la macchina vedono. Come vediamo, il computer vede una serie di pixel. Ad esempio, se la dimensione dell'immagine è 500×500, la dimensione dell'array sarà 500x500x3. Qui, 500 sta per ogni altezza e larghezza, 3 sta per il canale RGB in cui ogni canale di colore è rappresentato da un array separato. L'intensità dei pixel varia da 0 a 255.
Ora per la classificazione delle immagini, il computer cercherà le funzionalità al livello base. Secondo noi come esseri umani, queste caratteristiche di base del gatto sono le sue orecchie, il naso e i baffi. Mentre per il computer, queste caratteristiche di livello base sono le curvature e i confini. In questo modo, utilizzando diversi livelli come i livelli Convoluzionali e i livelli Pooling, il computer estrae le caratteristiche del livello base dalle immagini.
Nel modello Convolutional Neural Network, ci sono diversi tipi di strati come il –
- Livello di input
- Strato convoluzionale
- Strato di pooling
- Livello completamente connesso
- Livello di uscita
- Funzioni di attivazione
Esaminiamo brevemente ciascuno dei livelli prima di entrare nella sua applicazione nella classificazione delle immagini.
Livello di input
Dal nome, capiamo che questo è il livello in cui l'immagine di input verrà inserita nel modello CNN. A seconda delle nostre esigenze, possiamo rimodellare l'immagine in diverse dimensioni come (28,28,3)
Strato convoluzionale
Poi arriva lo strato più importante che consiste in un filtro (noto anche come kernel) con una dimensione fissa. L'operazione matematica di Convoluzione viene eseguita tra l'immagine in ingresso e il filtro. Questa è la fase in cui la maggior parte delle caratteristiche di base come spigoli vivi e curve vengono estratte dall'immagine e quindi questo livello è anche noto come il livello di estrazione delle caratteristiche.
Strato di pooling
Dopo aver eseguito l'operazione di convoluzione, eseguiamo l'operazione di pooling. Questo è anche noto come downsampling in cui il volume spaziale dell'immagine viene ridotto. Ad esempio, se eseguiamo un'operazione di raggruppamento con un passo di 2 su un'immagine con dimensioni 28×28, quindi la dimensione dell'immagine ridotta a 14×14, viene ridotta alla metà della sua dimensione originale.
Livello completamente connesso
Il Fully Connected Layer (FC) viene posizionato appena prima dell'output di classificazione finale del modello CNN. Questi livelli vengono utilizzati per appiattire i risultati prima della classificazione. Coinvolge diversi pregiudizi, pesi e neuroni. L'associazione di un livello FC prima della classificazione si traduce in un vettore N-dimensionale in cui N è un numero di classi tra le quali il modello deve scegliere una classe.
Livello di uscita
Infine, il livello di output è costituito dall'etichetta che è per lo più codificata utilizzando il metodo di codifica one-hot.
Funzione di attivazione
Queste funzioni di attivazione sono il fulcro di qualsiasi modello di rete neurale convoluzionale. Queste funzioni vengono utilizzate per determinare l'output di una rete neurale. In breve, determina se un particolare neurone deve essere attivato ("attivato") o meno. Di solito si tratta di funzioni non lineari eseguite sui segnali di ingresso. Questo output trasformato viene quindi inviato come input al livello successivo di neuroni. Esistono diverse funzioni di attivazione come Sigmoid, ReLU, Leaky ReLU, TanH e Softmax.
Architettura di base della CNN
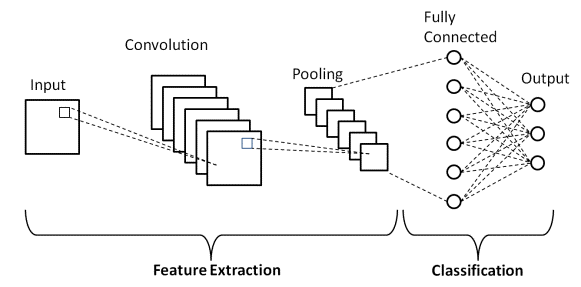
Fonte : architettura CNN di base
Come definito in precedenza, il diagramma sopra mostrato è l'architettura di base di un modello di rete neurale convoluzionale. Ora che siamo pronti con le basi della classificazione delle immagini e della CNN, analizziamo ora la sua applicazione con un problema in tempo reale. Ulteriori informazioni sull'architettura CNN di base.
Implementazione di reti neurali convoluzionali
Ora che abbiamo compreso le basi della classificazione delle immagini e delle reti neurali convoluzionali, visualizziamo la sua implementazione in TensorFlow/Keras con la codifica Python. In questo, costruiremo un semplice modello di rete neurale convoluzionale con un'architettura LeNet di base, addestreremo il modello su un set di addestramento e set di test e infine otterremo l'accuratezza del modello sui dati del set di test.
Problema impostato
In questo articolo per costruire e addestrare il modello di rete neurale convoluzionale, utilizzeremo il famoso set di dati Fashion MNIST. MNIST sta per Modified National Institute of Standards and Technology. Fashion-MNIST è un set di dati delle immagini degli articoli di Zalando, costituito da un set di formazione di 60.000 esempi e un set di test di 10.000 esempi. Ogni esempio è un'immagine in scala di grigi 28×28, associata a un'etichetta di 10 classi.

Ogni esempio di addestramento e test è assegnato a una delle seguenti etichette:
0 – Maglietta/top
1 – Pantaloni
2 – Pullover
3 – Abito
4 – Cappotto
5 – Sandalo
6 – Maglia
7 – Scarpa da ginnastica
8 – Borsa
9 – Stivaletti
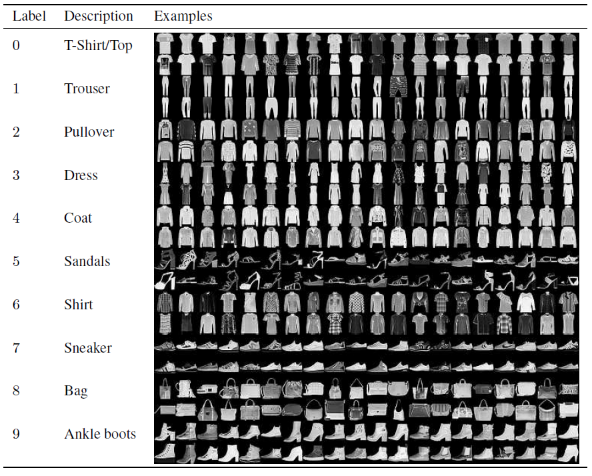
Fonte : Fashion MNIST Dataset Images
Codice del programma
Passaggio 1: importare le librerie
Il primo passo per costruire qualsiasi modello di Deep Learning è importare le librerie necessarie per il programma. Nel nostro esempio, poiché utilizziamo il framework TensorFlow, importeremo la libreria Keras e anche altre importanti librerie come il numero per il calcolo e la matplotlib per tracciare i grafici.
#TensorFlow – Importazione delle librerie
importa numpy come np
importa matplotlib.pyplot come plt
%matplotlib in linea
importa flusso tensoriale come tf
da tensorflow import Keras
Passaggio 2: ottenere e dividere il set di dati
Dopo aver importato le librerie, il passaggio successivo consiste nel scaricare il set di dati e suddividere il set di dati Fashion MNIST nei rispettivi 60.000 dati di addestramento e 10.000 di test. Fortunatamente, keras ci fornisce una funzione predefinita per importare il set di dati Fashion MNIST e possiamo dividerli nella riga successiva usando una semplice riga di codice che è autocomprensibile.
#TensorFlow – Ottenere e dividere il set di dati
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
Passaggio 3 – Visualizzazione dei dati
Poiché il set di dati viene scaricato insieme alle immagini e alle relative etichette, per renderlo più chiaro all'utente, si consiglia sempre di visualizzare i dati in modo da poter comprendere il tipo di dati di cui abbiamo a che fare con la build del Convolutional Neural Modello di rete di conseguenza. Qui, con questo semplice blocco di codice riportato di seguito, visualizzeremo le prime 3 immagini del set di dati di addestramento che viene mischiato in modo casuale.
#TensorFlow – Visualizzazione dei dati
def imshowTensorFlow(img):
plt.imshow(img, cmap='grigio')
print(“Etichetta:”, img[0])
imshowTensorFlow(train_images_tf[0])
Etichetta: 9 Etichetta: 0 Etichetta: 3
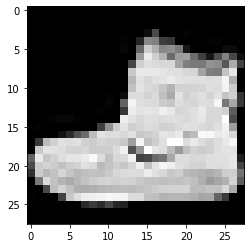


L'immagine sopra indicata e le relative etichette possono essere verificate con le etichette fornite nei dettagli del set di dati Fashion MNIST sopra. Da ciò deduciamo che la nostra immagine di dati è un'immagine in scala di grigi con un'altezza di 28 pixel e una larghezza di 28 pixel.
Quindi, il modello può essere costruito con una dimensione di input di (28,28,1), dove 1 sta per l'immagine in scala di grigi.
Passaggio 4: costruzione del modello
Come accennato in precedenza, in questo articolo costruiremo una semplice rete neurale convoluzionale con l'architettura LeNet. LeNet è una struttura di rete neurale convoluzionale proposta da Yann LeCun et al. nel 1989. In generale, LeNet si riferisce a LeNet-5 ed è una semplice rete neurale convoluzionale.
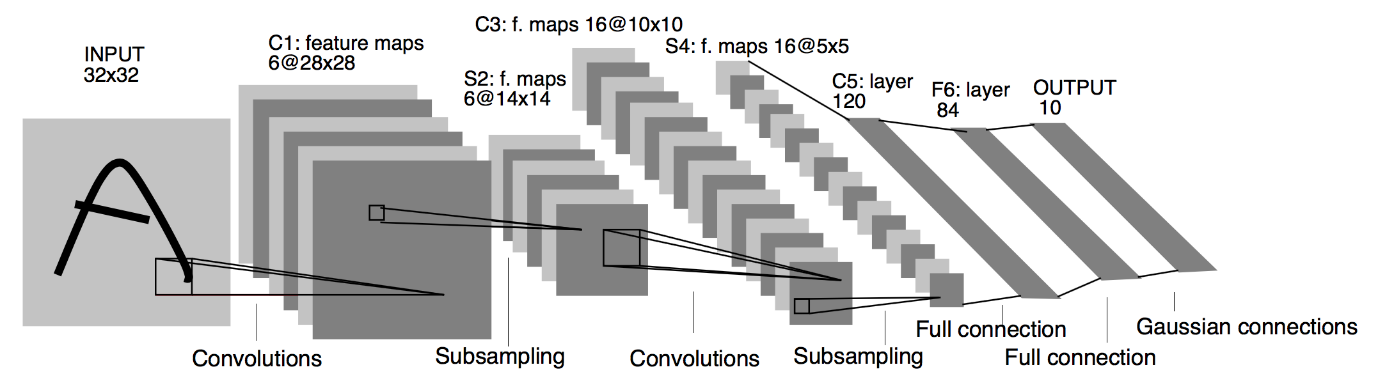
Fonte : L'architettura LeNet
Dal diagramma dell'architettura sopra indicato del modello LeNet CNN, vediamo che ci sono 5+2 strati. Il primo e il secondo livello sono uno strato convoluzionale seguito da uno strato di raggruppamento. Anche in questo caso, il terzo e il quarto strato sono costituiti da uno strato convoluzionale e uno strato di pooling. Come risultato di queste operazioni, la dimensione dell'immagine in ingresso da 28×28 si riduce a 7×7.
Il quinto livello del modello LeNet è il livello completamente connesso che appiattisce l'output del livello precedente. Seguito da due strati Dense, lo strato di output finale del modello CNN consiste in una funzione di attivazione Softmax con 10 unità. La funzione Softmax prevede una probabilità di classe per ciascuna delle 10 classi del set di dati Fashion MNIST.
#TensorFlow – Costruire il modello
modello = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), filtri=6, kernel_size=5, strides=1, padding=”stesso”, attivazione=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, padding=”stesso”, attivazione=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, attivazione=tf.nn.relu),
keras.layers.Dense(84, attivazione=tf.nn.relu),
keras.layers.Dense(10, attivazione=tf.nn.softmax)
])
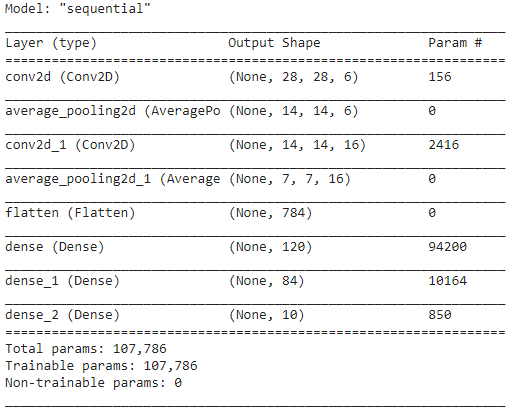
Passaggio 5: riepilogo del modello
Una volta finalizzati i livelli del modello LeNet, possiamo procedere alla compilazione del modello e visualizzare una versione riepilogativa del modello CNN disegnato.
#TensorFlow – Riepilogo del modello
model.compile(loss=keras.losses.categorical_crossentropy,
ottimizzatore='adam',
metriche=['acc'])
modello.riepilogo()
In questo, poiché l'output finale ha più di 2 classi (10 classi), utilizziamo la crossentropia categoriale come funzione di perdita e Adam Optimizer per il nostro modello costruito. Il riepilogo del modello è riportato di seguito.
Passaggio 6 – Formazione del modello
Infine, arriviamo alla parte in cui iniziamo il processo di formazione del modello LeNet CNN. In primo luogo, rimodelliamo il set di dati di addestramento e lo normalizziamo a valori più piccoli dividendo per 255,0 per ridurre il costo computazionale. Quindi le etichette di addestramento vengono convertite da un vettore di classe intero a una matrice di classe binaria. Ad esempio, l'etichetta 3 viene convertita in [0, 0, 0, 1, 0, 0, 0, 0, 0]
#TensorFlow – Allenare il modello
train_images_tensorflow = (train_images_tf / 255.0).reshape(train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
Alla fine dell'allenamento dopo 30 epoche, otteniamo l'accuratezza e la perdita dell'allenamento finale in quanto,
Epoca 30/30
1875/1875 [===============================] – 4s 2ms/passo – perdita: 0,0421 – acc: 0,9850
Precisione dell'allenamento: 98.294997215271 %
Perdita di allenamento: 0.04584110900759697
Passaggio 7: prevedere i risultati
Infine, una volta terminato il nostro processo di addestramento del modello CNN, adatteremo lo stesso modello al set di dati di test e prevediamo l'accuratezza di 10.000 immagini di test.
#TensorFlow – Confronto dei risultati
previsioni = model.predict(test_images_tensorflow)
corretto = 0
per i, pred in enumerate(predictions):
if np.argmax(pred) == test_labels_tf[i]:
corretto += 1
print('Accuratezza di prova del modello sulle immagini di prova {}: {}% con TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0]))
L'output che otteniamo è
Test Precisione del modello sulle 10000 immagini di prova: 90,67% con TensorFlow
Con questo, si conclude il programma sulla costruzione di un modello di classificazione delle immagini con reti neurali convoluzionali.
Leggi anche: Idee per progetti di apprendimento automatico
Conclusione
Pertanto, in questo tutorial sull'implementazione della classificazione delle immagini nella CNN, abbiamo compreso i concetti di base alla base della classificazione delle immagini, delle reti neurali convoluzionali insieme alla sua implementazione nel linguaggio di programmazione Python con il framework TensorFlow.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Stato di ex alunni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Quale modello della CNN è considerato il più ottimale per la classificazione delle immagini?
Il miglior modello CNN per la classificazione delle immagini è il VGG-16, che sta per Very Deep Convolutional Networks for Large-Scale Image Recognition. VGG, che è stato progettato come una CNN profonda, supera le linee di base su un'ampia gamma di attività e set di dati al di fuori di ImageNet. La caratteristica distintiva del modello è che durante la sua creazione, è stata posta maggiore attenzione sull'incorporazione di eccellenti strati di convoluzione piuttosto che concentrarsi sull'aggiunta di un gran numero di iperparametri. Ha un totale di 16 livelli, 5 blocchi e ogni blocco ha un livello massimo di pooling, il che lo rende una rete abbastanza grande.
Quali sono gli svantaggi dell'utilizzo dei modelli CNN per la classificazione delle immagini?
Quando si tratta di classificazione delle immagini, i modelli CNN hanno molto successo. Tuttavia, ci sono diversi inconvenienti nell'impiegare le CNN. Se l'immagine da identificare è inclinata o ruotata, il modello CNN ha problemi a identificare con precisione l'immagine. Quando la CNN visualizza le immagini, non ci sono rappresentazioni interne dei componenti e delle loro connessioni parte-tutto. Inoltre, se il modello CNN da impiegare include numerosi strati convoluzionali, il processo di classificazione richiederà molto tempo.
Perché l'uso del modello CNN è preferito rispetto all'ANN per i dati di immagine come input?
Combinando filtri o trasformazioni, la CNN può apprendere molti livelli di rappresentazioni delle caratteristiche per ogni immagine fornita come input. L'overfitting è diminuito poiché il numero di parametri che la rete deve apprendere nella CNN è sostanzialmente inferiore rispetto alle reti neurali multistrato. Quando si utilizza l'ANN, le reti neurali possono apprendere una rappresentazione di una singola caratteristica dell'immagine, ma, nel caso di immagini complesse, l'ANN non fornirà visualizzazioni o classificazioni migliorate poiché non può apprendere le dipendenze dei pixel esistenti nelle immagini di input.