
HTTP/3: miglioramenti delle prestazioni (parte 2)
Pubblicato: 2022-03-10Bentornati a questa serie sul nuovo protocollo HTTP/3. Nella parte 1, abbiamo esaminato il motivo per cui abbiamo esattamente bisogno di HTTP/3 e del protocollo QUIC sottostante e quali sono le loro principali nuove funzionalità.
In questa seconda parte, analizzeremo i miglioramenti delle prestazioni che QUIC e HTTP/3 apportano alla tabella per il caricamento delle pagine Web. Tuttavia, saremo anche alquanto scettici sull'impatto che possiamo aspettarci nella pratica da queste nuove funzionalità.
Come vedremo, QUIC e HTTP/3 hanno davvero un grande potenziale di prestazioni web, ma principalmente per utenti su reti lente . Se il tuo visitatore medio si trova su una rete mobile o cablata veloce, probabilmente non trarrà molto vantaggio dai nuovi protocolli. Tuttavia, tieni presente che anche nei paesi e nelle regioni con uplink tipicamente veloci, l'1% fino al 10% più lento del tuo pubblico (il cosiddetto 99° o 90° percentile ) può potenzialmente guadagnare molto. Questo perché HTTP/3 e QUIC aiutano principalmente ad affrontare i problemi alquanto insoliti ma potenzialmente ad alto impatto che possono sorgere su Internet di oggi.
Questa parte è un po' più tecnica della prima, anche se scarica la maggior parte delle cose davvero profonde a fonti esterne, concentrandosi sulla spiegazione del perché queste cose sono importanti per lo sviluppatore web medio.
- Parte 1: Storia di HTTP/3 e concetti fondamentali
Questo articolo è rivolto a persone che non conoscono HTTP/3 e protocolli in generale e discute principalmente le nozioni di base. - Parte 2: Funzionalità di prestazione HTTP/3
Questo è più approfondito e tecnico. Le persone che già conoscono le basi possono iniziare da qui. - Parte 3: Pratiche opzioni di distribuzione HTTP/3
Questo terzo articolo della serie spiega le sfide legate alla distribuzione e al test di HTTP/3 da soli. Descrive in dettaglio come e se è necessario modificare anche le pagine Web e le risorse.
Una guida alla velocità
Discutere di prestazioni e "velocità" può diventare rapidamente complesso, perché molti aspetti sottostanti contribuiscono al caricamento "lento" di una pagina Web. Poiché qui abbiamo a che fare con i protocolli di rete, esamineremo principalmente gli aspetti della rete, di cui due sono i più importanti: latenza e larghezza di banda.
La latenza può essere approssimativamente definita come il tempo necessario per inviare un pacchetto dal punto A (ad esempio, il client) al punto B (il server) . È fisicamente limitato dalla velocità della luce o, praticamente, dalla velocità con cui i segnali possono viaggiare nei cavi o all'aria aperta. Ciò significa che la latenza spesso dipende dalla distanza fisica nel mondo reale tra A e B.
Sulla terra, questo significa che le latenze tipiche sono concettualmente piccole, comprese tra circa 10 e 200 millisecondi. Tuttavia, questo è solo un modo: anche le risposte ai pacchetti devono tornare. La latenza bidirezionale è spesso chiamata tempo di andata e ritorno (RTT) .
A causa di funzionalità come il controllo della congestione (vedi sotto), avremo spesso bisogno di alcuni viaggi di andata e ritorno per caricare anche un singolo file. Pertanto, anche basse latenze inferiori a 50 millisecondi possono comportare ritardi considerevoli. Questo è uno dei motivi principali per cui esistono reti di distribuzione dei contenuti (CDN): posizionano i server fisicamente più vicini all'utente finale per ridurre la latenza e quindi ritardare il più possibile.
La larghezza di banda, quindi, può essere approssimativamente definita come il numero di pacchetti che possono essere inviati contemporaneamente . Questo è un po' più difficile da spiegare, perché dipende dalle proprietà fisiche del mezzo (ad esempio, la frequenza utilizzata delle onde radio), dal numero di utenti sulla rete e anche dai dispositivi che interconnettono diverse sottoreti (perché in genere può elaborare solo un certo numero di pacchetti al secondo).
Una metafora spesso usata è quella di un tubo usato per trasportare l'acqua. La lunghezza del tubo è la latenza, mentre la larghezza del tubo è la larghezza di banda. Su Internet, tuttavia, abbiamo in genere una lunga serie di tubi collegati , alcuni dei quali possono essere più larghi di altri (portando ai cosiddetti colli di bottiglia nei collegamenti più stretti). In quanto tale, la larghezza di banda end-to-end tra i punti A e B è spesso limitata dalle sottosezioni più lente.
Sebbene una perfetta comprensione di questi concetti non sia necessaria per il resto di questo post, avere una definizione comune di alto livello sarebbe positivo. Per ulteriori informazioni, consiglio di dare un'occhiata all'eccellente capitolo di Ilya Grigorik sulla latenza e la larghezza di banda nel suo libro High Performance Browser Networking .
Controllo della congestione
Un aspetto delle prestazioni riguarda l' efficienza con cui un protocollo di trasporto può utilizzare l'intera larghezza di banda (fisica) di una rete (cioè, all'incirca, quanti pacchetti al secondo possono essere inviati o ricevuti). Questo a sua volta influisce sulla velocità con cui le risorse di una pagina possono essere scaricate. Alcuni sostengono che QUIC in qualche modo lo faccia molto meglio di TCP, ma non è vero.
Lo sapevate?
Una connessione TCP, ad esempio, non inizia semplicemente a inviare dati a piena larghezza di banda, perché ciò potrebbe finire per sovraccaricare (o congestionare) la rete. Questo perché, come abbiamo detto, ogni collegamento di rete ha solo una certa quantità di dati che può (fisicamente) elaborare ogni secondo. Dagli di più e non c'è altra opzione se non quella di eliminare i pacchetti in eccesso, portando alla perdita di pacchetti .
Come discusso nella parte 1, per un protocollo affidabile come TCP, l'unico modo per recuperare dalla perdita di pacchetti è ritrasmettere una nuova copia dei dati, che richiede un round trip. Soprattutto su reti ad alta latenza (ad esempio, con un RTT di oltre 50 millisecondi), la perdita di pacchetti può influire seriamente sulle prestazioni.
Un altro problema è che non sappiamo in anticipo quanto sarà la larghezza di banda massima . Spesso dipende da un collo di bottiglia da qualche parte nella connessione end-to-end, ma non possiamo prevedere o sapere dove sarà. Internet inoltre non ha meccanismi (ancora) per segnalare le capacità di collegamento agli endpoint.
Inoltre, anche se conoscessimo la larghezza di banda fisica disponibile, ciò non significherebbe che potremmo usarla tutta da soli. Diversi utenti sono in genere attivi su una rete contemporaneamente, ognuno dei quali ha bisogno di una giusta quota della larghezza di banda disponibile.
In quanto tale, una connessione non sa quanta larghezza di banda può utilizzare in modo sicuro o corretto in anticipo e questa larghezza di banda può cambiare quando gli utenti si uniscono, lasciano e utilizzano la rete. Per risolvere questo problema, TCP cercherà costantemente di scoprire la larghezza di banda disponibile nel tempo utilizzando un meccanismo chiamato congestion control .
All'inizio della connessione, invia solo pochi pacchetti (in pratica, tra 10 e 100 pacchetti, o circa 14 e 140 KB di dati) e attende un round trip fino a quando il destinatario non restituisce i riconoscimenti di questi pacchetti. Se vengono tutti riconosciuti, significa che la rete può gestire quella velocità di invio e possiamo provare a ripetere il processo ma con più dati (in pratica, la velocità di invio di solito raddoppia ad ogni iterazione).
In questo modo, la velocità di invio continua a crescere fino a quando alcuni pacchetti non vengono riconosciuti (che indica la perdita di pacchetti e la congestione della rete). Questa prima fase è in genere chiamata "partenza lenta". Al rilevamento della perdita di pacchetti, TCP riduce la velocità di invio e (dopo un po') ricomincia ad aumentare la velocità di invio, anche se con incrementi (molto) inferiori. Questa logica di riduzione e crescita viene ripetuta per ogni perdita di pacchetti in seguito. Alla fine, ciò significa che TCP cercherà costantemente di raggiungere la sua condivisione di larghezza di banda ideale ed equa. Questo meccanismo è illustrato nella figura 1.
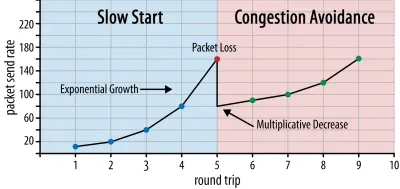
Questa è una spiegazione estremamente semplificata del controllo della congestione. In pratica, sono in gioco molti altri fattori, come il bufferbloat, la fluttuazione degli RTT a causa della congestione e il fatto che più mittenti simultanei devono ottenere la loro giusta quota di larghezza di banda. Pertanto, esistono molti diversi algoritmi di controllo della congestione e molti vengono ancora inventati oggi, nessuno dei quali funziona in modo ottimale in tutte le situazioni.
Sebbene il controllo della congestione di TCP lo renda robusto, significa anche che ci vuole del tempo per raggiungere velocità di invio ottimali , a seconda dell'RTT e della larghezza di banda disponibile effettiva. Per il caricamento delle pagine Web, questo approccio ad avvio lento può influire anche su metriche come il primo disegno di contenuto, poiché solo una piccola quantità di dati (da decine a poche centinaia di KB) può essere trasferita nei primi round trip. (Potresti aver sentito la raccomandazione di mantenere i tuoi dati critici a meno di 14 KB.)
La scelta di un approccio più aggressivo potrebbe quindi portare a risultati migliori su reti ad alta larghezza di banda e ad alta latenza, soprattutto se non ti interessa la perdita occasionale di pacchetti. È qui che ho visto di nuovo molte interpretazioni errate su come funziona QUIC.
Come discusso nella parte 1, QUIC, in teoria, soffre meno della perdita di pacchetti (e del relativo blocco dell'head-of-line (HOL)) perché tratta la perdita di pacchetti sul flusso di byte di ciascuna risorsa in modo indipendente. Inoltre, QUIC viene eseguito su User Datagram Protocol (UDP), che, a differenza di TCP, non ha una funzione di controllo della congestione integrata; ti consente di provare a inviare alla velocità che desideri e non ritrasmette i dati persi.
Ciò ha portato a molti articoli che affermano che anche QUIC non utilizza il controllo della congestione, che QUIC può invece iniziare a inviare dati a una velocità molto più elevata rispetto a UDP (facendo affidamento sulla rimozione del blocco HOL per far fronte alla perdita di pacchetti), ecco perché QUIC è molto più veloce di TCP.
In realtà, nulla potrebbe essere più lontano dalla verità: QUIC utilizza in realtà tecniche di gestione della larghezza di banda molto simili a TCP . Anch'esso inizia con una velocità di trasmissione inferiore e la aumenta nel tempo, utilizzando i riconoscimenti come meccanismo chiave per misurare la capacità della rete. Questo è (tra gli altri motivi) perché QUIC deve essere affidabile per essere utile per qualcosa come HTTP, perché deve essere corretto con altre connessioni QUIC (e TCP!) E perché la sua rimozione del blocco HOL non lo fa in realtà aiuta molto bene contro la perdita di pacchetti (come vedremo di seguito).
Tuttavia, ciò non significa che QUIC non possa essere (un po') più intelligente su come gestisce la larghezza di banda rispetto a TCP. Ciò è principalmente dovuto al fatto che QUIC è più flessibile e più facile da evolvere rispetto a TCP . Come abbiamo detto, gli algoritmi di controllo della congestione sono ancora in forte evoluzione oggi e probabilmente dovremo, ad esempio, modificare le cose per ottenere il massimo dal 5G.
Tuttavia, TCP è in genere implementato nel kernel del sistema operativo (OS), un ambiente sicuro e più limitato, che per la maggior parte dei sistemi operativi non è nemmeno open source. Pertanto, l'ottimizzazione della logica di congestione viene solitamente eseguita solo da pochi sviluppatori selezionati e l'evoluzione è lenta.
Al contrario, la maggior parte delle implementazioni QUIC vengono attualmente eseguite nello "spazio utente" (dove in genere eseguiamo app native) e sono rese open source, esplicitamente per incoraggiare la sperimentazione da parte di un pool molto più ampio di sviluppatori (come già mostrato, ad esempio, da Facebook ).
Un altro esempio concreto è la proposta di estensione della frequenza di riconoscimento ritardato per QUIC. Mentre, per impostazione predefinita, QUIC invia un riconoscimento ogni 2 pacchetti ricevuti, questa estensione consente invece agli endpoint di riconoscere, ad esempio, ogni 10 pacchetti. È stato dimostrato che ciò offre grandi vantaggi in termini di velocità su reti satellitari e con larghezza di banda molto elevata, poiché il sovraccarico della trasmissione dei pacchetti di riconoscimento viene ridotto. L'aggiunta di tale estensione per TCP richiederebbe molto tempo per essere adottata, mentre per QUIC è molto più semplice da implementare.
Pertanto, possiamo aspettarci che la flessibilità di QUIC porterà a una maggiore sperimentazione e a migliori algoritmi di controllo della congestione nel tempo, che a loro volta potrebbero anche essere trasferiti su TCP per migliorarlo.
Lo sapevate?
La QUIC Recovery RFC 9002 ufficiale specifica l'uso dell'algoritmo di controllo della congestione NewReno. Sebbene questo approccio sia robusto, è anche alquanto obsoleto e non è più ampiamente utilizzato nella pratica. Allora, perché è nel QUIC RFC? Il primo motivo è che quando è stato avviato QUIC, NewReno era l'algoritmo di controllo della congestione più recente che era esso stesso standardizzato. Algoritmi più avanzati, come BBR e CUBIC, non sono ancora standardizzati o sono diventati RFC solo di recente.
Il secondo motivo è che NewReno è una configurazione relativamente semplice. Poiché gli algoritmi richiedono alcune modifiche per gestire le differenze di QUIC rispetto a TCP, è più facile spiegare tali modifiche su un algoritmo più semplice. In quanto tale, RFC 9002 dovrebbe essere letto più come "come adattare un algoritmo di controllo della congestione a QUIC", piuttosto che "questa è la cosa che dovresti usare per QUIC". In effetti, la maggior parte delle implementazioni QUIC a livello di produzione ha realizzato implementazioni personalizzate sia di Cubic che di BBR.
Vale la pena ripetere che gli algoritmi di controllo della congestione non sono specifici per TCP o QUIC ; possono essere utilizzati da entrambi i protocolli e la speranza è che i progressi in QUIC alla fine trovino la loro strada anche negli stack TCP.
Lo sapevate?
Si noti che, accanto al controllo della congestione c'è un concetto correlato chiamato controllo del flusso. Queste due funzionalità sono spesso confuse in TCP, perché si dice che entrambe utilizzino la "finestra TCP" , sebbene in realtà ci siano due finestre: la finestra di congestione e la finestra di ricezione TCP. Il controllo del flusso, tuttavia, entra in gioco molto meno per il caso d'uso del caricamento di pagine Web che ci interessa, quindi lo salteremo qui. Sono disponibili informazioni più approfondite.
Che cosa significa tutto questo?
QUIC è ancora vincolato dalle leggi della fisica e dalla necessità di essere gentile con gli altri mittenti su Internet. Ciò significa che non scaricherà magicamente le risorse del tuo sito Web molto più rapidamente di TCP. Tuttavia, la flessibilità di QUIC significa che la sperimentazione di nuovi algoritmi di controllo della congestione diventerà più semplice, il che dovrebbe migliorare le cose in futuro sia per TCP che per QUIC.
Configurazione della connessione 0-RTT
Un secondo aspetto relativo alle prestazioni riguarda il numero di round trip necessari prima di poter inviare dati HTTP utili (ad esempio, risorse di pagina) su una nuova connessione. Alcuni sostengono che QUIC sia da due a tre round trip più veloce di TCP + TLS, ma vedremo che in realtà è solo uno.
Lo sapevate?
Come abbiamo detto nella parte 1, una connessione esegue in genere uno (TCP) o due (TCP + TLS) handshake prima che le richieste e le risposte HTTP possano essere scambiate. Questi handshake scambiano parametri iniziali che sia il client che il server devono conoscere per, ad esempio, crittografare i dati.
Come puoi vedere nella figura 2 di seguito, ogni singola stretta di mano richiede almeno un viaggio di andata e ritorno per essere completata (TCP + TLS 1.3, (b)) e talvolta due (TLS 1.2 e precedenti (a)). Questo è inefficiente, perché abbiamo bisogno di almeno due round trip del tempo di attesa dell'handshake (overhead) prima di poter inviare la nostra prima richiesta HTTP, il che significa attendere almeno tre round trip per i primi dati di risposta HTTP (la freccia rossa di ritorno) per arrivare in. Su reti lente, questo può significare un sovraccarico da 100 a 200 millisecondi.
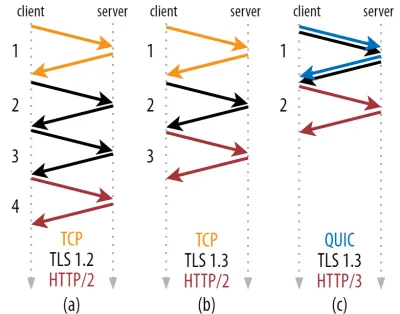
Ti starai chiedendo perché l'handshake TCP + TLS non può essere semplicemente combinato, eseguito nello stesso viaggio di andata e ritorno. Sebbene ciò sia concettualmente possibile (QUIC fa esattamente questo), inizialmente le cose non erano progettate in questo modo, perché dobbiamo essere in grado di utilizzare TCP con e senza TLS in cima. In altre parole, TCP semplicemente non supporta l'invio di materiale non TCP durante l'handshake. Ci sono stati sforzi per aggiungere questo con l'estensione TCP Fast Open; tuttavia, come discusso nella parte 1, questo si è rivelato difficile da implementare su larga scala.
Fortunatamente, QUIC è stato progettato pensando a TLS fin dall'inizio e, in quanto tale, combina sia il trasporto che le strette di mano crittografiche in un unico meccanismo. Ciò significa che il completamento dell'handshake QUIC richiederà un solo viaggio di andata e ritorno in totale, ovvero un viaggio di andata e ritorno in meno rispetto a TCP + TLS 1.3 (vedere la figura 2c sopra).
Potresti essere confuso, perché probabilmente hai letto che QUIC è due o anche tre round trip più veloce di TCP, non solo uno. Questo perché la maggior parte degli articoli considera solo il caso peggiore (TCP + TLS 1.2, (a)), senza menzionare che anche il moderno TCP + TLS 1.3 effettua "solo" due round trip ((b) viene mostrato raramente). Mentre un aumento di velocità di un viaggio di andata e ritorno è bello, non è affatto sorprendente. Soprattutto su reti veloci (diciamo, meno di un RTT di 50 millisecondi), questo sarà appena percettibile , sebbene le reti lente e le connessioni a server distanti traggano profitto un po' di più.
Successivamente, potresti chiederti perché dobbiamo aspettare la stretta di mano. Perché non possiamo inviare una richiesta HTTP nel primo round trip? Questo principalmente perché, se lo facessimo, la prima richiesta verrebbe inviata non crittografata , leggibile da qualsiasi intercettatore sul filo, il che ovviamente non è eccezionale per la privacy e la sicurezza. Pertanto, è necessario attendere il completamento dell'handshake crittografico prima di inviare la prima richiesta HTTP. O noi?
È qui che viene utilizzato in pratica un trucco intelligente. Sappiamo che gli utenti spesso rivisitano le pagine web entro breve tempo dalla loro prima visita. Pertanto, possiamo utilizzare la connessione crittografata iniziale per avviare una seconda connessione in futuro. In poche parole, a volte durante la sua vita, la prima connessione viene utilizzata per comunicare in modo sicuro nuovi parametri crittografici tra il client e il server. Questi parametri possono quindi essere utilizzati per crittografare la seconda connessione dall'inizio, senza dover attendere il completamento dell'handshake TLS completo. Questo approccio è chiamato "ripresa della sessione" .
Consente una potente ottimizzazione: ora possiamo inviare in sicurezza la nostra prima richiesta HTTP insieme all'handshake QUIC/TLS, risparmiando un altro viaggio di andata e ritorno ! Come per TLS 1.3, questo rimuove efficacemente il tempo di attesa dell'handshake TLS. Questo metodo è spesso chiamato 0-RTT (sebbene, ovviamente, ci voglia ancora un round trip prima che i dati di risposta HTTP inizino ad arrivare).
Sia la ripresa della sessione che 0-RTT sono, ancora una volta, cose che ho visto spesso erroneamente spiegate come funzionalità specifiche di QUIC. In realtà, si tratta in realtà di funzionalità TLS che erano già presenti in qualche forma in TLS 1.2 e ora sono completamente attive in TLS 1.3.
In altre parole, come puoi vedere nella figura 3 di seguito, possiamo ottenere i vantaggi in termini di prestazioni di queste funzionalità su TCP (e quindi anche HTTP/2 e persino HTTP/1.1)! Vediamo che anche con 0-RTT, QUIC è ancora solo un round trip più veloce di uno stack TCP + TLS 1.3 perfettamente funzionante. L'affermazione che QUIC è tre round trip più veloce deriva dal confronto della figura 2 (a) con la figura 3 (f), il che, come abbiamo visto, non è proprio giusto.
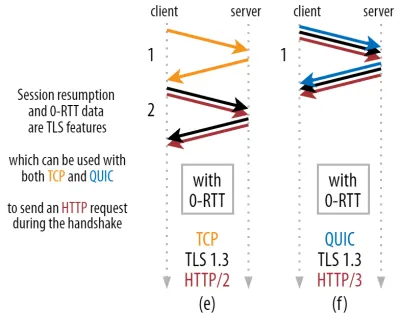
La parte peggiore è che quando si utilizza 0-RTT, QUIC non è nemmeno in grado di utilizzare molto bene quel viaggio di andata e ritorno guadagnato a causa della sicurezza. Per capire questo, dobbiamo capire uno dei motivi per cui esiste l'handshake TCP. Innanzitutto, consente al client di essere sicuro che il server sia effettivamente disponibile all'indirizzo IP specificato prima di inviargli qualsiasi dato di livello superiore.
In secondo luogo, e soprattutto qui, consente al server di assicurarsi che il client che apre la connessione sia effettivamente chi e dove dicono di essere prima di inviargli i dati. Se ricordi come abbiamo definito una connessione con la 4-tupla nella parte 1, saprai che il client è principalmente identificato dal suo indirizzo IP. E questo è il problema: gli indirizzi IP possono essere falsificati !
Si supponga che un utente malintenzionato richieda un file molto grande tramite HTTP su QUIC 0-RTT. Tuttavia, falsificano il loro indirizzo IP, facendo sembrare che la richiesta 0-RTT provenga dal computer della loro vittima. Ciò è mostrato nella figura 4 di seguito. Il server QUIC non ha modo di rilevare se l'IP è stato contraffatto, perché questo è il primo pacchetto che vede da quel client.

Se il server inizia semplicemente a inviare il file di grandi dimensioni all'IP contraffatto, potrebbe finire per sovraccaricare la larghezza di banda della rete della vittima (soprattutto se l'attaccante dovesse eseguire molte di queste false richieste in parallelo). Nota che la risposta QUIC verrebbe eliminata dalla vittima, perché non si aspetta dati in arrivo, ma non importa: la loro rete deve ancora elaborare i pacchetti!
Questo è chiamato riflessione, o amplificazione, attacco ed è un modo significativo in cui gli hacker eseguono attacchi DDoS (Distributed Denial-of-Service). Si noti che ciò non accade quando viene utilizzato 0-RTT su TCP + TLS, proprio perché l'handshake TCP deve essere completato prima che la richiesta 0-RTT venga inviata insieme all'handshake TLS.
Pertanto, QUIC deve essere prudente nel rispondere alle richieste 0-RTT, limitando la quantità di dati che invia in risposta fino a quando il cliente non è stato verificato come un cliente reale e non una vittima. Per QUIC, questo importo di dati è stato impostato su tre volte l'importo ricevuto dal cliente.
In altre parole, QUIC ha un "fattore di amplificazione" massimo di tre, che è stato determinato come un compromesso accettabile tra l'utilità delle prestazioni e il rischio per la sicurezza (soprattutto rispetto ad alcuni incidenti che avevano un fattore di amplificazione di oltre 51.000 volte). Poiché il client in genere invia prima solo uno o due pacchetti, la risposta 0-RTT del server QUIC avrà un limite di soli 4-6 KB (inclusi altri overhead QUIC e TLS!), Il che è un po' meno che impressionante.
Inoltre, altri problemi di sicurezza possono portare, ad esempio, a "attacchi di replica", che limitano il tipo di richiesta HTTP che è possibile eseguire. Ad esempio, Cloudflare consente solo richieste HTTP GET senza parametri di query in 0-RTT. Questi limitano ulteriormente l'utilità di 0-RTT.
Fortunatamente, QUIC ha opzioni per renderlo un po' migliore. Ad esempio, il server può verificare se 0-RTT proviene da un IP con cui ha avuto una connessione valida in precedenza. Tuttavia, funziona solo se il client rimane sulla stessa rete (limitando in qualche modo la funzionalità di migrazione della connessione di QUIC). E anche se funziona, la risposta di QUIC è ancora limitata dalla logica di avvio lento del controller di congestione di cui abbiamo discusso sopra; quindi, non c'è un aumento di velocità extra massiccio oltre a un viaggio di andata e ritorno salvato.
Lo sapevate?
È interessante notare che il limite di amplificazione di tre volte di QUIC conta anche per il suo normale processo di handshake non-0-RTT nella figura 2c. Questo può essere un problema se, ad esempio, il certificato TLS del server è troppo grande per contenere da 4 a 6 KB. In tal caso, dovrebbe essere diviso, con il secondo blocco che deve attendere l'invio del secondo round trip (dopo che sono arrivati i riconoscimenti dei primi pacchetti, indicando che l'IP del client non è stato falsificato). In questo caso, l'handshake di QUIC potrebbe comunque richiedere due round trip , pari a TCP + TLS! Questo è il motivo per cui per QUIC, tecniche come la compressione dei certificati saranno estremamente importanti.
Lo sapevate?
Potrebbe essere che alcune impostazioni avanzate siano in grado di mitigare questi problemi abbastanza da rendere più utile 0-RTT. Ad esempio, il server potrebbe ricordare quanta larghezza di banda aveva un client disponibile l'ultima volta che è stato visto, rendendolo meno limitato dall'avvio lento del controllo della congestione per la riconnessione dei client (non contraffatti). Questo è stato studiato nel mondo accademico e c'è anche un'estensione proposta in QUIC per farlo. Diverse aziende fanno già questo tipo di cose per velocizzare anche il TCP.
Un'altra opzione sarebbe fare in modo che i client inviino più di uno o due pacchetti (ad esempio, inviando altri 7 pacchetti con riempimento), quindi il limite di tre volte si traduce in una risposta più interessante da 12 a 14 KB, anche dopo la migrazione della connessione. Ne ho scritto in uno dei miei giornali.
Infine, i server QUIC (che si comportano male) potrebbero anche aumentare intenzionalmente il limite di tre volte se ritengono che sia in qualche modo sicuro farlo o se non si preoccupano dei potenziali problemi di sicurezza (dopotutto, non esiste una polizia di protocollo che lo impedisca).
Che cosa significa tutto questo?
La configurazione più rapida della connessione di QUIC con 0-RTT è davvero più una micro-ottimizzazione che una nuova funzionalità rivoluzionaria. Rispetto a una configurazione TCP + TLS 1.3 all'avanguardia, risparmierebbe un massimo di un viaggio di andata e ritorno. La quantità di dati che può essere effettivamente inviata nel primo viaggio di andata e ritorno è ulteriormente limitata da una serie di considerazioni di sicurezza.
In quanto tale, questa funzione brillerà principalmente se i tuoi utenti si trovano su reti con latenza molto elevata (ad esempio, reti satellitari con RTT di oltre 200 millisecondi) o se in genere non invii molti dati. Alcuni esempi di questi ultimi sono siti Web con cache pesante, nonché app a pagina singola che recuperano periodicamente piccoli aggiornamenti tramite API e altri protocolli come DNS-over-QUIC. Uno dei motivi per cui Google ha visto risultati 0-RTT molto buoni per QUIC è che lo ha testato sulla sua pagina di ricerca già fortemente ottimizzata, dove le risposte alle query sono piuttosto ridotte.
In altri casi, guadagnerai al massimo solo poche decine di millisecondi , anche meno se stai già utilizzando un CDN (cosa che dovresti fare se ti interessano le prestazioni!).
Migrazione della connessione
Una terza caratteristica delle prestazioni rende QUIC più veloce durante il trasferimento tra reti, mantenendo intatte le connessioni esistenti . Sebbene funzioni davvero, questo tipo di modifica della rete non si verifica così spesso e le connessioni devono comunque ripristinare le velocità di invio.
Come discusso nella parte 1, gli ID di connessione (CID) di QUIC consentono di eseguire la migrazione della connessione quando si cambia rete . Lo abbiamo illustrato con un client che si sposta da una rete Wi-Fi a 4G mentre esegue il download di file di grandi dimensioni. Su TCP, il download potrebbe dover essere interrotto, mentre per QUIC potrebbe continuare.
Innanzitutto, tuttavia, considera la frequenza con cui si verifica effettivamente quel tipo di scenario. Potresti pensare che ciò si verifichi anche quando ti muovi tra punti di accesso Wi-Fi all'interno di un edificio o tra torri cellulari mentre sei in viaggio. In queste configurazioni, tuttavia (se eseguite correttamente), il dispositivo in genere manterrà intatto il proprio IP, poiché la transizione tra le stazioni base wireless avviene a un livello di protocollo inferiore. In quanto tale, si verifica solo quando ci si sposta tra reti completamente diverse , cosa che direi non accade così spesso.
In secondo luogo, possiamo chiederci se funziona anche per altri casi d'uso oltre a download di file di grandi dimensioni e videoconferenze e streaming dal vivo. Se stai caricando una pagina web nel momento esatto in cui cambi rete, potresti dover richiedere nuovamente alcune delle risorse (successive).
Tuttavia, il caricamento di una pagina in genere richiede nell'ordine di secondi, quindi anche la coincidenza con uno switch di rete non sarà molto comune. Inoltre, per i casi d'uso in cui si tratta di un problema urgente, in genere sono già in atto altre misure di mitigazione . Ad esempio, i server che offrono download di file di grandi dimensioni possono supportare richieste di intervallo HTTP per consentire download ripristinabili.
Poiché in genere c'è un certo tempo di sovrapposizione tra l'interruzione della rete 1 e la disponibilità della rete 2, le app video possono aprire più connessioni (1 per rete), sincronizzandole prima che la vecchia rete scompaia completamente. L'utente noterà comunque il passaggio, ma non rilascerà completamente il feed video.
In terzo luogo, non vi è alcuna garanzia che la nuova rete disponga di una larghezza di banda pari a quella precedente. Pertanto, anche se la connessione concettuale viene mantenuta intatta, il server QUIC non può semplicemente continuare a inviare dati ad alta velocità. Invece, per evitare di sovraccaricare la nuova rete, è necessario reimpostare (o almeno abbassare) la velocità di trasmissione e ripartire nella fase di avvio lento del controllore di congestione.
Poiché questa velocità di invio iniziale è in genere troppo bassa per supportare realmente cose come lo streaming video, noterai una perdita di qualità o un singhiozzo, anche su QUIC. In un certo senso, la migrazione della connessione riguarda più la prevenzione dell'abbandono e l'overhead del contesto di connessione sul server che il miglioramento delle prestazioni.
Lo sapevate?
Si noti che, come discusso per 0-RTT sopra, possiamo escogitare alcune tecniche avanzate per migliorare la migrazione della connessione. Ad esempio, possiamo, ancora una volta, provare a ricordare quanta larghezza di banda era disponibile l'ultima volta su una determinata rete e provare a salire più velocemente a quel livello per una nuova migrazione. Inoltre, potremmo immaginare non semplicemente di passare da una rete all'altra, ma di utilizzarle entrambe contemporaneamente. Questo concetto è chiamato multipath e ne parleremo più dettagliatamente di seguito.
Finora abbiamo parlato principalmente di migrazione della connessione attiva, in cui gli utenti si spostano tra reti diverse. Esistono, tuttavia, anche casi di migrazione passiva della connessione, in cui una determinata rete stessa cambia parametri. Un buon esempio di ciò è il rebinding NAT (Network Address Translation). Sebbene una discussione completa su NAT sia fuori dall'ambito di questo articolo, significa principalmente che i numeri di porta della connessione possono cambiare in qualsiasi momento, senza preavviso. Questo accade anche molto più spesso per UDP che per TCP nella maggior parte dei router.
Se ciò si verifica, il QUIC CID non cambierà e la maggior parte delle implementazioni presumerà che l'utente sia ancora sulla stessa rete fisica e quindi non ripristinerà la finestra di congestione o altri parametri. QUIC include anche alcune funzionalità come PING e indicatori di timeout per evitare che ciò accada, poiché ciò si verifica in genere per le connessioni inattive a lungo.
Abbiamo discusso nella parte 1 del fatto che QUIC non utilizza un singolo CID per motivi di sicurezza. Al contrario, cambia i CID durante l'esecuzione della migrazione attiva. In pratica, è ancora più complicato, perché sia il client che il server hanno elenchi separati di CID (chiamati CID di origine e di destinazione nel QUIC RFC). Ciò è illustrato nella figura 5 di seguito.
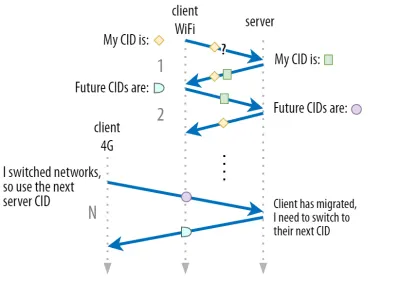
Questo viene fatto per consentire a ciascun endpoint di scegliere il proprio formato e contenuto CID , che a sua volta è fondamentale per consentire l'instradamento avanzato e la logica di bilanciamento del carico. Con la migrazione della connessione, i sistemi di bilanciamento del carico non possono più semplicemente guardare la tupla a 4 per identificare una connessione e inviarla al server back-end corretto. Tuttavia, se tutte le connessioni QUIC dovessero utilizzare CID casuali, ciò aumenterebbe notevolmente i requisiti di memoria nel sistema di bilanciamento del carico, poiché sarebbe necessario archiviare le mappature dei CID sui server back-end. Inoltre, questo non funzionerebbe ancora con la migrazione della connessione, poiché i CID cambiano in nuovi valori casuali.

Pertanto, è importante che i server back-end QUIC distribuiti dietro un sistema di bilanciamento del carico abbiano un formato prevedibile dei CID, in modo che il sistema di bilanciamento del carico possa derivare il server back-end corretto dal CID, anche dopo la migrazione. Alcune opzioni per farlo sono descritte nel documento proposto dall'IETF. Per rendere tutto questo possibile, i server devono poter scegliere il proprio CID, cosa che non sarebbe possibile se l'iniziatore della connessione (che, per QUIC, è sempre il client) scegliesse il CID. Questo è il motivo per cui c'è una divisione tra CID client e server in QUIC.
Che cosa significa tutto questo?
Pertanto, la migrazione della connessione è una caratteristica situazionale. I test iniziali di Google, ad esempio, mostrano miglioramenti in bassa percentuale per i suoi casi d'uso. Molte implementazioni QUIC non implementano ancora questa funzionalità. Anche quelli che lo fanno in genere lo limiteranno a client e app mobili e non ai loro equivalenti desktop. Alcune persone sono addirittura dell'opinione che la funzione non sia necessaria, perché l'apertura di una nuova connessione con 0-RTT dovrebbe avere proprietà di prestazioni simili nella maggior parte dei casi.
Tuttavia, a seconda del caso d'uso o del profilo utente, potrebbe avere un grande impatto. Se il tuo sito web o la tua app viene utilizzato più spesso mentre sei in movimento (ad esempio, qualcosa come Uber o Google Maps), probabilmente ne trarrai vantaggio maggiore che se i tuoi utenti fossero in genere seduti dietro una scrivania. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
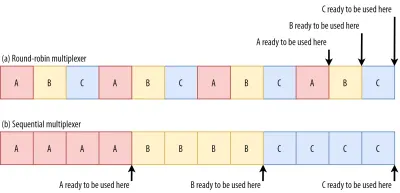
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
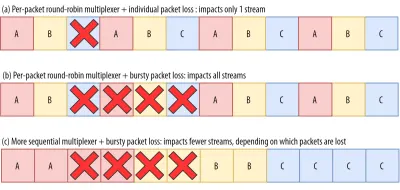
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
Che cosa significa tutto questo?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
Prestazioni UDP e TLS
Un quinto aspetto delle prestazioni di QUIC e HTTP/3 riguarda l'efficienza e le prestazioni con cui possono effettivamente creare e inviare pacchetti sulla rete. Vedremo che l'utilizzo di UDP e crittografia pesante da parte di QUIC può renderlo un po' più lento di TCP (ma le cose stanno migliorando).
Innanzitutto, abbiamo già discusso del fatto che l'utilizzo di UDP da parte di QUIC riguardava più la flessibilità e la distribuzione che le prestazioni. Ciò è dimostrato ancor di più dal fatto che, fino a tempi recenti, l'invio di pacchetti QUIC su UDP era in genere molto più lento dell'invio di pacchetti TCP. Ciò è in parte dovuto al luogo e al modo in cui questi protocolli vengono generalmente implementati (vedere la figura 9 di seguito).
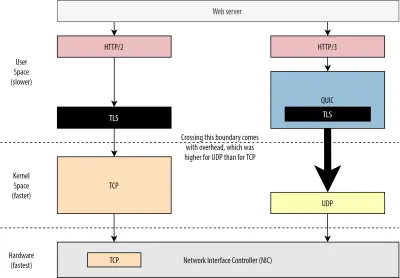
Come discusso in precedenza, TCP e UDP sono in genere implementati direttamente nel kernel veloce del sistema operativo. Al contrario, le implementazioni TLS e QUIC sono per lo più in uno spazio utente più lento (nota che questo non è realmente necessario per QUIC — è principalmente fatto perché è molto più flessibile). Questo rende QUIC già un po' più lento di TCP.
Inoltre, quando inviamo dati dal nostro software user-space (ad esempio, browser e server Web), dobbiamo passare questi dati al kernel del sistema operativo , che quindi utilizza TCP o UDP per inserirli effettivamente nella rete. Il passaggio di questi dati viene eseguito utilizzando le API del kernel (chiamate di sistema), il che comporta una certa quantità di sovraccarico per chiamata API. Per TCP, queste spese generali erano molto inferiori rispetto a UDP.
Ciò è dovuto principalmente al fatto che, storicamente, TCP è stato utilizzato molto più di UDP. Pertanto, nel tempo, sono state aggiunte molte ottimizzazioni alle implementazioni TCP e alle API del kernel per ridurre al minimo le spese generali di invio e ricezione di pacchetti. Molti controller di interfaccia di rete (NIC) dispongono anche di funzionalità di offload hardware integrate per TCP. UDP, tuttavia, non è stato altrettanto fortunato, perché il suo uso più limitato non giustificava l'investimento in ulteriori ottimizzazioni. Negli ultimi cinque anni, questo è fortunatamente cambiato e da allora la maggior parte dei sistemi operativi ha aggiunto opzioni ottimizzate anche per UDP .
In secondo luogo, QUIC ha molto sovraccarico perché crittografa ogni pacchetto individualmente . Questo è più lento rispetto all'utilizzo di TLS su TCP, perché lì puoi crittografare i pacchetti in blocchi (fino a circa 16 KB o 11 pacchetti alla volta), il che è più efficiente. Questo è stato un compromesso consapevole fatto in QUIC, perché la crittografia di massa può portare alle proprie forme di blocco HoL.
A differenza del primo punto, dove potremmo aggiungere API extra per rendere UDP (e quindi QUIC) più veloce, qui, QUIC avrà sempre uno svantaggio intrinseco a TCP + TLS. Tuttavia, questo è anche abbastanza gestibile in pratica con, ad esempio, librerie di crittografia ottimizzate e metodi intelligenti che consentono di crittografare in blocco le intestazioni dei pacchetti QUIC.
Di conseguenza, mentre le prime versioni QUIC di Google erano ancora due volte più lente di TCP + TLS, da allora le cose sono sicuramente migliorate. Ad esempio, in test recenti, lo stack QUIC fortemente ottimizzato di Microsoft è stato in grado di ottenere 7,85 Gbps, rispetto a 11,85 Gbps per TCP + TLS sullo stesso sistema (quindi qui, QUIC è circa il 66% più veloce di TCP + TLS).
Questo è con i recenti aggiornamenti di Windows, che hanno reso l'UDP più veloce (per un confronto completo, il throughput UDP su quel sistema era di 19,5 Gbps). La versione più ottimizzata dello stack QUIC di Google è attualmente circa il 20% più lenta di TCP + TLS. Test precedenti di Fastly su un sistema meno avanzato e con alcuni accorgimenti rivendicano anche prestazioni uguali (circa 450 Mbps), dimostrando che a seconda del caso d'uso, QUIC può sicuramente competere con TCP.
Tuttavia, anche se QUIC fosse due volte più lento di TCP + TLS, non è poi così male. Innanzitutto, l'elaborazione QUIC e TCP + TLS in genere non è la cosa più pesante che accade su un server, perché è necessario eseguire anche altre logiche (ad esempio, HTTP, memorizzazione nella cache, proxy e così via). In quanto tale, non avrai effettivamente bisogno del doppio di server per eseguire QUIC (non è chiaro però quanto impatto avrà in un data center reale, perché nessuna delle grandi aziende ha rilasciato dati su questo).
In secondo luogo, ci sono ancora molte opportunità per ottimizzare le implementazioni QUIC in futuro. Ad esempio, nel tempo, alcune implementazioni QUIC si sposteranno (parzialmente) al kernel del sistema operativo (molto simile a TCP) o lo ignoreranno (alcune lo fanno già, come MsQuic e Quant). Possiamo anche aspettarci che l'hardware specifico per QUIC diventi disponibile.
Tuttavia, ci saranno probabilmente alcuni casi d'uso per i quali TCP + TLS rimarrà l'opzione preferita. Ad esempio, Netflix ha indicato che probabilmente non passerà a QUIC a breve, avendo investito molto in configurazioni personalizzate di FreeBSD per trasmettere i suoi video su TCP + TLS.
Allo stesso modo, Facebook ha affermato che QUIC sarà probabilmente utilizzato principalmente tra gli utenti finali e l'edge della CDN , ma non tra i data center o tra i nodi periferici e i server di origine, a causa del suo sovraccarico maggiore. In generale, gli scenari con larghezza di banda molto elevata continueranno probabilmente a favorire TCP + TLS, soprattutto nei prossimi anni.
Lo sapevate?
L'ottimizzazione degli stack di rete è una tana del coniglio profonda e tecnica di cui quanto sopra graffia semplicemente la superficie (e perde molte sfumature). Se sei abbastanza coraggioso o se vuoi sapere quali termini comeGRO/GSO,SO_TXTIME, bypass del kernel esendmmsg()erecvmmsg()significano, posso consigliarti anche alcuni articoli eccellenti sull'ottimizzazione di QUIC di Cloudflare e Fastly come un'ampia procedura dettagliata del codice di Microsoft e un discorso approfondito di Cisco. Infine, un ingegnere di Google ha tenuto una nota molto interessante sull'ottimizzazione della loro implementazione QUIC nel tempo.
Che cosa significa tutto questo?
Il particolare utilizzo da parte di QUIC dei protocolli UDP e TLS lo ha storicamente reso molto più lento di TCP + TLS. Tuttavia, nel tempo, sono stati apportati (e continueranno ad essere implementati) diversi miglioramenti che hanno in qualche modo colmato il divario. Tuttavia, probabilmente non noterai queste discrepanze nei casi d'uso tipici del caricamento di pagine Web, ma potrebbero darti mal di testa se mantieni server farm di grandi dimensioni.
Funzionalità HTTP/3
Finora abbiamo parlato principalmente di nuove funzionalità per le prestazioni in QUIC rispetto a TCP. Tuttavia, che dire di HTTP/3 rispetto a HTTP/2? Come discusso nella parte 1, HTTP/3 è in realtà HTTP/2-over-QUIC e, in quanto tale, nella nuova versione non sono state introdotte vere e proprie novità. Questo è diverso dal passaggio da HTTP/1.1 a HTTP/2, che era molto più ampio e introduceva nuove funzionalità come la compressione dell'intestazione, la definizione delle priorità del flusso e il push del server. Queste funzionalità sono ancora tutte in HTTP/3, ma ci sono alcune importanti differenze nel modo in cui vengono implementate sotto il cofano.
Ciò è dovuto principalmente al modo in cui funziona la rimozione del blocco HoL da parte di QUIC. Come abbiamo discusso, una perdita sul flusso B non implica più che i flussi A e C dovranno attendere le ritrasmissioni di B, come hanno fatto su TCP. Pertanto, se A, B e C inviassero ciascuno un pacchetto QUIC in quell'ordine, i loro dati potrebbero essere consegnati (ed elaborati dal) browser come A, C, B! In altre parole, a differenza di TCP, QUIC non è più completamente ordinato su flussi diversi!
Questo è un problema per HTTP/2, che si basava davvero sul rigido ordinamento di TCP nella progettazione di molte delle sue funzionalità, che utilizzano messaggi di controllo speciali intervallati da blocchi di dati. In QUIC, questi messaggi di controllo potrebbero arrivare (ed essere applicati) in qualsiasi ordine, potenzialmente anche facendo in modo che le funzionalità facciano l' opposto di quanto previsto! I dettagli tecnici sono, ancora una volta, non necessari per questo articolo, ma la prima metà di questo articolo dovrebbe darti un'idea di quanto possa diventare stupidamente complesso.
Pertanto, i meccanismi interni e le implementazioni delle funzionalità hanno dovuto cambiare per HTTP/3. Un esempio concreto è la compressione dell'intestazione HTTP , che riduce il sovraccarico di intestazioni HTTP di grandi dimensioni ripetute (ad esempio, cookie e stringhe user-agent). In HTTP/2, questo è stato fatto utilizzando la configurazione HPACK, mentre per HTTP/3 questo è stato rielaborato nel più complesso QPACK. Entrambi i sistemi offrono la stessa funzionalità (ad esempio la compressione dell'intestazione) ma in modi abbastanza diversi. Alcune eccellenti discussioni tecniche e diagrammi approfonditi su questo argomento possono essere trovati sul blog Litespeed.
Qualcosa di simile vale per la funzione di definizione delle priorità che guida la logica di multiplexing del flusso e di cui abbiamo brevemente discusso sopra. In HTTP/2, questo è stato implementato utilizzando un complesso "albero delle dipendenze", che ha cercato esplicitamente di modellare tutte le risorse della pagina e le loro interrelazioni (maggiori informazioni sono nel discorso "The Ultimate Guide to HTTP Resource Prioritization"). L'utilizzo di questo sistema direttamente su QUIC porterebbe a layout degli alberi potenzialmente molto errati, poiché l'aggiunta di ciascuna risorsa all'albero sarebbe un messaggio di controllo separato.
Inoltre, questo approccio si è rivelato inutilmente complesso, causando molti bug e inefficienze di implementazione e prestazioni inferiori alla media su molti server. Entrambi i problemi hanno portato a riprogettare il sistema di definizione delle priorità per HTTP/3 in un modo molto più semplice. Questa configurazione più semplice rende difficile o impossibile l'applicazione di alcuni scenari avanzati (ad esempio, l'inoltro del traffico da più client su una singola connessione), ma consente comunque un'ampia gamma di opzioni per l'ottimizzazione del caricamento delle pagine Web.
Anche se, ancora una volta, i due approcci offrono la stessa funzionalità di base (guida al multiplexing del flusso), la speranza è che la configurazione più semplice di HTTP/3 comporterà un minor numero di bug di implementazione.
Infine, c'è il server push . Questa funzione consente al server di inviare risposte HTTP senza attendere prima una richiesta esplicita. In teoria, questo potrebbe fornire ottimi guadagni in termini di prestazioni. In pratica, però, si è rivelato difficile da usare correttamente e implementato in modo incoerente. Di conseguenza, probabilmente verrà persino rimosso da Google Chrome.
Nonostante tutto ciò, è ancora definita come una funzionalità in HTTP/3 (sebbene poche implementazioni la supportino). Sebbene il suo funzionamento interno non sia cambiato tanto quanto le due caratteristiche precedenti, anch'esso è stato adattato per aggirare l'ordinamento non deterministico di QUIC. Purtroppo, però, questo farà ben poco per risolvere alcuni dei suoi problemi di vecchia data.
Che cosa significa tutto questo?
Come abbiamo detto prima, la maggior parte del potenziale di HTTP/3 deriva dal QUIC sottostante, non da HTTP/3 stesso. Sebbene l'implementazione interna del protocollo sia molto diversa da quella di HTTP/2, le sue caratteristiche di prestazioni di alto livello e il modo in cui possono e dovrebbero essere utilizzate sono rimaste le stesse.
Sviluppi futuri a cui prestare attenzione
In questa serie, ho regolarmente evidenziato che un'evoluzione più rapida e una maggiore flessibilità sono aspetti fondamentali di QUIC (e, per estensione, HTTP/3). Pertanto, non dovrebbe sorprendere che le persone stiano già lavorando su nuove estensioni e applicazioni dei protocolli. Di seguito sono elencati i principali che probabilmente incontrerai da qualche parte lungo la linea:
Correzione degli errori in avanti
Lo scopo di questa tecnica è, ancora una volta, quello di migliorare la resilienza di QUIC alla perdita di pacchetti . Lo fa inviando copie ridondanti dei dati (sebbene codificati e compressi in modo intelligente in modo che non siano così grandi). Quindi, se un pacchetto viene perso ma arrivano i dati ridondanti, non è più necessaria una ritrasmissione.
Questo era originariamente una parte di Google QUIC (e uno dei motivi per cui la gente dice che QUIC è buono contro la perdita di pacchetti), ma non è incluso nella versione 1 standardizzata di QUIC perché il suo impatto sulle prestazioni non è stato ancora dimostrato. I ricercatori ora stanno effettuando esperimenti attivi con esso, tuttavia, e puoi aiutarli utilizzando l'app PQUIC-FEC Download Experiments.Multipercorso QUIC
In precedenza abbiamo discusso della migrazione della connessione e di come può aiutare quando si passa, ad esempio, dal Wi-Fi al cellulare. Tuttavia, ciò non implica anche che potremmo utilizzare sia Wi-Fi che cellulare contemporaneamente ? L'utilizzo simultaneo di entrambe le reti ci darebbe più larghezza di banda disponibile e maggiore robustezza! Questo è il concetto principale alla base del multipath.
Questo è, ancora una volta, qualcosa che Google ha sperimentato ma che non è arrivato alla versione 1 di QUIC a causa della sua complessità intrinseca. Tuttavia, da allora i ricercatori hanno mostrato il suo alto potenziale e potrebbe arrivare alla versione 2 di QUIC. Si noti che esiste anche il multipath TCP, ma ci sono voluti quasi un decennio per diventare praticamente utilizzabile.Dati inaffidabili su QUIC e HTTP/3
Come abbiamo visto, QUIC è un protocollo completamente affidabile. Tuttavia, poiché funziona su UDP, che è inaffidabile, possiamo aggiungere una funzionalità a QUIC per inviare anche dati inaffidabili. Questo è delineato nell'estensione del datagramma proposta. Ovviamente non vorresti usarlo per inviare risorse di pagine Web, ma potrebbe essere utile per cose come giochi e streaming video live. In questo modo, gli utenti otterrebbero tutti i vantaggi di UDP ma con crittografia a livello QUIC e controllo della congestione (opzionale).WebTrasporto
I browser non espongono direttamente TCP o UDP a JavaScript, principalmente a causa di problemi di sicurezza. Invece, dobbiamo fare affidamento su API a livello HTTP come Fetch e sui protocolli WebSocket e WebRTC, un po' più flessibili. L'ultima di questa serie di opzioni si chiama WebTransport, che consente principalmente di utilizzare HTTP/3 (e, per estensione, QUIC) in un modo più basso (sebbene possa anche ricadere su TCP e HTTP/2 se necessario ).
Fondamentalmente, includerà la possibilità di utilizzare dati inaffidabili su HTTP/3 (vedi il punto precedente), il che dovrebbe rendere cose come i giochi un po' più facili da implementare nel browser. Per le normali chiamate API (JSON), utilizzerai comunque Fetch, che utilizzerà automaticamente HTTP/3 quando possibile. WebTransport è ancora oggetto di pesanti discussioni al momento, quindi non è ancora chiaro come sarà alla fine. Dei browser, solo Chromium sta attualmente lavorando a un'implementazione pubblica di proof-of-concept.Streaming video DASH e HLS
Per i video non live (si pensi a YouTube e Netflix), i browser in genere utilizzano i protocolli Dynamic Adaptive Streaming over HTTP (DASH) o HTTP Live Streaming (HLS). Entrambi fondamentalmente significano che codifichi i tuoi video in blocchi più piccoli (da 2 a 10 secondi) e diversi livelli di qualità (720p, 1080p, 4K, ecc.).
In fase di esecuzione, il browser stima la qualità più alta che la tua rete può gestire (o la più ottimale per un determinato caso d'uso) e richiede i file rilevanti dal server tramite HTTP. Poiché il browser non ha accesso diretto allo stack TCP (come in genere implementato nel kernel), occasionalmente commette alcuni errori in queste stime o impiega un po' di tempo per reagire alle mutevoli condizioni della rete (con conseguente stallo del video) .
Poiché QUIC è implementato come parte del browser, questo potrebbe essere leggermente migliorato, fornendo agli estimatori di streaming l'accesso a informazioni di protocollo di basso livello (come tassi di perdita, stime della larghezza di banda, ecc.). Altri ricercatori hanno sperimentato la combinazione di dati affidabili e inaffidabili anche per lo streaming video, con alcuni risultati promettenti.Protocolli diversi da HTTP/3
Poiché QUIC è un protocollo di trasporto per scopi generici, possiamo aspettarci che molti protocolli a livello di applicazione che ora vengono eseguiti su TCP vengano eseguiti anche su QUIC. Alcuni lavori in corso includono DNS-over-QUIC, SMB-over-QUIC e persino SSH-over-QUIC. Poiché questi protocolli in genere hanno requisiti molto diversi rispetto a HTTP e al caricamento di pagine Web, i miglioramenti delle prestazioni di QUIC di cui abbiamo discusso potrebbero funzionare molto meglio per questi protocolli.
Che cosa significa tutto questo?
QUIC versione 1 è solo l'inizio . Molte funzionalità avanzate orientate alle prestazioni che Google aveva precedentemente sperimentato non sono arrivate a questa prima iterazione. Tuttavia, l'obiettivo è quello di evolvere rapidamente il protocollo, introducendo nuove estensioni e funzionalità ad alta frequenza. Pertanto, nel tempo, QUIC (e HTTP/3) dovrebbero diventare chiaramente più veloci e flessibili di TCP (e HTTP/2).
Conclusione
In questa seconda parte della serie, abbiamo discusso le diverse caratteristiche e aspetti delle prestazioni di HTTP/3 e in particolare di QUIC. Abbiamo visto che mentre la maggior parte di queste funzionalità sembra di grande impatto, in pratica potrebbero non fare molto per l'utente medio nel caso d'uso del caricamento di pagine Web che abbiamo preso in considerazione.
Ad esempio, abbiamo visto che l'uso di UDP da parte di QUIC non significa che può improvvisamente utilizzare più larghezza di banda rispetto a TCP, né significa che può scaricare le risorse più rapidamente. La funzione 0-RTT, spesso lodata, è davvero una micro-ottimizzazione che ti fa risparmiare un viaggio di andata e ritorno, in cui puoi inviare circa 5 KB (nel peggiore dei casi).
La rimozione del blocco HoL non funziona bene se si verifica una perdita di pacchetti o quando si caricano risorse che bloccano il rendering. La migrazione della connessione è altamente situazionale e HTTP/3 non ha nuove funzionalità importanti che potrebbero renderlo più veloce di HTTP/2.
Pertanto, potresti aspettarti che io raccomandi di saltare semplicemente HTTP/3 e QUIC. Perché preoccuparsi, giusto? Tuttavia, sicuramente non farò nulla del genere! Anche se questi nuovi protocolli potrebbero non aiutare molto gli utenti su reti veloci (urbane), le nuove funzionalità hanno sicuramente il potenziale per avere un forte impatto sugli utenti altamente mobili e sulle persone su reti lente.
Anche nei mercati occidentali come il mio Belgio, dove generalmente abbiamo dispositivi veloci e accesso a reti cellulari ad alta velocità, queste situazioni possono interessare dall'1% fino al 10% della tua base di utenti, a seconda del prodotto. Un esempio è qualcuno su un treno che cerca disperatamente un'informazione critica sul tuo sito web, ma deve aspettare 45 secondi per caricarla. So sicuramente di essere stato in quella situazione, desiderando che qualcuno avesse schierato QUIC per tirarmi fuori.
Tuttavia, ci sono altri paesi e regioni in cui le cose vanno ancora molto peggio. Lì, l'utente medio potrebbe assomigliare molto di più al 10% più lento del Belgio e l'1% più lento potrebbe non vedere mai una pagina caricata. In molte parti del mondo, le prestazioni web sono un problema di accessibilità e inclusività.
Questo è il motivo per cui non dovremmo mai solo testare le nostre pagine sul nostro hardware (ma anche utilizzare un servizio come Webpagetest) e anche perché dovresti assolutamente implementare QUIC e HTTP/3 . Soprattutto se i tuoi utenti sono spesso in movimento o difficilmente hanno accesso a reti cellulari veloci, questi nuovi protocolli potrebbero fare la differenza, anche se non noti molto sul tuo MacBook Pro cablato. Per maggiori dettagli, consiglio vivamente il post di Fastly sull'argomento.
Se ciò non ti convince completamente, considera che QUIC e HTTP/3 continueranno ad evolversi e ad accelerare negli anni a venire. Ottenere una prima esperienza con i protocolli ripagherà lungo la strada, consentendoti di sfruttare i vantaggi delle nuove funzionalità il prima possibile. Inoltre, QUIC applica le migliori pratiche di sicurezza e privacy in background, a vantaggio di tutti gli utenti ovunque.
Finalmente convinto? Quindi continua con la parte 3 della serie per leggere come puoi utilizzare in pratica i nuovi protocolli.
- Parte 1: Storia di HTTP/3 e concetti fondamentali
Questo articolo è rivolto a persone che non conoscono HTTP/3 e protocolli in generale e discute principalmente le nozioni di base. - Parte 2: Funzionalità di prestazione HTTP/3
Questo è più approfondito e tecnico. Le persone che già conoscono le basi possono iniziare da qui. - Parte 3: Pratiche opzioni di distribuzione HTTP/3
Questo terzo articolo della serie spiega le sfide legate alla distribuzione e al test di HTTP/3 da soli. Descrive in dettaglio come e se è necessario modificare anche le pagine Web e le risorse.